PolarDB ·性能大赛·云原生共享内存数据库性能优化
Author: saimu
第四届全球数据库大赛,瓜分40万奖金池,只等你来!各赛道TOP10都可获得现金奖励 “云原生共享内存数据库性能优化”赛道,邀您提交评测啦!
早鸟活动说明
1、即日起–7月29日,前60名报名【云原生共享内存数据库性能优化】赛道、提交有效代码并成功出分的参赛队伍,均可获赠 天池定制款笔记本一件 或 阿里云数据库定制款帆布包一个,先到先得! 2、即日起–8月22日,【云原生共享内存数据库性能优化】赛道初赛排行榜成绩前40位(需成功出分),且在赛道论坛发布高分心得文章的选手,均可获赠天池/阿里云数据库限量版订制电脑包一个! 3、邀请小伙伴报名,亦可赢取精美礼品: 报名期间(即日起-8月17日)成功邀请其他选手参赛即成为程序员鼓励师。鼓励师点击“报名参赛”下方“邀请参赛”生成个人专属海报,每拉新一个选手,可获得天池150粮票,粮票可在天池礼品库兑换天池纪念品。 4、另有早鸟礼遇,详见:https://developer.aliyun.com/adc/series/tianchi/polardb


注:
- 排行榜score显示0.0000,表示没有成绩,不符合成功出分条件。本大赛规程的最终解释权归本届大赛组织委员会所有
- 高分心得文章,文字篇幅不可低于500字
- 满足以上获奖条件的队伍,请加入【天池大赛】2022数据库大赛选手Q&A群,联系群主“七幕”
还未报名或没提交代码的小伙伴抓紧上车啦! 立即报名【赛道1】云原生共享内存数据库性能优化 — 点击跳转
大赛简介
2022年第四届全球数据库大赛—PolarDB性能挑战赛,是由阿里云、英特尔联袂主办,阿里云数据库、阿里云天池承办的数据库年度品牌赛事。自2018年以来,“阿里云数据库大赛”已经连续成功举办三届,吸引了国内外数千支队伍和个人参加,参赛者遍布11个国家和地区。 本届大赛采用双赛道机制,聚焦分布式共享内存池、基于索引的多维查询等数据库核心业务场景,参赛者在充分认知英特尔第二代傲腾持久内存(BPS)、Icelake CPU特质特性的情况下,设计最优的数据结构,探索数据库创新场景最佳实践。 其中,云原生共享内存数据库性能优化赛道,共设奖金20万元人民币
赛题解析
本赛题需要选手实现一个双节点的内存KV数据库,实现Put,Get接口并且支持并发读取。
赛题场景就是该数据库有本地和远端两个服务节点,且远端的内存远大于本端节点。本地节点负责接收Put或者Get指令后选择合适的策略将<K,V>数据存储在本地节点或者远端节点,远端节点负责接收本地节点发送来的<K, V>数据并存储。
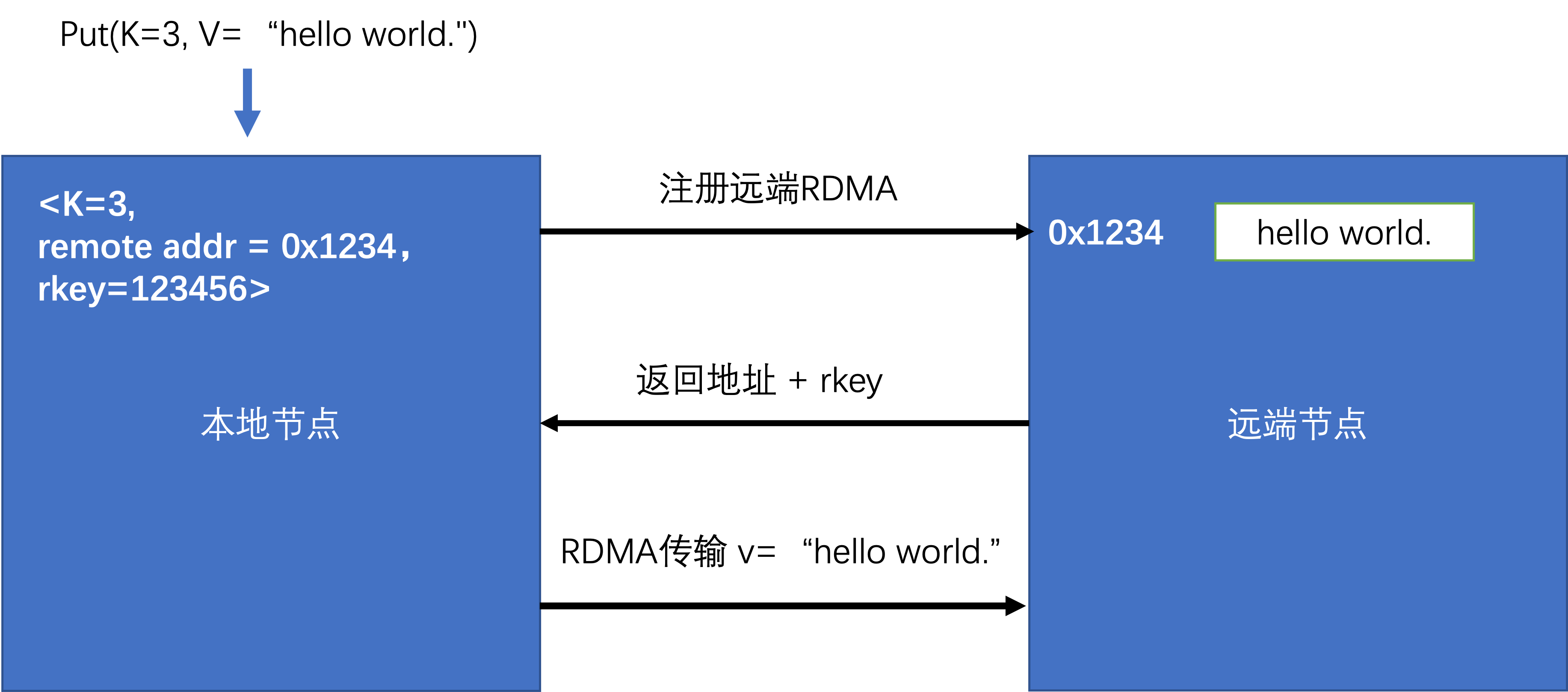
由于V的字节数远大于K的字节数,因此可以将V尽可能的存在远端,在本地存储K以及V在远端的位置。Sample Code中提供了一种解题思路,将K和V的存储分离,具体来说就是本地节点收到一条Put(K, V)指令后,将K存在本地内存中,通过远程通信手段(RDMA)将V传输到远端节点。下图展示了Sample Code中一条Put指令的过程,首先本地节点收到一条Put(3, “hello world “)指令后,向远端发送一条RDMA注册指令,申请在远端注册一块内存存放V, 远端节点收到该注册请求后注册内存并将该段内存的地址以及密钥返回给本地节点,本地节点将该数据作为K的元信息存储在本地,同时通过RDMA将V传输到远端节点完成存储。通过以上流程,远端节点存储了V,而本地节点保存了K以及对应的V的地址以及密钥。
解题思路
实现该KV数据库有以下几个设计难点:
- RDMA使用与内存分配
RDMA是一种特殊的通信工具,对比TCP等通信方式,其优势在于可以使得两个节点在不通过CPU的情况下完成数据的传输,大大减小了CPU的负载,提升了传输效率。 选手在使用RDMA时需要注意,当使用节点A访问节点B的一段内存时,需要节点B先注册该段内存,并将该段内存的地址addr以及密钥rkey告知节点A,节点A将B的内存地址addr、密钥rkey信息作为元信息存在本地。这部分工作需要节点A和B的CPU共同参与完成,注册完成后,A可以直接通过RDMA访问这段内存(A节点同样需要注册的相应内存为RDMA使用),无需通过B的CPU。 其次,选手使用节点A进行RDMA访问节点B的一段内存后,返回的数据需要存储在A的一段内存中,并且这段内存也需要提前被A注册。也就是说RDMA通信本质上是两个节点上的两段提前注册好的内存之间的信息传输。因此,使用RDMA前,必须在A和B两个节点中均进行内存注册。 Sample Code中提供了RDMA注册的示例代码,使用RDMA完成节点A和节点B通信的简单流程由以下三个步骤构成:
- 1、节点A和节点B建立连接
- 2、注册节点A内存,注册节点B的内存
- 3、节点A读写节点B的内存
第一步建立连接过程Sample Code已经提供,选手可以直接使用也可以自行优化。 第二部分内存注册的模版Sample Code中也已经提供,和上图保持一致,其对于内存的注册采取的策略是“即时注册”,即本地节点每次收到一条Put请求时,就发送指令给远端节点,注册一块相应大小的内存以存储该数据。然而这种注册方式存在两种问题(1)注册内存需要CPU的参与,频繁的调用注册导致程序性能下降。(2)基于该种注册方式,对于每个K,需要存储对应的V的addr和rkey等元信息,会消耗大量的内存。(这样的方式无法通过正确性测试) 因此后续选手应该优化Sample Code中的内存注册策略。提供一种参考的思路,每次注册一块较大的远端内存,在本地管理该数据在远端内存上的存储位置。这种方式减少了注册的次数,同时减少了元信息的内存消耗,但是需要选手自行管理每个数据存储在远端节点上的位置信息。对于RDMA的部分,Sample Code已经提供了完整的模版代码,选手需要在理解RDMA原理的基础上使用并完成步骤2的优化。 注意由于eRDMA内存使用特性,RDMA内存注册时建议以4096字节对齐, 如使用aligned_alloc。避免过多过小的内存注册,以避免额外元信息开销;避免超大的内存注册,避免注册失败或RDMA访问变慢。 选手的工作重心在于高效KV引擎的设计上,该部分着重考虑以下几个方面
- 哈希实现
Sample Code中使用了std::unordered_map存储每个K对应的V信息,选手直接提交会造成本地段OOM,因为std::unordered_map会导致巨大的内存消耗。因此,选手需要设计自己的哈希来存储K以及相应信息。
- 数据存储位置——local cache
设计合理的数据存储方式,将K和V存储在合适的位置。Sample Code中提供的方式将V全部存储在远端节点,本地节点存储K以及对应V在远端节点的元信息。一种优化思路是将一部分V存储在本地作为local cache,该部分由选手自行设计并比较。
- 冷热数据分离
由于测试数据存在热点分布,因此选手需要考虑将热点数据存在本地节点,将冷数据存放在远端节点。可以通过设计类似LRU的替换策略来替换冷热数据。
- 读写策略以及并发访问
Sample Code中的Put和Get的实现原理是以一个<K,V>键值对为单位进行读写,这会导致频繁的IO。选手可以参照操作系统的分页思想,以页为单位来进行数据的读写从而减少和远端IO的次数。 实现过程中需要满足多线程读取,并保证数据的正确性。该部分选手需要考虑如何分散对热点资源的访问,比如可以通过分区的方式来分散对哈希表的并发访问。同时选手应该减少通过while等消耗CPU资源的轮询方式来获取锁的机制。
报名方式
瓜分40万元奖金池,两大赛道任意选择,马上报名参赛: 【大赛专题页】第四届全球数据库大赛—PolarDB性能挑战赛 【赛道1】云原生共享内存数据库性能优化
奖项设置
云原生共享内存数据库性能优化赛道共设奖金20万元人民币 冠军:1支队伍,每支队伍奖金6万元人民币,颁发获奖证书。 亚军:2支队伍,每支队伍奖金3万元人民币,颁发获奖证书。 季军:3支队伍,每支队伍奖金2万元人民币,颁发获奖证书。 优胜奖:4支队伍,每支队伍奖金5千元人民币,颁发获奖证书。 (上述奖项以总决赛答辩的最终名次决定) 参与奖:初赛TOP50队伍的选手将获得大赛限量版纪念T恤一件,数量按照各队伍选手人数发放。 极客奖:复赛最终排名入围TOP20所在队伍的选手将获得阿里云数据库产品事业部优先推荐招聘名额。 注:同一选手只能获得一个参赛奖,多赛道入围前10排行榜的选手,按最高排行所在赛道计入名次,其余赛道该选手所在团队名次作废,获奖资格顺延。 (例:A选手在赛道1获得第一名,与B选手组队在赛道2获得第二名,则按赛道1名次发放奖品,赛道2名次作废,获奖资格向下顺延一位。)