Redis · 最佳实践 · 集群配置:Redis Cluster
Author: 矽岸
在数据库领域,当数据量大到一定程度后,我们总是绕不开分布式这个话题。这个问题牵扯很多方面,
- 分片策略(Sharding):分库分表?水平切片?垂直切片?
- 数据备份:数据备份什么时候做?粒度是什么?怎样备份?
- 数据迁移:当数据分布发生拓扑变化的时候,怎么把数据从原来的节点迁移到新的节点上?
- 集群管理:如何管理整个集群,如何把用户请求定向到某个特定的节点上?
这些问题很很多不同的解法,在不同的使用场景,不同的数据库设计结构下有不同的选择。大体上讲,因为相对简单,NoSQL在这个方面的解决方案较传统SQL数据库使用更广泛。我们不妨来看看开源社区中使用最普遍的分布式解决方案之一:Redis Cluster,看看它是如何解决分布式的问题。
Redis Cluster集群
Redis Cluster是一个Redis的分布式部署形式,使用数据分片的办法把数据分配到不同的节点;每个节点可以有自己的备份节点(一个或多个)。整个集群之上另有一个叫做Redis Sentinel的分布式组件用以提供更丰富的HA能力。
下面我们就前一个章节提到的问题来看看Redis Cluster的解决方案。
数据分片
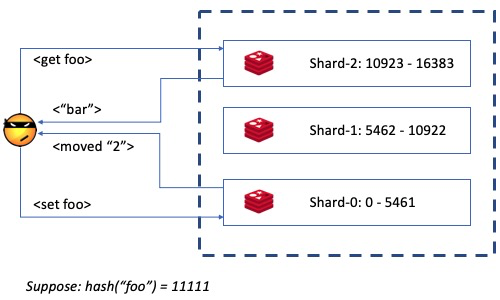
Redis Cluster使用 Slot 的概念:作为一个KV系统,它把每个key的值hash成0 ~ 16383之间的一个数。这个hash值被用来确定对应的数据存储在哪个节点中。集群中的每个节点都存储了一份类似路由表的东西,描述每个节点所拥有的 Slots;当用户请求一个不在本机的key的时候,它可以根据这个路由表找到正确的服务节点,然后回复给用户一个moved,告知用户正确的服务节点。
slot = CRC16(key) % 16383;- 是集群内数据管理和迁移的最小单位,保证数据管理的粒度易于管理;
- 每个节点都知道
slot在集群中的分布,并能把对应信息回复给无法服务的请求。 - 节点之间保持
Gossip通信
下面图例就是一个简单的、最小的3节点Redis Cluster数据分配例子。
数据备份
Redis的备份是最简单的Master-Slave备份。每个主节点都可以有若干个从节点跟随;从节点(Replica)可以提供高可靠性(HA),也可以用作只读节点提供高吞吐量。
通过加入针对每个节点的复制备份能力,Redis Cluster在单个数据粒度上提供了高可用性。整个部署架构从前一张图中的简单分布式Sharding结构演变为下图中所示的结构。
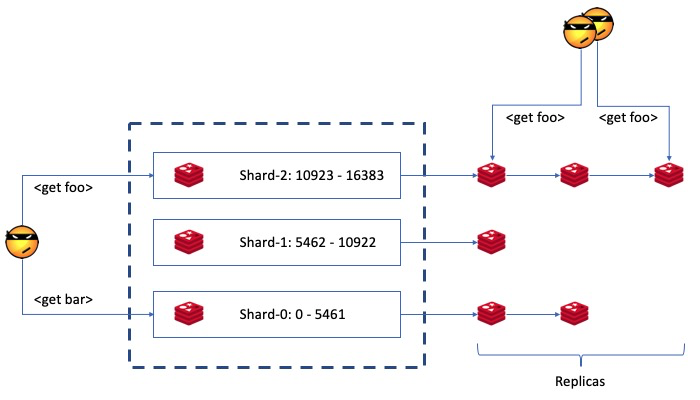
数据备份架构中,主节点把自己的状态通过AOF异步(缺省方式)传送给从节点。多个从节点可以使用级联的方式传输数据,而不用全部都从主节点获得,以此减轻对主节点的性能压力。从节点不光可以用来备份数据保证高可用,也可以担任只读节点的任务,提供压力分流。
数据迁移
Redis Cluster中的数据迁移又称作Reshard,一般是因为有节点的变化或者是做load balancing。简单的讲,Reshard就是把一些slots从一个节点转移到另一个节点。
Reshard的原理并不复杂:
- 外部工具向某分片发出
migrate命令,触发一个或者多个(3.2开始支持)key的迁移。 - 接收到
migrate命令的分片,即迁出分片,将对应的key进行序列化后发往迁入分片,并阻塞等待迁入分片的返回。 - 迁入分片通过
restore-asking命令将收到的key进行应用,并返回成功给迁出分片。 - 迁出分片收到应答后,删除对应的key,并将
migrate命令转化为del命令并同步给同步和记录到AOF中供replicas消费,完成迁移。
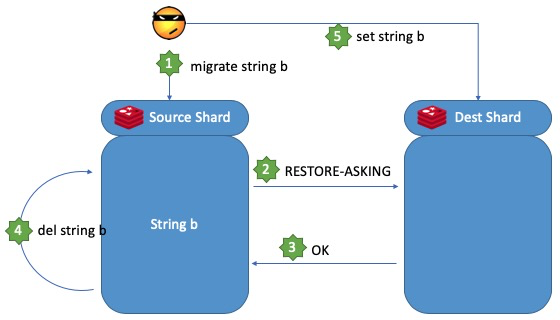
上面图例就是一个Reshard的流程示意,我们用一个string b来指代若干个slots;图中的数字代表步骤的顺序。
集群管理
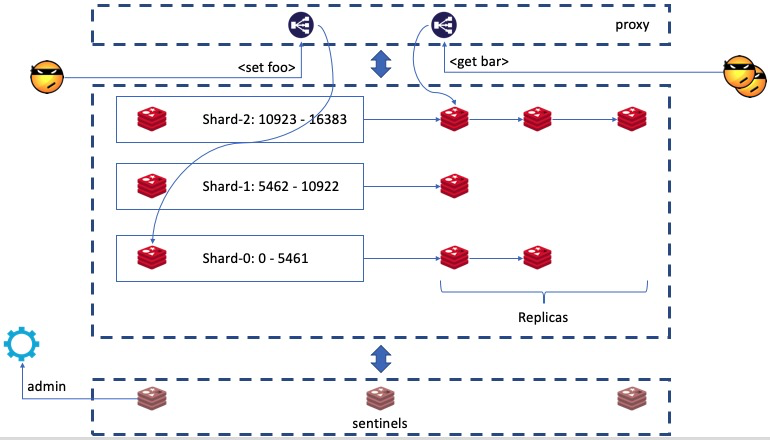
Redis Cluster集群管理引入了一个新的组件,叫做Redis Sentinel,在整个集群的纬度上提供高可用的能力。简单的讲,它类似一个集群的Registry,包含监控、报警、自动切换、配置管理等常见功能。另外,Sentinel本身也是分布式部署,采用多数派算法维持状态的一致性。
- Sentinels监视所有的数据节点
- Sentinels监视所有其他Sentinels
- 当Sentinels对节点宕机达成共识之后,选举出一个新的master(升级)并完成各种配置方面的联动
以我们在上面《数据备份》小节中的系统架构为基础,加上Sentinel,以及高可用的代理节点(HAProxy),就是一个典型的Redis Cluster部署形态。
小结
Less is more 这个概念重要且真实。Redis Cluster的分布式设计非常简单,也正因为如此非常容易维护。它的每个组件都很简单,功能不多;可以很简单的实现分布式设计。整个系统设计方面,它省略了很多一致性方面的考虑,用以换取高性能和健壮性。