MySQL · 最佳实践 · 性能分析的大杀器—Optimizer trace
Author: jijunxiang
1. 前言
当听到PolarDB支持并行的消息时,我感到十分兴奋,终于MySQL家族也能支持并行了。但当我真正使用并行的时候,却发现不知所措,结果并未如我所期望的那样欢快的在多核CPU上跑起来,仍然在单行线上慢如老牛。难道所谓的并行只是个噱头?还是只是PPT吗?经过一番深入的研究,终于发现,不是法拉利太差,而是司机太菜。
PolarDB为DBA提供了一个非常厉害的大杀器—optimizer trace,通过它我们可以了解到每个SQL是如何被解析、优化并到最终执行的。在其中我们可以清楚的看到并行优化器是如何生成并行执行计划,如果SQL不能被并行化,就会给出清晰的理由。看到这里,终于对改善慢如老牛的查询有了一点点信心,也许我们慢如老牛的查询并未如我们所愿在并行的快车道上执行呢?下面我们就以案例来分析trace的灵活运用。
2. 开启大杀器-optimizer trace
Optimizer trace并不是自动就会默认开启的,开启trace多多少少都会有一些额外的工作要做,因此并不建议一直开着。但trace属于轻量级的工具,开启和关闭都非常简便,对系统的影响也微乎其微。而且支持在session中开启,不影响其它session,对系统的影响降到了最低。
如果发现某个SQL有问题,只需要在session中设置optimizer_trace,将trace开启即可,当不再需要时,直接关闭即可。
SET SESSION optimizer_trace=”enabled=on”;
然后执行有问题的SQL,如果SQL的执行时间很长的话,也可以只进行explain 操作,即:
EXPLAIN your SQL;
最后,通过
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
查询即可得到trace信息。trace信息以json格式输出,通过\G可以格式化输出trace信息,更宜于阅读。如下所示:
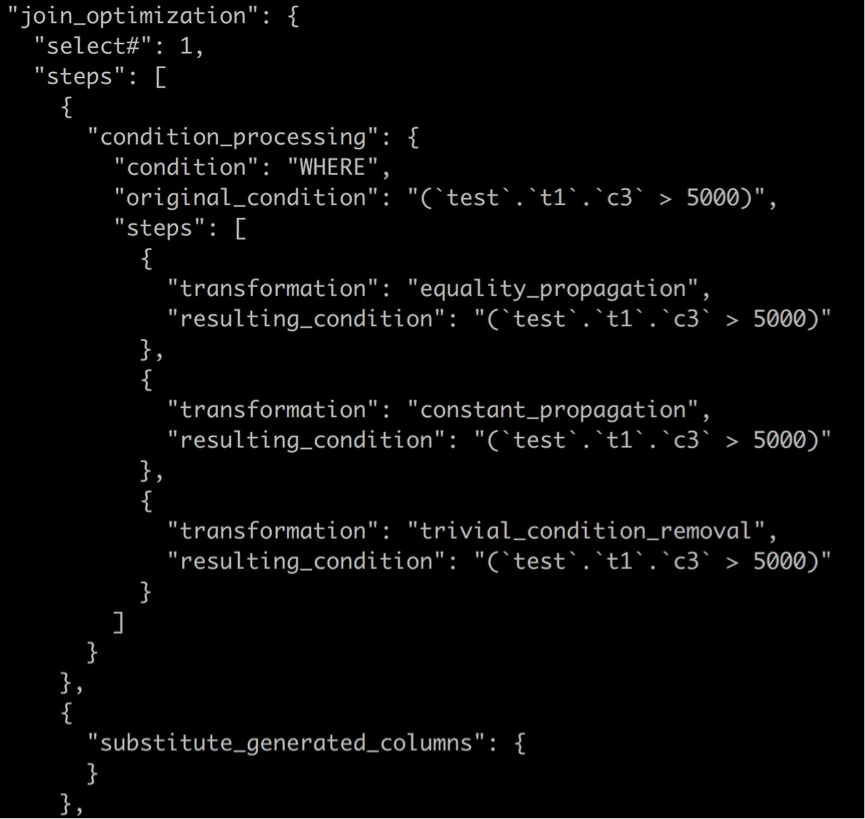
3. 如何分析trace来改善查询的执行效率
下面我们以实例来分析一下trace在实践中的应用。TPCH的数据的scale为1G,以tpch的query 5为例:
select
n_name,
sum(l_extendedprice * (1 - l_discount)) as revenue
from
customer,
orders,
lineitem,
supplier,
nation,
region
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and l_suppkey = s_suppkey
and c_nationkey = s_nationkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AMERICA'
and o_orderdate >= date '1995-01-01'
and o_orderdate < date '1995-01-01' + interval '1' year
group by
n_name
order by
revenue desc
limit 1;
TPCH的query5是一个多表JOIN,其中customer,orders,lineitem,supplier表比较大,nation和region比较小。
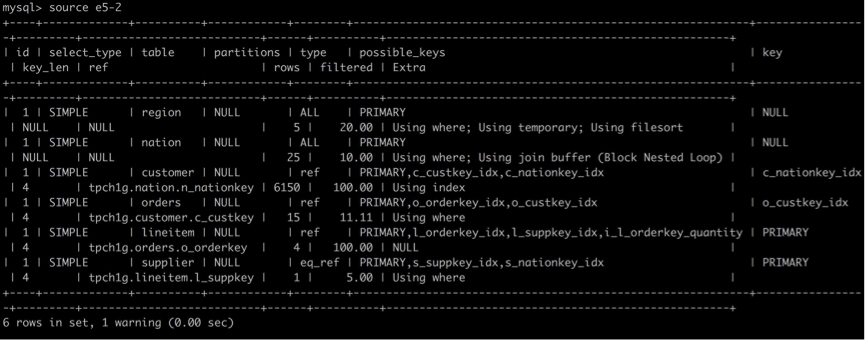
首先我们来看一下未开启并行的查询计划,如下所示:
然后开启并行,再看一下查询计划:
开启并行的SQL如下:
SET SESSION MAX_PARALLEL_DEGREE=16; //设置最大并行度为16
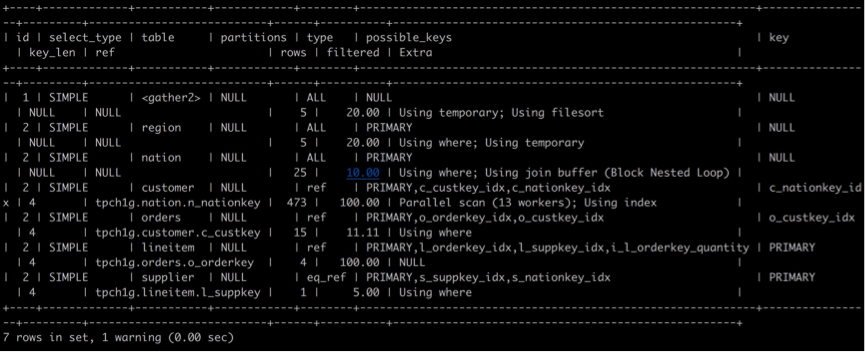
比较串行的查询计划和并行的查询计划,可以发现有些不同之处:
- 首先在并行查询计划中多了一个gather,gather是在并行查询计划中主要用于合并不同worker线程并行执行的结果,并进行后续必需的操作如group by/order by等,最终将结果返回给用户。 除此之外,还可以发现对于customer表一行,在Extra中有Parallel scan (13 workers);这表示会对customer表进行并行扫描,共有13个workers线程。
- 后分别以串行和并行方式执行Query 5语句:结果如下:
| Query 5 | 串行执行(秒) | 并行执行(秒) DOP=16 |
| Round - 1 | 4.00 | 1.71 |
| Round - 2 | 3.96 | 1.60 |
| Round - 3 | 3.98 | 1.55 |
| Round - 4 | 3.96 | 1.58 |
| Round - 5 | 3.97 | 1.54 |
| Avg | 3.974 | 1.596i |
从结果中可以看到,性能提升了大约150%,那么还有没有提升的空间呢?
下来我们来看一下并行计划的trace。
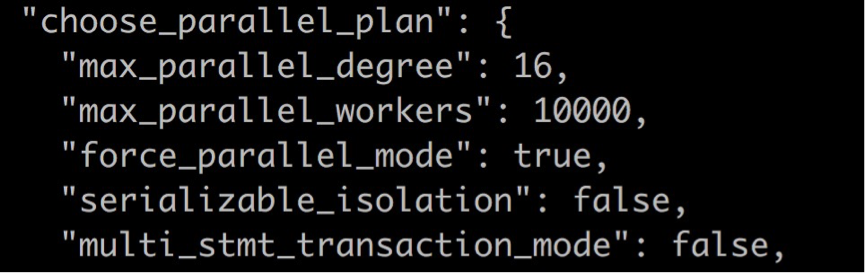
在trace的输出中有很多项,这里我们主要看是如何选择并行执行计划的。上图中可以看到一些并行计划的基础条件检查:
- max_parallel_degree:表示最大并行度,当其为0时,表示不允许选择并行计划。
- max_parallel_workers:表示系统同时允许的最大worker线程数。当可用worker线程数不足时,不允许选择并行计划;
- force_parallel_mode:表示强制采用并行模式,不建议在生产环境下使用,可用于测试,它用于当数据量不是很大时,正常情况下不会选择并行计划,但为了测试,使用此参数强制使用并行计划。
- serializable_isolation:是当前事务的隔离方式,串行化隔离方式的事务不支持并行化;
- multi_stmt_transaction_mode:表示单语句事务或长事务,目前只支持单语句事务的并行化;
当这些条件已经满足,则开始选择可能并行扫描的表:
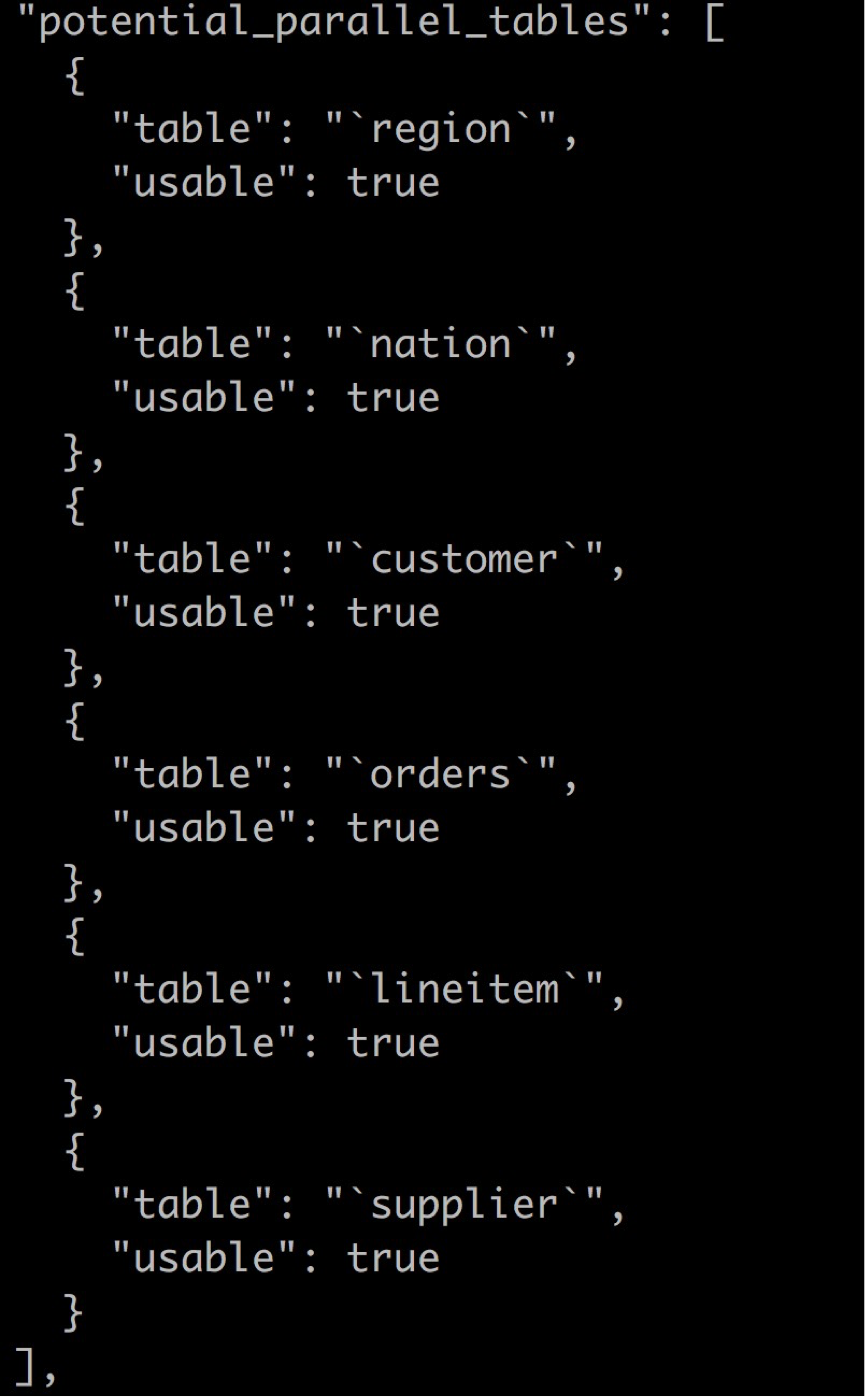
在potential_parallel_tables列表中会显示此语句中潜在的可能并行化的表。
在considered_parallel_tables子项中会依次检查潜在表,以确定可以并行化的表。
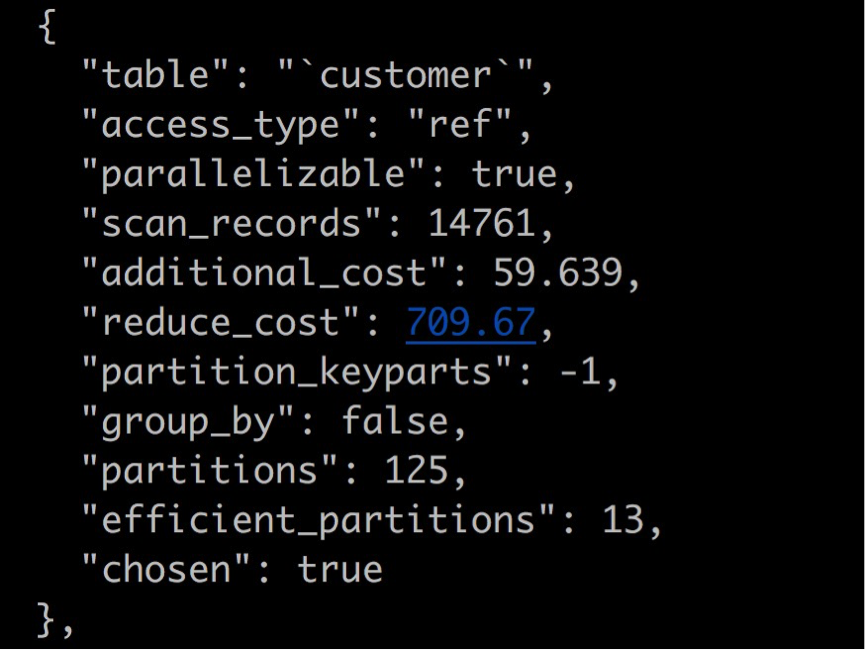
每个子项如上图所示,其中包含表名、访问类型、是否支持并行化等信息,其中与并行化有关的最重要信息是
- partitions:表示表用于并行化的分片数,如表customer是125个分片;
- efficient_partitions:表示有效的分片数,因为表本身可能会有condition条件等,所以并不是所有分片都需要扫描,因此可能会小于分片总数;
- chosen:表示当前片已经被候选为并行化表,如之后再没有其它表被选中,则最后一个被选中的表就是并行化表;
当chosen为false时,trace中会输出选择失败的原因,如下所示:
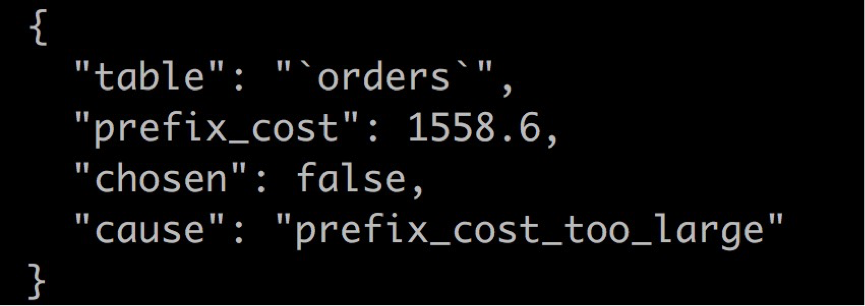
prefix_cost_too_large表示到目前为止cost已经太大,无法继续选择其它表作为并行化表。
下面我们来看如何优化提升Query 5的性能:
从trace中我们可以看到,可并行化的表customer的efficient_partitions为13,而我们设置的最大并行度为16,也就是说最大可以有16个worker可以使用,但任务分片却只有13个,显然没有充分利用所有资源。
通过分析所有可选择的表我们发现还有orders、lineitem表也是很大的表,若是选择其它表是不是就可以充分利用这些资源呢?
我们来看下orders,如何让优化器先尝试orders表呢?其中可以通过hint:join_order()来改变Join的顺序来间接实现选择并行化表的顺序。
hint如下:/*+ join_order(orders, customer) */
然后我们再来看一下并行的查询计划:
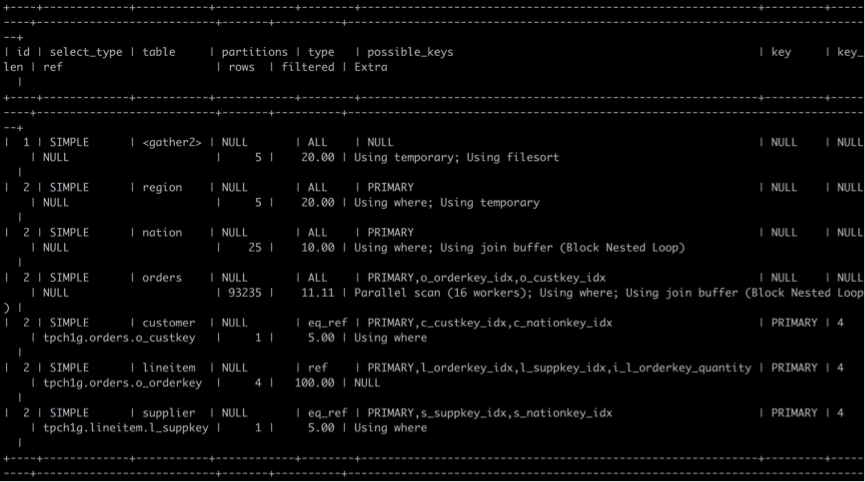
与没有hint的查询计划相比,会发现JOIN的表顺序发生了变化,orders表与customer表交换了顺序,并且orders表的 Parallel scan (16 workers)变成为16个worker。
下面我们重新做下测试:
| Query 5 | 串行执行(秒) | 并行执行(秒) DOP=16 | 并行执行—hint DOP=16 |
| Round - 1 | 4.00 | 1.71 | 0.75 |
| Round - 2 | 3.96 | 1.60 | 0.76 |
| Round - 3 | 3.98 | 1.55 | 0.78 |
| Round - 4 | 3.96 | 1.58 | 0.77 |
| Round - 5 | 3.97 | 1.54 | 0.77 |
| Avg | 3.974 | 1.596 | 0.766 |
通过测试发现,通过修改join_order后,发现性能有明显提升,对比串行计划提升大约420%,对比未hint的性能提升大约100%。 另外,也对其它表做并行化进行了测试,结果与customer表并行化的结果相关不大。
4. 总结
通过trace,我们可能发现一些我们在explain中看不到的东西,当发现query并未产生并行查询计划时,可以将trace打开,可以协助我们发现查询不能并行化的原因,针对这些原因可以进行调整,如增加资源、调整参数、转换存储引擎、修改JOIN顺序等。
另外,trace还可以帮我们探索更高性能优化的可能,如前述实例,通过trace有针对性的调整JOIN顺序、增加索引等,也许可以收到更大的性能提升。