MySQL · 最佳实践 · 今天你并行了吗?---洞察PolarDB 8.0之并行查询
Author: jijunxiang
前言
今天你并行了吗?在PolarDB 8.0中,我们领先MySQL官方版本,率先支持了SQL的并行执行,充分利用硬件多核多CPU的优势,大幅提高了类OLAP的查询性能,体现了自研PolarDB数据库极高的性价比。
如何深入分析SQL的并行执行情况,以协助DBA解决可能存在的性能瓶颈,是一个迫在眉睫的问题,因此PolarDB 8.0在Performance Schema中添加了对并行查询的支持,可以帮助DBA洞察并行执行过程中的各种情况,为后续的查询优化提供丰富的情报。下面我们就详细了解一下并行查询的分析过程。
准备工作
打开并行查询
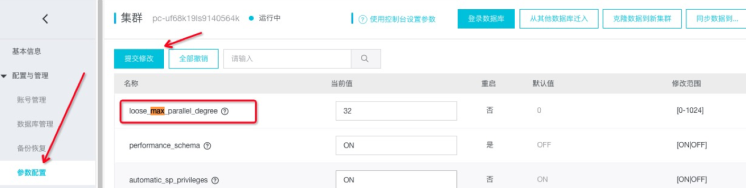
- 若是等于0,意味着关闭并行模式。
- 当max_parallel_degree大于0时,表示允许最多有多少个worker参与并行执行, 建议设置为实例cpu 核数的一半。比如对于8core32g 的实例, 建议设置为4, 对于16core128g的实例,建议设置为8, 对于2核或4核的实例, 建议关掉并行查询功能。
打开performance_schema
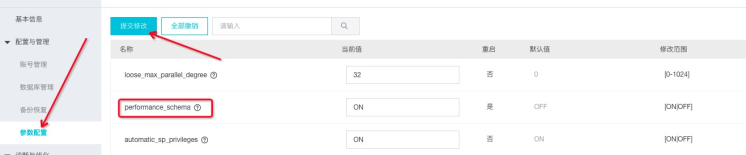
注意: 打开performance_schema 需要重启实例, 因此用户请在合适时间进行设置
开启并行查询相关的消费者consumer
后续操作都是由实例的超级用户,或者库performance_schema 已经授权给当前用户
update performance_schema.setup_consumers
set ENABLED= 'YES'
where name like 'events_parallel_query_current' ;
update performance_schema.setup_consumers
set ENABLED= 'YES'
where name like 'events_parallel_operator_current' ;
update performance_schema.setup_consumers
set ENABLED= 'YES'
where name like 'events_parallel_query_history' ;
update performance_schema.setup_consumers
set ENABLED= 'YES'
where name like 'events_parallel_operator_history' ;
启动时自动开启对并行查询相关事件的监测。
在my.cnf中添加以下行:
performance-schema-instrument='parallel_query%=ON'
性能分析
(1)检测是否并行
当出现性能问题时,首先我们要确定查询是否真的是并行执行。虽然通过查看执行计划,我们可以看到执行计划是并行的执行计划,但这并不意味着在执行时一定会并行执行,不能并行执行的原因通常是资源不足,CPU、内存、线程等资源的限制都要求我们不能无限制的并行。如果并行不受限制的执行,可能会导致一个并行查询就耗光了所有的资源,从而导致其它所有任务都被堵塞,可用性也受到极大影响。
因此针对这个问题,系统提供了一个参数max_parallel_workers来限制同时执行的并行数量。max_parallel_workers指在同一时刻用于并行执行的worker线程的最大数目(系统硬性设置为实例cpu数的4倍)。当超过max_parallel_workers时,之后就不会再产生并行执行计划,即使这些查询的执行计划中并行执行计划最优。
我们不能实时的去查询每个执行计划,因此当查询执行完成后,需要一些方法去确定刚刚执行完成的查询是否以并行方式执行。在performance schema中的events_statements_current/events_statements_history可以查看某条查询是否以并行方式执行。
如果发现当前情况下, 原本预期应该是并行的查询,但变成非并行查询, 需要进一步分析
- 运行的SQL 是否可以并行, 查询并行查询文档,检查 “并行查询的限制” 一节, 比如当前表记录数小于20000行,无法满足并行查询
- 检查当前系统负荷是否比较重, 如果当前系统负荷,比如内存利用率已经接近实例上限或cpu负荷较重时,会退化为非并行查询。
查询当前连接的内部thread_id:
select thread_id from performance_schema.threads where processlist_id=connection_id();
然后执行以下SQL:
select th.thread_id,
processlist_id,
SQL_TEXT,
PARALLEL
from performance_schema.events_statements_history stmth,
performance_schema.threads th
where stmth.thread_id= th.thread_id
order by PARALLEL desc;
下图是在控制台dms上的输出结果
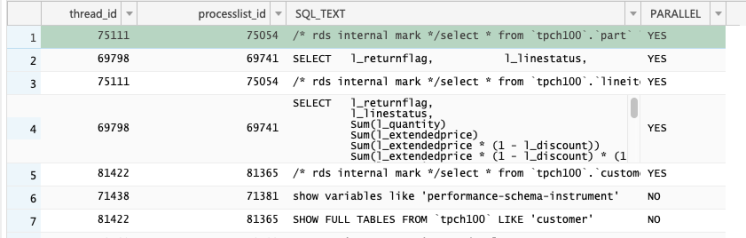
找到你关注的SQL 的thread_id, PARALLEL 状态。
注意:
- 查询出来的thread_id 很重要, 后续会大量依赖这个thread_id
- 直接从events_statements_xxx查到的thread_id与通过show processlist查到ID是两个完全不同的ID,processlist中的ID是connection_id,也可以认为是session_id,它也可以通过内部函数connection_id()查询到。如果想通过connection_id查询thread_id,可以通过以下SQL得到。
select thread_id from performance_schema.threads where processlist_id=connection_id();
- events_statements_current表只显示最近执行的一条SQL的执行信息,因此不能在当前session中查询,因为如果在当前sesssion中查询的话,只能查询到当前这条查询语句的执行信息。但可以在其它session中查询,并通过thread_id定位到需要查询的SQL的执行信息。
如想查询在session-1上执行的并行查询信息:
1)在session-1上执行以下语句,得到session-1的connection_id=2143;select connection_id();
2) 在session-1上执行并行查询select sum(c3), c4 from test.t1 where c3 > 5000 group by c4;
3) 在session-2上查询session-1刚刚执行的并行查询的执行信息
select processlist_id,
SQL_TEXT,
PARALLEL
from performance_schema.events_statements_current stmt,
performance_schema.threads th
where stmt.thread_id= th.thread_id
and processlist_id= 2143\G
结果如下所示:
(2)查看并行查询的运行时信息
当我们确定一个查询以并行方式执行时,也许更想知道到底这个查询的并行执行过程是怎样的?有多少个并行算子?有多个并行执行的线程?每个线程都做了什么,扫描多少数据,又返回了多少数据?……
通过查询performance schema中的events_parallel_query_xxx和events_parallel_operator_xxx可以为你提供以上的所有信息。
events_parallel_query_xxx中保存并行查询在执行过程中的运行时信息,参与执行的每个线程,包括session线程和worker线程,每个线程都有自己的并行执行信息。因此一条并行查询会有多条并行执行信息。
- events_parallel_query_current表中保存最近一次执行的并行查询的执行信息;
- events_parallel_query_history表中保存最近执行的并行查询的历史执行信息,默认是每个session最近10条并行查询的历史信息。
当并行查询执行正在执行或执行完成后,可以通过events_parallel_query_xxx来查看并行执行的相关信息。
select ph.thread_id,
ph.event_id,
sh.parallel,
ph.timer_wait/1000000000000 as exec_time,
sh.sql_text,
ph.state,
ph.*
from performance_schema.events_parallel_query_history ph,
performance_schema.events_statements_history sh
where ph.thread_id= sh.thread_id
and ph.thread_id= 87267 /* 替换为前面查询的thread_id */
and ph.nesting_event_id = sh.event_id
\G
表events_parallel_query_xxx中包含以下内容:
- THREAD_ID:指当前线程ID
- EVENT_ID: 指当前事件ID,在每个线程中事件ID单调递增。
- END_EVENT_ID: 指当前事件完成时的最大事件ID,当为NULL时表示当前事务尚在进行中。
- EVENT_NAME:指当前正在进行中的事件,并行相关的事件以parallel_query开始,role表示执行角色,最后是角色名,可以为leader或worker。
- PARENT_THREAD_ID: 父线程ID,只有worker线程有父线程ID,leader线程的父线程ID为NULL。
- OPERATOR_ID:与当前worker线程相关的并行算子ID,若是leader线程,则为NULL
- WORKER_ID:Worker ID,如果是leader,则为NULL
- STATE:执行状态,COMPLETED表示已完成,STARTED表示正在运行中
- SOURCE:表示此事件嵌入代码的位置;
- TIMER_START:表示此事件开始时刻,单位是皮秒picoseconds (trillionths of a second).
- TIMER_END:事件结束的时刻
- TIMER_WAIT:事件持续的时间
- MYSQL_ERRNO:执行出错时输出错误码
- RETURNED_SQLSTATE:执行出错时输出错误状态
- MESSAGE_TEXT:执行出错时输出错误消息
- ERRORS:是否正确执行的标志,出错时输出为1,否则为0
- WARNINGS:警告消息的个数
- ROWS_AFFECTED:受影响的行数
- ROWS_SENT:返回的行数
- ROWS_EXAMINED:检查的行数,不包含worker扫描的行数,通常等于所有worker返回的行数总和
- CREATED_TMP_DISK_TABLES:在磁盘上创建的临时表个数
- CREATED_TMP_TABLES:在内存中创建的临时表个数
- SELECT_FULL_JOIN:JOIN时全表扫描的数目,此处不为0,应检查索引的合理性
- SELECT_FULL_RANGE_JOIN:JOIN时RANGE扫描的数目
- SELECT_RANGE:JOIN时第一个表采用RANGE扫描的数目
- SELECT_RANGE_CHECK: RANGE扫描检查的数目
- SELECT_SCAN:第一个表采用全表扫描的JOIN数目
- SORT_MERGE_PASSES:归并排序的次数
- SORT_RANGE:RANGE排序次数
- SORT_ROWS:排序的行数
- SORT_SCAN:通过全表扫描完成的排序数目
- NO_INDEX_USED:若未使用索引扫描,为1;否则为0
- NO_GOOD_INDEX_USED:若未找到好的能用的索引,为1;否则为0
- NESTING_EVENT_ID:关联的上级事件的ID,可以通过此ID查询父事件即并行查询事件
- NESTING_EVENT_TYPE:关联的上级事件的类型
- NESTING_EVENT_LEVEL:级别的层数。
举例来说,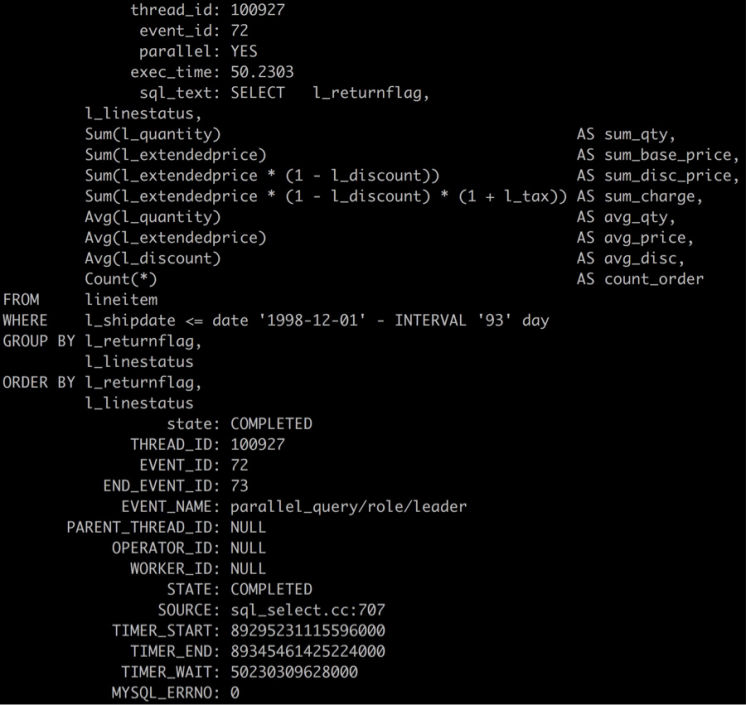
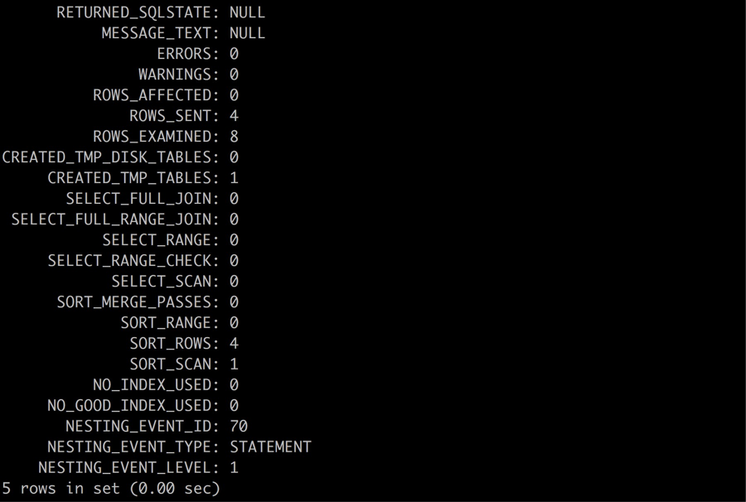
其中:
- EVENT_NAME= parallel_query/role/leader, 表示此事件是并行查询事件,角色是leader
- PARENT_THREAD_ID=NULL,仅对worker有效
- OPERATOR_ID= NULL,仅对worker有效
- WORKER_ID= NULL,仅对worker有效
- STATE= COMPLETED,表示此并行查询已执行完成
- TIMER_WAIT= 50230309628000,表示执行的时间,单位是皮秒,转成秒应该是50230309628000/1000000000000= 50.2303
- ROWS_SENT= 4,表示此查询返回4行数据;
- ROWS_EXAMINED= 8,表示leader线程共检查了74行数据
- CREATED_TMP_TABLES= 1,表示创建了1个内存临时表
- NESTING_EVENT_ID= 70,表示与其关联的父事件ID为,可通过此ID从events_statements_xxx表中得到此查询的SQL文本;
- NESTING_EVENT_TYPE= STATEMENT,表示与其关联的父事件类型
- NESTING_EVENT_LEVEL= 1,级别事件层级为1
(3)查看并行算子的运行时信息
events_parallel_operator_xxx表中提供并行查询中并行算子的相关信息,所谓并行算子,指可以由多个线程并行执行完成的任务,比如gather,gather会创建一组worker线程,由一组worker线程共同来完成扫描任务。
- events_parallel_operator_current表中保存session中最近一次执行的并行查询相关的并行算子的执行信息。
- events_parallel_operator_history表中保存session中最近执行的并行查询相关的并行算子的历史信息,默认是每个session最近10条并行查询的并行算子信息。
并行算子在执行计划中也可以查看到,如下所示:explain select sum(c3), c4 from test.t1 where c3 > 5000 group by c4;
其中
当查询执行计划过程中或完成后,可以通过events_parallel_operator_current查看最近执行语句的并行算子相关信息。
select *
from performance_schema.events_parallel_operator_history
where thread_id= xxx /* 替换为前面查询的thread_id*/
表events_parallel_operator_xxx中包含以下内容:
- THREAD_ID:指当前线程ID
- EVENT_ID: 指当前事件ID,在每个线程中事件ID单调递增。
- END_EVENT_ID: 指当前事件完成时的最大事件ID,当为NULL时表示当前事务尚在进行中。
- EVENT_NAME:指当前正在进行中的事件,并行相关的事件以parallel_query开始,operator表示并行算子,最后是具体的算子名称,目前只有一种gather类型。
- OPERATOR_ID:并行算子ID,每个并行查询可能有1个或多个并行算子,ID单调递增。
- OPERATOR_TYPE:并行算子类型,目前只有一种类型gather。
- STATE:执行状态,COMPLETED表示已完成,STARTED表示正在运行中。
- SOURCE:表示此事件嵌入代码的位置;
- TIMER_START:表示此事件开始时刻,单位是皮秒picoseconds (trillionths of a second).
- TIMER_END:事件结束的时刻
- TIMER_WAIT:事件持续的时间
- PLANNED_DOP:并行计划的并行度,即计划最多可以有多少worker线程
- ACTUAL_DOP:实际执行时的并行度,即实际执行时的worker线程数
- PARTITIONED_OBJECT:并行执行的目标对象
- NUMBER_OF_PARTITIONS:目标对象的内部分片数,与表的分区不同,不分区的表也可以内部分片,每个分片由一个worker来执行扫描,分片越多,并行度也越高,分片越少,并行度越低。
- MYSQL_ERRNO:执行出错时输出错误码
- RETURNED_SQLSTATE:执行出错时输出错误状态
- MESSAGE_TEXT:执行出错时输出错误消息
- ERRORS:是否正确执行的标志,出错时输出为1,否则为0
- WARNINGS:警告消息的个数
- ROWS_SENT:返回的行数
- ROWS_EXAMINED:检查的行数,不包含worker扫描的行数,通常等于所有worker返回的行数总和
- CREATED_TMP_DISK_TABLES:在磁盘上创建的临时表个数
- CREATED_TMP_TABLES:在内存中创建的临时表个数
- NESTING_EVENT_ID:关联的上级事件的ID,可以通过此ID查询父事件即并行查询事件
- NESTING_EVENT_TYPE:关联的上级事件的类型
- NESTING_EVENT_LEVEL:级别的层数。
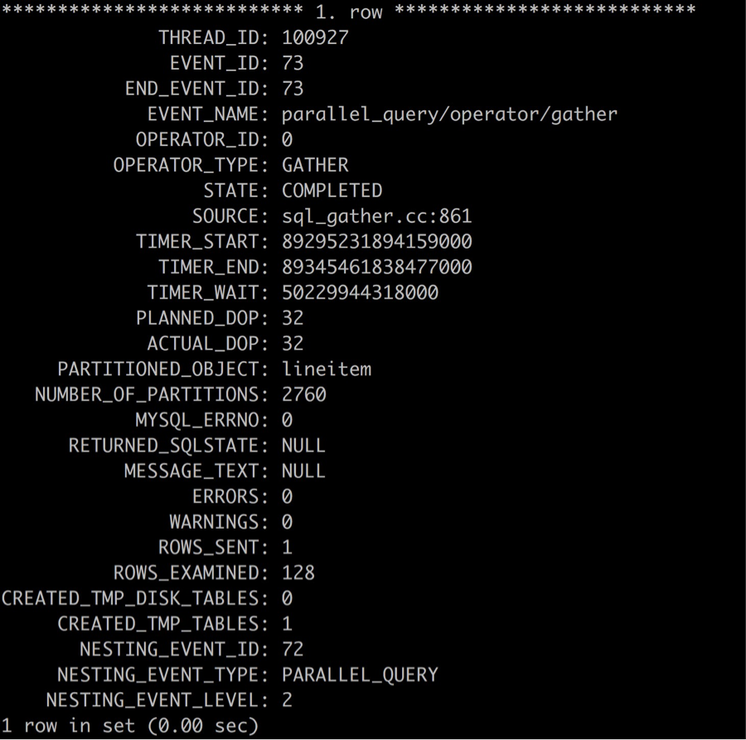
在本例中
- Event_name是parallel_query/operator/gather,表示是并行算子gather类型的事件
- OPERATOR_ID=0,表示是本并行查询中的第1个并行算子
- OPERATOR_TYPE = GATHER,表示是GATHER
- STATE= COMPLETED表示此并行算子的执行已经完成
- TIMER_WAIT= 50229944318000,是此算子的执行时间,单位是皮秒,转成秒应该是50229944318000/1000000000000= 50.2299s
- PLANNED_DOP=32,表示计划的并行度为32
- ACTUAL_DOP=32,表示实际执行时的并行度为32,此值有时会小于计划的并行度 – 注意此处真实情况下是否
- PARTITIONED_OBJECT=lineitem:表示此gather执行并行扫描的表是lineitem表。
- NUMBER_OF_PARTITIONS=2760,表示表lineitem内部有2760个分片,这些分片会依次分配到不同的worker上执行扫描,worker当一个分片扫描完成后,会自动申请下一个分片,直到所有分片全部处理完毕。
- ROWS_SENT= 1,表示gather算子执行完成后,会产生1行数据。
- ROWS_EXAMINED = 128,表示gather算子共检查了128行数据,这些数据由worker返回,因为每个worker上会优先执行已经下推的where条件。
- CREATED_TMP_DISK_TABLES=0,表示没有在磁盘上产生临时表。
- CREATED_TMP_TABLES=1,表示产生1个内存临时表。
- NESTING_EVENT_ID=72,表示与此并行算子事件关联的父事件ID是72,这个ID可用于指定查询并行执行的主事件信息;
- NESTING_EVENT_TYPE= PARALLEL_QUERY,表示与此并行牌子事件关联的父事件类型是PARALLEL_QUERY,即并行查询事件;
- NESTING_EVENT_LEVEL=2,表示嵌套事件层级为2
(4)查看worker的运行时信息
每个并行算子可以有多个worker,每个worker独立完成部分子任务,如扫描某个表的若干个分片。每个worker也都有自己的运行时信息,这些信息也是保存在events_parallel_query_xxx中,只是角色是worker而已。
因为worker是关联到并行算子的,所以可以通过并行算子的event_id和thread_id来过滤查询,
/纪君祥, 原文中, 有/
select *
from performance_schema.events_parallel_query_current
where parent_thread_id= xxx /*前面查询的thread_id*/
UNION
select *
from performance_schema.events_parallel_query_history
where parent_thread_id= xxx \G; /*前面查询的thread_id*/
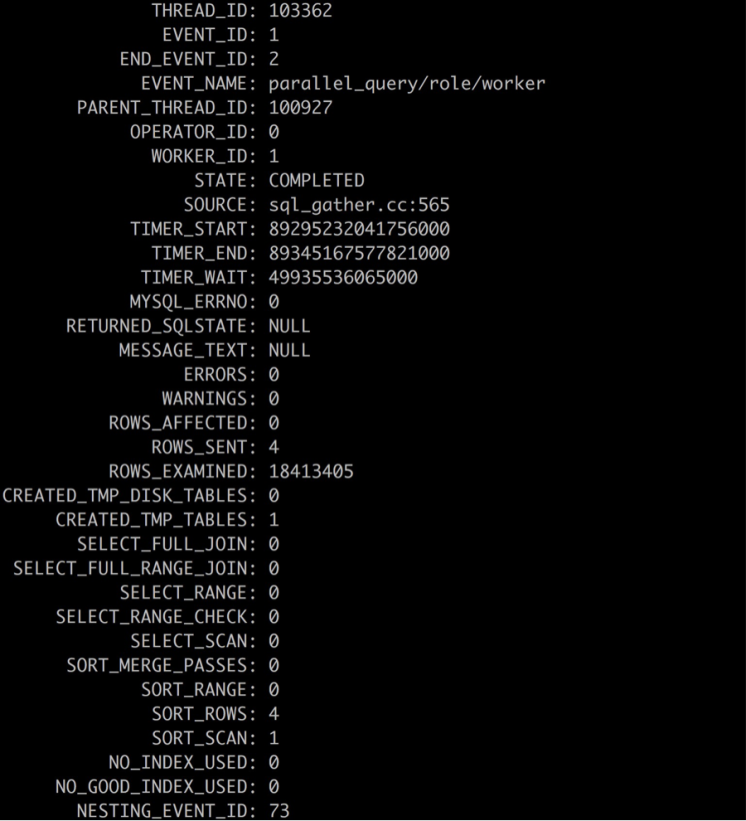
其中:
- EVENT_NAME= parallel_query/role/worker,表示是worker事件
- PARENT_THREAD_ID= 100927,表示其父线程ID是100927
- OPERATOR_ID= 0,表示此worker所属并行算子ID为0
- WORKER_ID= 1,表示此worker的worker ID为1
- TIMER_WAIT= 49935536065000,此worker的运行时间为49935536065000/1000000000000=49.94s
- ROWS_SENT= 4,表示此worker返回4条数据
- ROWS_EXAMINED= 18413405,表示此worker共扫描了18413405行数据;
- CREATED_TMP_TABLES= 1,表示此worker创建了1个内存临时表
- NESTING_EVENT_ID= 73,表示此worker的父事件ID为73,即其关联的并行算子的event_id为73
- NESTING_EVENT_TYPE= PARALLEL_OPERATOR,表示worker的父事件类型是并行算子
- NESTING_EVENT_LEVEL= 3,表示级联事件层级为3。
(5)查看内存消耗
select *
from performance_schema.memory_summary_global_by_event_name
where event_name like '%parallel%' \G


其中:
- memory/performance_schema/parallel_query_class指为parallel_query事件类分配的内存,目前只有3种parallel_query事件类型,role/leader,role/worker及operator/gather,主要用于保存事件类的各种属性。
- memory/performance_schema/parallel_query_objects指为记录并行查询执行过程中的运行时信息所需对象所分配的内存,以page为单位分配,每个page包含128个parallel_query对象,此内存一经分配,除非系统重新启动,不能被释放。
- memory/performance_schema/parallel_operator_objects指为记录并行算子执行过程中的运行时信息所需对象所分配的内存,以page为单位分配,每个page包含128个parallel_operator对象,此内存一经分配,除非系统重新启动,不能被释放。
- memory/performance_schema/parallel_query_history指为保存历史并行查询的运行时信息所分配的内存,此处只为其分配存储指针的内存,默认每个线程10条历史记录,与线程对象同时分配。此内存一经分配,除非系统重新启动,不能被释放。
- COUNT_ALLOC指分配的次数,对于事件相关对象是可变的,当新分配page时,自动加1,此数值只能单调递增。
- CURRENT_NUMBER_OF_BYTES_USED指当前已经分配的内存,单位是byte。
注意:
- 所有performance schema所需的内存,如果开启了performance schema,大部分内存是在系统初始化时就已经预先分配好的,与事件相关对象的内存可以按需分配,但只能按page增加,每个page包含若干对象,一经分配,除非系统重启,不能释放。
- 所有事件相关的对象按page分配后,将由container来统一管理,对象可以重用,只有当container中没有可用的对象时,才会申请分配新的page。
- 此处没有memory/performance_schema/parallel_operator_history,是因为所有并行算子都链接在leader对象,而所有的worker对象都链接在并行算子对象上。因此历史记录只需要保存leader对象的指针即可,不需要单独保存并行算子的历史记录。
(6)查看parallel query 对象
每个并行查询的并行度可能都不一样,每个并行查询包含的并行算子个数可能都不一样,因此每个并行查询所需记录运行时信息的parallel query对象和operator对象并不确定,为防止无限制的使用内存,系统做了以下限制:
- 每个并行查询最多只记录8个并行算子的运行时信息,多余的并行算子的运行时信息将被丢弃;
- 每个并行算子最多只记录32个worker的运行时信息,多余的worker运行时信息将被丢弃;
- 可以配置参数performance_schema_max_parallel_query_objects来限制parallel query的对象数目,以限制内存使用;
- 可以配置参数performance_schema_max_parallel_operator_objects来限制parallel operator的对象数目,以限制内存使用。
- 每个session中超出performance_schema_events_parallel_query_history_size的parallel query对象及parallel operator对象将被释放给container,以供将来重用。
- 当session退出时,当前session中记录的所有parallel query对象及parallel operator对象将被释放给container,以供将来重用。
此外,可以查看并行对象的使用情况,如show status like '%objects_used';
总结
首先,我们需要了解的是,并行并不一定是最好的执行计划,在许多场景下,单线程顺序执行也许效率更高,执行更快。如表数据比较少,或能分配到worker上执行的任务比较少,或资源不足等。另外目前对并行的支持还有很多需要提升的地方,不是每个场景都适合并行执行。所以不要因为开启了并行,就期待对所有场景都有极大的提升,性能的提升还是需要DBA不断的去分析、去优化,并行执行只是其中的一个手段而已。
并行查询的支持只是一个开始,让我们期待PolarDB有更多更好的自研特性出来,为客户提供更美好的用户体验。