MySQL · HTAP · 分析型执行引擎
Author: 无哈
众所周知,MySQL是为了在线事务处理(OLTP)设计的开源数据库,一直以来弱于对于分析型业务场景的支持。如果有对MySQL数据库中的数据进行分析的业务场景,一般都是需要借助于第三方的ETL工具将数据导入到外部AP型数据库或者专门的数据仓库,然后将分析业务运行其上。这一处理方式对于现有业务系统引入了额外的复杂度和开销:
- 数据库之间数据传输的网络开销以及额外的数据存储开销
- 数据库之间数据同步处理逻辑的复杂性
- 多个数据库的管理复杂性和业务逻辑分流处理的复杂性
为了MySQL更好地支持数据分析业务,MySQL官方团队发布了新的分析执行引擎 – Heatwave,遗憾的是目前这一服务仅限于Orcale Cloud Infrastruct上使用。本文尝试结合MySQL Analytic Engine相关说明文档以及RAPID论文梳理一些MySQL分析引擎的基本信息。
HeatWave分析引擎以集群模式提供分析服务,如图1描述,集群包括常规的MySQL数据库节点和多个HeatWave分析引擎节点。应用程序只需要连接MySQL数据库节点,而无需连接到HeatWave节点。所有的查询依然是通过该节点进行分析,优化并生成执行计划。其中HeatWave插件以Secondary Engine的形式负责数据的载入和更新的同步、计算Query在HeatWave引擎执行的cost、生成HeatWave执行计划以及执行计划下发等。
 图 1. HeatWave架构图
图 1. HeatWave架构图
HeatWave存储
HeatWave将所有数据以列存格式存储在内存中,基本数据组织形式如图2所示。
- 基于行存数据做水平分区,基于水平分区,可以将查询在节点级并行执行来加速scan、join、group-by、aggr和top-k等算子,同时分区规划是与底层RAPID定制化硬件适配的。
- 分区内部将数据按照schema定义组织成列式存储,以引入向量化执行,每个向量化计算的单位是16KiB的vector,各列对应行的vector组合在一起成为chunk,每个partition会有多个chunks。
- 为了适配DMS,vector又划分为多个tile,每64行组成一个tile作为数据传输的最小单元。
- 为了减少内存的使用,所有存储的数据都会做编码或压缩。
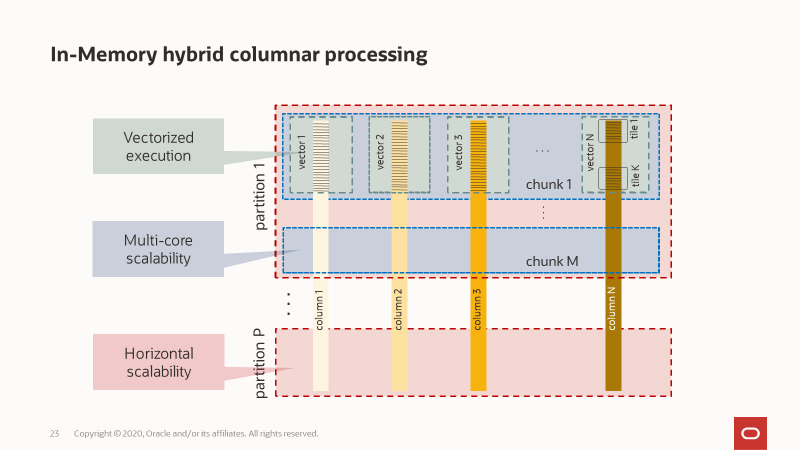 图 2. HeatWave存储布局
图 2. HeatWave存储布局
HeatWave Engine
现代计算设备随着更多特性的实现也导致能耗需求更大,为了满足云数据中心提高能耗比的需求,一般有两种考虑方向:
- 从业务逻辑出发尽可能地利用设备强大的计算能力,以匹配相应的能耗。
- 使用新型低能耗的硬件架构和组件针对业务场景从硬件层进行定制设计,并且在软件层面做一定的适配来达到性能和能耗的平衡。
HeatWave Engine选择的是后者,其针对关系型数据处理场景的业务模式进行硬件定制和相应的数据处理软件系统设计上适配。
RAPID硬件
HeatWave Engine的硬件核心部分称作Data Processing Unit(DPU),该SoC主要包括dpCores、Data Memeory/Cache、Data Move System(DMS)等特定组件,如图3所示。
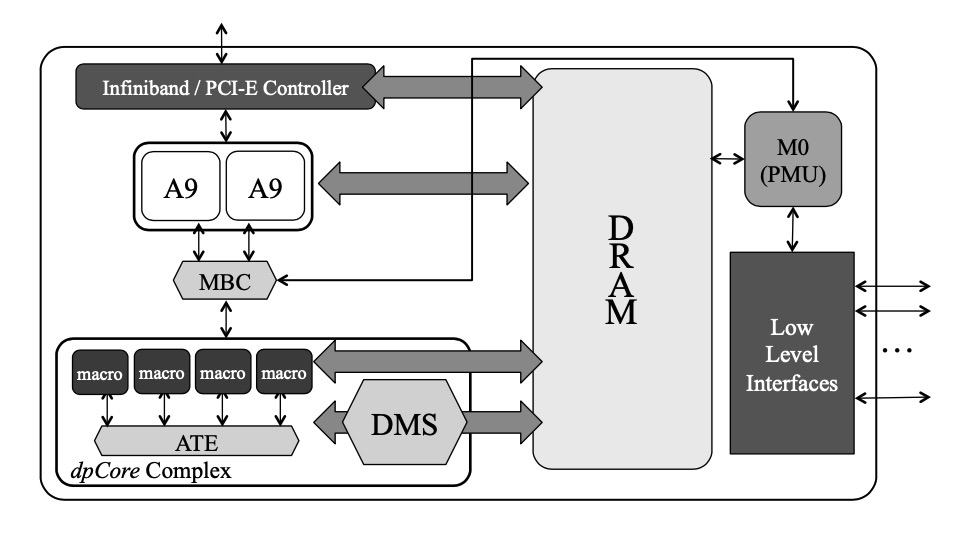 图 3. RAPID DPU
图 3. RAPID DPU
其中每个DPU包含32个dpCores,并均分为4组微服务单元以做数据并行处理。
dpCore内部采用类MIPS的64bits精简指令集架构,专门针对SELECT/JPIN等算子设计了单指令周期的BVLD(bit-vector load)、FILT(filter)、CRC32等指令。每个dpCore包含32KB的SRAM用作临时存储空间(DMEM),以及部分L1/L2 cache。dpCore实现了算数逻辑单元和Load-Store的双流水线。
RAPID SoC没有设计内存管理单元,而是采用直接寻址的访问方式。访问DMEM数据的主要方式是通过DMS子系统,其负责DRAM和dpCore之间的数据复制,利用DMS来操作DRAM和DMEM省去了通用CPU架构中的cache预取/替换等复杂逻辑。
Atomic Trasaction Engine(ATE)组件负责联通dpCores、消息传递、管理DMEM指针、中断处理以及信号同步等来完善dpCore之间的通信。
RAPID执行引擎
MySQL中的RAPID插件扩展了cost model,可以计算query在HeatWave节点上执行的cost以帮助优化器做决策,并且可以支持完整query和query片段下推。
RAPID插件基于pull的方式采用迭代器模型来执行算子和获取结果,RAPID Engine节点基于push的流式模型来处理RAPID插件生成并下推的执行计划。
限于篇幅,本文不逐个描述各个算子的优化以及执行流程。
HeatWave实践
HeatWave是作为插件以secondary engine的方式配合primary storage engine一起使用的,在部署好HeatWave集群后,就可以根据业务中的分析查询的特点来对Primary Engine上的表做变更已启用分析查询引擎,基本步骤包括:
- 通过CREATE TABLE或ALTER TABLE语句中指定SECONDARY_ENGINE=RAPID选项来开启RAPID
- 对于无需做分析的列指定NOT SECONDARY属性
- 对于字符串列,根据value分布的特点来决定采用变长压缩还是字典压缩
- 根据业务JOIN、GORUP-BY个特点来指定分区键
- 通过ALTER TABLE SECONDARY_LOAD将数据load到HeatWave执行节点,得益于8.0高版本平行扫描的功能,数据载入过程得到了加速;后期增量操作会由HeatWave插件以批量的方式自动同步。
RAPID使用限制包括:
- 不能用于无主键表,主键索引不能包含前缀列
- 最多支持470列
- 字典压缩的字符串列不能用于JOIN查询、LIKE、SUBSTR、CONCAT等函数
- 启用了RAPID引擎的表无法再做其他DDL
总结
本文粗略梳理Orcale Cloud Infratstructure推出的MySQL Analytic Engine服务中的HeatWave引擎的存储、RAPID引擎以及实践操作相关的信息。
- 采用专门定制的硬件来降低功耗是出彩的点, 特定业务场景采用定制的硬件可以更好地与软件结合起来做优化。
- 软件技术实现上算是中规中矩,目前还有一些不必要的使用限制。
对比来看,PolarDB存储引擎团队从尽可能利用计算资源的角度出发,设计了基于PolarDB的全内存列式存储,其特点:
- 基于SIMD的方式极大地并行化执行SCAN、JOIN、GROUP-BY、TOP-K等算子。
- 列式存储的存在对于应用层是“透明”的,优化器会自动生成相关的执行计划,并且与现有的PolarDB并行执行相兼容。
- 支持PolarDB的一写多读扩展。
参考文献
- RAPID论文: RAPID: In-Memory Analytical Query Processing Engine with Extreme Performance per Watt
- HeatWave用户手册 https://dev.mysql.com/doc/heatwave/en/
- MySQL Secondary Engine http://mysql.taobao.org/monthly/2020/11/04/