MySQL · 引擎特性 · InnoDB Parallel read of index
Author: boen
parallel read是什么
现代服务器硬件里,两路甚至四路的CPU成为主流,主流的公有云供应商普遍推出88 CORES的实例。
数据库学术界的研究热点也一直都是如何提高并行能力(如mass-tree),在工业界,以POLARDB,HANA为代表的新型数据库,都把并行处理的能力做为自己的核心竞争力,然而MySQL官方演进的节奏一直偏慢,迟迟没有推出自己的并行处理方案,直到8.0.14,INNODB团队首次推出了parallel read,先看release notes:
- InnoDB:
InnoDBnow supports parallel clustered index reads, which can improveCHECK TABLEperformance. This feature does not apply to secondary index scans. Theinnodb_parallel_read_threadssession variable must be set to a value greater than 1 for parallel clustered index reads to occur. The default value is 4. The actual number of threads used to perform a parallel clustered index read is determined by theinnodb_parallel_read_threadssetting or the number of index subtrees to scan, whichever is smaller.
从官方的介绍上看,第一个版本的pread仅仅支持check table以及select count(),从代码提交记录看,编码最早可以追溯到2018年1月,经历了一年多的时间的研发, 可以说这一步迈得非常谨慎,不过我们相信这套并行执行的框架随着新版本的不断推出,通用性以及适用场景会越来越强。
在这篇文章里,我们一起来探索一下原厂是如何实现并行查询的:
parallel read 如何使用
Parallel Read的使用方法延续了MySQL简单易用的传统,仅增加了一个innodb会话级别的参数parallel_read_threads,取值从1~256。如果不指定,默认线程数是4;
这里需要注意,最大256线程同样是实例级别限制,遵循先得先到的原则,一旦threads消耗完,后续的并行查询只能回退到传统的一行行scan。
打开parallel read方法也很简单,
set local innodb_parallel_read_threads=64;
select count(*) from sbtest.sbtest1;
count查询就会走到并行的逻辑里,略微遗憾的是,这个功能还在初级阶段,最新的release版本仅仅支持check table和count查询。
parallel read性能表现如何
接下来我们对parallel read做一个性能评测,测试服务器的cpu是 Intel(R) Xeon(R) CPU E5-2682 @ 2.50GHz,总共32个逻辑核,因此我们期望在32线程时获得最低的延时,并且有接近线性的加速比。
我们生成了单表2.5亿行记录,分别使用1 ~ 128并发去测试select count(*)的耗时 ,结果如下图:
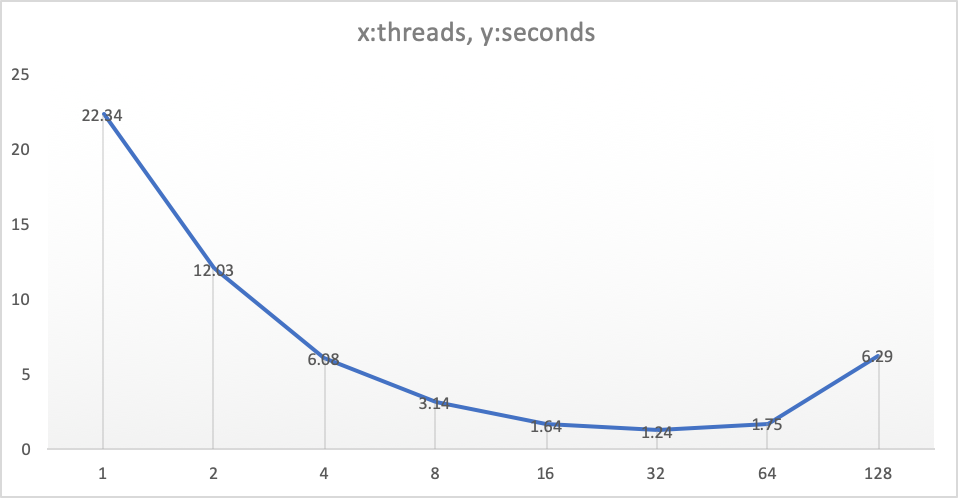
从这个结果看,parellel read的表现是符合我们的预期的,在低并发的时候可以获得接近线程的加速比,整体可以把延时从22秒降低到1.2秒。
高并发时加速比下降明显,这也是因为多线程调度的overhead太大导致的。
我们也观察到超线程对并行执行的效果不理想,并发数超过了cpu核数之后,出现了明显的性能衰退,可见当前的实现并不能很好的利用cpu的流水线,在榨干cpu性能方面还有很大的潜力。
parallel read是如何实现的
1. 主要数据结构
-
Parallel_reader
并行查义的执行主体对象,主要提供三个接口:
-
add_scan()
把scan的目标index注册到reader里,虽然当前仅支持clustered index,但从接口的设计看,未来会支持多个index,甚至多个table的parallel scan。
这里还会对B+tree进行预分片,为什么是预分片,主要原因还是add_scan是单线程执行,计算需要尽可能的轻量,后面的执行线程会做更细粒度的分片,这样的设计带来的好处后面做进一步的解释。
-
run()
启动worker线程和read_ahead线程,worker线程也就是真正的执行线程,对一个切好的sub tree做scan,或者做分片计算。
-
-
Parallel_reader::Scan_ctx
对应一个index,通过add_scan()注册到reader中。
-
Parallel_reader::Ctx
执行的上下文,对应B+ tree的一个分片。
2. B+tree 分片策略
parallel read自从8.0.14 release之后,有过一个大的改动,就是修复分片算法上的一个设计缺陷。
在最初的设计里,把 B+tree 切成N个subtrees的策略很简单,假如并发度是N,从最一层开始逐层扫描每层的节点数,找到节点数大于N的一层。
假如我们有4个线程,找到了5个sub-trees,这时就会出现数据倾斜,必然有个线程需要处理两个sub-trees,而此时其他线程都是IDLE的状态。
这个问题在数据量非常大的时候会比较明显,因此在8.0.18,对这个算法进行了重新设计,具体的做法如下:
前面提到了add_scan()时做第一次分片,这时粒度是比较粗的,worker线程需要进行二次分片,通常此时,整体B+tree会切成粒度很细的sub-trees,数量远远超过work threads,从而比较优雅的解决数据倾斜的问题;
3. 数据预读
pre-fetching也是后面引入的优化,假如数据都在不BufferPool中,scan table的bottlenect就不是cpu,而是IO,增加cpu效果自然不理想。对于逻辑上的顺序读,一个常见的优化是,额外采用一组线程,提前把数据从磁盘读到BufferPool中,尽可能减少scan时的IO。
4. Handler API
parallel reader目前仅仅是innodb内部使用的一个框架,但己经定义了handler api,这也是一个信号,表明innodb团队在后面的版本里会提供一些系列并行加速的能力,例如parallel DDL。