PostgreSQL · 源码分析 · 回放分析(一)
Author: 烛远
基本原理
在数据库的运行过程中,难免会遇到各种非预期的问题,例如:
- 硬件错误,例如突然断电、磁盘错误、有人拔了你的内存条 :P
- 软件问题,例如操作系统崩溃、数据库内部存在bug等等
- 操作错误,例如误删数据、插入了不符合预期的数据、应用程序异常等等
- … …
在这些情况下,我们不希望我们的数据异常甚至丢失,有的情况下我们不能进行修复,例如火灾(这类问题依赖于备份存储介质的方式解决,需要异地容灾),但有的情况下我们可以进行解决,例如断电、崩溃。我们希望当数据库重新启动时,能够恢复其崩溃的那一瞬间的状态,能够恢复出“一致的”、“完整的”数据。
由于内存是易失性的,当数据库发生断电、崩溃等情况时,存储在内存中的数据会丢失,因此不能寄希望于存储在内存中的数据,我们希望找到一种方式,能够帮助数据库系统完成崩溃恢复,同时不那么影响性能。
| REDO | UNDO | |
|---|---|---|
| 未提交事务 | 不允许未提交的数据写入 | 允许未提交的数据写入(Steal) |
| 已提交事务 | 已提交的数据可以延迟写入 | 已提交的数据必须写入(Force) |
| 优点 | 可以延迟数据写入,减弱随机写 | 可以直接inplace修改,减少膨胀 |
表1 REDO和UNDO的对比
WAL(Write-Ahead Logging,预写式日志),就是完成这一工作的重要方式,数据库在执行事务的过程中,会将对数据的操作过程记录在WAL中,当数据库发生崩溃的时候,能够使用这个操作记录,将数据库恢复到崩溃前的状态。日志有几种记录方式,一是记录REDO,二是UNDO,还有一种是REDO/UNDO日志,REDO允许我们重新进行对数据的修改,UNDO允许我们撤销对数据的修改,REDO/UNDO日志是以上两种日志的结合。
除了WAL以外,还有Shadow Pagging的技术,是System R和sqlite所使用到的技术,看上去有点像COW(Copy On Write,写时复制)技术;此外还存在WBL(Write-Behind Logging,结合NVM所产生的技术)等技术出现。

图1 数据库基本组件的联系,I/O是围绕着缓冲区管理器进行的《数据库系统实现》
在数据库系统的内部,存在一个叫做 日志管理器 的基本组件,当数据库在正常运行的时候,事务管理器将对数据的操作发送到日志管理器中,日志管理器会将日志顺序写入到缓冲区管理器中,缓冲区管理器将日志刷入到磁盘中,事务管理器只有在确认这条事务的最后一条日志被刷入到磁盘后,才会向客户端返回事务提交的信息。
当崩溃发生时,在重启的时候,恢复管理器就会开始工作,它会读取事务的状态,将已经提交的数据重新回放,将已经放弃或者中断的事务进行回滚,将数据库内不一致的数据恢复到一致的状态。在恢复的时候,恢复管理器有一套算法逻辑在其中,决定如何进行回放,大名鼎鼎的ARIES就是这方面的一个算法。
ARIES的算法,是IBM提出的一整套关于日志记录和恢复处理的算法,后续的数据库管理系统都多少参考了该算法。
可以预见的是,如果数据库长时间运行了很久,突然崩溃了,在重启的时候可能需要从数天前开始进行恢复,需要花费数个小时甚至上天的时间。这时候需要使用到检查点技术,将脏数据刷入到磁盘中,记录检查点刷下的最旧的数据页的,可以保证我们在恢复的时候从相对较新的位置开始。同时让我们可以清理掉旧的日志文件(或者复用),让日志不会无限制地增长。
日志所提供的功能不仅于崩溃恢复,它还能提供复制(包括主备复制、外部订阅复制等)、主备状态同步、按时间点还原等功能。
实现简述
在记录日志时
- 每个数据页面 (堆或索引) 都标有影响页面的最新XLog记录的LSN
- 在缓冲区管理器能够写出一个脏页面之前,它必须确保XLog已经被刷新到磁盘,至少达到页面的LSN
在写XLog、写数据页面的时候,都只写入到缓冲区中,而不等待写入到磁盘中,以提供很快的写入速度,只在事务提交时会进行等待(当打开同步提交时)。
LSN检查仅存在于共享缓冲区管理器中,不存在于临时表使用的本地缓冲区管理器中,因此,对临时表的操作不能被 WAL记录。
XLog:Transaction log,事务的日志,通常指的是记录时的在内存中的事务日志,WAL指的是持久化后的日志 LSN:Log sequence number,日志序列号,这是WAL日志唯一的、全局的标识 bgwriter:PostgreSQL负责将脏页面刷入磁盘的进程 walwriter:PostgreSQL负责将WAL刷入磁盘的进程
在崩溃恢复时
- 从检查点开始,回放WAL日志,如果数据页面的LSN小于WAL记录的LSN,则说明数据页面比较旧,需要进行回放,反之则不需要回放,就会跳过回放过程。
在回放的过程中,checkpointer会持续地做检查点,让数据页面向前更新,这样万一又重启了,能更快地恢复。
checkpointer:PostgreSQL中的检查点进程
日志内容
PostgreSQL的WAL是REDO类型的。我们看一下PostgreSQL的日志的格式和包含的信息。
PG社区还在实现Zheap的特性,这是PG的新的日志格式,是一种REDO/UNDO日志,届时将能够很好地解决PG数据库的膨胀问题,我们将在后续的文章中介绍这一特性。
WAL文件
PostgreSQL的WAL文件存放于数据目录下的pg_wal目录里,ls一下可以看到以下文件:
-rw------- 1 postgres users 1073741824 Apr 17 08:41 000000010000000000000001
-rw------- 1 postgres users 1073741824 Apr 14 11:09 000000010000000000000002
-rw------- 1 postgres users 1073741824 Apr 14 11:09 000000010000000000000003
drwx------ 2 postgres users 4096 Apr 14 11:09 archive_status #和备份有关,表示日志文件的备份状态,这里不做介绍
可以看到这里每个WAL文件大小为1GB(这和我们configure、initdb时的参数有关),命名为一串16进制的串,这个串和时间线以及LSN紧密相关,每个WAL文件都包含了特定时间线内,从某个LSN开始到某个LSN结束的WAL日志。根据一个特定的LSN,可以知道对应的WAL日志的文件名,以及在文件中所处的位置。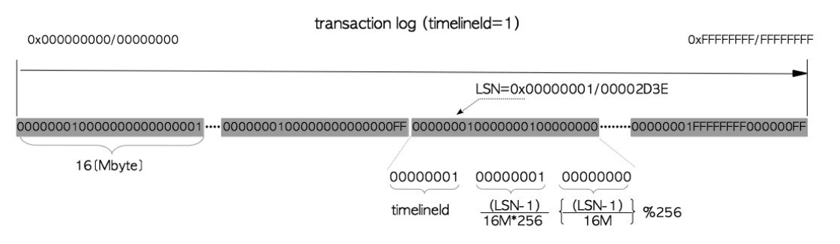
事务日志与WAL段文件 《PostgreSQL指南:内幕探索》
WAL日志
使用pg_waldump工具我们可以看到PostgreSQL的日志,每一条日志可以理解为一次对数据库的操作记录:
rmgr: Standby len (rec/tot): 42/ 42, tx: 699, lsn: 0/410E21B8, prev 0/410E2180, desc: LOCK xid 699 db 13933 rel 221196
rmgr: Heap len (rec/tot): 59/ 59, tx: 699, lsn: 0/410E21E8, prev 0/410E21B8, desc: INSERT off 4, blkref #0: rel 1663/13933/221196 blk 0
rmgr: Transaction len (rec/tot): 38/ 38, tx: 699, lsn: 0/410E2228, prev 0/410E21E8, desc: COMMIT 2020-04-17 08:38:04.881890 UTC
这是一条id为699的事务所产生的三条日志,做了锁表、插入数据、提交的操作,让我们对照着SQL看一下这条日志是怎么生成的:
postgres=# begin;
BEGIN --开启一个新的事务,此时不会分配事务ID,也不会生成WAL
postgres=# lock table t;
LOCK TABLE --锁住表t,生成事务ID 699,生成锁表的日志0/410E21B8
--锁住了(db:13933, rel:221196)的表(我们后续会聊这条日志如何在热备模式下发挥作用)
postgres=# insert into t select 1;
INSERT 0 1 --向表t插入一条数据,生产插入数据的日志0/410E21E8
--向表(1663,13933,221196),BlockNumber为0的page,offset为4的tupe的位置,写入了一条数据,该页面的LSN会被更新为这条日志的LSN
postgres=# end;
COMMIT --提交,生成提交日志0/410E2228(数据库会等待这条日志刷盘再返回给客户端,这是保证持久化的关键,当然得设置同步提交为on)
--这条日志包含了事务的提交状态,以及提交的时间(我们后续会聊这个时间如何在时间点还原下发挥作用)
在上面产生了三条不同类型的日志,有Standby,Heap,Transaction三种类型,这里的类型指的是资源管理器的类型。在PostgreSQL中,对数据不同的操作被进行了分类,例如对序列号的操作、对BTree索引的操作,每一类操作类型会使用对应的资源管理器进行管理,包括进行记录和回放。
下图展示了在PostgreSQL 10中所包含的资源管理器的类型,共计有22种(在最新的PostgreSQL 12中,资源管理器的类型未增加),涉及到了堆元组操作、索引操作、序列号操作等。

PostgreSQL 10的资源管理器 《PostgreSQL指南:内幕探索》
记录流程
在数据库的运行过程中,很多操作需要记录WAL日志,一个标准的记录流程是这样的:
- 对需要修改的页面进行PIN和LOCK操作
- START_CRIT_SECTION() 开启临界区,此时不允许任何错误,若发生错误,直接报PANIC错误
- 将需要的修改应用到页面上
- 将页面标记为脏,这必须发生在WAL日志插入前
- 如果该表需要进行插入WAL记录的操作,初始化一条XLOG并插入,然后设置页面的LSN
- END_CRIT_SECTION() 结束临界区。
- 对需要修改的页面进行UNPIN和UNLOCK操作
buffer和page的区别在于buffer是内存中的,page是在存储中的,buffer中有块区域叫做frame(页框), page会被读取到frame中以供读写 PIN buffer表示从磁盘中置换入page到frame中,并且不能被置换出去 LOCK > buffer表示锁定住buffer,使其他进程无法读写frame(page)
我们可以结合插入数据的代码看一下插入数据是WAL是如何记录的:
调用顺序:PostgresMain->exec_simple_query->PortalRun->PortalRunMulti->ProcessQuery->
standard_ExecutorRun->ExecutePlan->ExecModifyTable->ExecInsert->
heapam_tuple_insert->heap_insert
heap_insert(Relation relation, HeapTuple tup, CommandId cid,
int options, BulkInsertState bistate)
{
// 获取将要插入的heaptup
heaptup = heap_prepare_insert(relation, tup, xid, cid, options);
// 读取buffer,在内部会自动PIN buffer,LOCK buffer
buffer = RelationGetBufferForTuple(relation, heaptup->t_len,
InvalidBuffer, options, bistate,
&vmbuffer, NULL);
// 开始临界区
START_CRIT_SECTION();
// 插入数据
RelationPutHeapTuple(relation, buffer, heaptup,
(options & HEAP_INSERT_SPECULATIVE) != 0);
// 将页面标记为脏页
MarkBufferDirty(buffer);
// 开始记录WAL日志,RelationNeedsWAL,如果是临时表,就不需要WAL日志了
if (!(options & HEAP_INSERT_SKIP_WAL) && RelationNeedsWAL(relation))
{
// info信息,标记记录为XLOG_HEAP_INSERT类型的,将来将会使用heap_xlog_insert回放
// 如果是新页,还会标记这个为XLOG_HEAP_INIT_PAGE,就表示回放时需要先初始化新页
uint8 info = XLOG_HEAP_INSERT;
if (ItemPointerGetOffsetNumber(&(heaptup->t_self)) == FirstOffsetNumber &&
PageGetMaxOffsetNumber(page) == FirstOffsetNumber)
{
info |= XLOG_HEAP_INIT_PAGE;
bufflags |= REGBUF_WILL_INIT;
}
// 初始化一条XLog记录,并插入
XLogBeginInsert();
XLogRegisterData((char *) &xlrec, SizeOfHeapInsert);
...
// 这是一条RM_HEAP_ID类型的日志,将来回放的时候,将会根据这个ID使用heap_redo进行回放
recptr = XLogInsert(RM_HEAP_ID, info);
// 设置页面的LSN,值得注意的是这里的LSN用的是EndRecPtr,为什么要在最后设置?
PageSetLSN(page, recptr);
}
//结束临界区
END_CRIT_SECTION();
//UNLOCK buffer,UNPIN buffer,之后buffer可以被其他事务使用,或者置换出去
UnlockReleaseBuffer(buffer);
if (vmbuffer != InvalidBuffer)
ReleaseBuffer(vmbuffer);
}
上述代码是一个典型的插入数据、写WAL的一个流程,但关于这个流程还是有不少疑问:
- 先修改buffer里的数据,再写WAL,会不会导致数据落盘而写WAL不成功
回到前面的 缓冲区管理器能够写出一个脏页面 的前提,这个是数据库需要确保不能发生的。需要这个前提的原因在于,PostgreSQL的日志类型时REDO的,数据只能往前回放,无法向后恢复,因此数据页面不能比WAL“新” - 为什么将buffer标记为脏要发生在WAL日志插入前 如果在WAL日志插入后将buffer标记为脏,有可能做检查点时,使用了新的LSN,但是由于该页不是脏页导致跳过刷脏,导致该页数据在磁盘中的是旧的,但是检查点已经超前了,后续崩溃恢复时,该页面就会存在这条WAL日志未回放的情况
- 为什么要使用EndRecPtr,可以使用RecPtr吗
不只是页面的LSN,包括检查点的LSN、刷数据的LSN(flushPtr)等也是使用的EndRecPtr,以刷数据的LSN为例,使用EndRecPtr就能表示已经刷完了到哪个LSN结束的WAL日志对应的数据,要是使用RecPtr就很费解了;检查点的LSN使用EndRecPtr,就能方便地在下次回放时,找到下一条需要回放的日志的LSN。在页面的LSN中,使用就EndRecPtr可以和上述逻辑维持一致了;而且RecPtr在影响完页面后,对这个页面来说已经不重要了,我们关心的是下一条影响这个页面的WAL记录
另外,这里仅仅展示了最简单的插入数据的流程,生成的WAL日志也比较简单,有一些比较复杂的对数据库的修改,比如涉及到索引的分裂,需要创建一个新页面,再写入新key,这需要至少记录两个WAL(涉及到连续分裂会更多),当回放处于这两个WAL日志之间时,数据库处于一个“中间状态”,这就需要一些技巧来隐藏这种状态。
恢复流程
数据库从崩溃中重启,从控制文件中,获知上一次没有正常停库,进入崩溃恢复状态,从控制文件中读取到上一次检查点的位置,从检查点开始进行严格的串行回放。
- 读取到新的日志,解析日志头部,根据日志的类型,将日志交由对应资源管理器回放
- 解析该WAL日志,根据具体的操作类型,交由具体的函数进行回放
- 解析WAL日志内容
- XLogReadBufferForRedo,读取需要修改的页面,进行PIN和LOCK操作,并根据LSN确认是否需要REDO
- 如果需要REDO,则将日志应用到页面上,更新页面的LSN,标记页面为脏页
- 对需要修改的页面进行UNPIN和UNLOCK操作,其他进程可以使用该页面,bgwriter可以向下刷该页面
我们可以结合插入数据的代码看一下redo是如何工作的:
调用顺序:StartupXLOG->heap_redo->heap_xlog_insert
heap_xlog_insert(XLogReaderState *record)
{
// 如果xl_info中存在XLOG_HEAP_INIT_PAGE,则说明需要初始化页
if (XLogRecGetInfo(record) & XLOG_HEAP_INIT_PAGE)
{
buffer = XLogInitBufferForRedo(record, 0);
page = BufferGetPage(buffer);
PageInit(page, BufferGetPageSize(buffer), 0);
action = BLK_NEEDS_REDO;
}
else
// action是根据page LSN和record LSN计算得到的
// 如果page LSN<record LSN,说明页面比较旧,需要进行redo
action = XLogReadBufferForRedo(record, 0, &buffer);
if (action == BLK_NEEDS_REDO)
{
...
// 构建htup (HeapTuple),这个就是新插入的数据
htup = &tbuf.hdr;
...
// 向page中插入这条htup
if (PageAddItem(page, (Item) htup, newlen, xlrec->offnum,
true, true) == InvalidOffsetNumber)
elog(PANIC, "failed to add tuple");
// 将该page的LSN设置为这条记录的LSN
PageSetLSN(page, lsn);
if (xlrec->flags & XLH_INSERT_ALL_VISIBLE_CLEARED)
PageClearAllVisible(page);
// 将该buffer标记为脏
MarkBufferDirty(buffer);
}
// UNLOCK buffer,UNPIN buffer
if (BufferIsValid(buffer))
UnlockReleaseBuffer(buffer);
}
这是一条插入数据的WAL日志的回放流程,我们可以看到,记录WAL日志的代码和回放部分的代码是高度一致的,这也该过程被叫做回放的原因。
在崩溃恢复的过程中,数据库已经看不到具体的SQL语句了,只有一条条操作记录,恢复管理器只负责机械地将这些记录应用到数据上,将数据库还原到崩溃前的状态。
部分写问题
现在的磁盘/文件系统大多是4KB对齐的(部分老的磁盘甚至是512字节的扇区),这样就只能保证4KB的原子读写。这就导致了当写入一个较大页面时,会在文件系统、磁盘驱动里被拆分为几次I/O,当写入到一半时,就会发生部分写问题,导致数据页面或者WAL文件损坏。
MySQL也存在类似的问题,它采用了一个叫做double write buffer技术解决了这个问题,但也带来了额外的开销。
PostgreSQL有自己的一套解决的方法:
- 当数据页面损坏时,有一个叫做FullPageWrite(FPW)的特性来保证数据的完整性
- 数据文件可以打开checksum用于校验,由于较为影响性能,所以需要在初始化数据库时手动指定开启
- 每条WAL记录都包含crc校验码,来检查WAL记录是否正确
- 每个WAL页面,都包含magic,来检查页面的有效性
FullPageWrite(FPW)的原理是,当做了checkpoint后,如果某个数据页面是第一次被修改,那么就会记录完整的数据页面到WAL文件中,当恢复时,就能够获取完整数据页面重新进行修复,因此哪怕数据页面被写坏了,也能够修复出来。当然这也会带来写放大的开销,尤其是当checkpoint十分频繁时,写放大会十分地严重。
该特性需要手动开启,如果数据页大小大于文件系统所提供的原子写粒度的话,就不需要这个特性了。
当WAL也出现错误时,又不巧碰上了崩溃恢复,需要这段WAL日志,很不幸就不能进行恢复了,数据库会及时地崩溃并告诉你无能为力。
但是WAL日志是预分配且一直是顺序写入的,因此也最多由于部分写会丢失尾部的部分WAL日志,且这部分WAL文件没落盘成功,数据库也不会返回事务成功(当同步提交为on时),因此WAL文件遇到部分写问题也没啥影响,直接丢弃这段不完整的WAL日志就行了。
至于更加麻烦的磁盘静默错误和内存错误的话,就很难在数据库层面解决了,一般会通过冗余校验的方式进行解决,例如磁盘的RAID技术(部分RAID级别),ECC内存等。
总结
本文简单描述了数据库崩溃恢复的基本原理,以及PostgreSQL是如何记录日志、进行崩溃恢复的。
本文严重参考了PG源码中的src/backend/access/transam/README,README的原理部分讲的十分清晰,以至于该文在这部分的原理只做了翻译,以及结合源码进行了分析,该README中还包含更多的细节,如果对这部分原理感兴趣,强烈建议去阅读这篇文档。
在下一篇文章中,我将会详细描述在热备的情况下备库如何进行恢复,以及如何做到按时间点还原(PITR),这部分README没有进行描述,希望能将这部分原理清晰地带给大家。
参考
《Intro to Database Systems》CMU Database Group
《数据库系统实现》机械工业出版社
https://github.com/postgres/postgres/blob/master/src/backend/access/transam/README
https://www.pgcon.org/2012/schedule/track/Hacking/408.en.html
https://www.enterprisedb.com/blog/zheap-storage-engine-provide-better-control-over-bloat
http://www.vldb.org/pvldb/vol10/p337-arulraj.pdf
https://chenhuajun.github.io/2017/09/02/PostgreSQL如何保障数据的一致性.html