MySQL · 引擎特性 · ROLLUP 功能用法和实现
Author: 泊歌
在数据库查询语句中,在 GROUP BY 表达式之后加上 WITH ROLLUP 语句,可以在查询结果中包含更多高层级的统计输出。ROLLUP 功能使得可以通过单个查询语句来实现对数据进行不同层级上的分析与统计。因此,ROLLUP 功能能够很好得为 OLAP(Online Analytical Processing) 任务提供支持。
在本篇文章中,将会对 ROLLUP 的功能、用法、使用场景进行介绍并给出示例。也会从内核层面对 ROLLUP 的实现原理和方式进行阐述,包括逻辑过程与数据结构。
1 功能介绍
假如有一个 sales 表有 year, country, product 和 profit 四列,其中 profit 列为某年份某个国家的某种产品的一条收益。数据表的创建语句如下:
CREATE TABLE sales
(
year INT,
country VARCHAR(20),
product VARCHAR(32),
profit INT
);
为了方便演示,在数据表中插入如下数据:
INSERT INTO sales (year, country, product, profit) VALUES
(2000, 'Finland', 'Computer', 500),
(2000, 'Finland', 'Computer', 1000),
(2000, 'India', 'Calculator', 150),
(2000, 'India', 'Computer', 400),
(2000, 'Finland', 'Phone', 100),
(2001, 'USA', 'Calculator', 50),
(2001, 'USA', 'Computer', 2700),
(2001, 'USA', 'TV', 1),
(2000, 'India', 'Computer', 300),
(2000, 'India', 'Computer', 500),
(2000, 'USA', 'Calculator', 75),
(2000, 'USA', 'Computer', 1500),
(2001, 'USA', 'TV', 249),
(2001, 'Finland', 'Phone', 10);
我们经常需要使用如下查询语句对某年份某个国家的某种产品的总收益进行汇总:
SELECT year, country, product, SUM(profit) AS profit
FROM sales
GROUP BY year, country, product;
查询结果为:
+------+---------+------------+--------+
| year | country | product | profit |
+------+---------+------------+--------+
| 2000 | Finland | Computer | 1500 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | Finland | Phone | 100 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2001 | Finland | Phone | 10 |
+------+---------+------------+--------+
通常情况下,我们不光需要这种最高层次的统计结果,也需要在更低的层次进行分析。比如说,某年份某个国家在所有产品的收益总和,或者某年份所有国家的收益总和。为了达到这样的效果,我们可能需要对 Group By List 中的属性列进行调整,并重新执行查询语句得到我们需要的结果。但是 ROLLUP 功能使得我们可以仅通过一条查询语句实现上述效果:
SELECT year, country, product, SUM(profit) AS profit
FROM sales
GROUP BY year, country, product WITH ROLLUP;
查询结果为:
+------+---------+------------+--------+
| year | country | product | profit |
+------+---------+------------+--------+
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | Finland | NULL | 1600 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | India | NULL | 1350 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2000 | USA | NULL | 1575 |
| 2000 | NULL | NULL | 4525 |
| 2001 | Finland | Phone | 10 |
| 2001 | Finland | NULL | 10 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
| 2001 | USA | NULL | 3000 |
| 2001 | NULL | NULL | 3010 |
| NULL | NULL | NULL | 7535 |
+------+---------+------------+--------+
查询结果中的 NULL 值表示该行输出为更低层次上的聚合结果,在带 WITH ROLLUP 的聚合时,每当 GROUP BY 的属性列(非最后一列)的值发生变化时,查询结果中都会产生额外的聚合行。
因此,借助 ROLLUP,我们通过一条查询语句就能够得到 GROUP BY 的属性列在不同层次上的聚合结果。适用于需要在不同层次上对数据进行统计分析的场景,不仅省去了写多条查询语句重复查询的麻烦,而且提升了执行效果。
以上是 ROLLUP 的功能、用法、使用场景介绍的部分,接下来将会对 ROLLUP 的内核实现进行介绍,分为优化器和执行器两部分。
2 内核实现
2.1 优化器
2.1.1 开辟内存空间
优化器在优化阶段针对 ROLLUP 做的操作首先是为 ROLLUP 所需要的数据结构开辟内存空间(JOIN::optimize_rollup)。
由于 ROLLUP 需要对 GROUP BY 的属性列,按照不同层级进行聚合,那么假设有一条语句是 GROUP BY year, country, product WITH ROLLUP,那么输出的 ROLLUP 结果行应包含以下3种:
| year | country | product | Sum_func |
|---|---|---|---|
| NULL | NULL | NULL | … |
| 2000 | NULL | NULL | … |
| 2000 | Finland | NULL | … |
因此,为了方便在每读入一条数据时,能直接在不同层级上进行聚合,优化器会提前分配所有层级所需要的内存空间(Item List)。Item List 的条数与不同层级数、GROUP BY 的属性列数相同(send_group_parts)。
2.1.2 初始化数据结构
优化器对 ROLLUP 第二个阶段的操作是对数据结构进行初始化(JOIN::rollup_make_fields),对 ROLLUP 输出的聚合列指向用于表示 ROLLUP 聚合的 Item(Item_null_result),非聚合列对应的 Item 进行拷贝。
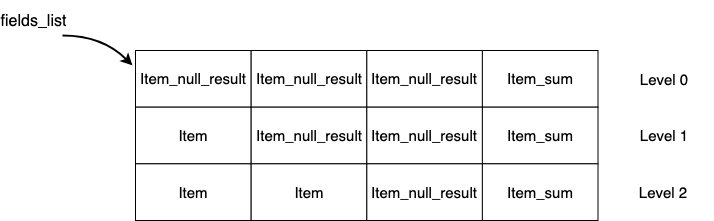
同时也对聚合函数的 Item(Item::SUM_FUNC_ITEM)进行拷贝,通过 sum_funcs 和 sum_funcs_end 的指向,来判断每读入一条数据时需要在哪些 Item_sum 上进行累积。

这样的内存设计可以方便在执行阶段,通过一条数据在 GROUP BY 列表中发生变化的最小层级列对应的下标来判断哪些 Item_sum 需要重置,剩下的 Item_sum 需要累积。也可以判断哪些 Level 已经统计完成,可以返回结果。
2.2 执行器
MySQL 中对 ROLLUP 的实现依赖于 Filesort,因此执行器依次读入的数据在 GROUP BY 列表上的属性是严格有序的。通过 List<Cached_item> group_fields 来缓存上一组的数据结果,新读入的数据与缓存数据进行比较,判断新读入的数据与缓存数据在 GROUP BY 属性列表上发生变化的最小层级,用 idx 表示。
如果 idx = -1,说明当前数据与缓存数据属于同一组,那么直接将当前组和所有 ROLLUP 层级的聚合函数进行累积(update_sum_func)。
如果 idx >= 0,说明当前数据与前一组数据在某些 GROUP BY 属性列的属性值发生了变化,idx 的具体值表示发生变化的分组最高属性列。比如有一条语句是:
SELECT year, country, product, SUM(profit) AS profit
FROM sales
GROUP BY year, country, product WITH ROLLUP;
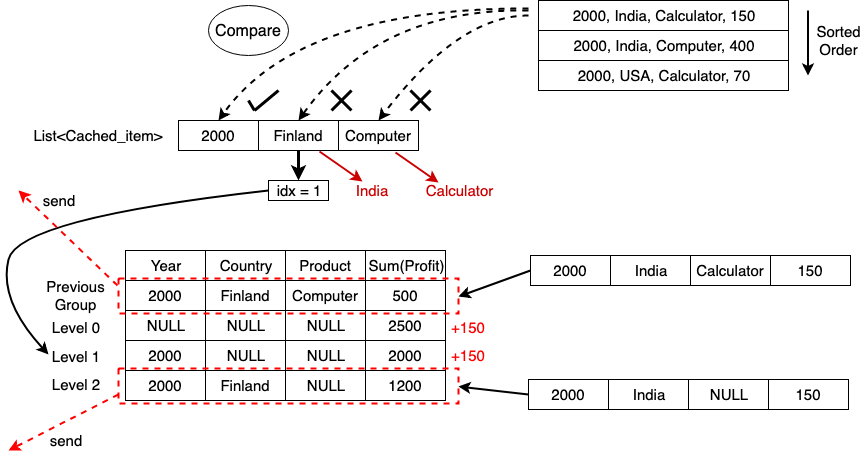
如果新的一条数据仅在 product 属性上发生变化,那么 idx = 2;如果在 country 属性上发生变化,那么 idx = 1。
在这种情况下,前一个组的聚合信息已经统计完成,执行器会更新缓存值(update_item_cache_if_changed),同时将这个组的结果输出。然后根据 idx 的值判断哪些 ROLLUP 层级的统计完成,将所有层级高于当前行的结果返回(JOIN::rollup_send_data)或者写入临时表(JOIN::rollup_write_data)。
然后对新的组拷贝 Item(copy_fields),对新的组和 ROLLUP 中高于当前层级的 Item_sum 进行重置和累积,对低于当前层级的 Item_sum 进行累积(init_sum_functions)。依此类推,直到读入全部数据。
总的来说,ROLLUP 的逻辑过程比较清楚,是通过顺序遍历排好序的数据,依次将其与之前缓存的上一组的属性列进行比较,判断之前组和 ROLLUP 层级的统计数据是否可以返回,并对新的组和低于当前层级的 ROLLUP 进行累积。
3 相关函数
-
JOIN::alloc_func_list 分配一组指向 sum_func 的指针来加速 sum_func 的计算过程。
-
JOIN::make_sum_func_list 使用 item_sum 对象初始化 sum_func 的数组。
-
JOIN::rollup_process_const_fields 将 group by 列表中的常数 item 进行封装。
-
JOIN::rollup_make_fields 用指向 field 的指针来填充 rollup 的数据结构。
-
JOIN::switch_slice_for_rollup_fields 为 rollup 结构切换 ref_items 的片。
-
JOIN::optimize_rollup 优化 rollup 过程,分配 rollup 处理过程中所需的对象。
-
ROLLUP rollup 基本数据结构。
-
JOIN::rollup_send_data 将 rollup 级别高于当前的发送到客户端。
-
JOIN::rollup_write_data 将 rollup 级别高于当前的写入临时表。
-
has_rollup_result 检查一个 item 是否包含 rollup 的 NULL 值,需要被写入临时表。
-
SELECT_LEX::resolve_rollup 解析 rollup 过程中的 items。
4 参考资料
注:以上测试结果和内核介绍基于 MySQL 8.0.16。