PolarDB · 最佳实践 · 并行查询优化器的应用实践
Author: 智邻
PolarDB MySQL8.0重磅推出了并行查询引擎,充分利用硬件多核多CPU的优势,基于COST自动选择并行查询计划,显著提升了查询性能,查询耗时呈>指数级下降,体现了自研PolarDB数据库极高的性价比。 下面我们以TPCH的query-10为例,详细解析并行查询引擎对复杂查询的优化能力,为用户指引一条并行执行的性能高速公路。 Q10的SQL如下所示:
SELECT
c_custkey, c_name, sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal, n_name, c_address, c_phone, c_comment
FROM
customer, orders, lineitem, nation
WHERE
c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate >= date '1993-05-01'
and o_orderdate < date '1993-05-01' + interval '3' month
and l_returnflag = 'R'
and c_nationkey = n_nationkey
GROUP BY
c_custkey, c_name, c_acctbal, c_phone, n_name, c_address, c_comment
ORDER BY
revenue desc
LIMIT 20;
从SQL语句中可以看出,这个查询首先是4个表的JOIN,然后进行GROUP BY分组聚合操作,最后对聚合操作的结果进行排序,并选择前20条输出。
串行查询测试
Q10是分析场景下最常见的操作,先JOIN,再聚合、最后排序输出。如果不开启并行查询开关,它的串行执行计划如下所示:
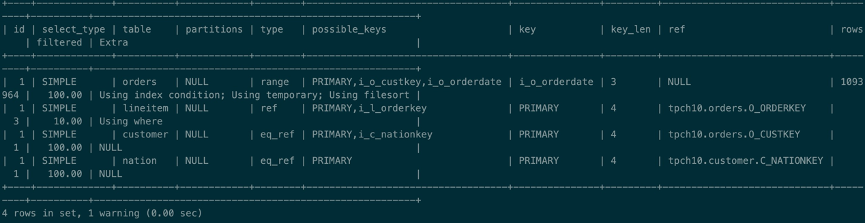 这个计划很简单,选择Orders表做为驱动表,然后做Nest loop join,当JOIN完成后,利用临时表来做聚合操作,最后进行排序。其中Orders表很大,即使Orders表上有条件可以帮助过滤大部分的数据,最终预估Orders表仍有大约110万行数据,最终执行时也比较长,大约需要16.29秒。
这个计划很简单,选择Orders表做为驱动表,然后做Nest loop join,当JOIN完成后,利用临时表来做聚合操作,最后进行排序。其中Orders表很大,即使Orders表上有条件可以帮助过滤大部分的数据,最终预估Orders表仍有大约110万行数据,最终执行时也比较长,大约需要16.29秒。
并行查询测试
PolarDB从8.0.1.0开始就支持并行查询,并且在8.0.2.0又做了全新的优化升级,接下来我们分别对2个版本进行并行查询的测试。 首先测试8.0.1.0版本,在8.0.1.0中开启并行查询,只需设置一个session级的参数max_parallel_degree,即最大并行度,简称DOP,用来设置执行>并行任务的最大worker线程数: 例:
set max_parallel_degree=32;
表示设置最大并行度DOP为32,根据实际查询的数据量,运行时的并行度可能小于32,但最大为32。并行查询计划如下所示:
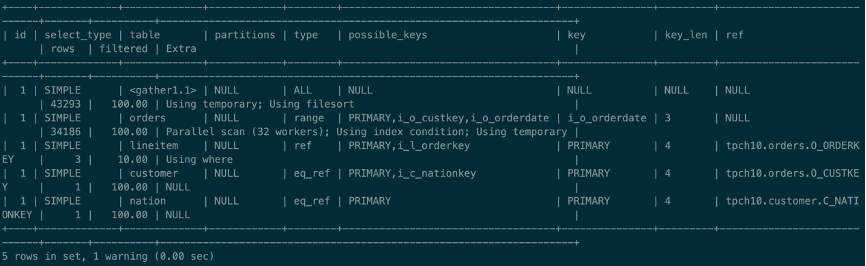 与之前的串行计划最大的不同在于计划上多了一行名为gather的计划,它表示汇集多个worker线程并行执行后的结果。同时在Orders表的Extra信息>也多了一些额外信息Parallel scan (32 workers),这表示Orders表将会执行并行扫描,同时有32个worker线程分别扫描Orders表的一部分数据,每个worker线程只需扫描大约3.4万行数据,然后并行完成JOIN,最后由Gather汇集所有JOIN的结果,执行聚合操作,完成排序后将结果返回。
查询总共大约3.46秒,相比串行性能已经有了明显提升,提升了大约5倍的性能。相信你已经感叹并行查询的威力,但是不要着急,后面的8.0.2.0的测试会给你带来更大的惊喜。
与之前的串行计划最大的不同在于计划上多了一行名为gather的计划,它表示汇集多个worker线程并行执行后的结果。同时在Orders表的Extra信息>也多了一些额外信息Parallel scan (32 workers),这表示Orders表将会执行并行扫描,同时有32个worker线程分别扫描Orders表的一部分数据,每个worker线程只需扫描大约3.4万行数据,然后并行完成JOIN,最后由Gather汇集所有JOIN的结果,执行聚合操作,完成排序后将结果返回。
查询总共大约3.46秒,相比串行性能已经有了明显提升,提升了大约5倍的性能。相信你已经感叹并行查询的威力,但是不要着急,后面的8.0.2.0的测试会给你带来更大的惊喜。
并行查询测试(8.0.2.0版本)
下面用8.0.2.0版本进行测试,在8.0.2.0中,对并行度做了重新定义,并行度DOP指的是活跃并行度,所谓活跃并行度指同时执行的worker线程数,>后面会根据示例再详细解释活跃并行度的概念。测试的并行度仍然设置为32,则并行计划如下图所示:
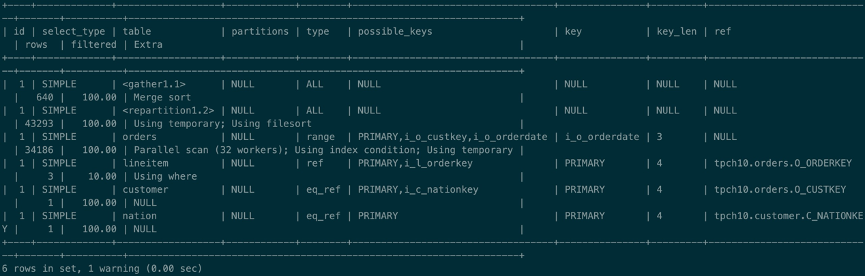 与8.0.1.0产生的并行计划相比,我们发现又多出了一行名为repartition的计划,它表示JOIN后的数据要通过repartition将数据根据group by的column重新分区,然后各个分区的数据在不同的worker上并行执行聚合操作和排序操作,最后Gather收集每个worker排序后的数据,此时只需要做一次Merge sort即可将数据全部排序完成,然后返回给用户。这里其实还有一个计划中未体现出来的优化,因为Query本身包含Limit,因此每个Worker只>需要返回limit指定的行数即可,这样gather就只需要收集32*(limit number)行数据即可。
测试结果出来了,简直不敢相信自己的眼睛,并行查询的总共执行时间居然只有0.75秒,下面我们为你分析一下为什么性能有这么大的提升。
与8.0.1.0产生的并行计划相比,我们发现又多出了一行名为repartition的计划,它表示JOIN后的数据要通过repartition将数据根据group by的column重新分区,然后各个分区的数据在不同的worker上并行执行聚合操作和排序操作,最后Gather收集每个worker排序后的数据,此时只需要做一次Merge sort即可将数据全部排序完成,然后返回给用户。这里其实还有一个计划中未体现出来的优化,因为Query本身包含Limit,因此每个Worker只>需要返回limit指定的行数即可,这样gather就只需要收集32*(limit number)行数据即可。
测试结果出来了,简直不敢相信自己的眼睛,并行查询的总共执行时间居然只有0.75秒,下面我们为你分析一下为什么性能有这么大的提升。
性能提升的秘密
在8.0.2.0版本中,为方便查看并行计划的细节,explain支持以树形方式展示并行计划,如下所示:
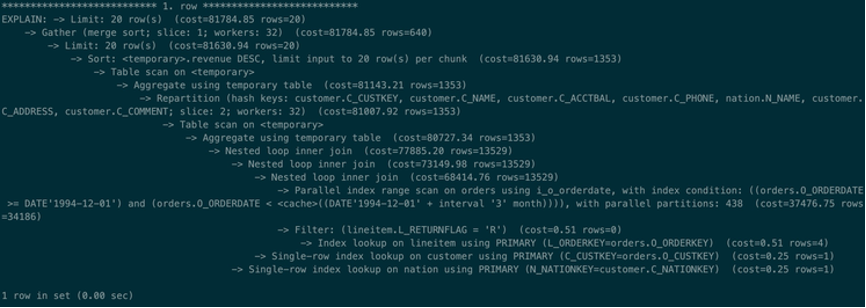 在树型结果中我们可以更清晰的看到并行查询计划的细节:
在树型结果中我们可以更清晰的看到并行查询计划的细节:
- 首先对Orders表做并行扫描,同时有32个worker线程分别扫描Orders表的部分数据,然后与其它3表做JOIN; JOIN完成后在当前worker线程>中做聚合操作,注意此时的聚合操作因为只是对当前worker线程的数据做聚合,相同分组的数据可能存在于多个不同的worker中,因此聚合结果只是对部分数据聚合的中间结果,还需要对完整的数据再做一个聚合操作。
- 当Worker线程完成对当前worker线程数据的聚合操作后,按group by的列将数据进行重新分区,将相同分区的数据发送到下一组worker线程的相同worker中,由下一组worker对重新分区后的数据进行并行聚合操作,然后再排序,并选择limit所需的20行发送给gather。
- 最后,因为同一worker线程的数据已经是有序的,所以Gather只需对每个worker线程发送的limit数据进行merge sort排序,然后选择limit所需的20行发送给用户即可。
到这里大家可能已经发现,与8.0.1.0有很大不同的是,在8.0.1.0中并行执行一共是32个worker线程,而在8.0.2.0中并行执行一共用于64个worker>线程,其中第一组32个worker线程的工作类似8.0.1.0的worker线程,而第二组32个worker线程用于执行重新分组后的并行聚合、排序和limit操作,而在8.0.1.0中只能在gather收集完数据后,串行执行后续的聚合、排序和limit操作,当数据量越大,串行操作的代价就越高,而并行操作的优势就越大。
为什么8.0.2.0会有那么大的性能提升?原因主要是将在8.0.1.0中只能串行执行的聚合、排序和limit等操作也变成了并行执行,这大大加速了查询>的执行效率。
这里我们还要借用这个示例来解释一下活跃并行度的概念。在8.0.2.0中,实际共使用64个线程,但为什么说DOP还是32呢?原因在于2组worker线程并不是同时执行的,在第一组worker未全部执行完成之前,第二组worker其实是不能开始执行的,因此虽然一共有64个worker线程,但可能同时执行的线程数是32个,这也就是活跃并行度的由来。
结束语
在传统OLTP应用中,总会有一些实时的分析、统计、汇总等操作,而传统的OLTP数据库对于这些操作的支持相对较弱,随着数据量的快速增加,复杂的分析统计性能成为了一个越来越明显的短板,但并行查询给我们带来了希望。通过对TPCH的并行测试结果来看,并行查询给我们带来了显著的性能提升。 我们坚信:用户的痛点就是我们的重点,为了满足用户不断增长的性能需求,PolarDB一直在努力。
附录
测试环境
| 硬件环境 | 实例配置 | 数据规模 | |||
|---|---|---|---|---|---|
| CPU | 64VCPU | innodb_buffer_pool_size | 8G | DATA SCALE | 10S |
| 内存 | 256G | sort_buffer_size | 2M |
测试结果
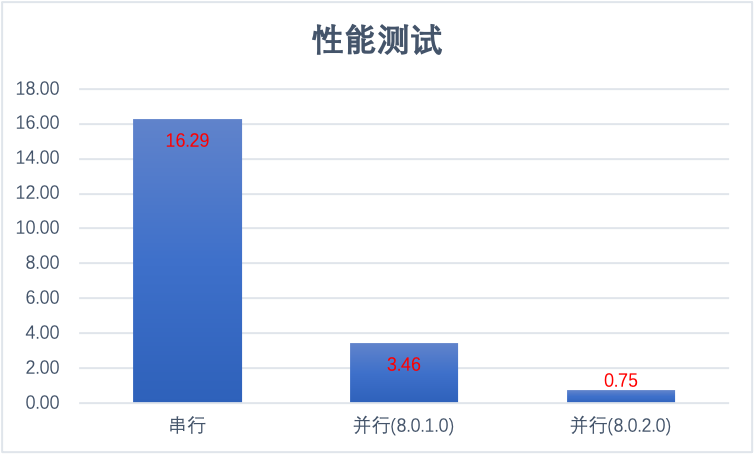
下面是一个实际测试的结果:(单位: 秒)(DOP: 32)
| 测试编号 | 串行查询 | 并行查询(8.0.1.0) | 并行查询(8.0.2.0) |
|---|---|---|---|
| TEST-1 | 16.1 | 3.46 | 0.76 |
| TEST-2 | 16.42 | 3.45 | 0.73 |
| TEST-3 | 16.34 | 3.48 | 0.76 |
| 平均 | 16.29 | 3.46 | 0.75 |
| 性能提升 | 470.71% | 2171.56% |