MongoDB · 最佳实践 · 哈希分片为什么分布不均匀
Author: linqing
今天接到一个用户反馈的问题,sharding集群,使用wiredtiger引擎,某个DB下集合全部用的hash分片,show dbs 发现其中一个shard里该DB的大小,跟其他的集合差别很大,其他基本在60G左右,而这个shard在200G左右?
由于这个DB下有大量的集合及索引,一眼也看不出问题,写了个脚本分析了一下,得到如下结论
- somedb 下所有集合都是hash分片,并且chunk的分布是比较均匀的
- show dbs 反应的是集合及索引对应的物理文件大小
- 集合的数据在各个shard上逻辑总大小是接近的,只有shard0占用的物理空间比其他大很多
从shard0上能找到大量 moveChunk 的记录,猜测应该是集合的数据在没有开启分片的情况下写到shard0了,然后开启分片后,从shard0迁移到其他shard了,跟用户确认的确有一批集合是最开始没有分片。
所以这个问题就转换成了,为什么复制集里集合的逻辑空间与物理空间不一致?即collection stat 里 size 与 storageSize 的区别。
mymongo:PRIMARY> db.coll.stats()
{
"ns" : "test.coll",
"size" : 30526664,
"count" : 500808,
"avgObjSize" : 33,
"storageSize" : 19521536,
"capped" : false,
....
}
逻辑存储空间与物理存储空间有差距的主要原因
- 存储引擎存储时,需要记录一些额外的元数据信息,这会导致物理空间总和比逻辑空间略大
- 存储引擎可能支持数据压缩,逻辑的数据块存储到磁盘时,经过压缩可能比逻辑数据小很多了(具体要看数据的特性,极端情况下压缩后数据变大也是有可能的)
- 引擎对删除空间的处理,很多存储引擎在删除数据时,考虑到效率,都不会立即去挪动数据回收删除的存储空间,这样可能导致删除很多文档后,逻辑空间变小,但物理空间并没有变小。如下图所示,灰色的文档删除表示被删除。删除的空间产生很多存储碎片,这些碎片空间不会立即被回收,但有新文档写入时,可以立即被复用。
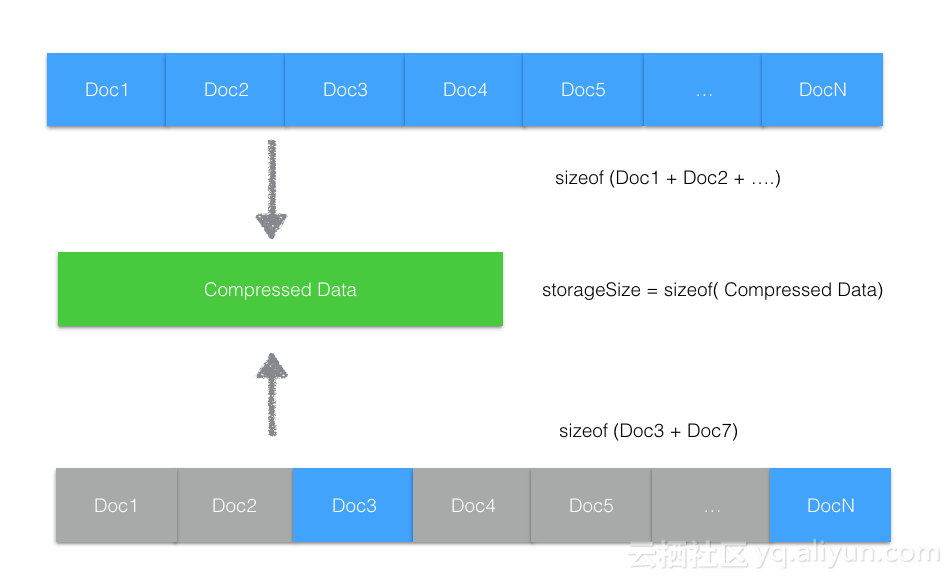
而上述case里,集合数据先分到一个shard,然后启用分片后,迁移一部分到其他shard,就是一个典型的产生大量存储碎片的例子。存储碎片对服务通常影响不大,但如果因为空间不够用了需要回收,如何去强制的回收这些碎片空间?
- 数据清理掉重新加入复制集同步数据,或者直接执行resync命令 (确保有还有其他的数据备份)
- 对集合调用 compact 命令