MySQL · 引擎特性 · clone_plugin
Author: kongzhi
背景
mysql官方在8.0.17 release了克隆实例功能,它能让用户很方便的在空实例上通过简单的sql命令把远端实例拷贝到本地并替换后重新提供服务,该功能由一系列的worklog实现:
worklog9209实现本地clone,它完成clone核心功能开发。
worklog9210在本地克隆的基础上实现远程克隆,通过新加协议,以流的方式把实例克隆到其他服务器上。
worklog9211完成获取,传输和保存克隆位点的功能,方便克隆实例能够正确的加入到被克隆集群中。
后续还有worklog基于克隆功能实现其他功能:比如备库重搭,group replication新建节点等。
基本原理
克隆最基本的要求就是要保证把克隆源的一个一致性的状态拷贝到另一个数据目录中,那么插件是如何保证拷贝完成时是一个一致性的点呢,这涉及到snapshot的概念,源库的一个snapshot就是一个一致性的状态点,拷贝源库的snapshot到目的数据目录就保证了目的数据目录具有源库的历史一致性状态。
clone snapshot
克隆snapshot是如何实现的呢?总的来说分为3步:
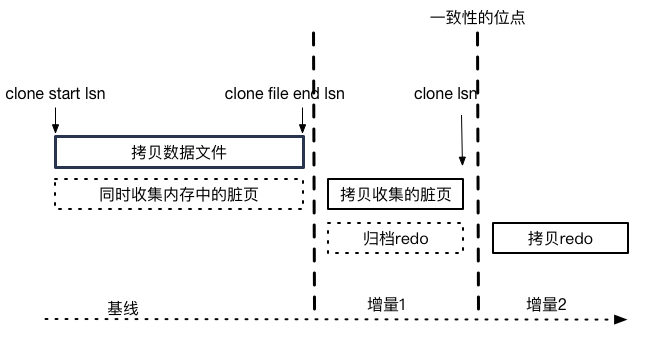
每一步的分界点都以lsn来区分 基线拷贝所有的文件(clone start lsn -> clone file end lsn) 增量1拷贝 clone start lsn到clone file end lsn之间搜集的脏页 增量2拷贝 clone file end lsn到clone lsn归档的redo
一致性原理: clone开始的时候所有已经flush的数据都通过文件拷贝了,而未flush的将被记录下来了 clone结束的时候: 到最近的checkpoint的脏页都被记录下来了,这些脏页应用到全量文件上就等价于最近的checkpoint,而checkpoint以后的增量通过拷贝归档redo来实现。这个截止点clone lsn(对应的binlog位点)就被完整的拷贝到了目的实例
snapshot因此被分成了如下几种状态:

实现snapshot必须实现脏页收集和redo归档 脏页收集: 脏页收集可以有两种方式:1. 在mtr 提交脏页时,2. i/o线程刷脏时。目前为了不影响mtr的并发选择了后者
一些关键点:
- 通过内存的队列去缓存修改的脏页和spaceid,page_id
- 不重复记录相同的spaceid,pageid
- 通过后台不停的追加写文件,防止内存撑爆
- 元信息不单独维护,文件名和头包括必要的信息
- 文件头中记录了开始和结束的lsn.
- 如果缓存满了会导致flushpage被阻塞,但是这种情况应该很少,
- 内存不足时会告警和停止收集脏页,同时会重启clone的流程
redo归档:
- 后台归档线程从checkpoint LSN开始归档redo 这个后台线程就是之前的脏页搜集线程
- 每次都按块从上次copy的lsn到最新的flush lsn把日志从redo file拷贝到archive file
- 拷贝的速度基本上要比redo生成的速度快,为了防止归档日志被覆盖,mtr在归档日志将要被覆盖时会柱塞mtr
- 归档日志通过lsn命名
- 提供如用户接口实现归档
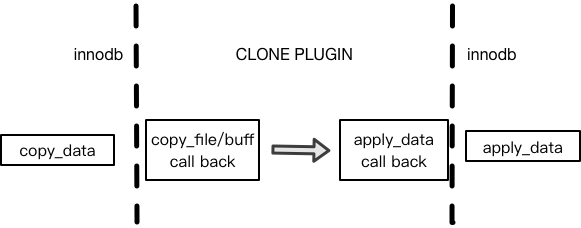
抽象接口
clone_copy 和 clone_apply,plugin通过调用这两组接口在源和目的之间拷贝文件和内存数据,从而实现拷贝完整的snapshot:
- copy_data:
clone_copy(locator[IN], callback_context[IN], ...) callback_context clone_file_cbk(from_file_descriptor[IN], copy_length[IN], ...) // 拷贝文件的回调 clone_buffer_cbk(from_data_buffer[IN], copy_length[IN], ...) // 拷贝脏页的回调 - apply_data:
clone_apply(locator[IN], callback_context[IN], ...)
clone_apply_file_cbk(to_file_descriptor[IN], copy_length[IN], ...) // 把copy的数据写到目的数据目录
接口调用示意图
远程克隆
语法:
CLONE INSTANCE FROM USER@HOST:PORT
IDENTIFIED BY ''
DATA DIRECTORY [=]''
[REQUIRE [NO] SSL];
克隆步骤:
- 创建空实例[mysqld–initialize]
- 启动目的实例
- 连接源实例
- 从源实例clone数据到目的实例
SQL > INSTALL PLUGIN CLONE SQL > CLONE REMOTE INSTANCE - 用在clone的数据目录上重启
具体实现:
远程克隆可以理解为将本地克隆的数据以流的方式发送到远端从而写入远端的目的数据目录完成克隆,具体流程如下图所示:
clone源和目的交互示意图
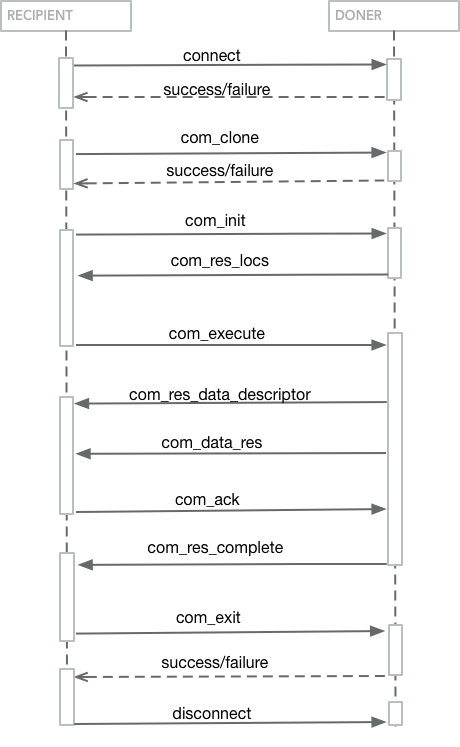
CLONE PROTOCOL说明:
- COM_INIT: 协商版本号,存储引擎发起clone操作,源端(DONER)的locater会返回给目的端(RECIPIENT),locater是一个innodb存储引擎内部表示snapshot状态的逻辑指针,协商版本号未来可以支持不同版本间的clone;
- COM_ATTACH: 新的slave线程和当前clone线程相关联,用于并发处理;
- COM_REINIT: 用于当出现类似网络错误时重启clone,clone主线程等待所有辅助线程退出后,会把stage/chunk/block信息发送给源端重新clone;
- COM_EXECUTE: 开始传输数据到客户端,源端流式的将snapshot通过网络发送到目的端,数据通过这个com的回包连续不断的发送; A. COM_RES_LOCS : 目的端发送给源端的locater信息; B. COM_RES_DATA_DESC :用于描述接下来数据包的描述符,第一部分是存储引擎在cloneplugin的位置,用于 clone plugin调用正确的存储引擎,第二部分就和具体的存储引擎相关,innodb有如下的内容: 1. State information 2. Task information 3. File metadata 4. Location next data block - file index and offset C. COM_RES_DATA :clone的原始数据; D. COM_RES_COMPLETE : 克隆成功完成; E. COM_RES_ERROR : 克隆报错退出,源端通过多次DESC+DATA直到snapshot发送完毕,然后发送一个 CLONE_COM_END表明结束;
- COM_ACK:用于目的端通知源端可以安全的切换snapshot状态了,它同时也可以用于目的端反馈给源端错误信息,因为COM_EXECUTE一直是源端发送数据到目的端;
- COM_EXIT: 退出plugin返回到普通的服务器协议;
关键类
这儿主要涉及remote clone:
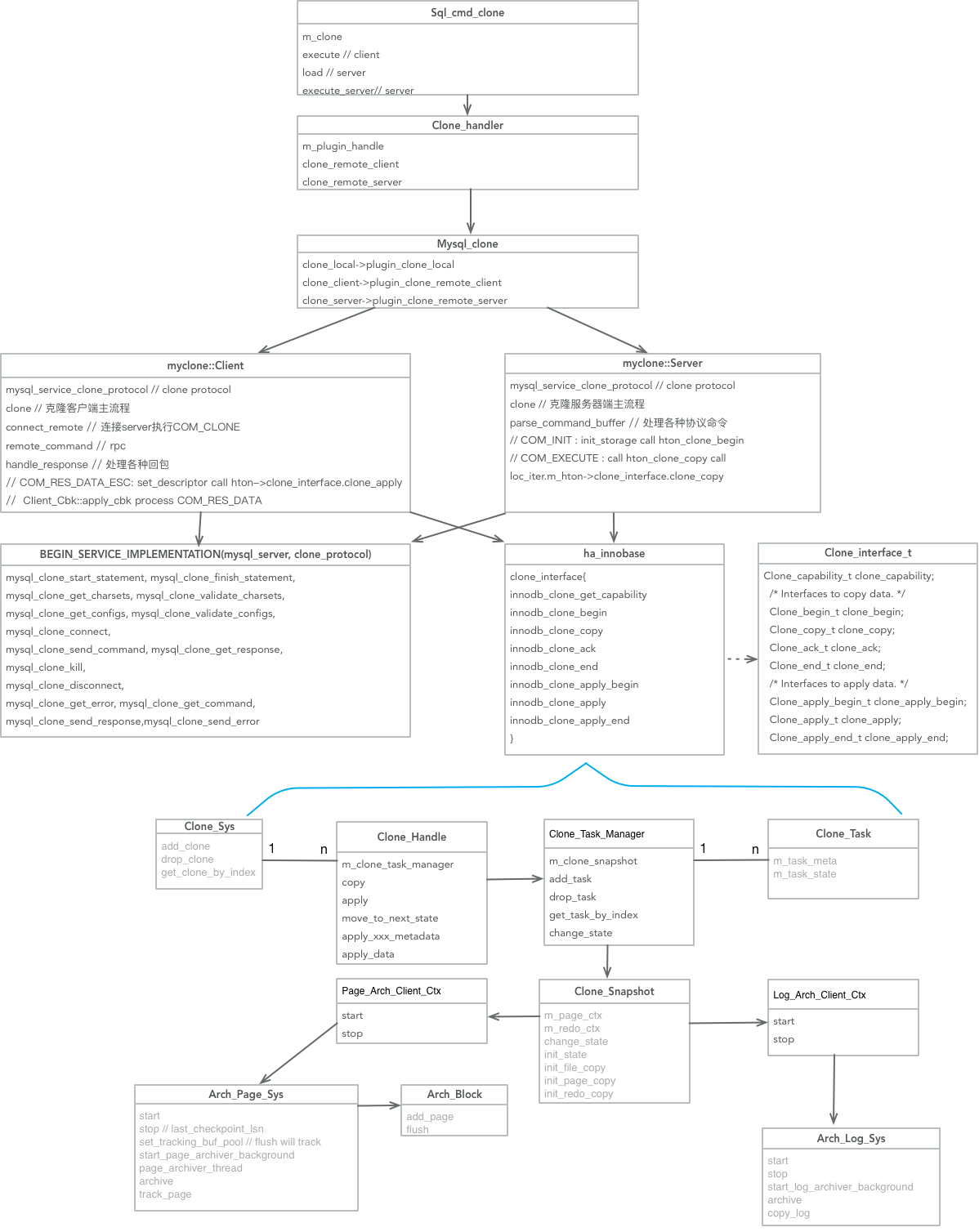
sql层:
- Sql_cmd_clone: 客户端处理sql(clone instance)和服务端处理COM_XXX命令
- Clone_handler和Mysql_clone:调用plugin的具体实现响应sql层处理
- myclone::Client: clone接收端的处理逻辑
- myclone::Server: 被clone端的处理逻辑
- clone_protocol: 定义的一组接口用于client和server rpc通信 6. Clone_interface_t: plugin调用的引擎层接口
- ha_innobase(clone_interface): innodb引擎实现的Clone_interface_t
innodb层:
- Clone_Sys:管理所有的Clone Handle
- Clone_Handle: 处理一次innodb clone请求(客户端和服务器端调用不同的接口)
- Clone_Task_Manager: 管理一个innodb clone请求的所有任务(多个task可以并行处理)
- Clone_Task: 标识一个任务
- Clone_Snapshot: 管理doner的一个一致性状态(见前文注释)
- Page_Arch_Client_Ctx, Arch_Page_sys, Arch_Block: 提供clone脏页搜集功能 7.Log_Arch_Client_Ctx, Arch_Log_Sys: 提供clone归档redo功能
主要逻辑
1. 发起克隆端(RECIPIENT/CLIENT)
用户发起clone instance 语法解析为SQLCOM_CLONE命令,同时构造出Sql_cmd_clone对象,在mysql_exeucte_command中执行,然后通过plugin_clone_init初始化和mysql_declare_plugin中的clone_descriptor设置的Mysql_clone对象调用plugin_clone_remote_client发起远端clone请求。
int mysql_execute_command(THD *thd, bool first_level) {
... ...
case SQLCOM_CLONE:
... ...
DBUG_ASSERT(lex->m_sql_cmd != nullptr);
res = lex->m_sql_cmd->execute(thd); // 调用Sql_cmd_clone::execute
break;
... ...
}
bool Sql_cmd_clone::execute(THD *thd) {
... ...
auto err = m_clone->clone_remote_client(// 调用Clone_handler::clone_remote_client
thd, m_host.str, static_cast<uint>(m_port), m_user.str, m_passwd.str,
m_data_dir.str, ssl_mode);
clone_plugin_unlock(thd, m_plugin);
m_clone = nullptr;
... ...
}
int Clone_handler::clone_remote_client(THD *thd, const char *remote_host,
uint remote_port,
const char *remote_user,
const char *remote_passwd,
const char *data_dir,
enum mysql_ssl_mode ssl_mode) {
... ...
error = m_plugin_handle->clone_client( // 调用plugin_clone_remote_client
thd, remote_host, remote_port, remote_user, remote_passwd, dir_ptr, mode);
... ...
}
plugin_clone_remote_client主要构造一个myclone::Client对象,然后调用它的clone方法,客户端协议主要就在这个方法中实现,它首先调用connect_remote 发送COM_CLONE命令给服务端表明要进行一次clone操作,然后通过remote_command执行其他的协议命令和处理服务器返回包。
static int plugin_clone_remote_client(THD *thd, const char *remote_host,
uint remote_port, const char *remote_user,
const char *remote_passwd,
const char *data_dir, int ssl_mode) {
... ...
myclone::Client clone_inst(thd, &client_share, 0, true);
error = clone_inst.clone(); // 调用 myclone::Client::clone
return (error);
}
// 客户端协议主流程 可以参见前文的说明
int Client::clone() {
... ...
do {
... ...
err = connect_remote(restart, false); // 连接服务端执行COM_CLONE命令
... ...
/* Make another auxiliary connection for ACK */
err = connect_remote(restart, true);
... ...
auto rpc_com = is_master() ? COM_INIT : COM_ATTACH;
... ...
/* Negotiate clone protocol and SE versions */
err = remote_command(rpc_com, false);// RPC主线程执行COM_INIT, 并发线程执行COM_ATTACH
... ...
/* Execute clone command */
if (err == 0) {
... ...
err = remote_command(COM_EXECUTE, false);// RPC执行拷贝命令
... ...
}
int Client::connect_remote(bool is_restart, bool use_aux) {
... ...
while (true) {
/* Connect to remote server and load clone protocol. */
m_conn = mysql_service_clone_protocol->mysql_clone_connect(// 调用协议实现mysql_clone_connect
m_server_thd, m_share->m_host, m_share->m_port, m_share->m_user,
m_share->m_passwd, &ssl_context, &conn_socket);
if (m_conn != nullptr) {
break;
}
... ...
}
DEFINE_METHOD(MYSQL *, mysql_clone_connect,
(THD * thd, const char *host, uint32_t port, const char *user,
const char *passwd, mysql_clone_ssl_context *ssl_ctx,
MYSQL_SOCKET *socket)) {
... ...
/* Load clone plugin in remote */
auto result = simple_command(mysql, COM_CLONE, nullptr, 0, 0); // 发送COM_CLONE给服务端
... ...
}
remote_command实际调用定义的一组协议接口clone_protocol发送命令等,协议服务的定义见宏BEGIN_SERVICE_IMPLEMENTATION(mysql_server, clone_protocol), 然后处理服务器返回的协议包, 比如处理COM_RES_DATA_DESC和COM_RES_DATA时调用引擎的clone_apply接口把数据写入。innodb引擎对应innodb_clone_apply,后面会详细介绍:
// 客户端RPC实现
int Client::remote_command(Command_RPC com, bool use_aux) {
... ...
/* Send remote command */
err = mysql_service_clone_protocol->mysql_clone_send_command(//调用协议发送命令
get_thd(), conn, !use_aux, command, m_cmd_buff.m_buffer, cmd_buff_len);
if (err != 0) {
return (err);
}
/* Receive response from remote server */
err = receive_response(com, use_aux); // 处理回包
... ..
}
int Client::receive_response(Command_RPC com, bool use_aux) {
... ...
err = handle_response(packet, length, saved_err, skip_apply, last_packet);
... ...
}
int Client::handle_response(const uchar *packet, size_t length, int in_err,
bool skip_loc, bool &is_last) {
switch (res_com) { //每个包的含义可以参见前文的说明
... ...
case COM_RES_DATA_DESC:
/* Skip processing data in case of an error till last */
if (in_err == 0) {
err = set_descriptor(packet, length); // 处理元信息包
}
break;
... ...
case COM_RES_DATA: // 数据包交给apply处理
/* Allow data packet to skip */
if (in_err != 0) {
break;
}
... ...
}
int Client::set_descriptor(const uchar *buffer, size_t length) {
... ...
Ha_clone_cbk *clone_callback = new Client_Cbk(this);
... ...
// 调用引擎层clone_apply把clone数据写到文件
err = hton->clone_interface.clone_apply(loc->m_hton, get_thd(), loc->m_loc,
loc->m_loc_len, m_tasks[loc_index], 0,
clone_callback);
... ...
}
2. 被克隆端(DONER/SERVER)
服务器端在收到COM_CLONE请求后首先构造一个Sql_cmd_clone, 同时执行它的execute_server。和客户端类似它最终会调用clone plugin初始化决定的plugin_clone_remote_server处理服务器端的逻辑。
bool dispatch_command(THD *thd, const COM_DATA *com_data,
enum enum_server_command command) {
... ...
case COM_CLONE: {// 执行COM_CLONE命令初始化 clone_cmd
thd->status_var.com_other++;
/* Try loading clone plugin */
clone_cmd = new (thd->mem_root) Sql_cmd_clone();
... ...
/* After sending response, switch to clone protocol */
if (clone_cmd != nullptr) {
DBUG_ASSERT(command == COM_CLONE);
error = clone_cmd->execute_server(thd); // 调用Sql_cmd_clone::execute_server
}
}
bool Sql_cmd_clone::execute_server(THD *thd) {
... ...
auto err = m_clone->clone_remote_server(thd, sock);// 调用Clone_handler::clone_remote_server
... ...
}
int Clone_handler::clone_remote_server(THD *thd, MYSQL_SOCKET socket) {
auto err = m_plugin_handle->clone_server(thd, socket); //调用plugin_clone_remote_server
return err;
}
plugin_clone_remote_server首先构造一个myclone::Server的对象,服务端的主要逻辑就在它的clone接口中实现,clone接口同样调用协议服务接收命令然后根据命令类型做相应的处理,比如是客户端发送的COM_EXECUTE命令,它就找到对应的locater然后调用locater关联的引擎clone_copy接口拷贝数据,innodb引擎就调用innodb_clone_copy,具体逻辑见后面的介绍。
tatic int plugin_clone_remote_server(THD *thd, MYSQL_SOCKET socket) {
myclone::Server clone_inst(thd, socket);
auto err = clone_inst.clone(); // myclone::Server::clone 服务器端主逻辑
return (err);
}
int Server::clone() {
int err = 0;
while (true) {
... ...
// 协议层接收命令,定义DEFINE_METHOD(MYSQL *, mysql_clone_get_command ...
err = mysql_service_clone_protocol->mysql_clone_get_command(
get_thd(), &command, &com_buf, &com_len);
... ...
if (err == 0) {
err = parse_command_buffer(command, com_buf, com_len, done);// 处理命令
}
... ...
}
// 服务器端处理COM_XXX逻辑,见前文具体说明
int Server::parse_command_buffer(uchar command, uchar *com_buf, size_t com_len,
bool &done) {
... ...
case COM_EXECUTE: {
... ...
Server_Cbk clone_callback(this);
// 调用引擎层clone_copy拷贝snapshot
err = hton_clone_copy(get_thd(), get_storage_vector(), m_tasks,
... ...
}
... ...
}
int hton_clone_copy(THD *thd, Storage_Vector &clone_loc_vec,
Task_Vector &task_vec, Ha_clone_cbk *clone_cbk) {
uint index = 0;
for (auto &loc_iter : clone_loc_vec) {
DBUG_ASSERT(index < task_vec.size());
clone_cbk->set_loc_index(index);
// 如果是innodb, 调用innodb_clone_copy接口进行数据拷贝
auto err = loc_iter.m_hton->clone_interface.clone_copy(
loc_iter.m_hton, thd, loc_iter.m_loc, loc_iter.m_loc_len,
task_vec[index], clone_cbk);
if (err != 0) {
return (err);
}
index++;
}
return (0);
}
3.innodb层copy
innodb层copy先在Clone_Sys中找到对应的任务Clone_Handle(可能不止一个clone任务), 然后调用Clone_Handle的copy接口进行具体的拷贝,拷贝与它绑定的Clone_Snapshot直到CLONE_SNAPSHOT_DONE,通过move_to_next_state驱动Clone_Snapshot切换状态拷贝不同的数据。
int innodb_clone_copy(handlerton *hton, THD *thd, const byte *loc, uint loc_len,
uint task_id, Ha_clone_cbk *cbk) {
cbk->set_hton(hton);
/* Get clone handle by locator index. */
auto clone_hdl = clone_sys->get_clone_by_index(loc, loc_len);
auto err = clone_hdl->check_error(thd);
if (err != 0) {
return (err);
}
/* Start data copy. */
err = clone_hdl->copy(thd, task_id, cbk); // 调用 Clone_Handle::copy进行拷贝
clone_hdl->save_error(err);
return (err);
}
// copy snapshot的几种状态直到DONE
int Clone_Handle::copy(THD *thd, uint task_id, Ha_clone_cbk *callback) {
... ...
/* Adjust block size based on client buffer size. */
auto snapshot = m_clone_task_manager.get_snapshot(); // 获取snapshot
while (m_clone_task_manager.get_state() != CLONE_SNAPSHOT_DONE) {
... ...
/* Send blocks from the reserved chunk. */
err = process_chunk(task, current_chunk, current_block, callback);
... ...
/* Next state is decided by snapshot for Copy. */
err = move_to_next_state(task, callback, nullptr); // 切换snapshot状态
... ...
}
}
状态切换实际在Clone_Snapshot::change_state中进行,根据不同的目标状态Clone_Snapshot做相应的初始化: 比如CLONE_SNAPSHOT_FILE_COPY阶段要打开脏页收集,查找要copy的文件,具体文件拷贝的细节请查看源码,这儿就不在赘述。CLONE_SNAPSHOT_PAGE_COPY需要开始redo归档和搜集要发送的脏页等。
int Clone_Handle::move_to_next_state(Clone_Task *task, Ha_clone_cbk *callback,
Clone_Desc_State *state_desc) {
... ...
// 调用 Clone_Task_Manager::change_state
auto err = m_clone_task_manager.change_state(task, state_desc, next_state,
alert_callback, num_wait);
... ...
}
nt Clone_Task_Manager::change_state(Clone_Task *task,
Clone_Desc_State *state_desc,
Snapshot_State new_state,
Clone_Alert_Func cbk, uint &num_wait) {
... ...
// 调用 Clone_Snapshot::change_state
err = m_clone_snapshot->change_state(
state_desc, m_next_state, task->m_current_buffer,
task->m_buffer_alloc_len, cbk, num_pending);
... ...
}
int Clone_Snapshot::change_state(Clone_Desc_State *state_desc,
Snapshot_State new_state, byte *temp_buffer,
uint temp_buffer_len, Clone_Alert_Func cbk,
uint &pending_clones) {
... ...
/* Initialize the new state. */
auto err = init_state(state_desc, temp_buffer, temp_buffer_len, cbk);
... ...
}
int Clone_Snapshot::init_state(Clone_Desc_State *state_desc, byte *temp_buffer,
uint temp_buffer_len, Clone_Alert_Func cbk) {
... ...
// snapshot的切换状态,file_copy page_copy redo_copy
switch (m_snapshot_state) {
... ...
case CLONE_SNAPSHOT_FILE_COPY:
err = init_file_copy();
m_monitor.change_phase();
... ...
case CLONE_SNAPSHOT_PAGE_COPY:
err = init_page_copy(temp_buffer, temp_buffer_len);
m_monitor.change_phase();
... ...
case CLONE_SNAPSHOT_REDO_COPY:
err = init_redo_copy(cbk);
m_monitor.change_phase();
... ...
}
int Clone_Snapshot::init_file_copy() {
... ...
/* Start modified Page ID Archiving */
err = m_page_ctx.start(false, nullptr); // 开启脏页收集
/* Iterate all tablespace files and add persistent data files. */
auto error = Fil_iterator::for_each_file( // 要copy的文件
include_log, [&](fil_node_t *file) { return (add_node(file)); });
... ...
}
int Clone_Snapshot::init_page_copy(byte *page_buffer, uint page_buffer_len) {
... ...
/* Start Redo Archiving */
err = m_redo_ctx.start(m_redo_header, m_redo_header_size); // 开始归档redolog
... ...
/* Stop modified page archiving. */
err = m_page_ctx.stop(nullptr);
... ...
// 获取要发送的pages
err = m_page_ctx.get_pages(add_page_callback, context, page_buffer,
page_buffer_len);
... ...
}
int Clone_Snapshot::init_redo_copy(Clone_Alert_Func cbk) {
... ...
/* Stop redo archiving even on error. */
auto redo_error = m_redo_ctx.stop(m_redo_trailer, m_redo_trailer_size,
m_redo_trailer_offset); // 停止归档redo
... ...
redo_error = m_redo_ctx.get_files(add_redo_file_callback, context);
... ...
}
4.innodb层apply
apply的主要工作就是接收服务器端发送的数据写到对应的文件里,它同样也是先根据index找到对应的Clone_Handle, 然后Clone_Handle根据具体的服务器回包类型做相应的处理,根据meta信息做好写数据的准备, 把CLONE_DESC_DATA数据接收然后写入文件
int innodb_clone_apply(handlerton *hton, THD *thd, const byte *loc,
uint loc_len, uint task_id, int in_err,
Ha_clone_cbk *cbk) {
... ...
/* Apply data received from callback. */
err = clone_hdl->apply(thd, task_id, cbk);
... ...
}
int Clone_Handle::apply(THD *thd, uint task_id, Ha_clone_cbk *callback) {
... ...
switch (header.m_type) {
case CLONE_DESC_TASK_METADATA:
err = apply_task_metadata(task, callback);
break;
case CLONE_DESC_STATE:
err = apply_state_metadata(task, callback);
break;
case CLONE_DESC_FILE_METADATA:
err = apply_file_metadata(task, callback);
break;
case CLONE_DESC_DATA:
err = apply_data(task, callback); // apply具体数据
break;
default:
ut_ad(false);
break;
}
}
int Clone_Handle::apply_data(Clone_Task *task, Ha_clone_cbk *callback) {
... ...
/* Receive data from callback and apply. */
err = receive_data(task, data_desc.m_file_offset, data_desc.m_file_size,
data_desc.m_data_len, callback);
... ...
}
5. 脏页收集
在Clone_Snapshot FILE_COPY状态的准备阶段会调用Page_Arch_Client_Ctx::start开启脏页收集,主要获取当前在线redo日志的lsn然后告诉buffer pool可以开始进行脏页的收集了,同时还要开启一个后台线程把内存收集的脏页在写满的情况下append到文件。
// Clone_Snapshot调用脏页收集客户端接口
int Page_Arch_Client_Ctx::start(bool recovery, uint64_t *start_id) {
... ...
/* Start archiving. */
err = arch_page_sys->start(&m_group, &m_last_reset_lsn, &m_start_pos,
m_is_durable, reset, recovery);
... ...
}
int Arch_Page_Sys::start(Arch_Group **group, lsn_t *start_lsn,
Arch_Page_Pos *start_pos, bool is_durable,
bool restart, bool recovery) {
... ...
// 收集开始lsn时在线日志当前最新分配的lsn
log_sys_lsn = (recovery ? m_last_lsn : log_get_lsn(*log_sys));
/* Enable/Reset buffer pool page tracking. */
set_tracking_buf_pool(log_sys_lsn); // 告诉刷脏开始统计sp_id,page_id
... ...
auto err = start_page_archiver_background(); // 开启后台线程归档收集的sp_id, page_id
... ...
if (!recovery) {
/* Request checkpoint */
log_request_checkpoint(*log_sys, true); // 保证归档结束一定有个checkpoint
}
}
后台刷脏在判断track_page_lsn设置的情况下就会调用Arch_Page_Sys::track_page接口进行脏页收集,记录脏页的space_id和page_id,结束的lsn为最近的一次checkpoint的LSN,归档redo从这个LSN开始。
// 在刷脏过程中收集
ibool buf_flush_page(buf_pool_t *buf_pool, buf_page_t *bpage,
buf_flush_t flush_type, bool sync) {
... ...
if (!fsp_is_system_temporary(bpage->id.space()) &&
buf_pool->track_page_lsn != LSN_MAX) { // start 设置了start_lsn
... ...
frame_lsn = mach_read_from_8(frame + FIL_PAGE_LSN); // 为了过滤重复的id
// 调用Arch_Page_Sys::track_page
arch_page_sys->track_page(bpage, buf_pool->track_page_lsn, frame_lsn,
false);
}
... ....
}
void Arch_Page_Sys::track_page(buf_page_t *bpage, lsn_t track_lsn,
lsn_t frame_lsn, bool force) {
... ...
if (!force) { // 去重逻辑
/* If the frame LSN is bigger than track LSN, it
is already added to tracking list. */
if (frame_lsn > track_lsn) {
return;
}
}
... ...
// 调用Arch_Block::add_page搜集 收集space_id, page_id
if (!cur_blk->add_page(bpage, &m_write_pos)) {
/* Should always succeed. */
ut_ad(false);
}
... ...
}
// 由start start_page_archiver_background 开启的后台线程
/** Archiver background thread */
void page_archiver_thread() {
... ...
while (true) {
... ...
/* Archive in memory data blocks to disk. */
page_abort = arch_page_sys->archive(&page_wait); // 归档内存中的ids
... ...
}
bool Arch_Page_Sys::archive(bool *wait) {
... ...
db_err = flush_blocks(wait);
... ...
}
dberr_t Arch_Page_Sys::flush_blocks(bool *wait) {
... ...
err = flush_inactive_blocks(cur_pos, end_pos);
... ...
}
dberr_t Arch_Page_Sys::flush_inactive_blocks(Arch_Page_Pos &cur_pos,
Arch_Page_Pos end_pos) {
... ...
while (cur_pos.m_block_num < end_pos.m_block_num) {
... ...
// 调用 Arch_Block::flush
err = cur_blk->flush(m_current_group, ARCH_FLUSH_NORMAL);
... ...
}
}
// 结束收集
int Arch_Page_Sys::stop(Arch_Group *group, lsn_t *stop_lsn,
Arch_Page_Pos *stop_pos, bool is_durable) {
... ...
*stop_lsn = m_latest_stop_lsn; // 最近一次checkpoint的LSN
... ...
}
6.归档redo
Clone_Snapshot在拷贝脏页的准备阶段开启redo归档,它主要的工作就是开启一个后台线程,从最近的一个Checkpoint的LSN开始拷贝线上redo到归档文件,一直到脏页拷贝完。
// Clone_Snapshot 归档REDO时调用
int Log_Arch_Client_Ctx::start(byte *header, uint len) {
... ...
auto err = arch_log_sys->start(m_group, m_begin_lsn, header, false);
... ...
}
int Arch_Log_Sys::start(Arch_Group *&group, lsn_t &start_lsn, byte *header,
bool is_durable) {
... ...
auto err = start_log_archiver_background(); // 开启归档后台线程
start_lsn = log_sys->last_checkpoint_lsn; // 开始为上一个Checkpoint lsn
... ...
}
/** Archiver background thread */
void log_archiver_thread() {
... ...
while (true) {
/* Archive available redo log data. */
log_abort = arch_log_sys->archive(log_init, &log_file_ctx, &log_arch_lsn,
&log_wait);
... ...
}
}
bool Arch_Log_Sys::archive(bool init, Arch_File_Ctx *curr_ctx, lsn_t *arch_lsn,
bool *wait) {
... ...
/* Copy data from system redo log files to archiver files */
err = copy_log(curr_ctx, arch_len);
... ...
}
dberr_t Arch_Log_Sys::copy_log(Arch_File_Ctx *file_ctx, uint length) {
... ...
/* Copy log data into one or more files in archiver group. */
while (length > 0) {
... ...
err =
curr_group->write_to_file(file_ctx, nullptr, write_size, false, false);
... ...
}
int Arch_Log_Sys::stop(Arch_Group *group, lsn_t &stop_lsn, byte *log_blk,
uint32_t &blk_len) {
... ...
// 最新的lsn
if (log_blk == nullptr) {
... ...
stop_lsn = m_archived_lsn.load();
} else {
/* Get the current LSN and trailer block. */
log_buffer_get_last_block(*log_sys, stop_lsn, log_blk, blk_len);
... ...
}
... ...
}
参考
https://dev.mysql.com/worklog/task/?id=9209 https://dev.mysql.com/worklog/task/?id=9210 https://dev.mysql.com/worklog/task/?id=9211 https://dev.mysql.com/worklog/task/?id=11636 https://dev.mysql.com/worklog/task/?id=12827 https://mysqlserverteam.com/clone-create-mysql-instance-replica/