PolarDB · 引擎特性· 闪回查询让历史随时可见
Author: WangKang
通过数据库我们我们可以方便的查询当前的数据。但当我们需要查询之前几秒,几个小时甚至几天的数据时,就变的非常复杂。比如需要从某个备份开始经过漫长的redo回放,得到一个对应历史时间的新实例,然后在这个新实例上进行查询。如果需要查询多个不同时间点的数据,那就更复杂了。有没有办法能够让数据库像当前查询一样实时的查询任意时间点的数据呢?
PolarDB Flashback Query使用
PolarDB最近发布了闪回查询(Flashback Query)功能,提供高效地,在当前实例,对历史某个时间点数据查询的能力。通过innodb_backquery_enable参数打开Flashback Query功能,并通过innodb_backquery_window设置需要回查的时间范围。之后,对数据库的查询操作都可以通过AS OF关键字来指定需要看到的历史时间点,下面是对一个products表的查询结果,为了方便感知,这个表中有createtime字段来记录当前行的最后修改时间:
SELECT * FROM products;
+---------+-----------+---------+---------------------+
| prod_id | prod_name | cust_id | createtime |
+---------+-----------+---------+---------------------+
| 103 | Beef | 2 | 2021-08-31 13:51:26 |
| 104 | Bread | 3 | 2021-08-31 13:51:27 |
| 105 | Cheese | 4 | 2021-08-31 13:51:29 |
| 110 | Book | 1 | 2021-08-31 14:18:21 |
| 119 | Apple | 1 | 2021-08-31 14:18:22 |
+---------+-----------+---------+---------------------+
5 rows in set (0.00 sec)
对比通过AS OF关键字指定时间点的Flashback Query查询结果:
SELECT * FROM products AS of TIMESTAMP '2021-08-31 14:00:00';
+---------+-----------+---------+---------------------+
| prod_id | prod_name | cust_id | createtime |
+---------+-----------+---------+---------------------+
| 101 | Book | 1 | 2021-08-31 13:51:22 |
| 102 | Apple | 1 | 2021-08-31 13:51:24 |
| 103 | Beef | 2 | 2021-08-31 13:51:26 |
| 104 | Bread | 3 | 2021-08-31 13:51:27 |
| 105 | Cheese | 4 | 2021-08-31 13:51:29 |
+---------+-----------+---------+---------------------+
5 rows in set (0.00 sec)
更多的使用说明可以参考官方的使用指南。本文将详细介绍PolarDB Flashback Query的实现思路,优势与限制。
多版本并发控制(MVCC)
为了实现历史随时可查的目标,我们先看看InnoDB的多版本实现机制,之前的文章庖丁解InnoDB之Undo LOG中也详细的介绍过Undo Log的实现。为了避免只读事务与写事务之间的冲突,避免写操作等待读操作,几乎所有的主流数据库都采用了多版本并发控制(MVCC)的方式,也就是为每条记录保存多份历史数据供读事务访问,新的写入只需要添加新的版本即可,无需等待。InnoDB在这里复用了Undo Log中已经记录的历史版本数据来满足MVCC的需求。如下图所示:
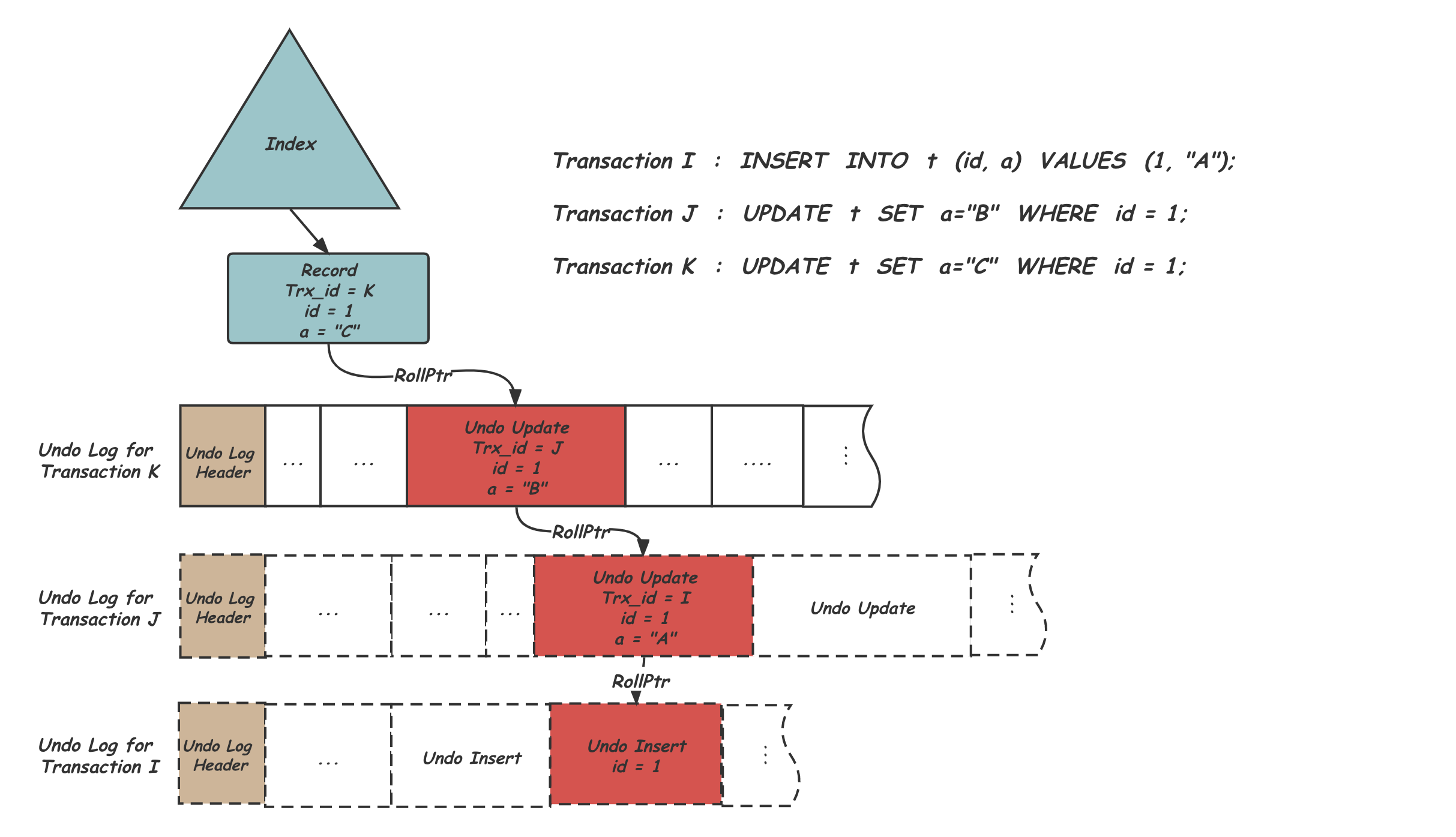
事务在做数据修改的时候,会先将当前的历史版本以一个Undo Record记录到Undo中,多个Undo Record首尾相连组成以段逻辑上连续的Undo Log,并在开头同Undo Log Header记录一些必要的维护信息。上图所示是I,J,K三个写事务生成的Undo Log,其中他们都对一条Record产生过操作,事务I首先插入了id为1的这条Record,之后事务J和事务K先后将这条记录的filed a修改成了B和C。针对同一条记录的修改被按照先后循序通过Rollptr从Index上触发串成一个历史版本链,并且每个版本上都记录了产生这个版本的事务号trx_id和再之前一个版本的Rollptr。
维护多个版本的目的是为了避免写事务和读事务的互相等待,每个读事务可以在不对Record加Lock的情况下, 找到对应的应该看到的历史版本。所谓应该看到的版本,就是假设在该只读事务开始的时候对整个DB打一个快照,之后该事务的所有读请求都从这个快照上获取。当然实现上不能真正去为每个事务打一个快照,这个时间空间都太高了。InnoDB的做法,是在读事务第一次读取的时候获取一份ReadView,并一直持有,其中记录所有当前活跃的写事务ID,由于写事务的ID是自增分配的,通过这个ReadView我们可以知道在这一瞬间,哪些事务已经提交哪些还在运行,根据Read Committed的要求,未提交的事务的修改就是不应该被看见的,对应地,已经提交的事务的修改应该被看到。
查询历史版本
作为存储历史版本的Undo Record,其中记录的trx_id就是做这个可见性判断的,对应的主索引的Record上也有这个值。当一个读事务拿着自己的ReadView访问某个表索引上的记录时,会通过比较Record上的trx_id确定是否是可见的版本,如果不可见就沿着Record或Undo Record中记录的rollptr一路找更老的历史版本。如下图所示:
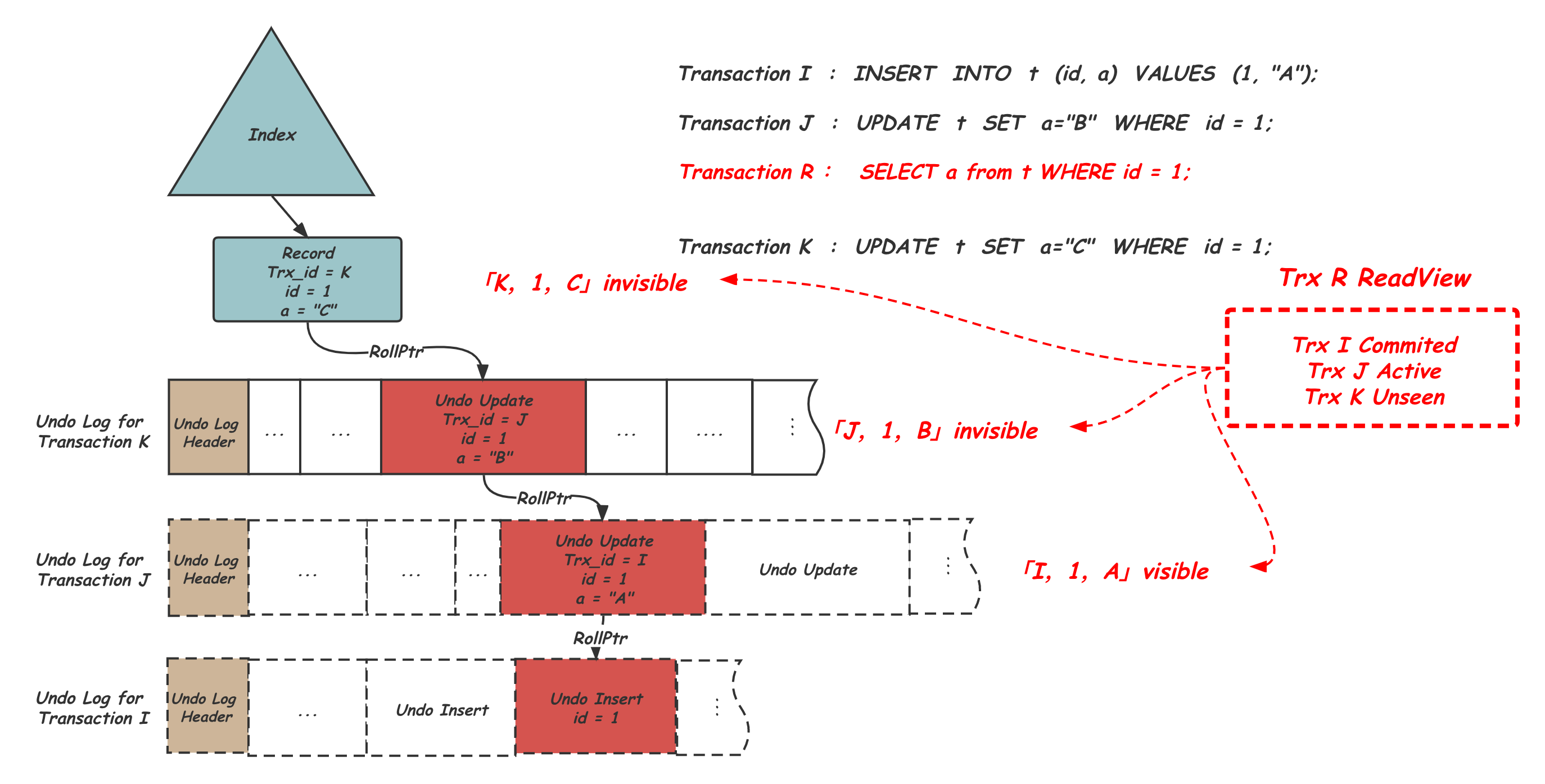
事务R开始需要查询表t上的id为1的记录,R开始时事务I已经提交,事务J还在运行,事务K还没开始,这些信息都被记录在了事务R的ReadView中。事务R从索引中找到对应的这条Record[1, C],对应的trx_id是K,不可见。沿着Rollptr找到Undo中的前一版本[1, B],对应的trx_id是J,不可见。继续沿着Rollptr找到[1, A],trx_id是I可见,返回结果。
清理历史版本
当然,这些积累的历史版本还是需要被清理掉的。因此就需要有办法判断哪些Undo Log不会再被看到。InnoDB中每个写事务结束时都会拿一个递增的编号trx_no作为事务的提交序号,而每个读事务会在自己的ReadView中记录自己开始的时候看到的最大的trx_no为m_low_limit_no。那么,如果一个事务的trx_no小于当前所有活跃的读事务Readview中的这个m_low_limit_no,说明这个事务在所有的读开始之前已经提交了,其修改的新版本是可见的, 因此不再需要通过undo构建之前的版本,这个事务的Undo Log也就可以被清理了。如下图所所以,由于ReadView List中最老的ReadView在获取时,Transaction J就已经Commit,因此所有的读事务都一定能被Index中的版本或者第一个Undo历史版本满足,不需要更老的Undo,因此整个Transaction J的Undo Log都可以清理了。如下图所示:
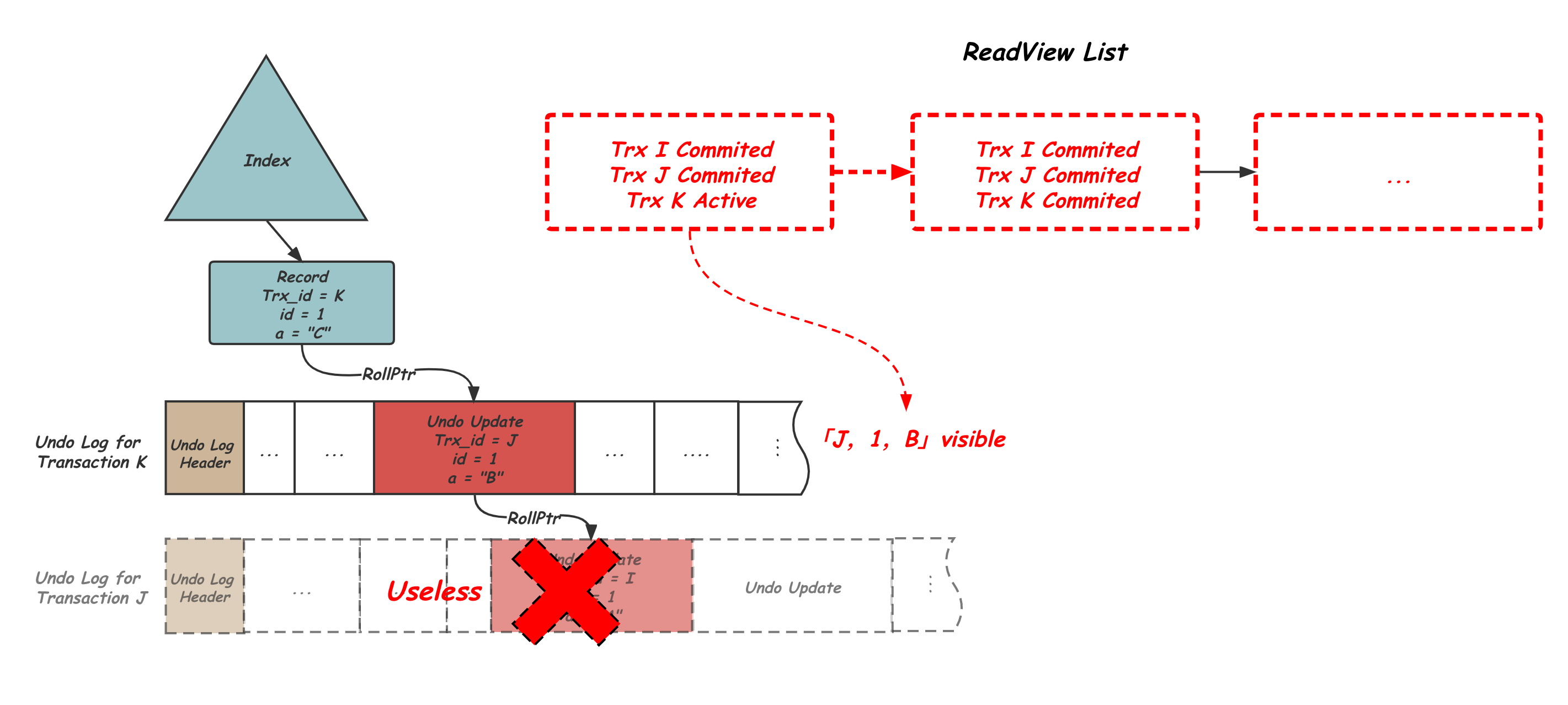
可以看出,全局ReadView List中最老的一个Read View开始的时候事务J已经提交了,那么事务J产生的数据修改对之后的所有事务都是可见的了,因此事务J产生改的Undo Log就可以被安全的清理掉了。Innodb中会按照这些可以被清理的Undo Log的事务提交顺序来一次进行清理。
PolarDB Flashback Query原理
有了这套完整的多版本维护和使用机制,自然地,我们希望能利用它来实现对历史数据实时访问的需求。如果历史数据的查询请求可以持有当时那个时刻对应的ReadView,并且延缓对应的可见版本清理,那么就能很自然的获得需要的数据版本, 因此Flashback Query的实现,首先是保存历史的ReadView及对应的数据版本。如下图所示:
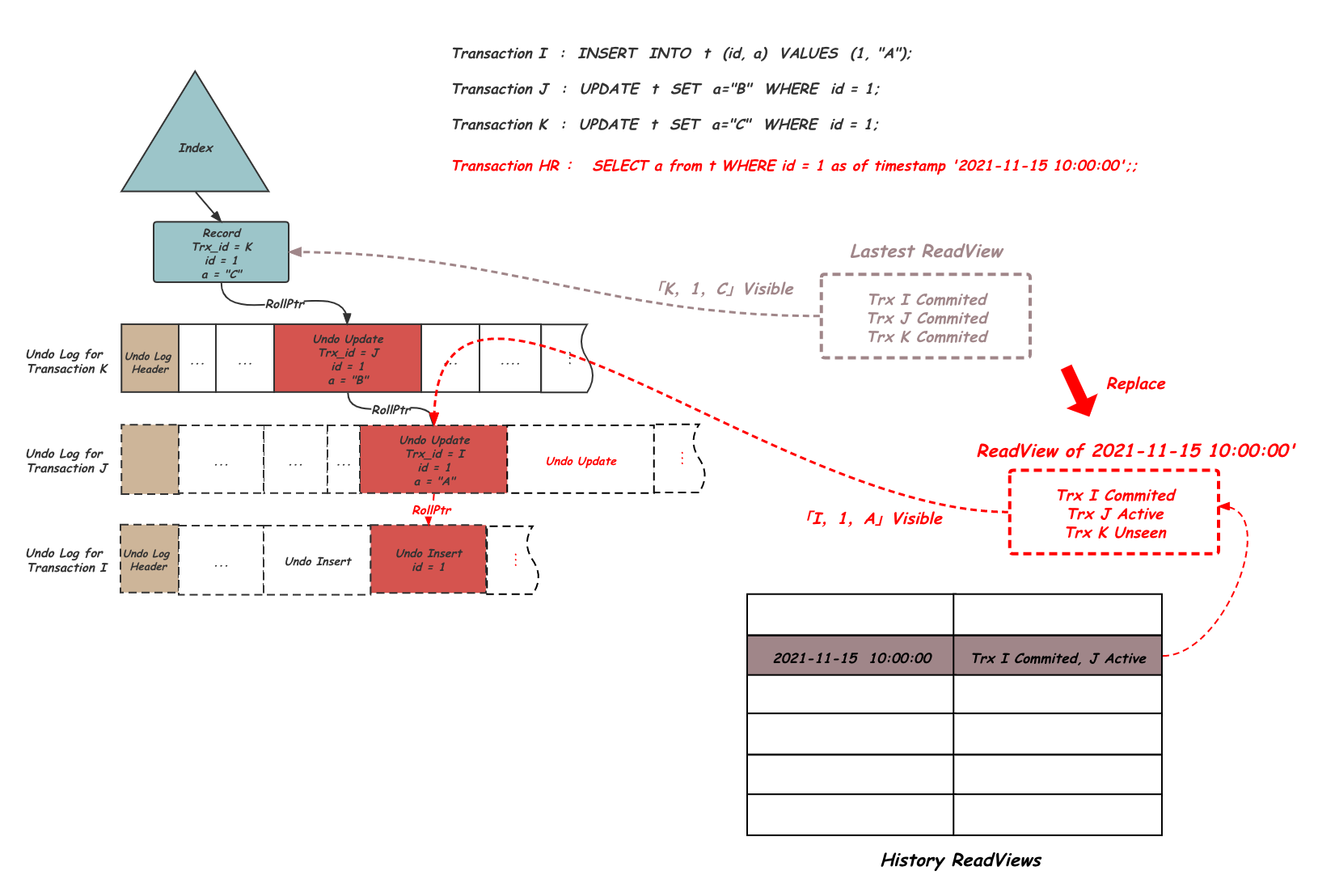
设置innodb_backquery_enable可以打开Flashback Query功能,PolarDB会周期的记录最新的ReadView到History ReadViews表中。当读事务HR开始查询之前,事务I,J,K都已经提交,HR如果获得最新的Lastest ReadView将直接可见最新的数据版本。但注意事务HR的查询语句中使用as of的关键字指定了需要的时间,因此这里会从History ReadViews中查询最接近的ReadView,来当做HR事务的ReadView使用,通过这个历史的ReadView,事务HR会经过上面讲过的MVCC流程找到对应的一个历史版本。
延后版本清理
为了使得Flashback Query查找到的数据版本可用,需要改造MVCC的清理工作,将之前受ReadView List中最老的Readview限制的清理工作推后。新的限制需要用整个History ReadViews中最老的哪一行记录。用户可以参数innodb_backquery_window指定Hisotry ReadViews中的ReadView保留的时间,其决定了History ReadViews中保留的历史ReadView的个数,从而间接地限制了Undo的版本清理。
二级索引带来的麻烦
由于为支持Flashback Query积累了更多的Undo,而PolarDB中每个Undo Record可能存在在不同的Page上,每个Page的访问都可能会触发IO,因此当需要沿着版本链去找很老的版本时,就会变得很慢。通常情况下正常的,非Flashback Query的查询都只需要访问最新的版本,不受历史链变长的影响。但有两个情况例外,一个是从二级索引上删除entry;另一个是在二级索引上判断隐式锁。而这两个都是由于innodb的一个设计权衡:二级索引上的记录不记录trx_id。这就导致二级索引上的记录是没有直接判断可见性的,因此当需要从二级索引上删除某个entry时,没有办法判断这个entry有没有被还存在的记录版本引用,因此就需要回查到主索引并遍历起整个版本链。当压力大时,这里会带来显著的性能瓶颈。
双Purge机制
为了解决这个问题,使得Flashback Query的不会对现有的DB访问带来影响,PolarDB做了权衡,就是将Undo版本清理的Purge过程拆分为两个阶段,同时供Flashback Query查询的数据不再提供二级索引,如下图所示:
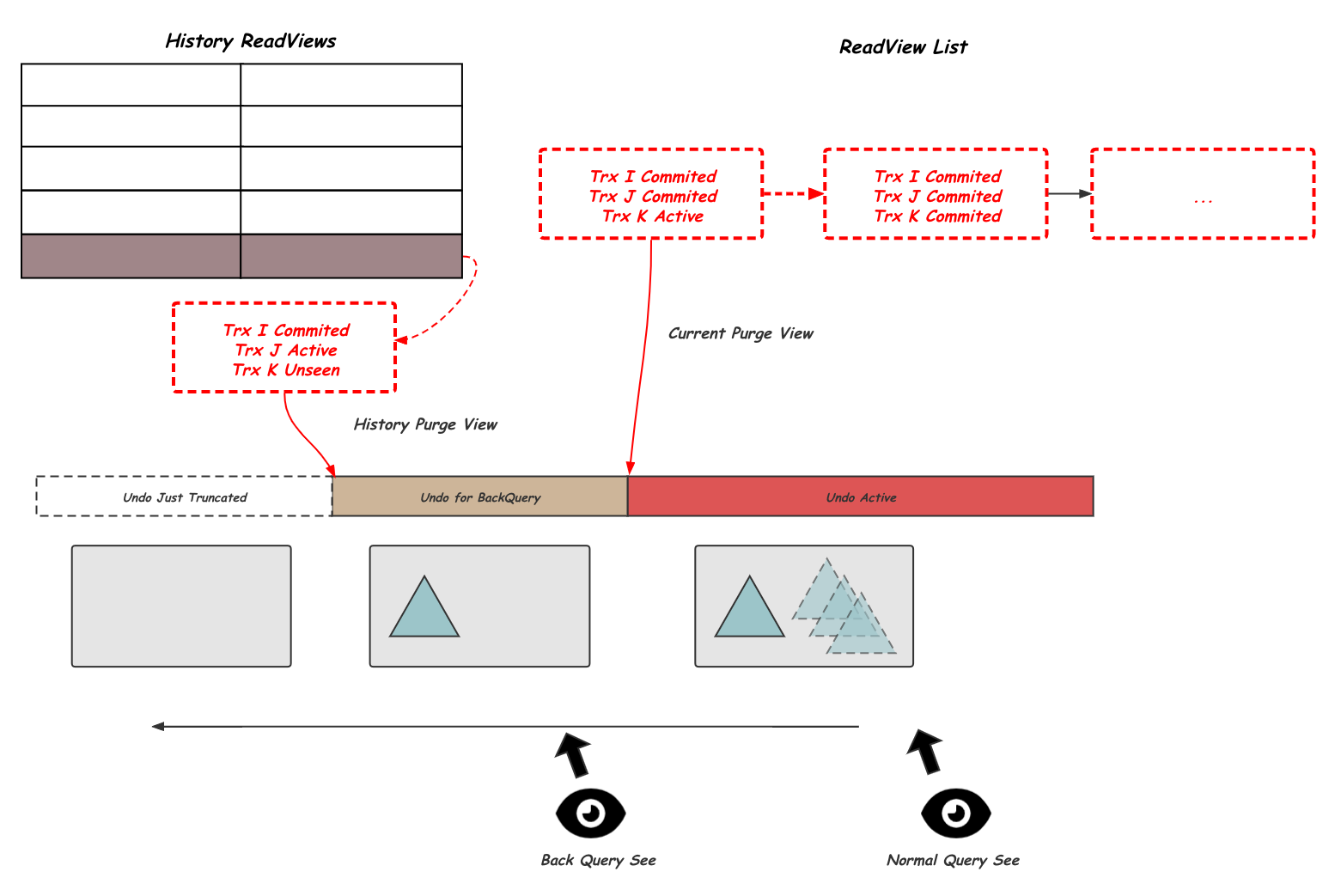
当前活跃的ReadView List中最老的ReadView作为限制第一轮Undo Purge的Current Purge View,经过这一轮的Undo Purge,所有对应的二级索引上的delete mark被删除,只保留其在主索引上的位置,对应上图的Undo for BackQuery。之后History ReadViews中最老的ReadView作为Hisotry Purge View限制第二轮的Undo Purge,经过这一轮的Undo Purge,对应的主索引上的delete mark也被清除,完成最终的清理任务。通过这种方式来避免上述二级索引删除回查过多的历史版本。
总结
我们通过定时保存ReadView的方式来利用PolarDB已有的多版本并发控制机制,实现对历史数据版本的Flashback Query。用保存下来的最老的ReadView限制延后Undo的正常清理,并且用双Purge机制来避免二级索引回查主索引版本链带来的性能开销。真正做到让历史随时可见。
后续PoalrDB BackQuery还会持续迭代,进一步拆分历史数据提供二级索引查询;通过版本合并来减少存储开销;支持表级别的BackQuery控制,提供更灵活的历史数据管理。提供更好用,低成本的历史数据查询能力。