MySQL · 引擎特性 · 排序实现
Author: 觉历
背景:
order by/group by作为mysql一个高频使用的语法,日常运维中经常遇到慢sql,内存使用不符合预期,临时文件的问题很多都和它们相关,本文通过介绍mysql 排序的具体实现,希望对排序可能引起这些问题的原因进行说明,为解决它们提供理论依据。同时也希望对功能有改进需求的同学提供帮助。以下基于mysql 5.7代码。 order by/group by 在mysql内部主要分为两个思路:
- 通过在order by/group by c1 … cN上的索引有序性,通过空间换时间,直接用索引的顺序返回结果。
- 如果没有索引可用那就行sorting。
其中通过索引排序主要就是在sql的处理过程中正确的判断是否有合适的索引可用
索引优化排序
在优化阶段对排序的处理主要有:
- 判断是否可以通过某个表完成排序并记录下这个表
get_sort_by_table // 判断排序是否只涉及到一个表,而且order和group的列是兼容的 - 判断order by 或者group by是否在join的第一张表(优化后的非const表),从而决定是否需要临时表
- 判断是否可以用index代替排序
// Test if we can use an index instead of sorting
test_skip_sort();
-->test_if_skip_sort_order
主要的逻辑:
- 遍历所有的sort field把它的part_of_sortkey map和这张表可用的keys的map做交集,获取所有可用的排序索引,这个交集保存在usable_keys中;
- 通过选择的表的quick访问方法(ref, range, index_merge …) 获取ref_key;
- 判断当前表选择的最优访问方式是否就在能用于排序的usable_keys中,如果是保留原有的方法,否则修改表的访问方式到可用的usable_keys中, 包括选择扫描索引的方式;
如果没有合适的索引可用,mysql选择对查询需要的数据进行排序,这个主要由filesort来实现。
filesort
主要流程
首先准备filesort的sort fields, 这里面很重要的结构是st_sort_field
struct st_sort_field {
Field *field; /* Field to sort */
Item *item; /* Item if not sorting fields */
uint length; /* Length of sort field */
uint suffix_length; /* Length suffix (0-4) */
Item_result result_type; /* Type of item */
enum_field_types field_type; /* Field type of the field or item */
bool reverse; /* if descending sort */
bool need_strxnfrm; /* If we have to use strxnfrm() */
};
比如 select * from t order by c1,c2,c3 将生成3个st_sort_field的数组 紧接着需要初始化排序需要的参数结构体:
class Sort_param {
public:
uint rec_length; // Length of sorted records.
uint sort_length; // Length of sorted columns.
uint ref_length; // Length of record ref.
uint addon_length; // Length of added packed fields.
uint res_length; // Length of records in final sorted file/buffer.
Addon_fields *addon_fields; ///< Descriptors for addon fields.
bool using_pq;
这里只对几个比较关键的成员进行介绍,其中前面几个xxx_length决定了一个sort key的长度,addon_length和addon_fields是对排序的一个优化,去除一次扫表,using_pq是另一个优化,表示排序是否可以用优先级队列来完成,后面都会进行详细介绍。
然后判断是可以用优先级队列处理排序, 同时初始化优先级队列。
这些准备完成后,就生成排序用的key。
最后根据找到所有key的数量决定用什么样的方式进行排序,如果是用优先级队列,在生成key的时候就完成了排序,如果需要排序的key比较少,这个判断依据就是key填满了多少chunk(sort_buffer), 这个buffer的大小由sort_buffer_size配置。如果只有一个chunk, 就对它进行排序就可以了,不然就需要对这些chunk进行归并排序,归并排序采用的7路归并,直到最终小于等于15个chunk, 进行最后一轮排序获得有序的ref pointers,通过这些pointers读取结果。流程图如下:
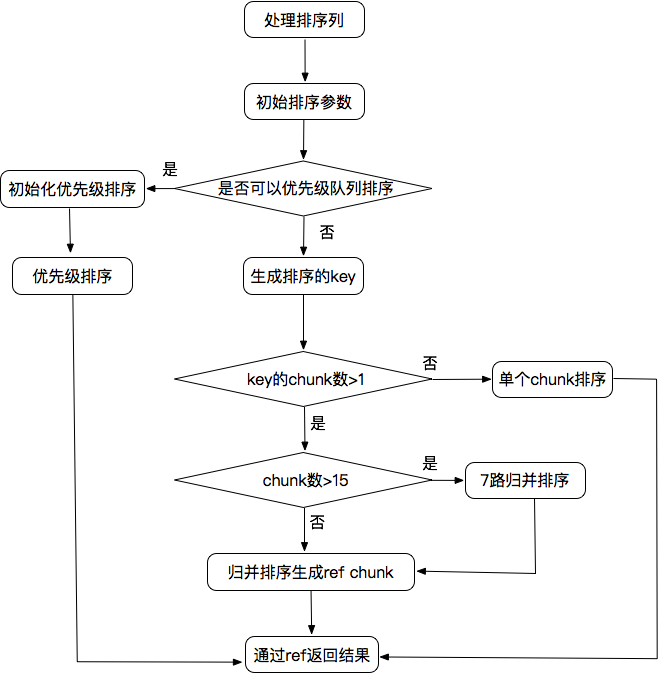 filesort流程
filesort流程
排序key的生成
读取每个符合条件的record, 然后调用排序参数的make_sortkey生成一个record的排序key。基本的逻辑就是调用每个排序field的make_sort_key方法,如果是其他item同样调用对应的生成sort_key的方法,然后把它们拼接在一起作为一个record的排序key. 而每个排序field需要多长的数据,通过初始化排序参数阶段调用sortlength计算得出,如果排序的类型是表的field, 通过sort_length接口获取单个列的排序长度,同时加上该列是否允许为NULL的一个字节,这儿的长度还受参数max_sort_length控制。 在拼接单个record的排序key时,遍历每个排序field, 如果这个field为NULL值,则填充全0,如果是反向排序,填充全1,对非NULL值的正常数据,如果是反向排序,还要对生成的排序数据每个字节取反, 整个key在sort_buffer中存储像定长的堆表,而生成的key可以通过memcmp进行比较。
create table t(id int primary key, c1 int, c2 varchar(10);
select * from t order by c1,c2;
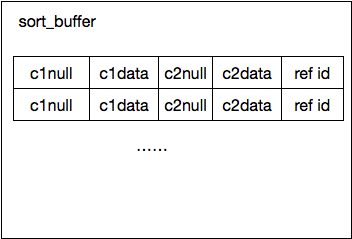
key的收集 每个sortkey末尾的ref id分两种情况:
- 把可以查询得到整个record的主键值拷贝到里面, 通过这个值排序完成后再次查询获取record返回。
- 减少一次读表,把结果集涉及到的列拷贝到排序key的后面,直接从排序好的结果中读取数据返回。
当收集满一个sort_buffer后,对它进行排序然后转储到临时文件。
优先级队列排序
为了优化带有limit n的order by查询语句:
SELECT ... FROM t ORDER BY a1,...,an LIMIT max_rows;
引入优先级队列排序算法,它通过在收集key的过程中维护一个优先级队列,将符合条件的n个key保留在这个队列中,key收集结束也就完成了排序。 首先需要评估用优先级队列和merge-sort的代价,从而选择最优的算法,merge-sort代价的估算模拟merge过程,优先级队列的代价主要包括队列维护代价加上扫表读取数据的代价。 如果选择了优先级队列排序,初始化优先级队列的buffer, 这儿需要多少内存通过limit的数量和每个key的长度计算出来了,初始化的主要工作就是生成key在buffer中offset的数组。然后把这个数组传给优先级队列进行排序,需要指定比较的函数和比较数据的长度:
Bounded_queue<uchar *, uchar *, Sort_param, Mem_compare>
pq((Malloc_allocator<uchar*>
(key_memory_Filesort_info_record_pointers)));
当初始化完成后,就可以在收集key的过程中把找到的record通过优先级队列的push接口放入,如果不满足优先级就淘汰,直到扫描结束,满足limit的n条记录保留在队列中:
void push(Element_type element)
{
if (m_queue.size() == m_queue.capacity())
{
const Key_type &pq_top= m_queue.top();
m_sort_param->make_sortkey(pq_top, element);
m_queue.update_top();
} else {
m_sort_param->make_sortkey(m_sort_keys[m_queue.size()], element);
m_queue.push(m_sort_keys[m_queue.size()]);
}
}
这里生成排序key的逻辑和前面说明的一样。
多路归并排序
如果不能用优先级队列,就要进行merge-sort, 当key比较少,全部在sort_buffer中时,首先需要对sort_buffer排序,然后把每个sort_key末尾的ref pointer拷贝到结果集的buffer中,通过这些ref pointer返回最后的结果。 如果生成的key存储到了多个chunk中,则需要进行merge, 这儿分两步,第一步是进行7路归并排序,把chunk数减少到<=15, 第二步将最后剩下的chunk merge成一个chunk, 这个chunk里面只有ref pointer用于读取数据。 返回结果ref pointer分两种:
总结
mysql内部排序实现主要分两种:
- 通过在排序列上的索引避免排序,这个就需要在表上新建必要的索引,它会占用一定的空间而且会对写入有影响。
- 通过filesort进行排序,如果有limit n可以选择优先级队列排序,在内存中完成排序,如果n比较大,则进行merge-sort, 这个会需要sort_buffer存储排序key和内存排序,同时需要临时表存储中间merge chunk。