MySQL · 引擎特性 · 8.0 Innodb redo log record 源码分析
Author: 攒叶
Introduction
redo log对于innodb高效实现事务有至关重要的作用,关于redo log的介绍目前已有许多资料,但大都针对MySQL 5.6、MySQL 5.7版本,内容大都聚集在redo log与事务、redo log与恢复、checkpoint技术等特性上,对于redo log record本身却很少有(甚至几乎没有)资料介绍。目前8.0.16版本,redo log record一共有64种类型,对每种类型都进行详细分析是困难的。本文针对insert语句的redo log类型进行分析,重点分析B+树分裂产生新页时,redo log作为物理日志是如何准确地描述该过程。由于涉及到B+树,本文也会对innodb的数据页进行简单总结。
Index Page
关于索引页,可以查看这篇文章,此处总结索引页的一些关键设计
innodb page的大小由innodb_page_size确定,默认为16 KBindex page的结构图如下所示
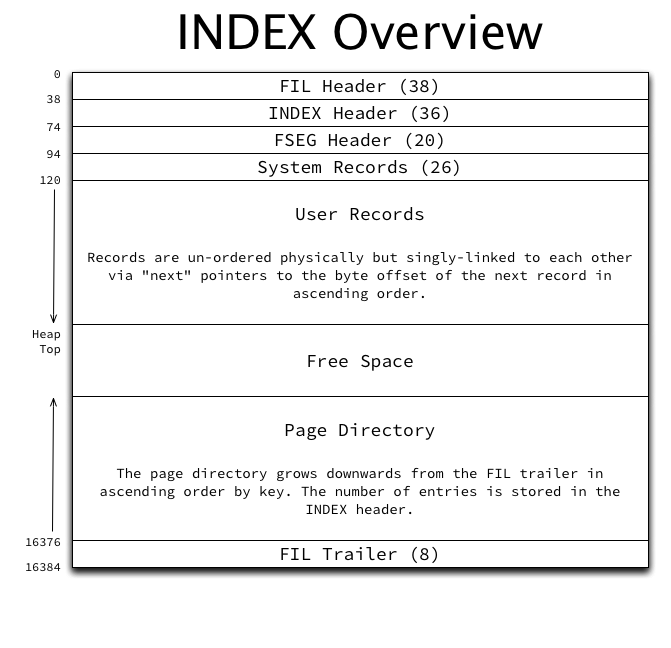
FIL Header / Trailer
Offset(Page Number):每个表空间从0开始,该值乘以数据页的大小得到数据页在文件中的起始偏移量。在redo log通过记录该值指示操作修改了哪个页面Previous/Next Page:两个指针,按照逻辑顺序(一般是主键顺序)组织成双向链表。这也可以看到,聚集索引指的是逻辑上的聚集,而物理上实际不一定是连续的。通过双向链表可以很方便进行范围查找FIL_PAGE_LSN:最新被修改的LSN,用于实现幂等特性FIL_PAGE_TYPE:可能的page type有index、undo、blob等十多种FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID:space id,redo log通过该值与page no唯一标识一个page

Page Header
Number of Directory Slots:目录槽的个数。- 从
index page overview图中看到,记录从上往下涨,而目录槽从下往上堆。 Page Directory是一个稀疏目录,按照key排序。里面的每个slot指向了本slot中的第一个记录。- 当定位到一个
page时,先通过page directory找到对应的slot,然后找到slot中的第一个记录,通过遍历slot内的所有记录,最终找到指定的记录 slot上的记录数不能太多也不能太少,对于普通记录在[4,8]区间内,如果超过则要重新整理,方法是将slot按照中间点拆分成两个,后续的目录进行平移(为了给新的slot腾出空间)
- 从
PAGE_HEAP_TOP:空闲空间的起始地址,PAGE_N_HEAP:最高位用来标记格式(compact还是redundant),不会减少,只要有空闲空间记录就会增加PAGE_FREE:删除记录的链表。- 当一个记录被删除时,会先被标记为
delete状态,随后被purge线程彻底删除,最后用头插法加入这个链表。 - 当一个记录被插入时,会先去
page_free找,不行再用空闲空间(heap)
- 当一个记录被删除时,会先被标记为
PAGE_LAST_INSERT, PAGE_DIRECTION, PAGE_N_DIRECTION:上一次被插入的记录、最后一个记录插入的防线、同一个方法插入的记录数,这些都是为了加速连续插入操作PAGE_N_RECS:用户的记录(不包括最大和最小记录)PAGE_MAX_TRX_ID:修改此数据页的当前最大事务idPAGE_LEVEL:索引页索引idPAGE_INDEX_ID:索引页的索引IDPAGE_BTR_SEG_LEAF,PAGE_BTR_SEG_TOP:叶子节点和非叶子节点的段头页地址

Infimum and Supremum Records
数据页上逻辑最小和最大的记录,数据页被创建时创建,不能被删除,目的是方便页内操作。
Compact Format
| 变长字段长度列表 | NULL字段标记 | 记录头 | 字段1数据 | 字段2数据 | … |
|---|---|---|---|---|---|
| 0~n | 0~m | 5 bytes | 字段1长度 | 字段2长度 | … |
上表是一个典型的compact格式的行记录,关于compact记录已有许多资料,具体可参考引用。
以下将补充许多资料中讲得相对模糊的地方:
- 变长字段长度列表只记录变长字段的长度,比如
VARCHAR,值得注意的是:CHAR类型也会被记录,因为从mysql 4.1开始,CHR(N)中的N指的的字符个数,而不是字节个数,所以CHAR本身也需要存储其变长长度
- 变长字段长度列表可以只有
0个字节,只要行记录中没有变长字段 - 对于一个变长字段,其字段长度最多只有
2个字节,当长度小于256字节,用1字节表示,否则用2字节 NULL字段标记可以也只有0个字节,只要行记录中没有nullable字段non-nullable字段是不会在NULL字段标记中被标记的 -NULL字段标记的标记方法:- 每一个
nullable列都在NULL字段标记中有1 bit对应的标记位 - 从右往左,即第一个
nullable列在最低位 - 如果
nullable列为NULL,则对应的标记位为1,否则为0
- 每一个
NULL字段标记可以不止1个字节(网上许多资料均标注这里固定采用1个字节,其实是不对的),具体可以参考这篇文章。此处简单总结下结论:NULL字段标记的长度不是固定的,每8个nullable列占用1个字节- 当
nullable列数不足8的整数倍时,最后一个字节高位补0 - 基于上述原因,在设计表时,并非
nullalbe字段越多越节省空间
-
记录头总是固定的
5个字节,其格式如下图所示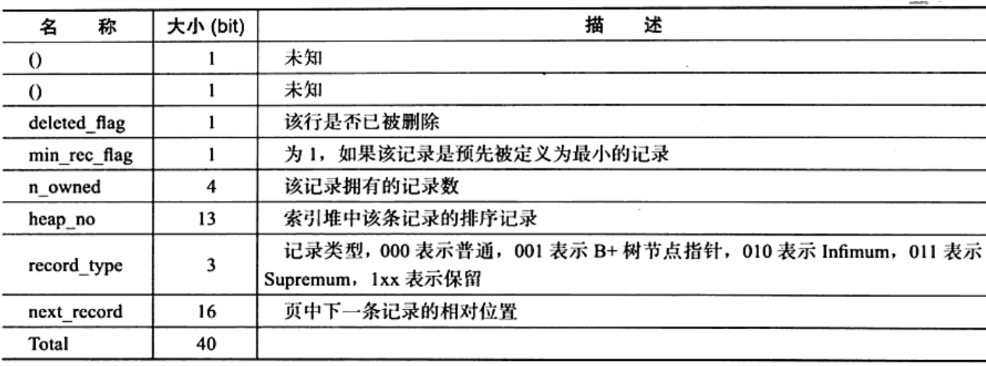
- 记录头其中有两位是预留位,
GCS格式中用来实现instantly add column,具体原理可参考这篇文章 - 记录头后就是各个字段的具体数据,值得注意的有:
- 第一个字段是主键,如果没有显示指定,则
innodb会隐式增加一个6字节的字段作为主键 - 接下来是两个隐藏的字段:事务
ID列以及回滚指针列,分别占6 byte和7 bytes - 接下来是个非主键字段,如果
nullable字段且其值为NULL,则不占用空间
- 第一个字段是主键,如果没有显示指定,则
insert && redo log
Flow Chart
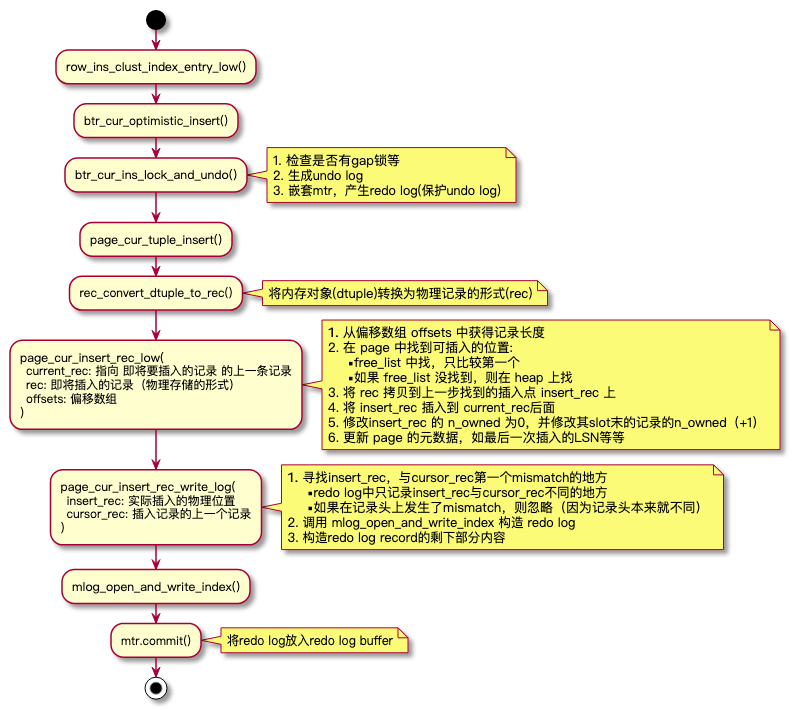
insert redo record

上表是一条insert语句对应的redo log记录。值得注意的是,这条insert语句没有涉及到instant列,也不是临时表上的插入,并且上一条记录与本记录的extra_len、data_len都相同(见compact format, 同一张表的不同记录,这两部分的长度可能不同)。
即使是同一种类型的redo record,其解析格式也可能不同,如果上一条记录与本记录的extra_len、data_len都不同,则会额外记录本条记录在page中的偏移,以及本条记录发生mismatch的位置。
关于redo log record的资料很少,本次分析是最为简单的一种,下面简单阐述该表中较为难以理解的部分:
compressed:一种压缩格式,从最高位开始,第几位开始为0则意味着它的字节长度,如第1位为0(0nnnnnnn,则它是1个字节的数据;如第2位为0(10nnnnnn nnnnnnnn则它为2个字节的数据;以此类推mismatch len:插入的记录与逻辑顺序上的上一条记录比对中,不一致的长度。- 当
recovery发生时,通过上一条记录与redo log中记录结合,可以恢复出插入的记录。 - 不同记录的记录头部分不一样,但在寻找
mismatch点时,会跳过该部分,在恢复过程中,新insert的记录的记录头会被重新计算填充
- 当
Notes
offset:在构造index page record以及redo log record过程中,会使用到offset数组offset数组用于标记一条记录中各个列相对于记录头的偏移- 该数组默认情况下从栈上分配,当表的列数超过
100时,则从innodb中获取 - 其结构如下所示:

rec_t*: 由于一条记录的extra以及data部分都是变长的,所以传入的指针rec_t*一般指向中间:即它的左侧是extra部分,包括变长字段长度列表、NULL标志、记录头;右侧则是各列的数据LSN的值为当前已经写入的redo log长度,它没有在redo log record中记录,其原因在于:redo log block的头部中记录了本block的第一个redo log recrod的LSN。在解析过程中,结合redo log record的长度可以获知该record的LSNredo log的刷写不需要double write保护,原因在于redo log block的长度为512个字节,与硬盘扇区的长度一致。读写一个扇区是原子操作。
create page && redo log
可以看到,当插入一条记录时,edo log记录了对对应数据页的修改过程。但当当前page不足以放下新插入的记录时,且邻居page也没有空间时,会触发B+树的分裂操作。具体过程:
// 持有page的X-latch
btr_cur_optimistic_insert-->
// 当前page空间不足,乐观插入失败,
// 进行悲观插入之前,btr_pcur_open对父亲子树进行上锁
btr_cur_pessimistic_insert-->
// 分裂,并将记录插入指定page
btr_page_split_and_insert-->
...
create page redo log record
在btr_page_split_and_insert函数中,调用btr_page_alloc分配新的page,然后调用btr_page_create创建新页,期间调用page_create_write_log生成一条类型为MLOG_COMP_PAGE_CREATE的redo log记录,其典型format如下:
| type | space_id | page_no |
|---|---|---|
| MLOG_COMP_PAGE_CREATE, 1 byte | 1~5 bytes | 1~5 bytes |
接着在btr_page_set_level方法中,生成一条类型为MLOG_2BYTES的record,记录page在B+树上的level(叶子节点的level为0,根节点level为深度),其format如下所示:
| type | space_id | page_no | page_offset | val |
|---|---|---|---|---|
| MLOG_2BYTES, 1 byte | 1~5 bytes | 1~5 bytes | 2 bytes | compressed, 1~3 bytes |
接下来btr_page_set_index_id方法中,生成一条类型为MLOG_8BYTES,该record表示将对应的page(space_id + page_no )中的PAGE_INDEX_ID字段设置为val值,其format与上述MLOG_2BYTES类似
接下来btr_insert_on_non_leaf_level_func会调用btr_cur_optimistic_insert,或者btr_cur_pessimistic_insert来将聚集索引的非叶子节点的记录插入。聚集索引的非叶子节点的记录形如下:
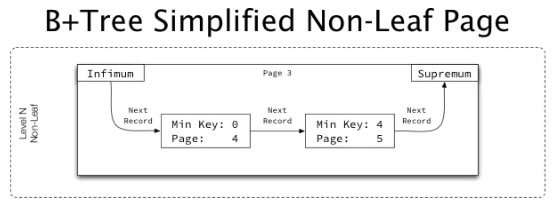
可以看到非叶子节点的记录与用户表记录实际并没有本质区别,该过程可以看成是往page中插入一条“用户记录”。
由于B+树的分裂是个递归过程,btr_insert_on_non_leaf_level_func函数也会被递归调用,直到调整好B+树。期间会继续不断产生相应的redo record,包括但不限于类型为MLOG_COMP_REC_INSERT,MLOG_COMP_PAGE_CREATE,MLOG_8BYTES等的redo log record。