MySQL · 源码分析 · 聚合函数(Aggregate Function)的实现过程
Author: 道客
总览
聚合函数(Aggregate Function)顾名思义,就是将一组数据进行统一计算,常常用于分析型数据库中,当然在应用中是非常重要不可或缺的函数计算方式。比如我们常见的COUNT/AVG/SUM/MIN/MAX等等。本文主要分析下该类函数实现的一些框架,不涉及到每个函数的详尽分析。聚合函数(Aggregate Function)实现的大部分代码在item_sum.h和item_sum.cc。
下面我们看一下代码,聚合函数(Aggregate Function)有哪些类型:
enum Sumfunctype {
COUNT_FUNC, // COUNT
COUNT_DISTINCT_FUNC, // COUNT (DISTINCT)
SUM_FUNC, // SUM
SUM_DISTINCT_FUNC, // SUM (DISTINCT)
AVG_FUNC, // AVG
AVG_DISTINCT_FUNC, // AVG (DISTINCT)
MIN_FUNC, // MIN
MAX_FUNC, // MAX
STD_FUNC, // STD/STDDEV/STDDEV_POP or DISTINCT
VARIANCE_FUNC, // VARIANCE/VAR_POP and VAR_SAMP or DISTINCT
SUM_BIT_FUNC, // BIT_AND, BIT_OR and BIT_XOR
UDF_SUM_FUNC, // user defined functions
GROUP_CONCAT_FUNC, // GROUP_CONCAT or GROUP_CONCAT DISTINCT
JSON_AGG_FUNC, // JSON_ARRAYAGG and JSON_OBJECTAGG
ROW_NUMBER_FUNC, // Window functions
RANK_FUNC,
DENSE_RANK_FUNC,
CUME_DIST_FUNC,
PERCENT_RANK_FUNC,
NTILE_FUNC,
LEAD_LAG_FUNC,
FIRST_LAST_VALUE_FUNC,
NTH_VALUE_FUNC
};
类Item_sum是聚合函数的基类。接下来我们继续看一下总体和主要的聚合函数具体在代码中的类结构和继承关系,

COUNT/SUM/AVG/STD/VAR_POP函数

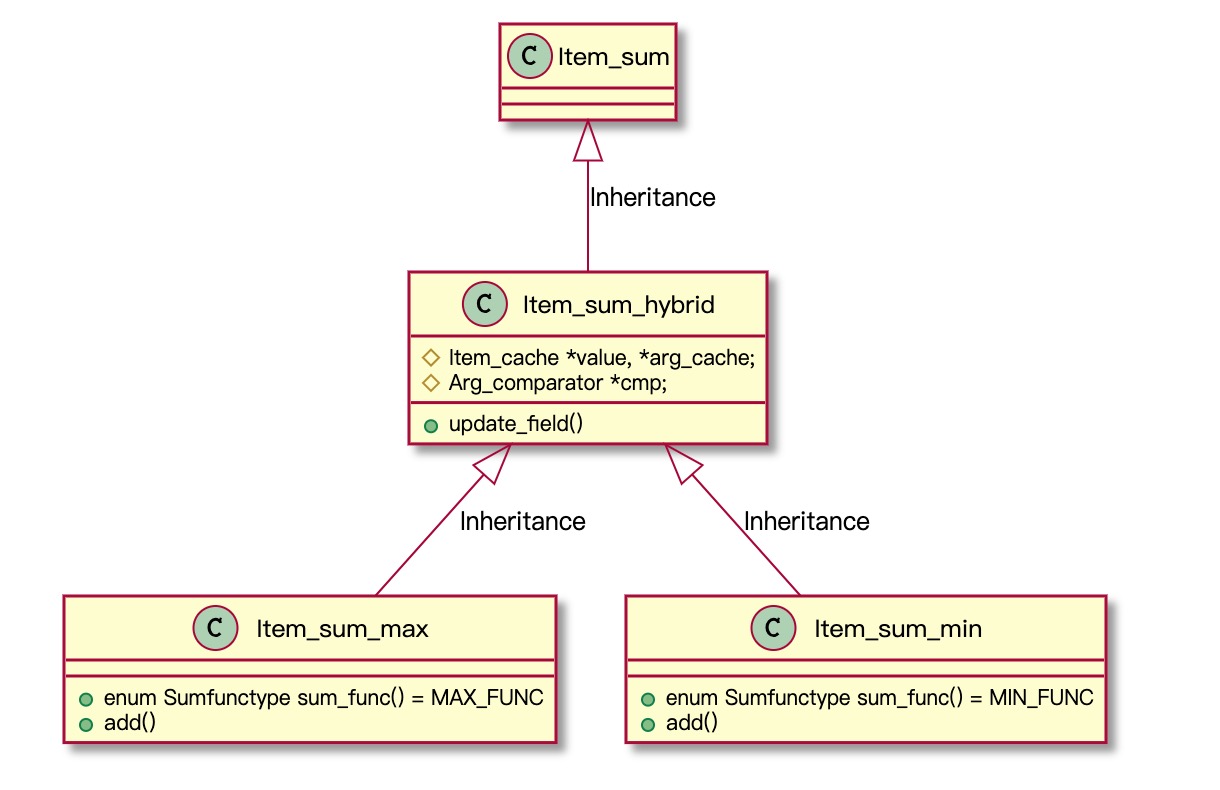
MIN/MAX函数
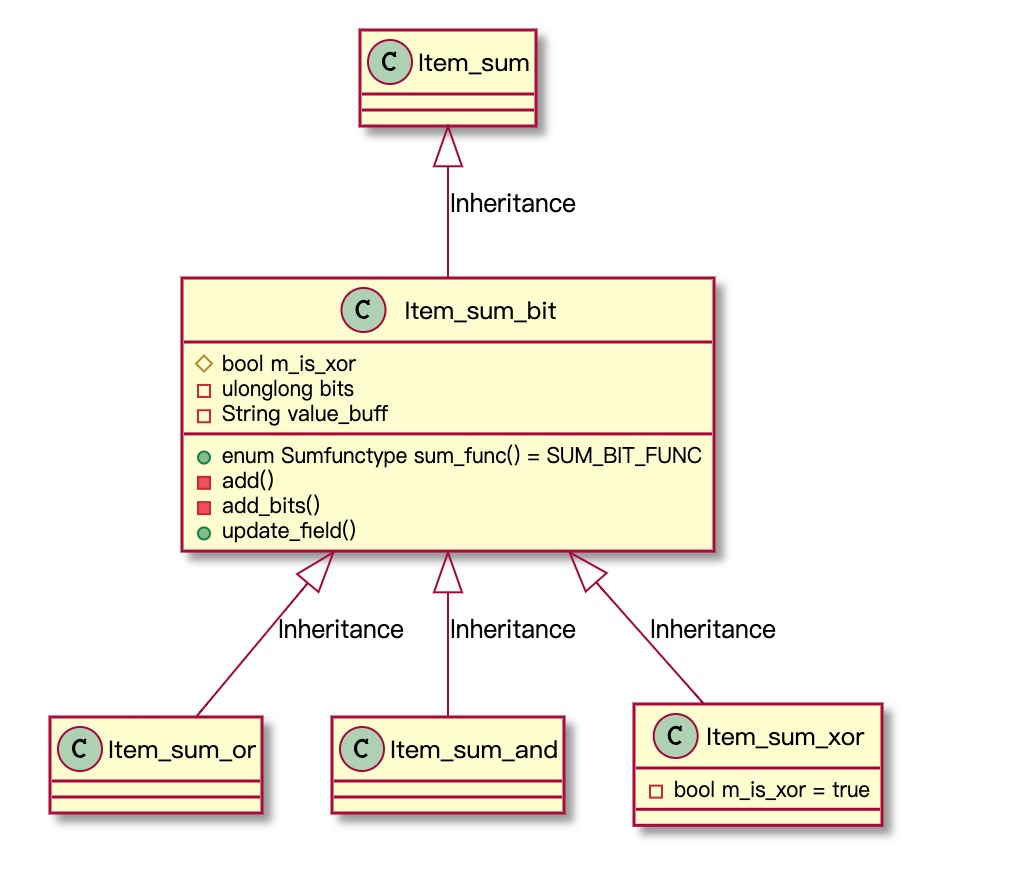
BIT_OR/BIT_AND/BIT_XOR函数
不带GROUP BY聚合
下面我们来介绍下如何工作的,先来看看不带GROUP BY的聚合过程。该过程借助了一个辅助类Aggregator,而GROUP BY并不使用该辅助类。
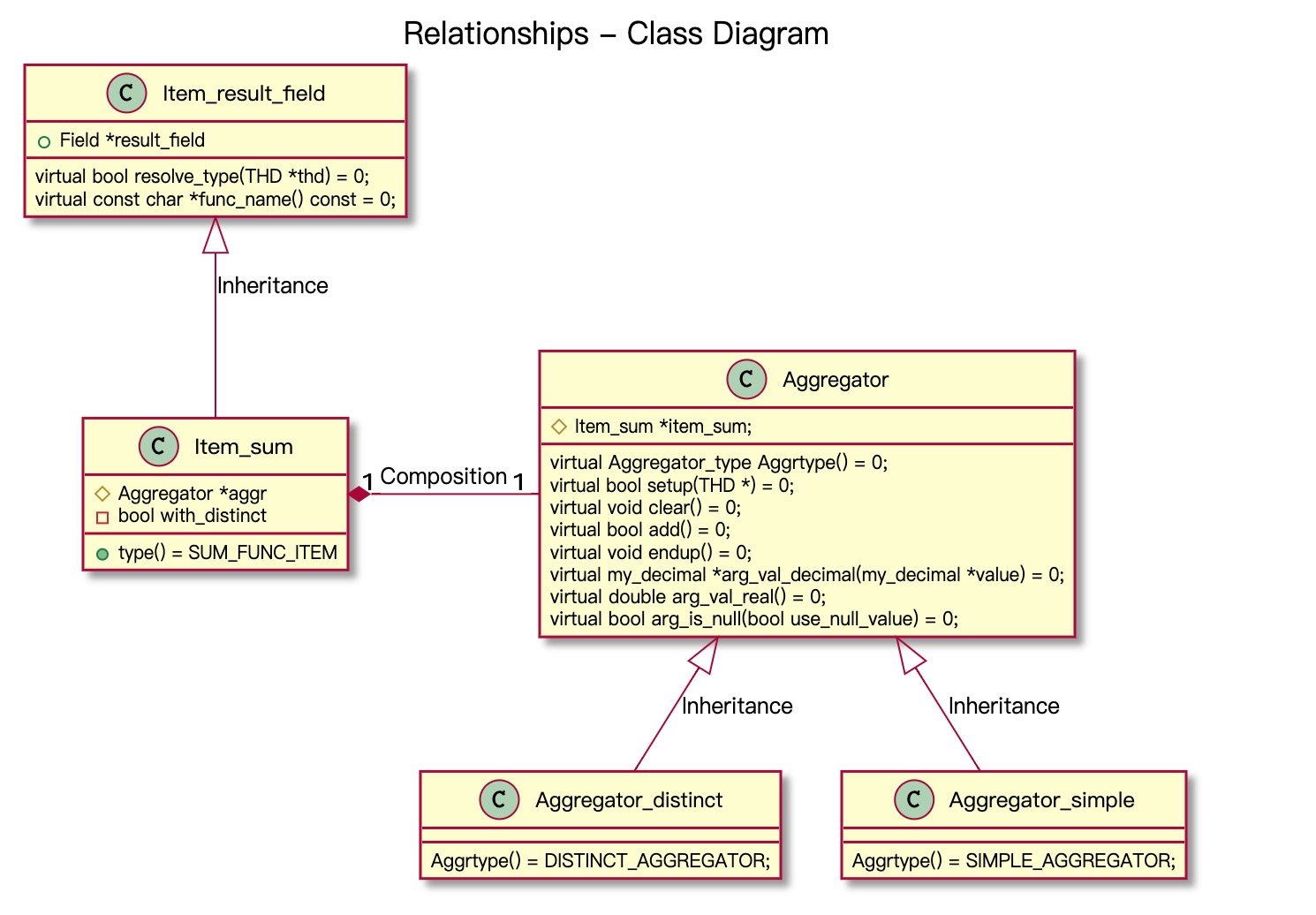
在优化阶段,需要进行setup,比如初始化distinct或者sorting需要Temp table或者Temp tree结构,方便下阶段的聚合函数。具体根据不同函数有不同的实现。
JOIN::optimize-->
JOIN::make_tmp_tables_info-->
setup_sum_funcs-->
Item_sum::aggregator_setup-->
Aggregator_simple::setup-->
Item_sum::setup-->
在执行阶段,结果输出函数end_send_group调用init_sum_functions来对该SQL查询的所有SUM函数进行聚合计算。
JOIN::exec()-->
do_select()-->
sub_select()-->
evaluate_join_record()-->
end_send_group()-->
init_sum_functions--> for all sum functions
reset_and_add()-->
aggregator_clear()/aggregator_add()-->
Item_sum_xxx::clear()/Item_sum_xxx::add()
在计算DISTINCT聚合时候,还需要必须实现aggregator::endup(),因为Distinct_aggregator::add() 只是通过某种方式采集了unique的行,但是并未保存,需要在这个阶段进行保存。这个过程也可以理解,因为在DISTINCT聚合过程中(add),在过程中无法判断是否为唯一。当然,这个并不适用于GROUP BY场景,因为GROUP BY场景本身就是通过临时表解决了唯一的问题。
带GROUP BY聚合
MySQL对于带GROUP BY的聚合,通常采用了Temp table的方式保存了(GROUP BY KEY, AGGR VALUE)。
JOIN::exec()-->
do_select()-->
sub_select()-->
evaluate_join_record()-->
sub_select_op()-->
QEP_tmp_table::put_record-->
end_update-->
init_tmptable_sum_functions/update_tmptable_sum_func--> // 每个group by的key都会调用至少一次
reset_sum_func-->Item_sum_xxx::reset_field()/Item_sum_xxx::update_field()
Item_sum继承Item_result_field,意味着该类作为计算函数的同时,也保存输出的结果。具体可以看对应Item_sum_xxx::val_xxx的实现,该函数负责对上层结果或者客户端结果进行输出。
但是,对于特殊聚合函数如AVG/STD/VAR_POP等函数,在累加过程中,临时保存的变量值有多个,实际的输出结果必须通过加工处理,尤其是在GROUP BY的场景下,多个临时变量需要保存到Temp table中,下次累加的时候取出来,直到最终结果输出。因此,需要额外的辅助Item_result_field类,帮助该聚合函数进行最终结果输出。下图为各个辅助Item_result_field的继承关系。

举例来说,对于Item_avg_field类的最终结果(SELECT AVG(c1) FROM t1 GROUP BY c2)则需要通过Item_avg_field::val_xxx计算后进行输出,如:
double Item_avg_field::val_real() {
// fix_fields() never calls for this Item
double nr;
longlong count;
uchar *res;
if (hybrid_type == DECIMAL_RESULT) return val_real_from_decimal();
float8get(&nr, field->ptr);
res = (field->ptr + sizeof(double));
count = sint8korr(res);
if ((null_value = !count)) return 0.0;
return nr / (double)count;
}
调用的堆栈如下:
Item_avg_field::val_real
Item::send
THD::send_result_set_row
Query_result_send::send_data
end_send
evaluate_join_record
QEP_tmp_table::end_send
sub_select_op
sub_select
do_select
JOIN::exec
当然,这有个小Tips就是,如果内核需要实现多线程并行计算聚合函数的时候,我们就可以通过改造 对中间结果输出save_in_field_inner函数,让每个中间结果如2个value或者以上会按照自己的设计保存到相应的field->ptr中,保留到临时表中,堆栈如下:
// 这个函数是fake函数,主要其实就是调用默认的Item::save_in_field_inner基类函数。
type_conversion_status Item_avg_field::save_in_field_inner(Field *to,
bool no_conversions) {
if (需要保留中间结果)
to->store((char *)field->ptr, field->field_length, cs);
else
return Item::save_in_field_inner(to, no_conversions);
}
调用的堆栈如下:
Item_avg_field::save_in_field_inner
Item::save_in_field
fill_record
fill_record_n_invoke_before_triggers
Query_result_insert::store_values
Query_result_insert::send_data
end_send
evaluate_join_record
QEP_tmp_table::end_send
sub_select_op
sub_select
do_select
JOIN::exec
聚合函数的优化
不带where子句的简单COUNT
在简单求计数统计时候(SELECT COUNT(*) FROM t1),Server层和Innodb层实现了handler::ha_records用于直接返回准确的计数。由于加了WHERE子句会调用evaluate_join_record评估是否该返回行否和统计条件。详细调用堆栈如下:
ha_innobase::records
handler::ha_records
get_exact_record_count
end_send_count
do_select
JOIN::exec
无GROUP BY的MIN/MAX单行优化
如果恰好对index所在的列求MIN/MAX,而且只返回一行没有GROUP BY的情况下,那么这个是可以进行优化的,可以看执行计划的Extra信息变成Select tables optimized away而非使用Using temporary。
mysql> explain select min(c1) from ttt;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
1 row in set, 1 warning (0.00 sec)
因此结果会在优化阶段就已经计算完毕返回到上层,堆栈如下:
ha_innobase::index_first
handler::ha_index_first
get_index_min_value
opt_sum_query
JOIN::optimize
当然还有类似MIN(1)/MAX(1)的常量处理也类似,连innodb层都不会涉及到,这里就不再赘述了。
使用松散索引扫描Using index for group-by方式的聚合
这种是适用于特殊场景:MIN/MAX,因为不需要去扫描所有行去找到最大最小值。扫描的方式可以通过index直接跳到最大和最小的聚合值的位置。比如下面的例子,需要找到每个唯一c1的最最小值,恰好c1,c2是一个index上的属性列,那么可以通过定位c1,直接在索引上寻找(c1, min(c2)),无需扫描所有行。
create table t1 (c1 int not null, c2 char(6) not null, c3 int not null, key(c1, c2, c3));
insert into t1 values (1, 'Const1', 2);
insert into t1 values (2, 'Const2', 4);
insert into t1 values (3, 'Const3', 4);
insert into t1 values (4, 'Const4', 9);
insert into t1 values (5, 'Const5', 9);
insert into t1 select * from t1;
insert into t1 select * from t1;
insert into t1 select * from t1;
insert into t1 select * from t1;
insert into t1 select * from t1;
insert into t1 select * from t1;
insert into t1 select * from t1;
# using IndexRangeScanIterator + QUICK_GROUP_MIN_MAX_SELECT Using index for group-by
explain select min(c2) from ttt2 group by c1;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | t1 | NULL | range | c1 | c1 | 4 | NULL | 2 | 100.00 | Using index for group-by |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
详细堆栈如下:
handler::ha_index_last
QUICK_GROUP_MIN_MAX_SELECT::reset
IndexRangeScanIterator::Init
sub_select
JOIN::exec
index_first/index_next_different
IndexRangeScanIterator::Read
IndexRangeScanIterator::Init
sub_select
JOIN::exec
综述
综上所述,本篇文章主要从源码层面对MySQL 8.0 实现的聚合函数(Aggregate Function)进行了一下简要的分析。聚合函数(Aggregate Function)在无GROUP BY的情况下,利用定义成员变量保存对应计算结果的中间值,在有GROUP BY的情况下利用了Temp Table来保存对应的GROUP BY的键和聚合值,另外还介绍了一些聚合函数(Aggregate Function)的优化方式。当然这里面还有两类重要的聚合就是ROLL UP和WINDOWS函数,由于篇幅限制,未来篇章会单独介绍。希望该篇文章能够帮助广大读者了解MySQL聚合函数(Aggregate Function)的实现原理。