MySQL · 最佳实践 · X-Engine并行扫描
Author: yanxian
概述
目前RDS(X-Engine)主打的优势是低成本,高性价比,在MySQL生态下帮助解决用户的成本问题。使用X-Engine的用户一般数据量都较大,比如已经在集团大规模部署的交易历史库,钉钉历史库以及图片空间库等。数据既然存储到了X-Engine,当然也少不了计算需求,因此如何高效执行查询是未来X-Engine一定要解决的问题。目前,在MySQL体系下,每个SQL都至多只能使用一个CPU,由一个线程完成串行扫描行并进行计算。X-Engine引擎需要提供并行扫描能力,这样让一个SQL具备利用多核扫描数据能力,整体缩短SQL执行的响应时间。
串行扫描
在具体介绍X-Engine并行扫描之前,先简单介绍下目前X-Engine串行扫描的逻辑。大家知道数据库引擎的核心区别在于数据结构,比如InnoDB引擎采用B+Tree结构,而X-Engine则采用LSM-Tree结构,两者各有特点,B+Tree结构对读更友好,而LSM-Tree则对写则更友好。
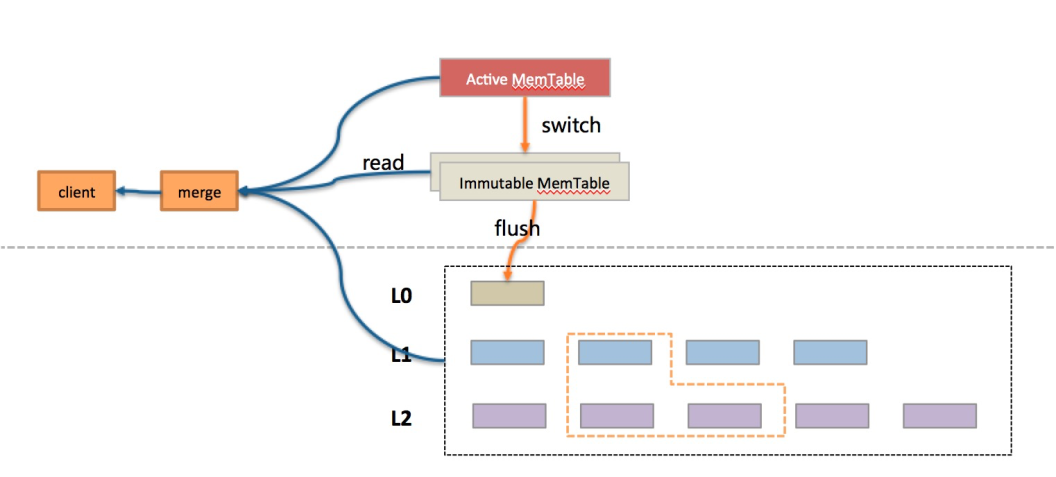
对于一条SQL,在优化器选择好了执行计划以后,扫描数据的方式就确定了,或是走索引覆盖扫描,或是走全表扫描,或者走range扫描等,这点通过执行计划就可以直观的看到。无论哪种方式,本质来说就是两种,一种是点查询,一种是范围查询,查询的数据要么来自索引,要么来自主表。X-Engine的存储架构是一个类LSM-tree的4层结构,包括memtable,L0,L1和L2,每一个层数据都可能有重叠,因此查询时(这里主要讨论范围查询),需要将多层数据进行归并,并根据快照来确定用户可见的记录。
如下图所示,从存储的层次上来看,X-Engine存储架构采用分层思想,包括memtable,L0,L1和L2总共4层,结合分层存储和冷热分离等技术,在存储成本和性能达到一个平衡。数据天然在LSM结构上存在多版本,这种结构对写非常友好,直接追加写到内存即可;而对读来说,则需要合并所有层的数据。
并行扫描
X-Engine并行扫描要做的就是,将本来一个大查询扫描,拆分成若干小查询扫描,各个查询扫描的数据不存在重叠,所有小查询扫描的并集就是单个大查询需要扫描的记录。并行扫描的依据是,上层计算对于扫描记录的先后顺序没有要求,那么就可以并行对扫描的记录做处理,比如count操作,每扫描一条记录,就对计数累加,多个并发线程可以同时进行。其它类型的聚集操作比如sum,avg等,实际上都符合这个特征,对扫描记录的先后顺序没有要求,最终归结到一点都是需要引擎层支持并行扫描。
如下图所示,X-Engine整个包括4层,其中内存数据用memtable表示,磁盘数据用L0,L1和L2表示,memtable这一层是一个简单的skiplist,每个方框表示一条记录;L0,L1和L2上的每个方框表示一个extent,extent是X-Engine的概念,表示一个大的有序数据块,extent内部由若干个小的block组成,block里面的记录按key有序排列。
根据分区算法得到若干分区后,可以划分分区,不同颜色代表不同的分区,每个分区作为一个并行task投入到队列,worker线程从TaskQueue中获取task扫描,各个worker不需要协同,只需要互斥的访问TaskQueue即可。每个扫描任务与串行执行时并无二样,也是需要合并多路数据,区别在于查询的范围变小了。
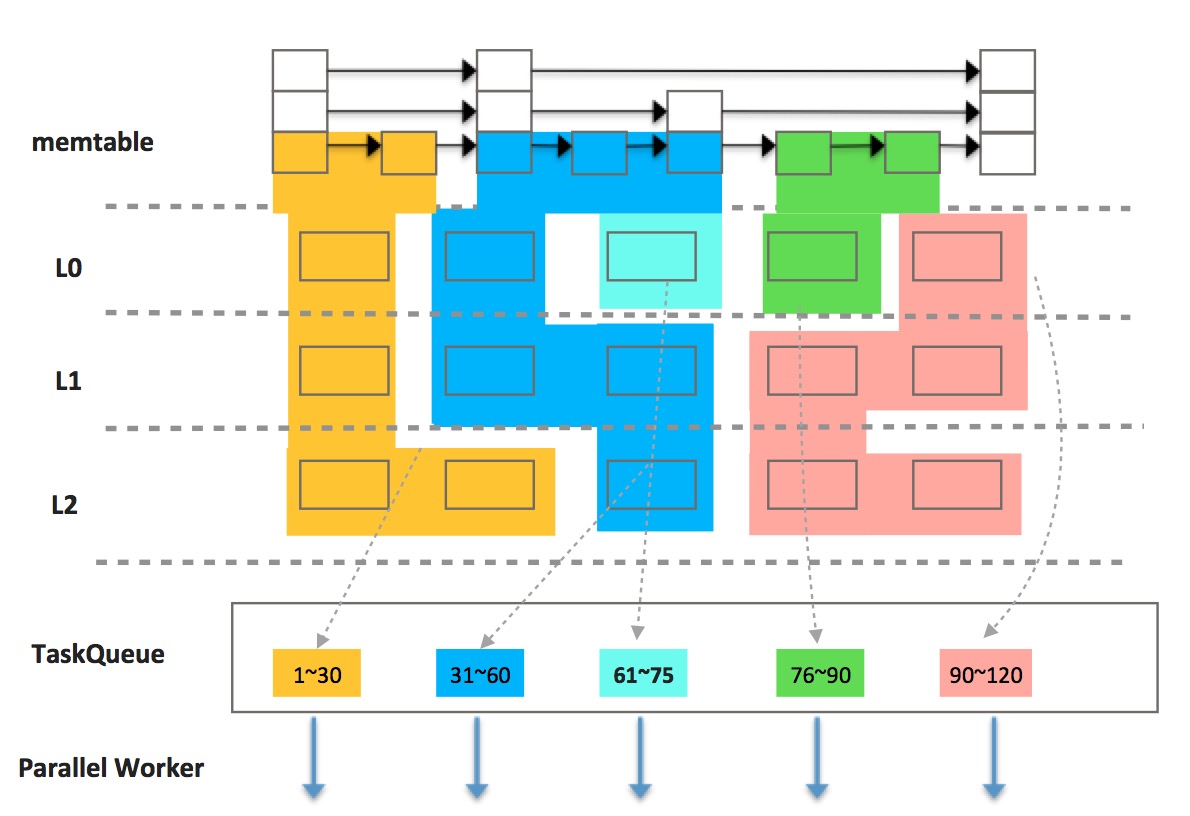
分区算法
将查询按照逻辑key大小划分成若干个分区,各个分区不存在交叠,用户输入一个range[start, end),转换后输出若干[start1,end1),[start2, end2)…[startn,endn),分区数目与线程数相关,将分区数设定在线程数的倍数(比如2倍,具体倍数可调),目的是分区数相对于线程数多一点,以均衡各个线程并行执行速度,提升整体响应时间。
数据按冷热分散存储在memtable,L0,L1和L2这4层,如果数据量很少,可能没有L1或者L2,甚至数据在全内存中。我们讨论大部分情况下,磁盘都是有数据的,并且memtable中的数据相对于磁盘数据较小,主要以磁盘上数据为分区依据。分区逻辑如下:
1).预估查询范围的extent数目
2).根据extent数目与并发线程数比例,预估每个task需要扫描的extent数目
3).对于第一个task,以查询起始key为start_key,根据每个task要处理的extent数目,以task中最后一个extent的largest_key信息作为end_key
4).对于其它task,以区间内第一个extent的smallest_key作为start_key,最后一个extent的largest_key作为end_key
5).对于最后一个task,以区间内第一个extent的smallest_key作为start_key,以用户输入的end_key作为end_key
至此,我们根据配置并发数,将扫描的数据范围划分成了若干分区。在某些情况下,数据可能在各个层次可能分布不均匀,比如写入递增的场景,各层的数据完全没有交集,导致分区不均,因此需要二次拆分,将每个task的粒度拆地更小更均匀。同时,对于重IO的场景(扫描的大部分数据都无法cache命中),X-Engine内部会通过异步IO机制来预读,将计算和IO并行起来,充分发挥机器IO能力和多核计算能力。
对比InnoDB并行扫描
InnoDB引擎也提供了并行扫描的能力,目前主要支持主索引的count和check table操作,而实际上X-Engine通用性更好,无论是主表,还是二级索引都能支持并行扫描。InnoDB与X-Engine一样是索引组织表,InnoDB的每个索引是一个B+tree,每个节点是一个固定大小的page(一般为16k),通过LRU缓存机制实现内外存交换,磁盘上空间通过段/簇/页三级机制管理。InnoDB的更新是原地更新,因此访问具体某个page时,需要latch保护。X-Engine的每个索引是一个LSM-tree,内存中以skiplist存在;外存中数据包括3层L0,L1和L2,按extent划分,通过copy-on-write多版本元数据机制索引extent,每次查询对应的一组extent都是静态的,因此访问时,没有并发冲突,不需要latch保护extent。
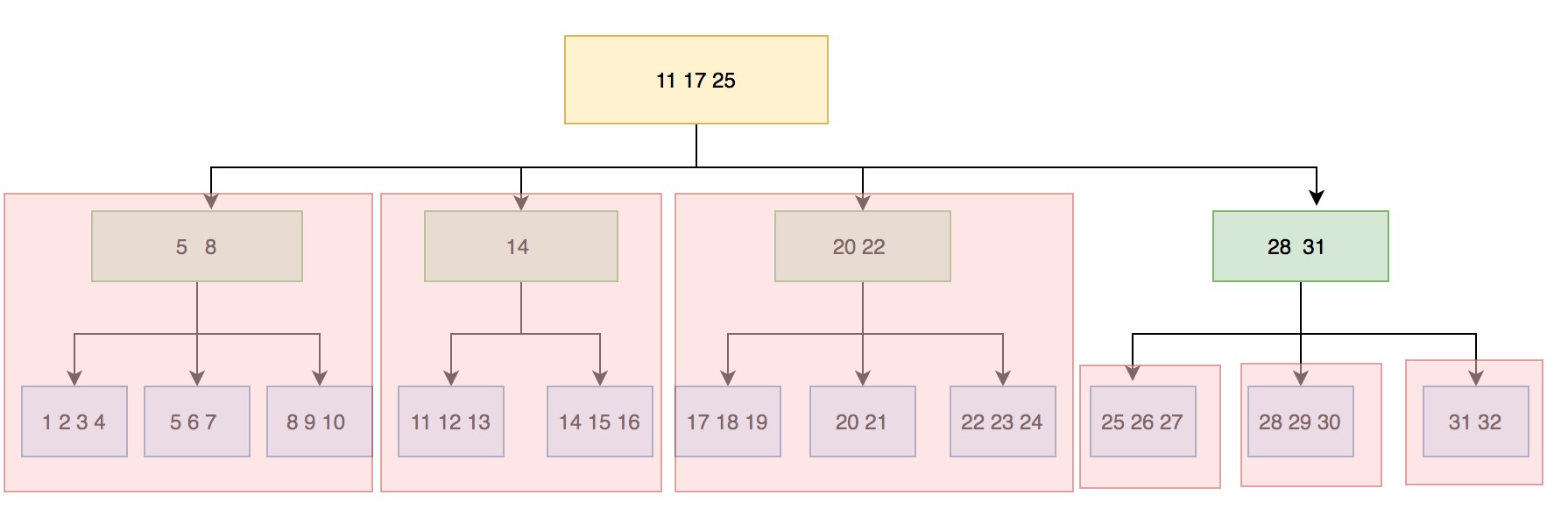
存储结构差异导致分区和扫描的逻辑也不一样,InnoDB的分区是基于B+tree物理结构拆分,根据线程数和B+tree的层数来划分,最小粒度能到block级别。X-Engine的分区分为两部分,内存中memtable粒度是记录级;外存中数据是extent级,当然也可以做到block级别。两者最终的目的都是希望充分利用多核CPU资源来进行扫描。下图是InnoDB的分区图。
InnoDB和X-Engine都是通过MVCC机制解决读不上锁的问题,进行扫描时需要过滤不可见记录和已删除的记录。InnoDB的delete记录有delete-mark,多版本记录存储在特殊的undo段中,并通过指针与原始记录建立关联,事务的可见性通过活跃事务链表判断。X-Engine是追加写方式更新,没有undo机制,多版本数据分布在LSM-tree结构中,delete记录通过delete-type过滤,事务的可见性通过全局提交版本号判断。
InnoDB扫描时,根据key搜索B+tree,定位到叶子节点起始点,通过游标向前遍历;因此分区后,第一次根据start_key搜索到叶子节点的指定记录位置,然后继续往后遍历直到end_key为止。X-Engine扫描时,会先拿一个事务snapshot,然后再拿一个meta-snapshot(访问extent的索引),前者用于记录的可见性判断,后者用于“锁定”一组extent,这样我们有了一个“静态”的LSM-tree。基于分区的范围[start_key,end_key],构建堆进行多路归并,从start_key开始输出记录,到end_key截止。
性能测试
通过配置参数xengine_parallel_read_threads来设置并发线程数,就能开始并行扫描功能,默认这个值为4。我这里做一个简单的实验,通过sysbench导入2亿条数据,分别配置xengine_parallel_read_threads为1,2,4,8,16,32,64,测试下并行执行的效果。测试语句为select count(*) from sbtest1;
测试环境
硬件:96core,768G内存
操作系统:linux centos7
数据库:MySQL8.0.17
配置:xengine_block_cache_size=200G, innodb_buffer_pool_size=200G
采用纯内存测试,所有数据都装载进内存,主要测试并发效果。
测试结果
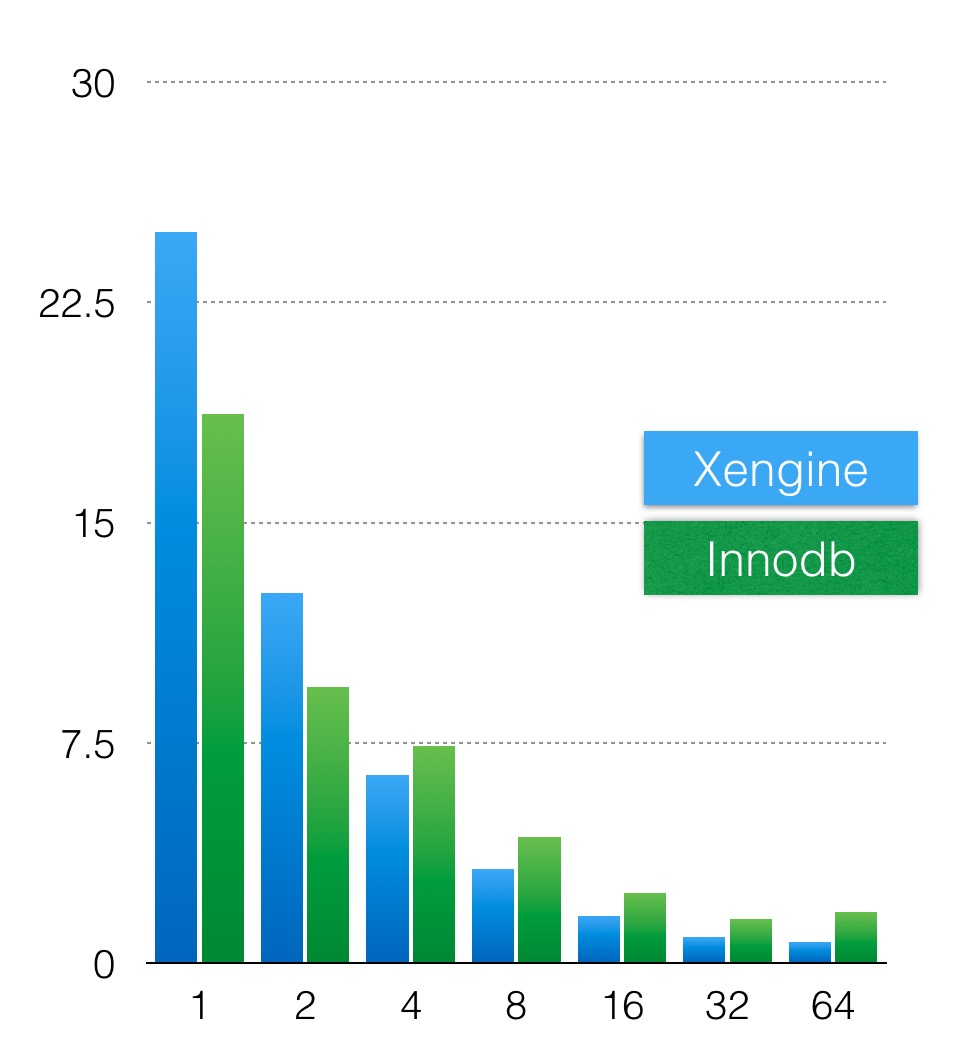
横轴是配置并发线程数,纵轴是语句执行时间,蓝色轴是xengine的执行时间,绿色轴是innodb执行的时间,当配置32个并发时,扫描2亿条数据只需要1s左右。
结果分析
可以看到X-Engine和Innodb都具有较好的并发扫描能力,X-Engine表现地更好,尤其是在16线程以后,InnoDB随着线程数上升,执行时间并没有显著下降。这个主要原因是InnoDB的并行是基于物理Btree的拆分,而X-Engine的并行是基于逻辑key的拆分,因此拆分更均匀,基本能随着线程数增加,响应时间成倍地减少。
总结与展望
目前X-Engine的并行扫描还只支持简单count操作,但已经显示出了充分利用CPU多核的能力。我们将继续向上改造执行器接口,以支持更多的并行操作。无论是RDS(X-Engine)还是我们的分布式产品PolarDB-X都将在X-Engine的基础上,让单条SQL跑地更快。