数据库系统 · 事物并发控制 · Two-phase Lock Protocol
Author: 原峰
背景
事务并发控制是关系型数据系统中的重要模块,首先通过几个问题对事务并发控制的背景进行简单介绍。
什么是事务?
事务是数据库中状态转移的最基本单位,包含一个或多个操作的执行序列。
事务有什么特性?
事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability), 也就是我们熟知的ACID。
原子性是指事务中的一系列操作,要不全部执行,要不全部不执行,不能部分执行,这就是事务定义中”最基本单位”的意义,事务必须是原子的,是不可分割的。
一致性是指事务的执行驱动数据库从一个正确的状态转移到另外一个正确的状态。正确性通常是指数据库的状态满足一定的约束条件,比如外键的约束、转账事务中总金额的约束等。正确性需要用户层面事务逻辑正确以及数据库事务执行层面正确两个维度来进行保证。
隔离性是指多个事务互相不影响,达到的效果就是每个事务都觉得系统中只有自己在执行。
持久性是指事务一旦执行成功,那么它对数据库状态的改变不能丢失,即使数据库发生了宕机重启也不能丢失。
事务为什么需要并发执行?
如果事务都是串行执行,是不是就没有这么多问题了。确实是这样,数据库中所有事务都串行执行,整个数据库状态机以及状态转移的模型就非常简单,早期在硬件能力受限以及并行处理能力尚未成熟时,事务串行执行确实可以满足要求了。但是随着硬件能力的提升、多核处理器、numa架构的cpu的兴起,以及业务对数据处理速度和吞吐要求的提升,事务串行执行一方面没办法发挥硬件的能力,另外一方面也无法满足真实业务场景的需求。因此事务并发执行是必然的结果。
事务并发执行还需要保证ACID吗?
需要。事务的并发执行主要目的是满足业务对数据库系统的性能要求,而ACID是业务对数据库系统的基本要求。其实原子性和持久性的保证,在事务串行执行和并发执行时没有太大的区别。事务并发控制最主要的问题是满足一致性和隔离性的要求。
事务并发控制如何保证正确性?
事务并发调度需要保证调度事务并发执行的结果与某一种事务串行执行的结果相同,也就是事务并发调度如果是可串行化的,那么认为该调度是正确的。”冲突可串行化”是验证事务并发调度是否是可串行化的常用手段,通过交换事务间不冲突操作的执行顺序并保证冲突操作执行顺序的偏序关系,如果最终事务操作执行序列与某一种事务串行执行的操作执行序列相同,那么认为该事务并发调度是”冲突可串行化的”。
两个操作冲突需要满足以下两个条件: 1)操作的是相同的数据; 2)两个操作来自不同的事务,并且至少一个是write操作。 因此冲突操作可以分为读写冲突、写读冲突、写写冲突。
事务并发调度保证了事务的ACID,那事务不同的隔离级别是怎么回事?
我们知道事务有很多不同的隔离级别,read uncommited、read commited、repeat read、snapshot isolation、serializable等待,事务隔离级别的定义也是经过了很长时间演进。截止目前,我们所说的隔离级别其实是指serializable。实际应用场景中发现满足serializable的并发调度,在事务的执行效率和吞吐仍然无法满足要求。因此,就有了通过降低隔离性的保证来换取数据库事务执行的并发度的提高,熟悉的”trade off”,隔离级别就是用来定义不同程度的隔离性保证。理论上,隔离性越低,数据库事务的并发度越高。
serializable以下的隔离级别,是以牺牲一定的一致性和隔离性来换取数据库执行事务并发度的提高。明确的隔离级别的定义就是告诉用户,数据库在对应的隔离级别下能作出那些保证,”满足用户预期的不正确何尝不是一种正确呢?”
什么是并发控制协议?
并发控制协议是数据库用来调度多个事务操作并发执行并保证执行结果符合预期的方式。通常,可以认为并发控制协议就是用来保证事务并发执行时的schedule是冲突可串行化的。并发协议可以分为”悲观并发控制协议”和”乐观并发控制协议”两大类。
我们接下来讨论的并发控制协议都是为了保证调度是冲突可串行化的,也就是保证事务隔离级别是serializable.
基于两阶段锁的并发控制协议
可以通过”交换不冲突的操作”或者”优先图”的方式来验证某个事务调度是否是”冲突可串行化的”。通过加锁的方式可以控制冲突操作的并发问题,并且如果事务在访问或修改某个数据项的过程中都通过相应的锁来保护,直到事务结束的时候才释放锁,那么其他事务与该事务所有的冲突的操作必然是可串行化的, 这就是两阶段锁的基本逻辑。
锁管理器负责锁的分配,如果请求的锁与其他的锁是相容的,那么成功分配,否则加锁请求需要等待或者失败。锁的类型可以分为s-lock(共享锁)、 x-lock(排他锁)。一般来说,读取操作需要持有s-lock、写入操作需要持有x-lock。只有两个加s-lock的请求是相容的,其他任意类型的两个加锁请求都是不相容的。
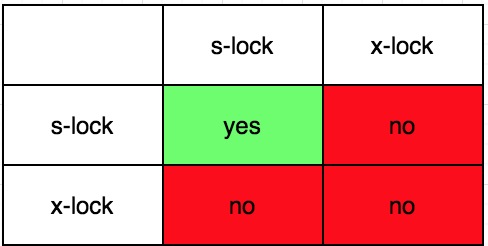
两阶段锁协议内容如下:
阶段一(Growing):事务向锁管理器申请所需要的锁,锁管理器分配或拒绝对应的锁。
阶段二(Shrinking):事务释放在Growing阶段申请的锁,并不能再申请新的锁。

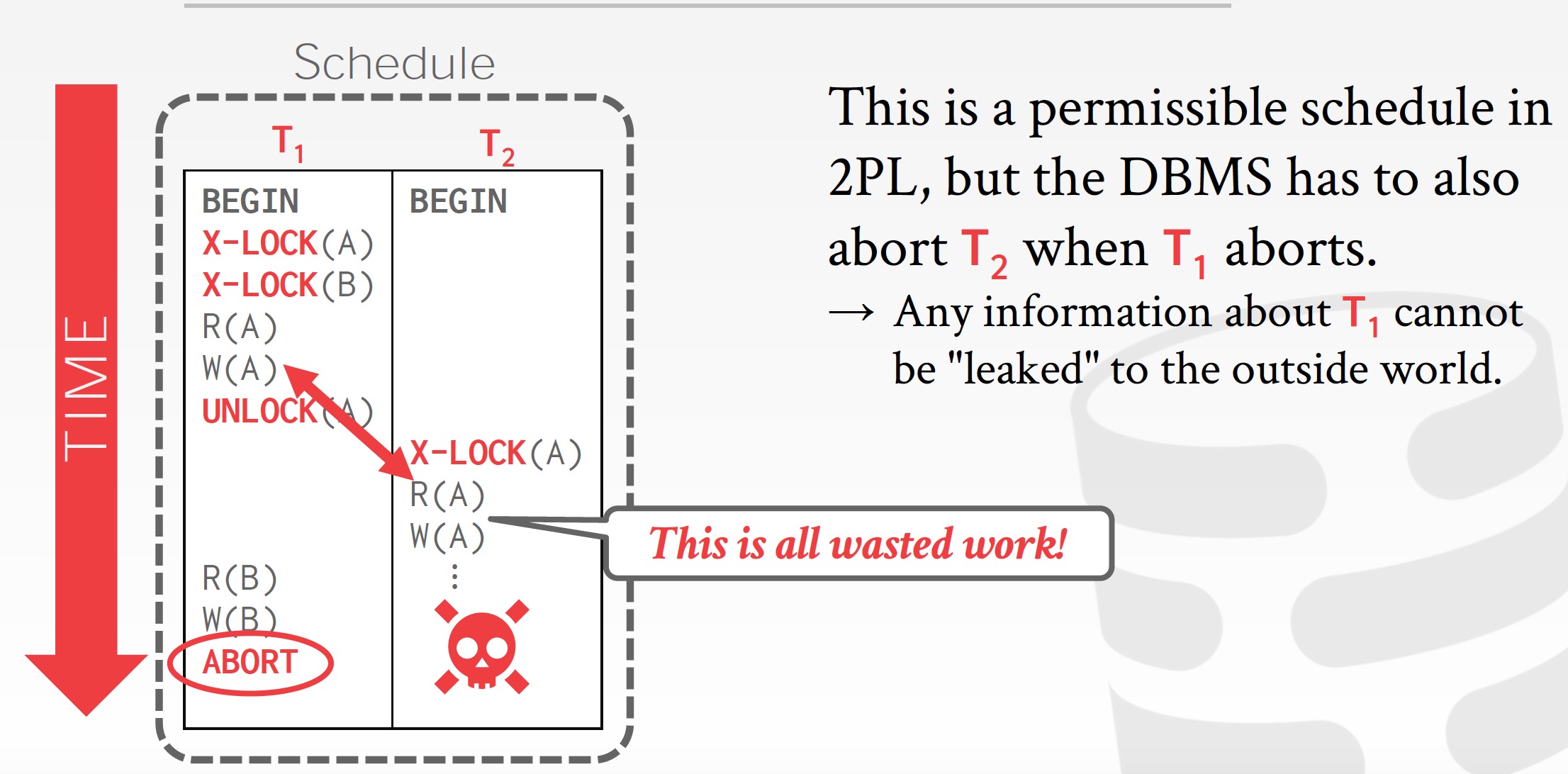
级联回滚
级联回滚是指一个事务的回滚引起了一系列相关事务的回滚。在两阶段协议下,级联回滚是可能发生的。如下图所示,当T1回滚后,T2也必须回滚,因为T2中读到T1中未提交的对A的未提交的修改,如果T2最终提交那么相当于读到了一个从未存在过的值,可能会违反一致性,并且T1相当于部分提交, 违反了原子性。
严格两阶段协议(Strict two-phase locking protocol)可以避免级联回滚,它在两阶段协议的基础上要求事务持有的所有排他锁必须在事务提交后方可释放。这个要求保证了未提交事务所写的任何数据在该事务提交之前均以排他方式加锁,防止了其他事务读到这些数据。
强两阶段协议(Strong Strict two-phase locking protocol)是在严格两阶段协议的基础上,进一步要求事务所有的共享锁也必须在事务提交后方可释放。这样其实Growing阶段横跨了整个事务执行的过程,其实相当于只有一个阶段了,因此实现起来比较简单,被广泛使用。

多粒度锁
截止目前,我们所讲的锁都指的是tuple级别的,也就是我们通常所说的行锁。我们知道数据库中数据管理的粒度从上到下有database、table、tuple、column。一般来说数据库操作的最小单位是行,所以最小粒度的锁也就是行锁。那么行锁释放可以满足所有场景的加锁需求呢?
事务T1要访问整个数据库,数据库中有几十亿条数据项,如果给其中的每一个数据项都加锁,那么加锁的代价是不可接受的。如果T1能够只发出一个封锁整个数据库的加锁请求,那么加锁的代价就很低了。另外一方面如果事务T1只访问少量的数据项,就不应该给整个数据库加锁,因为会限制整体的并发性。
因此为了满足不同场景的加锁需求,需要一种允许系统定义多级粒度锁的机制。整体多级粒度锁的关系是如下图的树状的结构,树中的每个节点都可以单独加锁。当事务对一个节点加锁(共享锁或排他锁)时,该事务隐式的给这个节点的所有后代节点加上了同类型的锁。层次越高的锁,整体加锁和释放锁的代价越低,但是会限制整体的并发度;层次越低的锁,整体加锁和释放锁的代价越高,但是有利于并发。
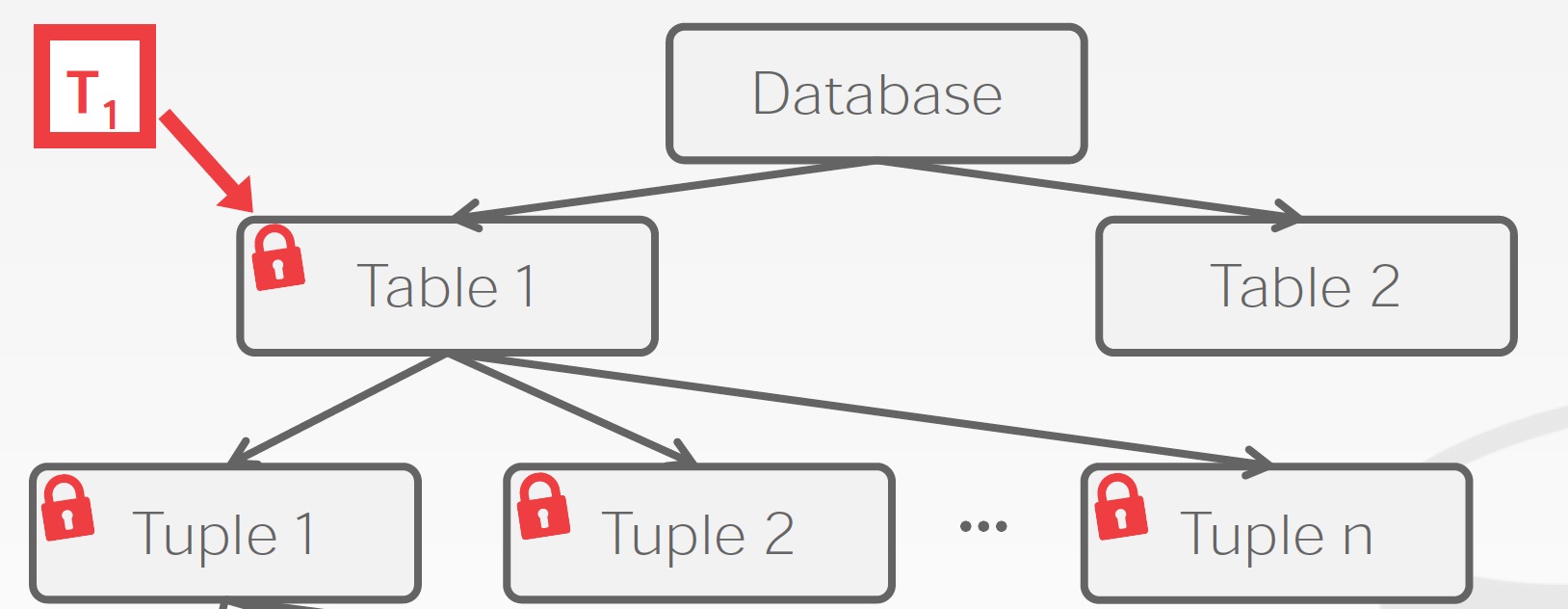
意向锁
假设事务T1希望对整个数据库加排他锁,也就是对root节点加排他锁,那么锁管理器需要确认这个加锁请求能否成功。为此,锁管理器需要遍历整个树状层次结构的所有节点,如果所有节点都没持有锁,那么可以对root节点加排他锁,否则需要延迟或拒绝该加锁请求。遍历整个层级结构的所有节点去判断能够加锁成功,这种方式不符合了多粒度锁的初衷,因为检查所有节点是否加锁跟直接对所有节点加锁的代价可以认为是相同的(最起码是一个数量级的)。
为了解决上述问题,引入了一种新的锁类型-意向锁。如果一个节点加了意向锁,则意味着要在其后代节点进行显式加锁。在一个节点显式加锁之前,该节点的全部祖先节点均加上了意向锁。因此,判定能够成功给一个节点加锁时不必搜索整棵树。给某个节点加锁的事务必须遍历从root节点到该节点的路径,并给路径上的各节点加上意向锁。
意向锁相当于是一个提前的加锁声明。这样其他事务就可以根据节点上的意向锁类型来判断它的加锁请求能否成功。为了达到这个目的要求,对某个节点显式的加共享锁或排他锁之前,必须对root节点到该节点的路径上的其他节点加相应的意向锁。通过意向锁,事务可以在一个高的层次上去加共享锁或排他锁,而不需要去检查所有的后代节点的加锁情况。
意向锁分为以下三类:
共享型意向锁(IS): 将在后代节点上显示加共享锁。
排他性意向锁(IX): 将在后代节点上显示加排他锁或共享锁。
共享排他型意向锁(SIX):当前节点被显示的加共享锁,并将在后代节点上加排他锁。
目前我们一共提到X、S、IS、IX、SIX这五种类型的锁,它们之前的相容关系如下:
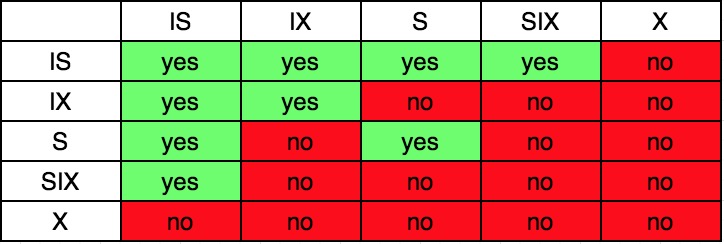
意向锁之间基本是相容的。
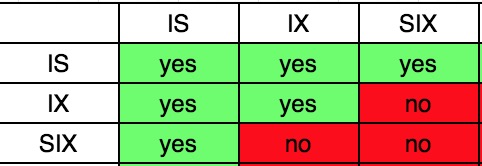
意向锁与S锁和X锁基本是不相容的。

为什么IS与IX是相容的?
因为IX也可能将在更低层次加共享锁,因此给当前节点加IS和IX是相容的。如果事务T1在当前节点持有了IS锁,事务T2在当前节点持有了IX锁,那么接下来如果T1要显示的加S锁,而T2要显示的加X锁,那么这两个事务只有一个事务会加锁成功。这样是符合加锁的逻辑的。如IS和IX不相容,那么如果T1和T2即使在更低层次都是显示的加S锁,T1和T2也不能并发执行。
为什么IX和S是不相容的?
事务T1持有节点的S锁意味着其所有后代节点都持有了S锁(虽然没有真正的执行加锁),如果T2同时也持有了该节点的IX锁并在更后代节点中加了X锁,那么就违反了S锁和X锁不相容的规则。同理,IX和SIX也是不相容的,因为SIX也显示的给它的后代节点加了共享锁。
为什么需要SIX锁?
事务T1做全表扫描,并对一部分数据做更新。事务T2扫描表中的一部分数据,并且与T1更新的数据没有交集。因为事务T1要做全表扫描,那么它应该对root节点加S锁以防止其他事务去更新,而由于它还要对部分低层次节点锁修改,所以接下来还需要加排他锁,以防止其他事务读到他未提交的修改。这正是SIX锁的意义,T1和T2可以并发。这也就是为啥SIX和IS是相容的。
SIX其实是相当于事务内做锁升级。
为什么S和SIX是不相容的?
如果给当前节点加S锁,那么意味着其所有后代节点都隐式的加上了S锁。而SIX可能在后代节点中显示的加排他锁,这样就违反了S锁和X锁不相容的规则。
为什么没有XIX或XIS锁?
SIX其实是一个锁升级的过程,X锁到X锁以及X锁到S锁都没有锁的升级,父节点已经是一个排他锁了,其他事务无法在给其的后代节点加任何锁,所以也必要进行锁降级,因此XIX和XIS锁就没有存在的必要。
举个实际的例子来说明意向锁带来的好处。一个读写事务对表加了IX锁,这时对表发起DDL操作,需要请求表的X锁,那么看到表持有IX就直接等待了,而不用逐个检查表内的行是否持有行锁,有效减少了检查开销。这时另外一个读写事务过来,由于表加的是IX而非X,并不会阻止其他的读写请求(先在表上加IX,再去记录上加S/X),两个读写事务如果涉及的行没有交集,那么可以正常并发执行,增大了系统的并发度。
多粒度加锁协议
多粒度锁协议和两阶段协议一样,用来保证在多粒度锁的机制下,schedule是可串行化的。
多粒度加锁协议的如下:
1、必须遵守锁间的相容性规则;
2、根节点必须首先加锁,可以加任意类型的锁;
3、仅当事务对当前节点的父节点持有IX或IS锁时,才可以对当前节点加S或IS锁;
4、仅当事务对当前节点的父节点持有IX或SIX锁时,才可以当前节点加X、SIX或IX锁;
5、仅当事务未曾对任何节点释放锁时,才可对节点加锁(也是两阶段);
6、仅当事务不持有当前节点的子节点的锁时,才可释放当前节点的锁。
多粒度加锁协议要求加锁按照从上到下的顺序,释放锁按照从下到上的顺序。
死锁
如果事务集中,若干个事务间加锁请求相互循环等待,那么就发生了死锁。
比如事务T1持有数据项A的排他锁,并请求数据项B的排他锁,而事务T2持有数据项B的排他锁,并请求数据项A的排他锁,那么事务T1和T2相互等待,都无法继续推进,也就是发生了死锁。
处理死锁问题主要有两种方法:死锁预防、死锁检测与死锁恢复。
死锁预防是一种”事前”手段,就是通过机制来保证系统不会产生死锁问题,这种方式往往会造成一些不必要的回滚,尤其在锁冲突并不严重的场景下更容易浪费系统资源。死锁检测与死锁恢复机制,是一种”事后”手段,通过死锁检测来及时发现系统中发生的死锁,并通过死锁恢复手段来保证一部分事务可以继续progress。
死锁预防
死锁预防是通过协议来保证系统永远不进入死锁的状态。
死锁预防有两种方法:1)通过对加锁请求进行排序或要求获得所有的锁来才开始执行保证不会发生循环等待。2)每当等待可能导致死锁时,进行事务回滚而不是等待加锁。
方法1)的最简单的机制要求每个事务在开始执行前持有所有涉及数据项的锁,要不全部封锁,要不全部不封锁。这个协议有两个主要的缺点:事务开始前通常很难预知那些数据项需要封锁;数据项使用率低导致限制事务并发度(许多数据项可能被提前封锁,但是长时间不用)。对应到上面的死锁例子中,要求事务T1执行前持有数据项A的排他锁和数据项B的排他锁,如果不能全部持有,那么就不持有数据项A和数据项B的任何锁。
方法1)的另外一种机制是对所有数据项设置一个加锁顺序的限制,要求事务只能按照规定的次序对数据项进行加锁。对应到上面死锁的例子中,要求所有事务对数据项加锁的顺序均为先A后B,这样就不会出现循环等待的情况了。
方法2)是使用抢占和事务回滚。在抢占机制中,当事务T2所申请的锁已经被T1锁持有时,授予T1的锁可能通过回滚事务T1并将锁授予事务T2。为控制抢占,给每个事务分配一个唯一的时间戳,系统仅根据时间戳的先后顺序来决定事务应该等待还是回滚。若一个事务回滚,该事务重启时仍保持原有的时间戳,这主要是为了防止回滚的事务被饿死。
利用时间戳进行死锁预防的机制包括以下两种: 1)wait-die机制是一种非抢占技术。当事务T1申请的数据项的锁当前被T2持有时,仅当T1的时间戳小于T2的时间戳(T1比T2老)时,允许T1等待,否则T1回滚。 2)wound-wait机制是一种抢占技术。当事务T1申请的数据项的锁当前被T2持有时,仅当T1的时间戳大于T2的时间戳(T1比T2年轻)时,允许T1等待,否则T2回滚。
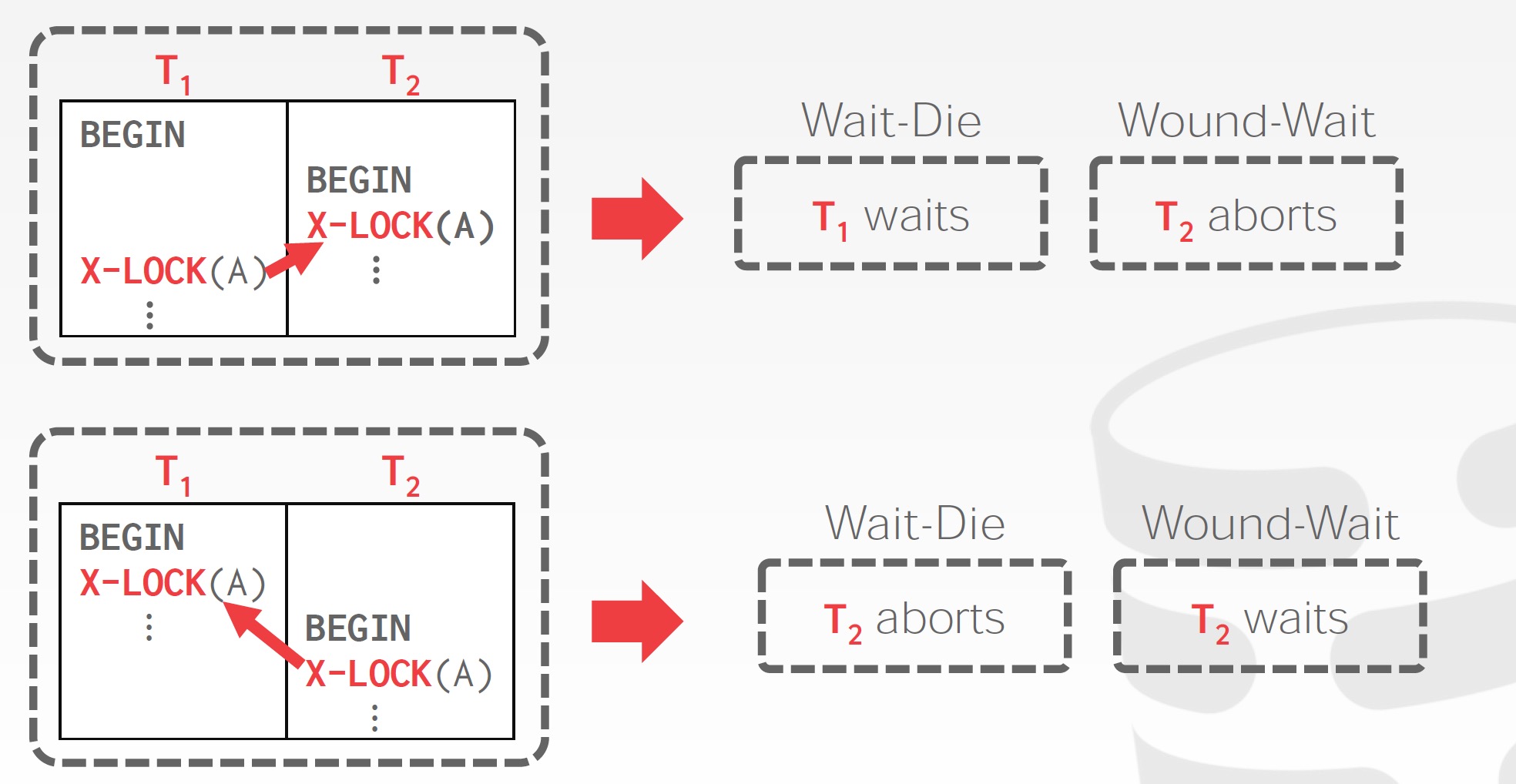
系统回滚事务的时候,保证无饿死发生非常重要,即必须保证不存在某个事务重复回滚而总是不能progress。
wait-die和wound-wait两种机制都可以避免饿死。任何时候均存在一个时间戳最小的事务,并且这个事务都不允许回滚。由于时间戳总是增长,并且回滚的事务不赋予新时间戳,被回滚的事务最终会变成最小时间戳事务,从而最终会progress。
可以发现在wait-die、wound-wait机制中,事务的时间戳相当于事务的优先级,并且时间戳越小的事务优先级越高。wait-die、wound-wait机制之所以可以保证不出现死锁是因为在各自的机制中,事务间的等待都是单向的。wait-die中只有老事务会等待新事务,wound-wait中只有新事务会等待老事务。
wound-wait机制相比wait-die引起的回滚可能更少。wait-die机制中,如果事务T1由于申请数据项的锁被事务T2持有,而引起T1回滚,则当事务T1重启时,它可能发出相同的申请序列,如果该数据项的锁仍然被T2持有,那么T1会再度死亡,因此在T1最终加锁成功前可能会多次回滚。同样的场景,在wound-wait机制中,T1会一直等待。
死锁检测与死锁恢复
死锁检测可以通过等待图(wait-for graph)来实现。等待图G = (V, E),其中V是顶点集表示事务集合,E是边集表示等待关系集合。如果T1->T2属于E, 表示事务T1在等待T2。如果等待图中包含环,那么说明系统中存在死锁。系统需要维护等待图,等待图是一种有向图,有向图的环检测算法可以用于检查系统中是否存在死锁。
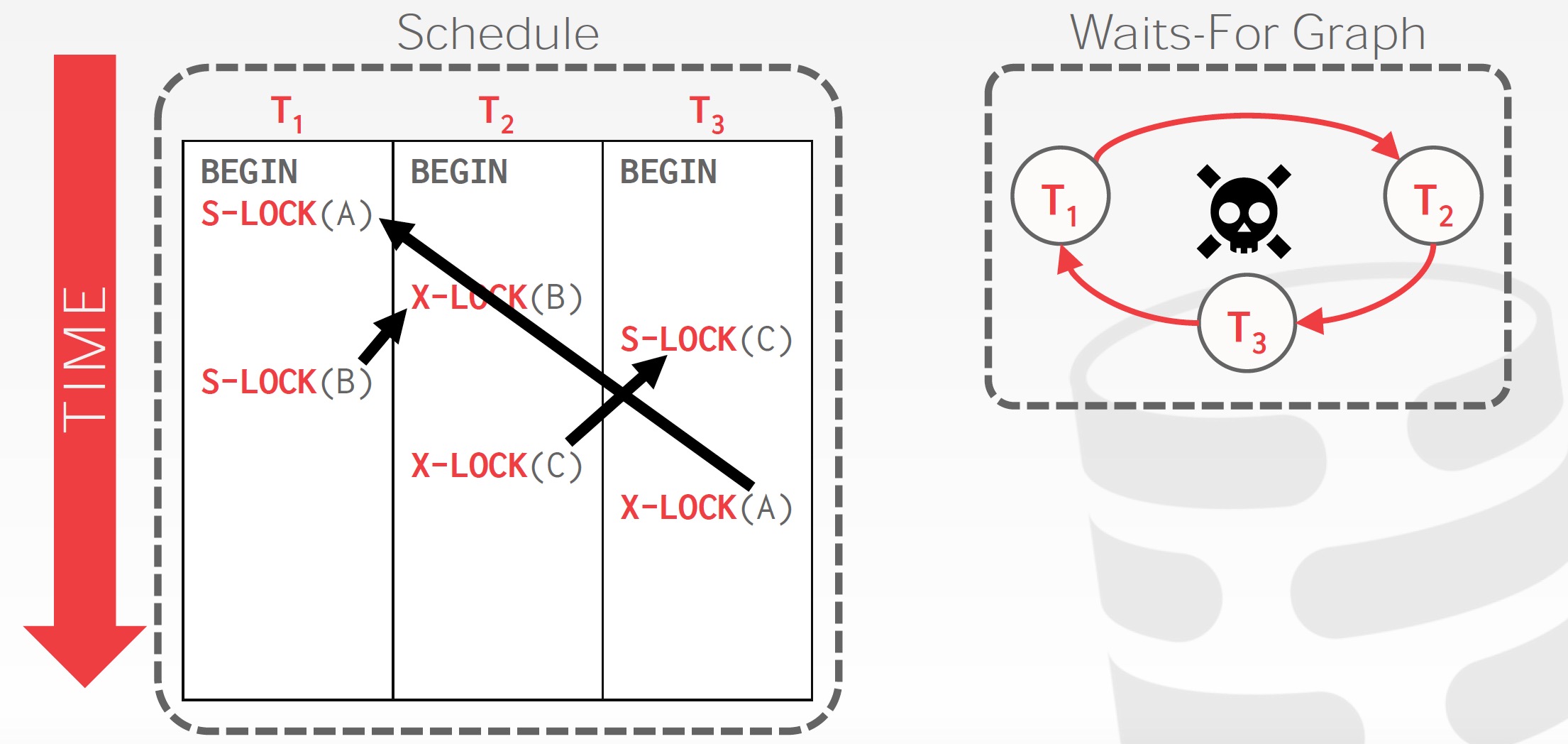
当检测算法判定存在死锁时,系统必须从死锁中恢复。死锁恢复的通常做法是回滚一个或多个事务。死锁恢复包括以下几步:
1、选择牺牲者。给定处于死锁状态的事务集,为解除死锁,必须决定回滚那个(或那些)事务。应使事务回滚带来的代价最小,很多因素决定事务回滚代价,其中包括:
1)事务已经计算了多久,在完成其指定任务之前该事务还将计算多长时间。
2)该事务已使用了多少数据项。
3)为完成事务还需使用多少数据项。
4)回滚时将牵涉多少事务。
2、回滚牺牲者。最简单的方式是将牺牲者完全回滚。另外一种方式是将牺牲者部分回滚,回滚到可以解除死锁的位置,当然这要求系统在事务执行过程中记录运行事务的额外状态信息。
死锁检测和死锁恢复机制也需要避免饿死。如果某个事务总被选为牺牲者,那么该事务就永远无法完成,可以通过限制事务被选为牺牲者的次数来避免饿死。
基于超时的机制
另外一种处理死锁的方式是基于锁超时。这种方法中,申请锁的事务至多等待给定的时间。若在此时间内锁未被授予该事务,则称该事务超时,此时该事务本身回滚并重启。如果确实存在死锁,卷入死锁的一个或多个事务将超时回滚,允许其他事务继续。
一般来说很难确定一个事务在超时前应该等待多长时间。如果已发生死锁,等待时间太长导致不必要的延迟。如果等待时间太短,即便没有发生死锁,也可能引起事务回滚,造成资源浪费。
这种方式介于死锁预防与死锁检测恢复之间。
参考
1.数据库系统概念。
2.CMU 15-445/645
3.https://mp.weixin.qq.com/s/CrmpDVdzCXzhKispv54bzg
4.https://mp.weixin.qq.com/s/Gya-PGXBUjx-Vjr5DbzZJA