PolarDB · 引擎特性 · B-tree 并发控制优化
Author: Yang Yuming
InnoDB 索引
InnoDB 引擎使用索引组织表,每个表的数据都放在一个对应的索引中,该索引称为聚集索引(clustered index),使用索引组织表的目的是:
- 动态地组织磁盘文件结构,维护数据记录有序;
- 借助索引快速定位记录;
除了 clustered index,一个表中的其它索引称为二级索引(secondary indexes)。二级索引的每个 record 除了包含本身的 columns,还包含其对应的数据行的 primary key,InnoDB 可以利用 primary key 去主索引找到完整的 row。
InnoDB 使用 B-tree 作为索引的数据结构,B-tree 本质是多级索引,扁平且平衡的树结构可以保证单次访问数据的 IO 次数较小且固定。
InnoDB 实现的 B-tree 结构有几点特性:
- 实际数据全部存储在 leaf 层(即 B+ tree,降低树高度、优化顺序访问);
- non-leaf 层只存储索引项(key, page no),每个索引项指向唯一一个 child 节点;
- 一个索引项的 key 为 P,它的 child 节点只能存 >= P 并且 < P1 的记录,其中 P1 是下一个索引项的 key;
- 每层节点通过双向链表串起来;
B-tree 并发控制
如果把 B-tree 索引看成一个黑盒,不关心内部具体的数据结构,外面看来只有有序排列的 record,所有的读取、插入、删除等操作都能原子地一步完成。这时多线程并发操作不会感知到索引结构,只需要考虑事务层面的约束,例如 InnoDB 中一个事务对 record 加逻辑锁(lock)阻止其它事务访问。
但是实际的 B-tree 操作不是原子的,例如,一个线程在做结构调整(SMO)时会涉及多个页面的改动,此时另外一个线程进来会访问到不正确的 B-tree 结构而产生错误,另外,页面内部的数据结构改动也不能多线程并发执行。
InnoDB 是采用 page 加锁的方式对 B-tree 进行并发控制,每个 page 有一个对应的物理读写锁(rw latch),线程读取一个 page 要先加 S latch,修改 page 时要加 X latch。
因为 B-tree 索引的访问和修改流程是确定的,所以 InnoDB 有一套设计好的加锁规则,防止多线程死锁。与之对应的是,事务锁(lock)是用户层面的,加锁顺序不可控,因此需要死锁检测机制。
并发瓶颈
InnoDB 对 B-tree 的并发控制实现细节可以参考 InnoDB btree latch 优化历程 这篇文章,可以看到多次优化改进的目的都是为了提高 B-tree 的并发访问能力,即尽量减小每个操作的加锁范围和时间。
目前 8.0 版本在 B-tree 并发上还有一些限制:
-
SMO 无法并发:同一时刻只允许有一个 SMO 进行(SMO 线程持有 index SX latch),导致在大批量插入场景下 index latch 会成为全局的瓶颈点,MySQL 官方性能测试人员 Dimitrick 也指出 TPCC 场景下最大的瓶颈在于 index lock contention([MySQL Performance : TPCC “Mystery” SOLVED])。设想一下,如果将这个限制放开,多个做 SMO 的线程会同时进入 B-tree,每个线程要拿多个 page,如何设计加锁规则避免线程间死锁,有很多细节需要处理。
-
加锁范围大:为了避免死锁,乐观读写操作要持有遍历路径上所有 non-leaf page 的 S latch,SMO 操作要持有所有可能修改的 page 的 X latch。单一操作的加锁范围比较大,并发操作越多越会加剧锁竞争,在某些关键节点(例如,root、internal node)的竞争会更明显。理论上采用 latch coupling 的方式可以减小加锁范围,遍历过程中最多同时持有 2 个 page 的锁(即沿着一个指针从一个节点到另一个节点时,不能有其他线程去改变这个指针,因此要拿到后一个节点的 latch 再放开前一个 latch),有利于降低并发操作的竞争。
PolarDB 解决了上述 B-tree 并发控制上的限制:
- 提升并发度:去除 index 锁,允许所有操作并发访问 B-tree,线程间冲突只在 page 级别;
- 降低锁粒度:所有操作都实现了 latch coupling,减小锁范围,大大降低线程间冲突;
PolarDB 并发控制优化
PolarDB 设计了页级别的 B-tree 并发控制,对索引页的加锁规则如下:
规则 1:所有操作采用 latch coupling 形式遍历 B-tree,遍历过程中对非目标节点加 S latch(相当于读取节点指针),直到找到目标节点,根据操作读/写类型对目标节点加 S latch 或 X latch(SMO 操作涉及邻居节点更新,还需要加左右邻居节点的 latch);
为了避免死锁,规定加锁方向为,自上而下,从左到右。而 SMO 操作是自下而上的,即 SMO 的加锁方向是破坏规则的,会造成死锁(InnoDB 的 SMO 操作不使用 latch coupling 方式,开始就从上到下拿到所有相关节点的 latch,从而避免死锁)。
规则 2:在 SMO 操作中间,申请父节点或左邻居节点的 latch 之前,对当前持有 X latch 的 page 做 SMO 标记,并释放这些 latch。
这里借鉴了 B-link 的设计,将 SMO 操作划分为两个阶段,第一阶段完成提前释放 latch,避免了 SMO 操作反向加锁。这样,在 SMO 中间状态没有持有任何 latch。
SMO 中间状态节点设置一个指向其右侧节点的指针(side link),其它读操作访问到 SMO 中间状态的节点,并可以同时在其 right page 中检索,解决了 B-tree 结构不完整的问题。
其它写操作不应该修改处于 SMO 中间状态的节点,因为之前 SMO 操作还没提交。因此,其它线程的写操作遇到 SMO 节点,要等待其 SMO 完成。
规则 3: 其它线程遍历到有 SMO 标记的节点,并想要修改该节点时:立即释放掉已持有的 latch,等待该节点 SMO 完成再从 root 重试;
如果其它线程不释放已持有的 latch,相当于跟 SMO 线程之间互相占有并等待,造成死锁。
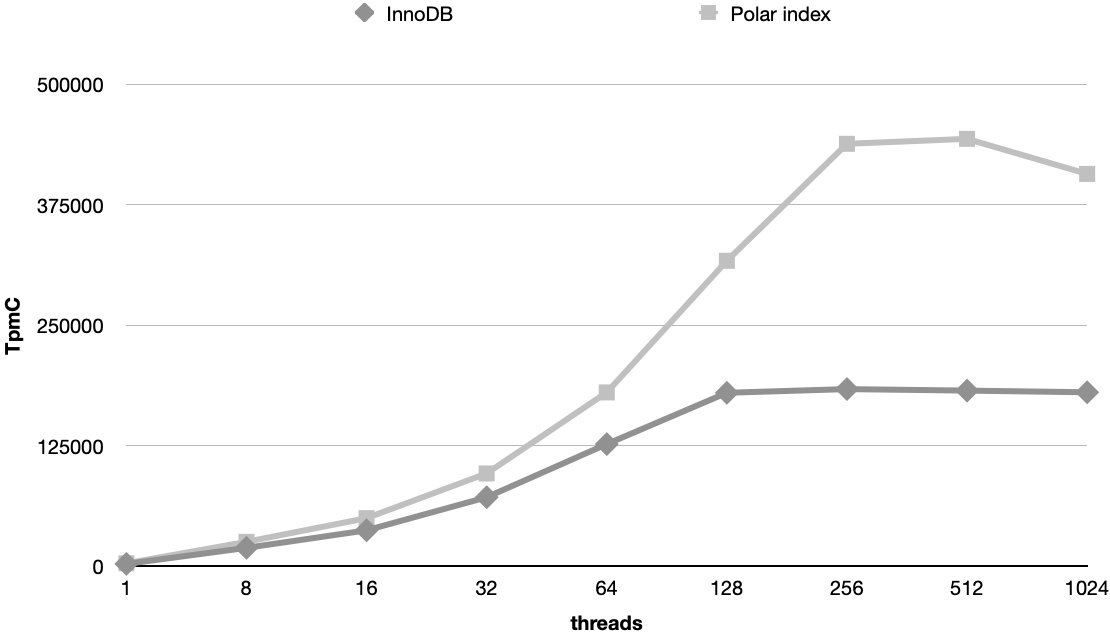
性能对比
采用上述的 B-tree 并发控制机制,在高并发 TPCC 场景(1000 warehouse),可以看到 Polar index 相比于 InnoDB,峰值提高 241%: