PolarDB · 引擎特性 · Nonblock add column
Author: zhp259558
Oracle add column的特征
1. 同一事务会看到不同的版本的DD
SQL_1> select * from test;
A
----------
1
SQL_2> alter table test add b number;
Table altered.
SQL_1> select * from test;
A B
---------- ----------
1
Oracle 不保证事务访问到的DD(data difination)的一致性,而在MySQL中,由于MDL的保护,普通事务是不允许跨DDL的,因此任意普通事务只能看到单一版本的DD。
2. DDL会被写事务堵塞,但后续新的写事务不会被DDL阻塞
SQL_1> insert into test values(1,2);
1 row created.
SQL_2> alter table test add c number not null;
SQL_3> insert into test values(1,2);
1 row created.
SQL_3> commit;
Commit complete.
Oracle中,DDL会被写事务阻塞,但此时后续新的写事务不会被该DDL阻塞。而在MySQL中,由于MDL-X锁具有较高的优先级,因此一旦DDL被未提交的事务阻塞,后续该表上的所有新事务都将被阻塞以防止MDL-X锁饥饿。
3. 被阻塞的DDL不会被后续新事务阻塞
SQL_1> insert into test values(1,2);
1 row created.
SQL_2> alter table test add c number not null;
SQL_3> insert into test values(1,2);
1 row created.
SQL_1> rollback;
Rollback complete.
Table altered.
SQL_3> commit;
Commit complete.
SQL_1> select * from test;
A B C
---------- ---------- ----------
1 2
SQL_1> desc test;
Name Null? Type
----------------------------------------- -------- ----------------------------
A NUMBER
B NUMBER
C NOT NULL NUMBER
当DDL被事务1阻塞后,新进的事务3正常执行,当事务1回滚后DDL将执行完成,而不会被未提交的事务3阻塞。
但值得注意的是,在该场景下似乎出现了DD和数据不一致的情形,列C有NOT NULL NUMBER约束,但是查询出来的数据列C没有值(该行由事务3写入)。但对该问题我们未做深入探究。
从以上几个特征可以看出,Oracle的add column的约束比MySQL要弱,它不保证DD的事务特性。与DML事务的并发能力比MySQL要强很多,也不会出现MySQL常见的锁表问题。
PolarDB Nonblock add column的能力
1. Nonblock add column不会被未提交的事务阻塞
我们在一个会话中开启一个新的事务,在表t1中插入数据,但不提交。
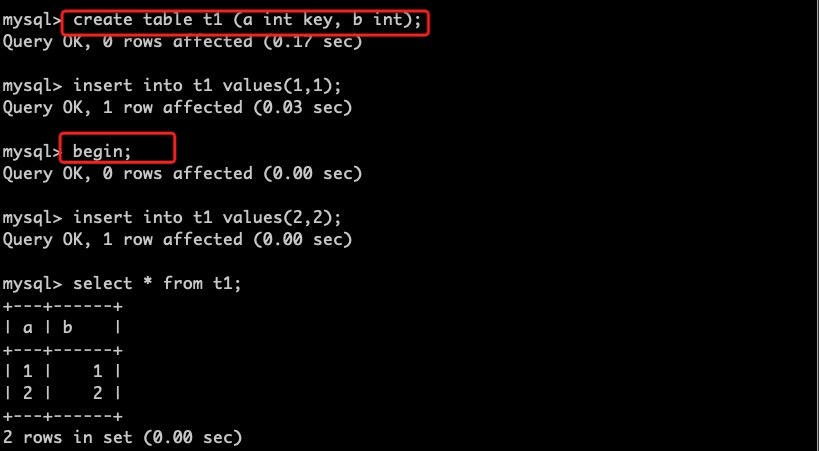
开启一个新的会话,我们首先查询数据,在RC的隔离级别下,未提交事务写入的数据不可见。然后做add column操作,该操作可以立即完成,而不会被未提交的事务阻塞。
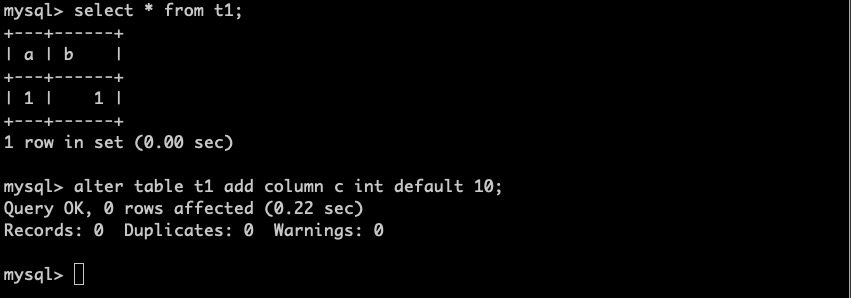
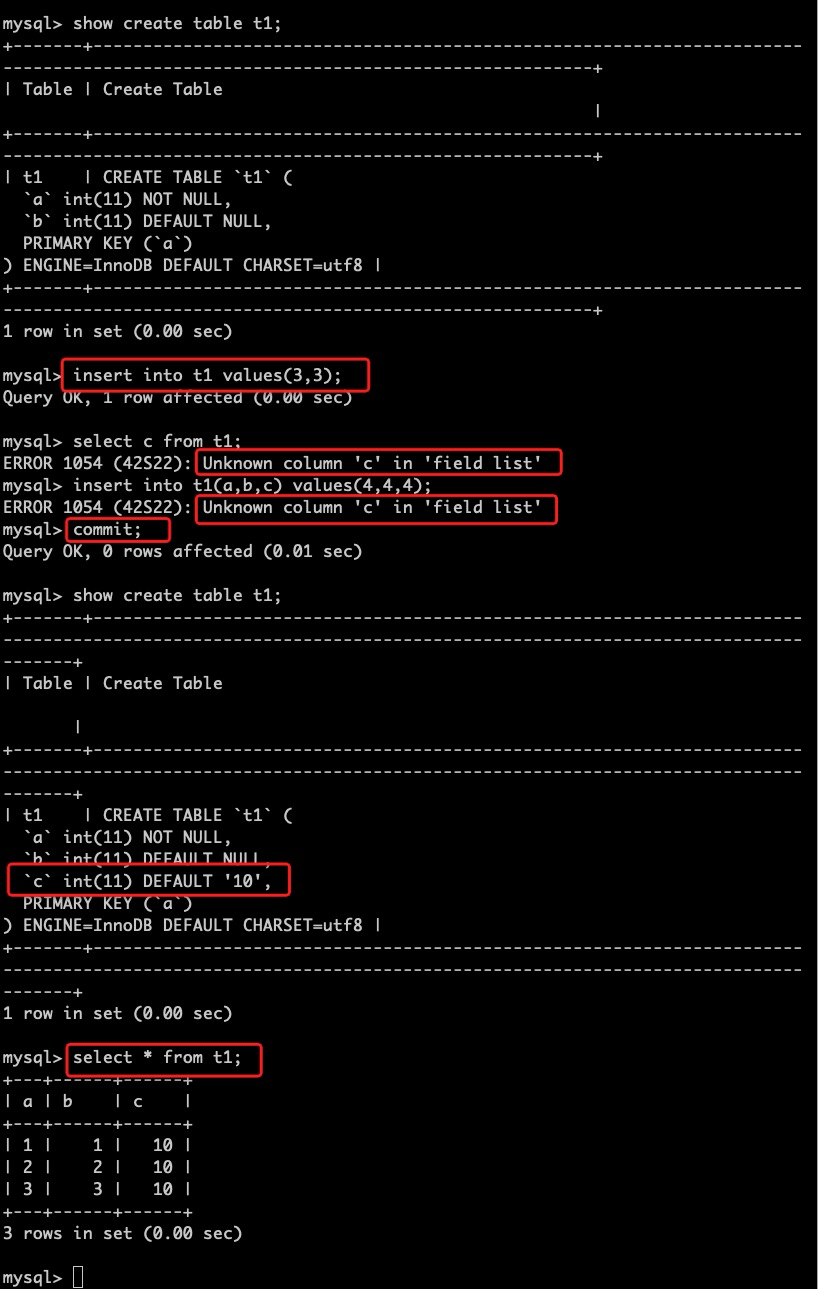
2. 保持DD的事务一致性,跨DDL的事务只能访问到一个版本的DD
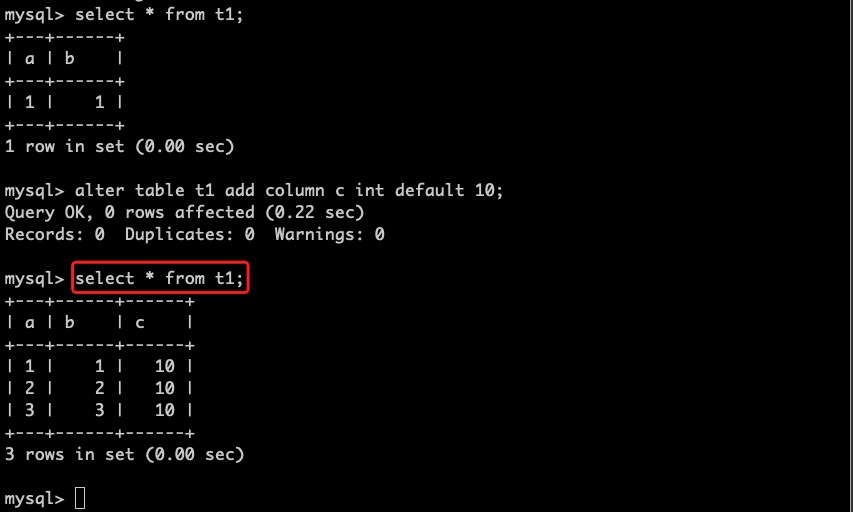
回到第一个会话,查看表结构并继续插入数据,此时由于该事务开始时间在add column之前,所以新增的列对其不可见。提交该事务后重新查询,我们将看到最新的表结构。
切换到第二个会话,当第一个会话的事务提交之后,查询将看到最新的已提交数据。
PolarDB Nonblock DDL的基本原理
1. DD多版本技术
说到多版本技术,最为人熟知的就是数据库的MVCC。Innodb MVCC的基本原理是允许每一行数据保持多个历史版本,这些版本通过undo链组织,每个事务在读取数据时都持有一个read view,通过read view判断该事务应该读取哪个版本的数据。通过MVCC,Innodb解决了数据读写相互阻塞的问题。但是,当我们把眼光投向DDL的时候,我们就会发现DD的读写仍然是相互阻塞的:DDL本质上是DD的写操作,而DML/DQL则是DD的读操作。因此为了实现DDL的Nonblock,我们需要在DD中引入MVCC技术,为每一个DD的元素赋予版本信息,允许同时存在DD元素的多个版本,同时为每一个事务绑定一个DD的read view。在访问DD时通过DD的read view判断DD元素的可见性并读取相应的版本。
2. DD元素的多版本存储
在MySQL8.0,所有表的DD信息都存储于Innodb中,以表的形式组织。整个DD的存储体系如下所示
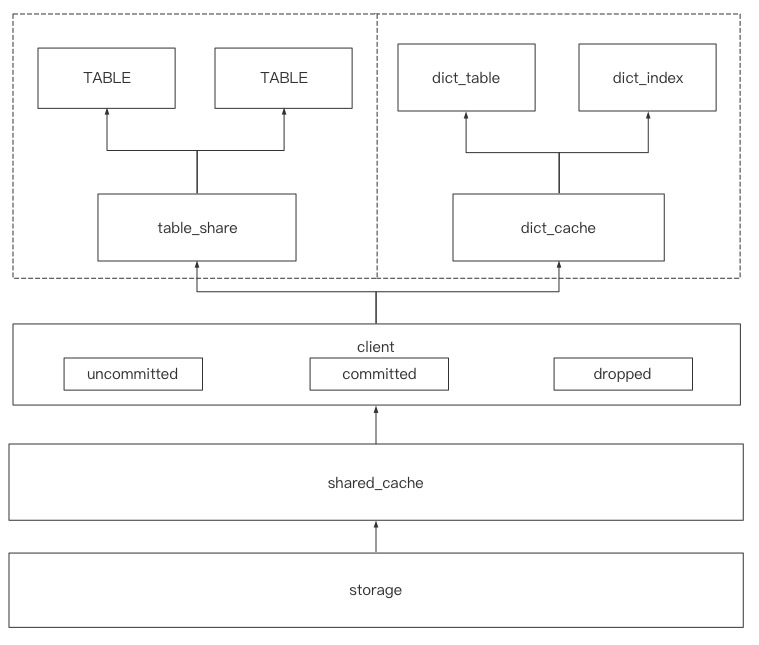
Server层和引擎层的DD信息都来于storage,这个storage就是InnoDB。在DEBUG模式下编译代码,并调用如下SQL语句,我们能看到所有用于存储DD的Innodb表。
set session debug='+d,skip_dd_table_access_check';
select name from mysql.tables where hidden='System' and type='BASE TABLE';
mysql> select name from mysql.tables where hidden='System' and type='BASE TABLE';
+------------------------------+
| name |
+------------------------------+
| dd_properties |
| innodb_dynamic_metadata |
| innodb_ddl_log |
| catalogs |
| character_sets |
| collations |
| column_statistics |
| column_type_elements |
| columns |
| events |
| foreign_key_column_usage |
| foreign_keys |
| index_column_usage |
| index_partitions |
| index_stats |
| indexes |
| parameter_type_elements |
| parameters |
| resource_groups |
| routines |
| schemata |
| st_spatial_reference_systems |
| table_partition_values |
| table_partitions |
| table_stats |
| tables |
| tablespace_files |
| tablespaces |
| triggers |
| view_routine_usage |
| view_table_usage |
+------------------------------+
31 rows in set (0.02 sec)
从这些表名,我们可以看到,MySQL将DD的信息分门别类的存储在不同的表中,例如columns表存储列的定义信息,indexes表存储索引的定义信息,这些DD的不同子项就是我们所说的DD元素,DD的多版本就是DD中这些元素的多版本。实际上在内部我们曾讨论过多版本信息的粒度问题。
- 粗粒度的实现整个表的多版本存储,DD中逻辑上存在table_v1,table_v2等同一个表的不同版本信息。
- 细粒度的实现特定元素的多版本存储,对表而言仅有一个版本,但是列/索引等DD元素存储多版本信息。以列信息为例,在该方案下表中的列具有如下图所示的逻辑结构。
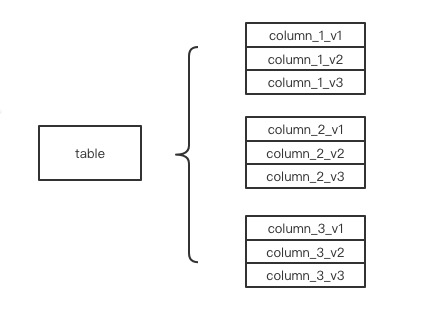
虽然细粒度的方案实现起来细节更多,但考虑的工程上的可迭代性,我们仍然选择了方案2。依据该方案的思路,我们率先实现了列信息的多版本:每个表有一个单调递增的唯一版本号,每个列在创建/修改时会从该版本号中分配一个。
3. 事务的DD ReadView
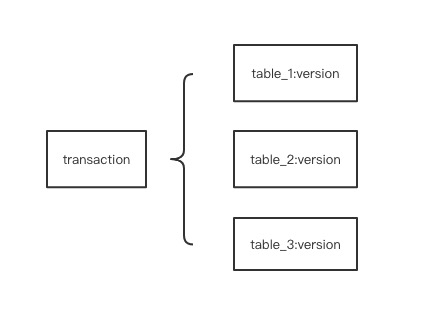
Innodb事务中存储了m_low_limit_id,m_up_limit_id,以及活跃事务列表m_ids等核心信息,用来选择数据的确切版本。因为我们不支持DDL本身的并行,也就是说任意时刻某个表上活跃的DD事务一个,所以DD的read view只需要记录目标表上单调递增的版本号就可以了,因此一个事务的DD ReadView有如下逻辑结构。为了保持MySQL DD语意的一致性,对DML/DQL事务来说,DD的读取总是RR的,当事务第一次访问到某个表时,DD ReadView中就记录了相应的版本,后续直到事务提交,该事务都只能看到该版本的DD信息(对Oracle来说,DD的读取可以认为是RC的,DDL事务提交后,非DDL事务可以立即看到最新的DD)。
4. 一次DDL和DML的并发过程
我们在下文抽象出DDL和DML的事务并发过程,该过程的一个实际例子在前文已有展示。
1. DML transaction begin;
1.1 open table t1;
1.2 build DD ReadView of table t1 (t1:v1)
1.3 use DD ReadView (t1:v1) to operate Data
2. DDL transaction begin;
2.1 operate data
2.2 operate DD
2.3 update table version to v2
2.4 commit
1.4 operate data with DD ReadView(t1:v1)
1.5 commit and release DD ReadView
3. DML transaction begin;
3.1 open table t1;
3.2 build DD ReadView of table t1 (t1:v2)
...
从上述流程中,我们可以看到,非DDL事务在open table时将构建DD ReadView并绑定,随后DDL的执行将不被未提交的事务阻塞,DDL提交后,事务利用ReadView仍然能保证随后看到同一个版本的DD。
Nonblock DDL的后续演进
1. Scope的扩大
PolarDB Nonblock add column已经在内部测试阶段,后续我们将支持更多DD元素的多版本,支持更多的DDL类型,目前在开发计划之内的DDL类型包括modify column type,add index。此外Converting table character set仍在调研阶段,modify column type和Converting a character set是目前为数不多的几个仅支持copy算法的常用DDL,解决这类DDL的并发问题是有非常大的意义的。
2. 限制的放宽
目前Nonblock DDL仅在普通表上得到了支持,在分区表或者含有Trigger/FTS/Foreign key等的表上还无法使用,这些类型的表在MySQL内部实现中关联了多个内部数据结构,具有更复杂的DD操作流程,后续我们将对这些特殊的的表进行适配和支持。