POLARDB · 引擎特性 · Logic Redo
Author:
众所周知,POLARDB 核心的技术是使用 InnoDB Redo Log 物理复制替代了 MySQL 原生的 Binlog 逻辑复制,并且在物理复制的基础上构建了一写多读的共享存储架构。物理复制相比于逻辑复制有很多优点(参考月报),但是 Binlog 逻辑日志是 MySQL 生态中重要的一环,如果说数据库让用户的数据 ‘在线’,那么 Binlog 日志可以让在线的数据准实时的流动,例如实时同步到下游做自建备库,分析数据做业务报表等等。虽然物理复制能够更好地满足云原生数据库的架构,但并不能取代逻辑日志的生态,那么如何解决两种不同类型日志的协同,即满足产品架构的演进又兼容开源的生态,就成为一个难题。
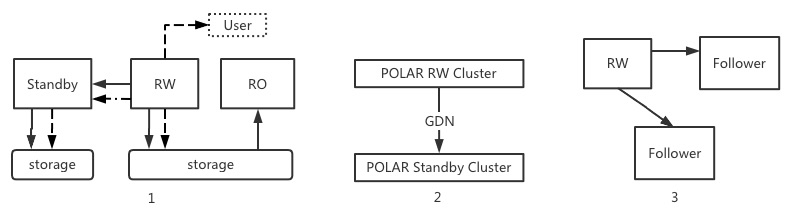
图1是目前共享存储的架构,实线表示 Redo Log 流,虚线表示 Binlog 流。集群内部 Redo 负责同步数据到 RO 和 Standby(灾备节点), Binlog 可以实时被用户拖走,同步到 Standby 并不应用,只是保留在本地。这个架构下大部分的灾备场景只需要切 RO 节点,在共享存储上可以保证两种日志的一致。Standby 的切换一般用于存储升级等场景,大部分都是 Plan Failover, 同样可以保证一致性。
图2是 GDN 的架构(官网介绍),两个集群通过 GDN 网络和 Redo 日志流同步两个 AZ 之间的数据,实际上类似于图1的 RW 和 Standby 间的复制。这种架构下,要满足跨 AZ 的容灾,同样如果是 Plan Failover 可以保证两条日志流一直,但是 Unplaned Failover 两条流各自复制,切换后的一致性很难保证。
图3是三节点的集群增强版,使用 Redo + Xpaxos 保证三 AZ 的高可用,这种架构下的角色切换,都是 Unplanned Failover, 两条流的一致性无法保证。
为了解决上述问题,我们提出了 Logic Redo 的方案,目标是以开源 Binlog 日志格式为基础,让 Innodb Redo Log 拥有提供逻辑日志服务的能力。
相关工作
Oracle Logic Standby

Oracle 同时支持 Physical Standby 和 Logic Standby,前者类似物理复制,使用 Redo Log 直接 Apply 到 Page 级别,不走 SQL 层。Logic Standby 类似 MySQL 原本的 Binlog 复制,同步逻辑的日志。不同之处在于 Oracle 的物理复制和逻辑复制都是从主库拿到 Redo Log。对于逻辑复制而言,需要从 Redo Log 解析出 SQL,然后在 Logic Standby 上进行回放 。
- Reader 进程负责读取主库的 Redo Log records,可以从 archived redo log 或者 standby 上的 Redo log 读取。这个看起来像是 MySQL 的 Binlog Apply 线程读取 Relay Log 的部分。
- Prepare 进程负责把记录 Page Block 变更的 Redo Log 转成 Logic Change Record (LCRs)。多个进程并发处理一个 File.
- Builder 进程把 LCR 整理成 transaction。
- Analyzer/Coordinator/Applier 类似 MySQL 的 Binlog Apply Worker 线程。
Oracle 的方案是把反解和排序的工作交给了下游,在闭源的生态里是可行的。并且在设计之初,就考虑了物理日志和逻辑日志的转换。
这种方案对于 MySQL 生态是困难的,因为 Binlog 设计之初是为了解决 MySQL 多个存储引擎间的数据异构问题,在 Server 层提供一套统一的复制日志,所以没有考虑过日志间的转换问题。第二个难点在于开源的生态,我们不能修改 Binlog 的日志格式,要完全兼容。
InnoDB Redo 转 SQL
这个方案在论文:InnoDB Database Forensics : Reconstructing Data Manipulation Queries from Redo Logs 中做了讨论,虽然 Binlog 格式在上下游更通用,但是SQL 是可以满足生态需求的,这个方案最大的弊端就是反解的效率,Binlog 作为 MySQL 内部 XA 事务的协调者,一个事务提交回滚是由 Binlog 是否落盘决定的,一旦 Binlog 落盘,就可以立刻被下游拖走,而不用等引擎的提交,所以这部分的延迟是非常小的,如果从 Redo 解析 SQL 再同步到下游,延迟必然会大大增加。
AliSQL Binlog In Redo
在 MySQL 8.0 中,对 Redo 的子系统进行了优化,可以 Lock Free 的写日志,在打开 Binlog 之后,因为内部两阶段提交,Ordered Commit 中的两次持久化操作,性能会有明显的下降,可以参考 Dimitri 的博客MySQL Performance: 8.0 RW & Binlog impact。为了解决这个问题,在月报 Binlog In Redo 中,AliSQL 将部分 Binlog 写到文件系统缓存的同事,也写到了 Redo Log 中,这样可以减少一次 Fsync,对性能有较大提升。
这个方案和 POLARDB 需要解决的问题是不一样的,AliSQL 内部还是使用 Binlog 做主备间的复制,Redo Log 只有两个文件循环写,所以大事务是没法写到 Redo 里的。POLARDB 需要从 Redo 里获得全量的 Binlog 数据,除了提升性能,还要解决两条日志流切换后的一致性问题。
Aurora Binlog Optimize
同样是以物理复制为基础的云原生数据库,Aurora 的架构的和 POLARDB 是不太一样的,它的存储拥有 Apply Redo 的能力,存储节点更像是一个 Page Server, 因此在计算节点 Crash Recover 的时候,存储节点可以提前把 Redo Apply 掉,这样崩溃恢复的时间就短了很多。在这种架构下,如果打开了 Binlog, Crash Recover 扫描 Binlog 和回滚 XA 事务,就成为了瓶颈,为此 Aurora 进行了针对性的优化,详细参考(Release Note)。具体做法是把大事务的的 Binlog 拆成独立的文件,崩溃恢复的时候可以直接判断这个文件是否完整,避免扫描整个文件。
这个方案显然无法解决双日志流同步的问题,在存储端去做的话,必然会带来写放大问题。
Logic Redo
两种日志除了存储格式,组织方式不同,最大的区别在于 Redo 是细粒度的状态日志,记录了引擎中 Page 等数据变化的每个状态,而 Binlog 是提交日志,以事务为粒度。即使使用了物理复制技术,Redo 也并不会被用户访问,只在集群内流转,但是 Binlog 实际上是一种服务,会不断有用户去读取。
要把两条流合一,新的日志会同时兼具原本两种日志的特性,可以在内部流转,也可以被用户读取,能吐出 Page 状态的数据变化,也能吐出事务粒度的状态日志。
我们的解决方案是把 Binlog 转成一种 Redo Log Type,有序的写入 Redo Log 中,日志类似于:

在原本两阶段提交中出现的性能瓶颈在 Binlog In Redo 中已经分析清楚了,在串行阶段的两次 fsync 会对性能有较大的损失,其实引擎 Prepare 的持久化也是在 Redo 里,当作为协调者的 Binlog 也记录在 Redo 之后,一份日志流的顺序性,就可以去掉引擎阶段的 Prepare 状态持久化。在 POLARDB 里,由于存储分离有高延迟高吞吐的特性,可以获得 20% ~ 50% 的性能提升。
架构
写入部分
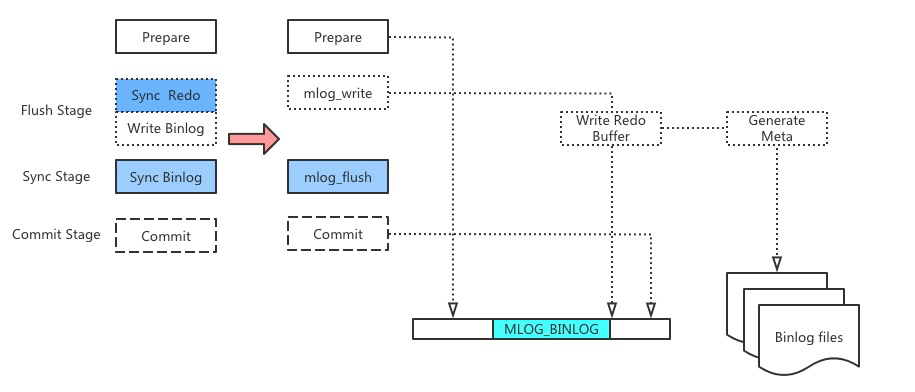
可以看到在 Ordered Commit 阶段去掉了一次 Sync Redo 的操作,为了保证兼容性,我们仍然保留了 Binlog 文件,但是文件中实际上已经不记录任何 Binlog 数据了,只是记录一些元信息,例如文件大小,Timestamp,Encryption,LSN 和 Offset 的映射等。这些在例如 show binary logs 等命令中需要用到,同时读取真正数据的时候,也需要从 Offset 找到对应的 LSN 位置。
读取部分
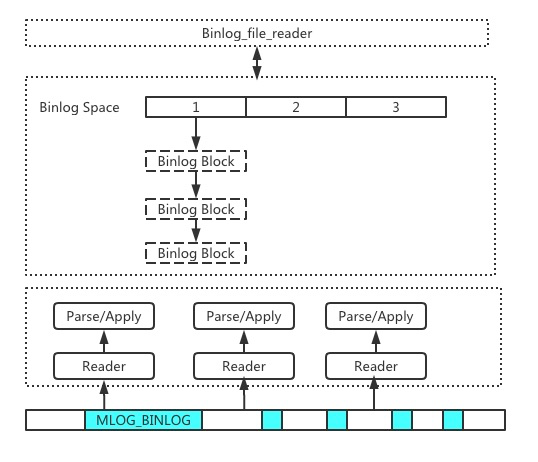
上面提到 Binlog 的一个比较大的优势是可以非常低的延迟把数据吐给下游,为此我们做了类似 Buffer Pool 的设计,Runtime Binlog Sys 可以实时的把需要读取的 Binlog 文件从 Redo 中读取并解析出来,放到内存里,根据 Dump 线程的读取特点,有一套预热和淘汰的机制,这样可以更加细粒度的控制数据,而不会过度依赖文件系统的调度。
性能
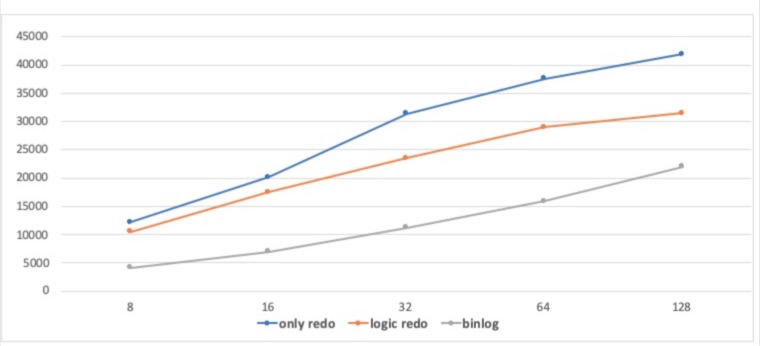
在 Sysbench write only 场景下,开发机模拟计存分离的环境简单对比了性能作为参考。
总结
日志合流之后最显著的就是存储空间问题,这个将来会配合日志上传,及时做归档,并且从实际测试来看,日志量变大后对复制延迟影响不大。Logic Redo 作为业内开创性的工作,解决了双日志同步的问题,并且在这种架构下,原本的 XA 崩溃恢复,Binlog 管理,性能优化等等问题都有了全新的视角和解决方式。首先将在三节点集群增强版中使用,敬请期待。