PolarDB MySQL·HTAP·浅析IMCI的列存数据压缩
Author: 蔡鑫
前言
数据库迁移上云是大数据时代的一大趋势,PolarDB MySQL是阿里云自研的云原生数据库,主要处理在线事务负载(OLTP, OnLine Transactional Processing),深受企业用户的青睐。当下,数据分析对于企业的重要性越发显著:企业使用数据驱动决策,利用分析结果精准调配资源,从而降低成本,提升企业效率,推动业务创新,快速适应外部环境的变化。然而,传统数仓架构的滞后性限制了企业的创新步伐。因此,企业对OLTP数据库提出更高的要求,希望能在OLTP数据库同时进行复杂的实时分析(OLAP, OnLine Analytical Processing),及时应对业务环境的高速变化。
为满足混合负载(HTAP, Hybrid Transactional/Analytical Processing)的需求,部分客户选择了MySQL + Clickhouse的方案,但困扰于着两套独立系统的高使用和高维护成本,以及系统间的数据不一致等问题。客户寻求在一套系统上完美地应对HTAP负载的解决方案。对此,PolarDB MySQL 技术团队提出了基于In-Memory Column Index(以下简称IMCI)的HTAP技术方案,在PolarDB MySQL行存支持OLTP的基础上,原生地构建列存索引以及实现列存计算引擎,支持高效地实时分析,在TPC-H测试中获得数百倍于行存的加速效果。关于PolarDB HTAP和IMCI的详细介绍参考《400倍加速, PolarDB HTAP实时数据分析技术解密》[1]。
本文介绍数据的压缩方法以及PolarDB HTAP在列存数据压缩上的工作。PolarDB MySQL作为云原生数据库,具有存储计算分离的特点,计算资源独可以进行按需分配,而存储始终固定存在且持续增长的,需要压缩对存储成本进行控制。IMCI的数据存储是为列存格式,列数据相比于行数据具有更高的相似性,利于数据压缩。通过压缩,IMCI在大部分业务场景将列存存储空间减少到十分之一,大幅减少客户的存储成本。另外IMCI通过数据压缩,减少数据的大小和存储访问开销,并探究将计算下推到压缩数据从而加速分析,进一步为客户提供更好的OLAP查询性能,实现HTAP系统性能和成本的兼得。
后文主要分为4个部分,在“数据压缩概述”部分我们从数据压缩的理论基础——信息论谈起,结合数据库中的数据压缩问题进行讨论。在“压缩算法分类和介绍”中,我们将压缩方法分为通用压缩和轻量压缩,介绍数据库中最常见的通用压缩方法原理,然后逐一介绍轻量压缩,并讨论字符串的轻量字典压缩,为下一个部分铺垫。在“延迟解压加速计算”部分,我们介绍压缩数据上的直接查询的优化技术,又称为延迟解压技术,然后分析基于字符串字典压缩优化的原理和难点。最后,我们进行“总结以及后续工作”的讨论,展望PolarDB HTAP在数据压缩方向的后续工作。
数据压缩概述
压缩算法包括无损压缩和有损压缩,本文我们只讨论无损压缩,即解压后的文本与压缩前的文本完全相同,后文的“压缩”都是指无损压缩。压缩算法由编码和解码两部分构成,编码和解码本质上是将文本映射到另一个更紧凑的文本空间以及逆映射的过程。
压缩与概率是紧密相关的。所有的压缩算法对于输入数据都有一定的预先假设,这种假设可以用概率描述,例如假设某种数据重复的概率或某几种数据一起出现的概率高。香农的论文《通信的数学原理》,被视为现代信息论研究的开端,正是信息论将数据出现的概率和数据所需编码长度联系起来。在论文中,香农从统计物理学中借鉴了熵的概念,定义了信息熵[2]: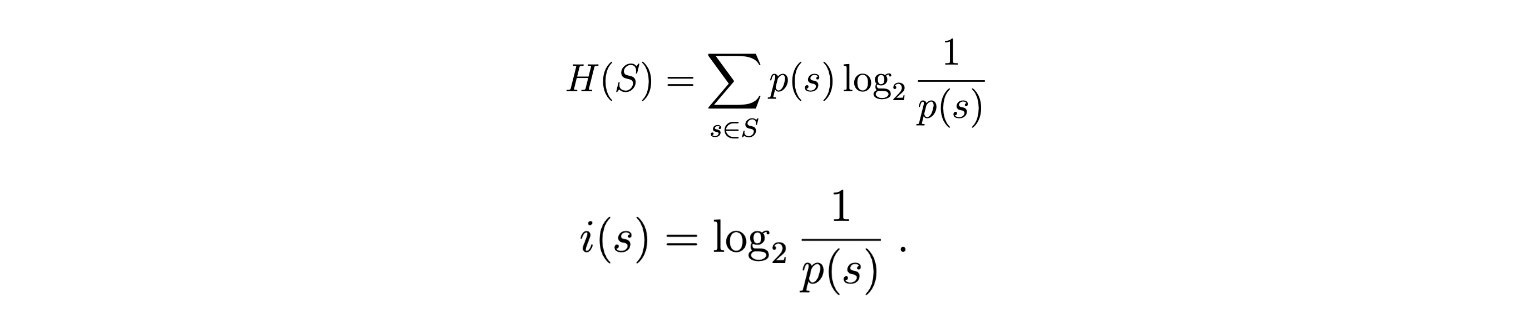
H(S)即信息熵,S是所有信息s构成的集合,p(s) 是信息s出现的概率,s ∈ S。i(s)表示需要编码单个信息所需要的比特数,而信息熵H(S)是i(s)以概率p(s)为权重的加权平均,表示编码信息集合S所需的总比特数。
举个例子简单理解这两个公式。我们假设96个可打印字符出现的概率相同,那么编码每个字符需要的平均比特数,即i(s) = log_2(96) = 6.6 bits/char,显然,至少7 bits才可以表示96(2^7=128)个不同的字符。如果我们基于一个英文文本集(例如Calgary Corpus)进行统计,使用字符的频率近似概率,计算出信息熵的平均值i(s)为4.5 bits/char,具体编码可以通过huffman编码算法得到。这个估算认为字符间是独立的,如果考虑上相邻字符、单词间的关联结合超大文本进行统计,编码字符所需要的比特数是1.3 bits/char,8/1.3 = 6.15近似为任意英文文章的压缩比的上界。
通用压缩算法对输入数据仅做简单的假设,如假设数据存在局部相似性等。GZIP和BOA在Calgary Corpus文本集的压缩效果为2.7 bits/char和2.0 bits/char,如果要更接近英文文本的压缩上界,通用压缩算法需要英文词频和语法等作为输入,这将影响其通用性。我们在下一部分对常见通用压缩算法的原理进行简单介绍。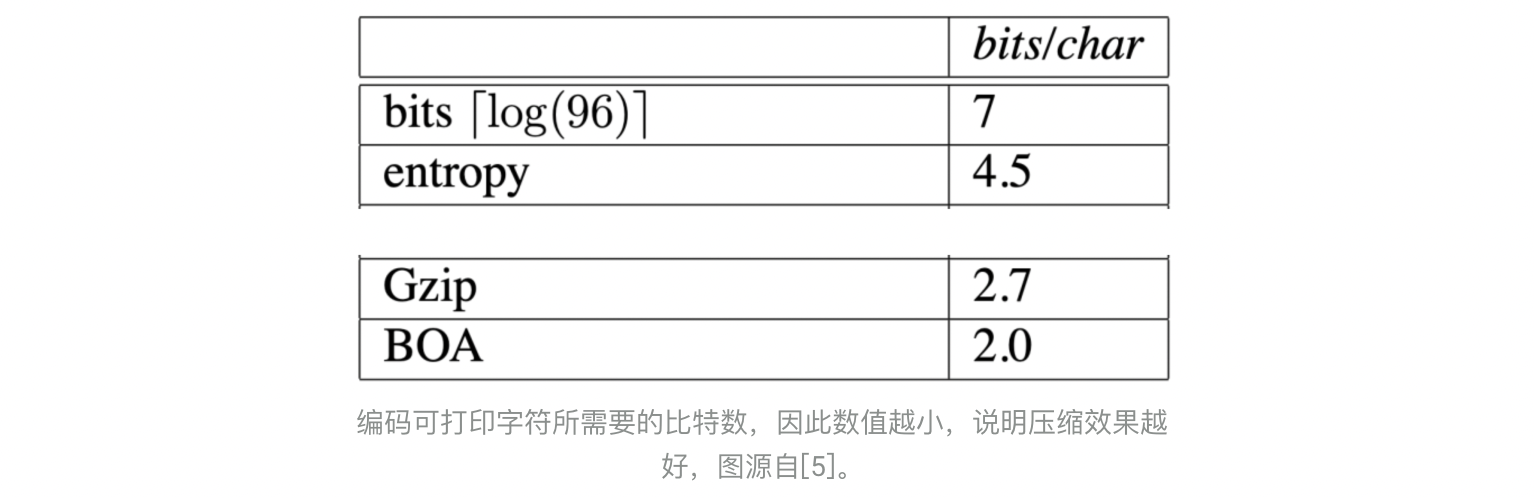
了解压缩与概率的关联后,我们看看数据库系统中的数据压缩问题。首先我们关注OLTP数据库和OLAP数据库的数据存储格式,常见的OLTP数据库的存储引擎包括基于B+Tree的innodb和基于LSM-Tree的X-Engine和rocksDB等,它们使用行式存储,表数据按行水平分割,每个记录会包含各个不同的列。而OLAP数据库使用列式存储,表数据按列垂直分割,每列数据单独存储。假设使用通用压缩算法,同一列数据的局部相似性一般高于不同的列,因此列存相比行存天然具有更高的压缩比。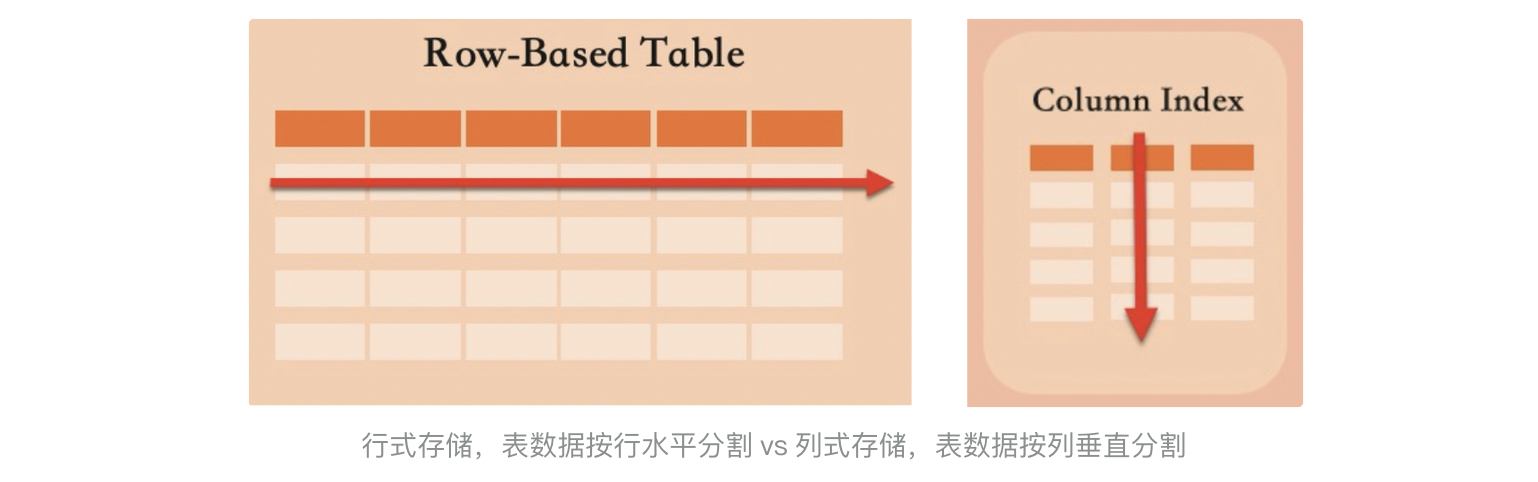
另一方面由于列存按列组织数据,因此不同的列可以选择不同的压缩算法,在下一部分我们将看到轻量压缩根据不同列的类型和特征,借此获得远高于通用压缩的压缩比和压缩解压性能。
论文[3]分析了列存相对行存加速查询的原因,包括高压缩,批处理和延迟物化等,其中仅考虑压缩,相比行存,列存数据库平均获得10倍以上的查询加速比。我们在IMCI的TPC-H测试中验证了这一结论,而且在业务真实数据中可以达到平均10倍的压缩比。可见数据压缩对于列存数据库尤为重要。
压缩算法分类和介绍
学术上对于压缩算法已经有了相当充分的研究,最新的学术工作开始探索深度学习方法更精确地估计数据的概率分布,从而提升压缩比,但暂未有大规模的实际应用。大部分压缩算法的区别在于工程上的优化。我们将压缩分为通用压缩和轻量压缩,通用压缩对输入不做复杂的假设,以块为粒度压缩数据,适用于各类数据;轻量压缩的使用存在限制条件,需要数据满足一定特性,例如有序性,distinct值少等,但压缩比,压缩和解压速度上优于通用压缩,并能进一步优化查询。两类压缩算法不冲突,通常会结合使用获得更高的压缩比。
通用压缩
我们简要介绍LZ4和ZSTD,它们是在目前数据库领域最为常用的两种快速压缩算法,相对于其他通用压缩算法,它们的压缩和解压性能较为突出,更适合数据库的数据访问模式。LZ4的特点是解压速度快,但压缩比一般,在lzbench标准测试中,解压速度达到4.97GB/s。Zstd 全称为Zstandard,定位是提供高压缩比的快速压缩算法,由Facebook于2016年发布的。Zstd 采用了有限状态熵(FSE,Finite State Entropy)编码器,获得了更高的压缩比的同时解压性能仍然保持在较高水平,lzbench测试中解压速度到 1.38GB/s。
事实上,包括LZ4和ZSTD在内,常见的snappy, zlib, gzip等压缩算法都属于LZ77算法的变体,因此我们简单介绍LZ77算法的原理。
LZ77 算法及其变体都使用了随cursor移动的滑动窗口。Cursor指向当前需要压缩的第一个位置,并把窗口分为两部分,cursor之前的部分,称为字典;包含cursor开始的部分,称为lookahead buffer。这两个部分的大小是由参数设置,在算法执行过程中是固定的。基本算法非常简单,循环执行以下步骤:
- 查找从cursor开始并完全包含在lookahead buffer中的字符串与字典中的字符串的最长匹配。
- 输出一个压缩结果三元组 (p, n, c),为字典中的位置p、匹配的长度 n 和匹配部分的下一个字符c。p是相对cursor的距离,具体含义是匹配字符串在字典中的第一个字符相对cursor的偏移量。
- 将光标向前移动 n + 1 个字符。
我们举个例子,如下图所示,使用LZ77算法压缩字符串aacaacabcabaaac,围绕字符的方框表示cursor,加粗的字符串部分是字典,大小为5,下划线字符串部分为lookahead buffer,大小为4(包括cursor指向的字符)。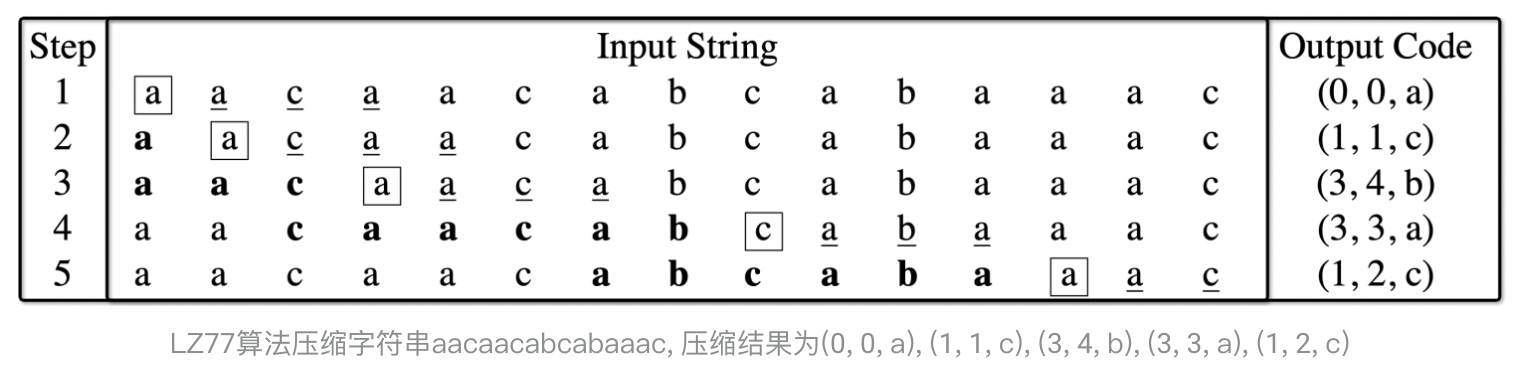
step1: 滑动窗口的字典部分为空,lookahead buffer为aaca,字典为空无法匹配,直接输出(0, 0, a)。
step2: 当前字典为a,lookahead buffer为acaa,匹配a后的下一个字符为c,输出(1, 1, c)。
step3: 当前字典为aac,lookahead buffer为aaca,在step3中,未优化的情况下,匹配到aac时应该结束,优化处理后实际匹配的字符串为aaca,下一个字符为b,输出(3, 4, b)。
step4: 当前字典为caacab,lookahead buffer为caba,匹配cab后的下一个字符为a,输出(3, 3, a)。
step5: 当前字典为abcaba,lookahead buffer为aac,类似step3,匹配aa后的下一个字符为c,输出(1, 2, c)。
step3和step5产生的(3,4,b)和(1,2,c)比较特殊,仔细观察会发现匹配的字符串超出了字典,即n > p,此时字典匹配在cursor的边界[cursor - p, cursor - 1],这部分被当成ring buffer, 匹配到末尾后又从头开始匹配,实现了对连续重复字符串的编码优化,这个压缩效果和下面介绍的轻量压缩中的RLE编码效果相似。结合解压过程动态产生字典的过程,可以更好理解这个处理。
解压比较简单,整个过程是边解压边使用之前解码的数据作为当前字典。step3和step5的需要特殊处理,当字典中出现的位置p小于匹配的长度 n,将p到cursor的字符串复制n / p次后加上剩下的n % p个字符即可。
从LZ77算法的原理中,我们不难理解为什么LZ4, ZSTD等LZ77变种的算法在压缩和解压方面的性能具有不对称性。这种不对称性体现在随着压缩等级增大,压缩比增加,压缩速度下降,但解压速度几乎不受影响,因为压缩过程中的计算复杂度取决于字典窗口的大小和匹配字符的长度等,而解压的过程仅仅是从字典中定位,拷贝数据到输出中。
轻量压缩
前文提到通用压缩以块为粒度压缩数据,这导致数据的随机访问存在读放大问题,即读取一个记录需要将块中所有的记录进行解压,计算代价大。这在内存计算为主的场景中严重影响性能,因此通用压缩常用于落盘数据,而内存压缩,使用轻量压缩方法。下面分字符串类型编码,数值类型编码,数据类型无关编码三个类别讨论轻量压缩方法。
[字符串类型编码]
- Prefix编码:前缀编码(incremental encoding/front coding),通过将字符串按字典序排列,将当前字符串表示为和上一个字符串重复的部分的长度 + 不重复的剩余部分。
[数值类型编码]
- FOR编码:FOR,Frame Of Reference存储与最小值进行相减后的结果。无须数据有序,压缩和解压速度很快,可以在压缩后的数组上进行O(1)随机访存,只需要额外存储的最小值信息。
- Delta编码:存储两两相邻相减的结果,有序存储的数据,两两相邻相减后的结果取值范围很小,例如主键两两相邻相减后近似常数。
- NS编码:Null Supression, NS算法本质是设计新的编码,尽量只存储数据的有效位(非0位),节省前缀存在的连续的0的存储开销。学术界主要关注这类轻量压缩算法,设计了诸多编码结合SIMD优化, 代表性的varint-GB, SIMD-BP128, simple_8b, fastpfor等,也在业界广泛使用,例如google的protobuf即使用了varint进行编码。NS假设待压缩数据为非负数(因为负数补码最高为1,不存在无效位)。常见和FOR编码, Delta编码等结合使用,例如FOR编码, Delta编码逻辑上将数据范围从int64缩小到int16,再使用NS编码将数据物理存储代价减少到int16即可。
[数据类型无关编码]
- 字典编码:字典编码本质是将重复性较高的一段数据作为字典entry,使用字典下标number替代原文的字典entry,达到压缩的目的。解压过程,将下标对应的数据从字典中取出即可。我们按字典entry的设计简单将字典编码分为三个子类。
- Entry为完整的单个记录(例如完整的字符串),编码后原数据用字典中的下标替代,适用于distinct值较少的列。
- 使用base + offset处理数值数据,Entry为base,原数据编码后为(下标, offset)的二元组。
- 使用common prefix + suffix处理二进制数据,Entry为common prefix,编码后为(下标, suffix)的二元组。
- RLE编码:要求连续重复的数据尽可能集中在一起,因此需要排序。编码结果为(value,length,position)的三元组,例如0,0,1,1,1…的数据,编码为(0, 2, 0),(1, 3, 2),压缩效果取决于avg run length,压缩比近似data size/avg run length。
- Bitmap编码:distinct值极端少的情况下使用bitmap压缩,例如数据为性别male, female,转化为两个bit位数等同于列数据长度的bitmap。bitmap本身就有集合的语义,可以用于group by等操作的优化以及集合运算。
- Constant编码:针对近似Constant的数据,出现频率最高的数据视为Constant,而只记录所有不等于这个Constant的异常值和它们的行号,Constant编码在实际业务数据中对应使用了默认值的列。
对比通用压缩算法和轻量压缩算法介绍,不难发现轻量压缩算法的压缩和解压较为简单,计算代价小,并且压缩后的数据仍然可以参与计算,例如RLE编码后的数据用于加速求和,FOR编码的数据更紧凑,CPU计算效率更高。
字符串的轻量字典压缩
本节我们展开讨论字符串的字典压缩算法,我们按构建字典entry的粒度将字典压缩分为三类:对整个字符串,子字符串和单个字符编码的字典。分别使用direct map,pattern map,char map区分三类算法。这三类算法及对应的典型算法如下:
- direct map: dictionary
- pattern map: FSST,见论文[4]
- char map: huffman
其中,从算法1->算法3,算法的通用程度低->通用程度高,解压速度高->解压速度低,压缩比则与实际数据的分布有关。对于cardinality较小的数据如category类的数据应使用dictionary,可获得较高的压缩比。对于pattern skew的情况,例如urls集合,FSST更适用。 Huffman编码在GZIP和ZSTD中使用,使用Huffman编码对滑动窗口压缩过的数据再进行压缩,进一步增加压缩比。
字典压缩算法通常具有保序性: **如下图所示字典映射后原字符串和编码相对顺序不变,方便直接在压缩数据上进行range查询优化。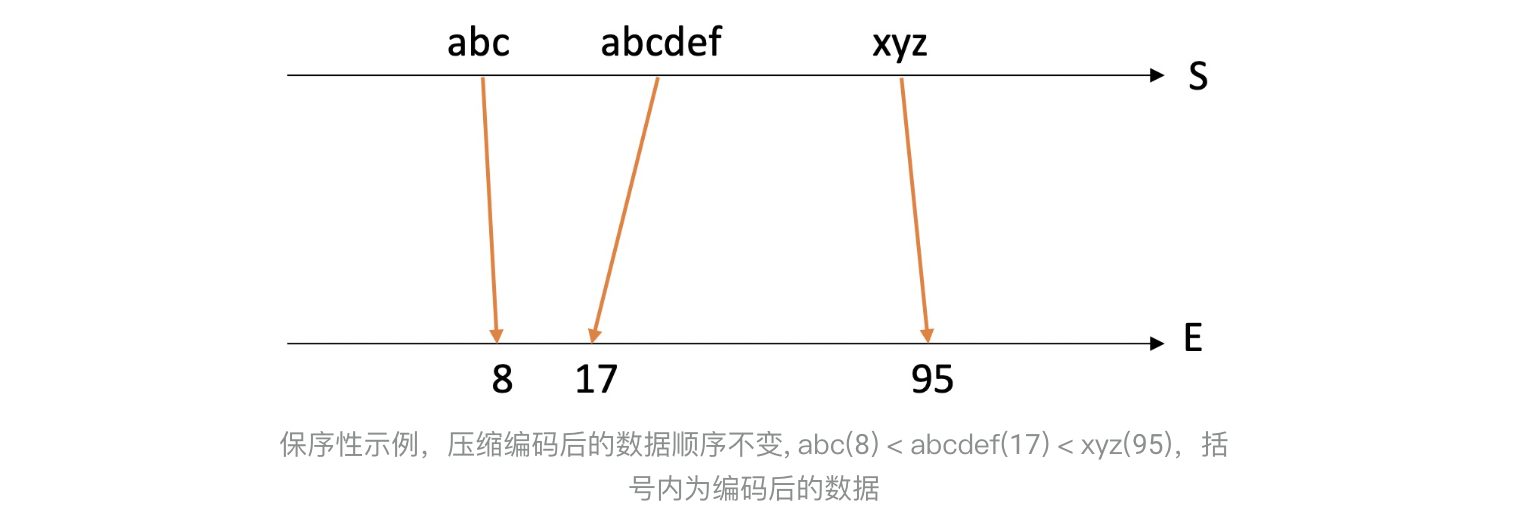
编码方式的变长vs定长**,变长的压缩比更高,但解压速度更慢,变长数据通过padding可以转化为定长,便于使用SIMD加速计算。direct map则是定长编码,而pattern map和char map为变长,编码方式影响三者的解压速度。
延迟解压加速计算
数据压缩能减少存储空间和IO的开销,代价是需要支付额外的计算资源对数据进行解压,是时间换空间的trade-off。由于IO带宽相比计算资源更容易成为瓶颈,因此开启压缩后,性能会提升。但数据在内存压缩时,数据解压占用计算资源,降低并行度,可能导致列存查询成倍的性能下降。因此如果条件允许,避免解压或者延迟解压,直接在压缩数据上查询是有必要的。例如对于以下查询:
SELECT COUNT(1) FROM table_a WHERE col_1 = "xxx";
假设我们将col_1列数据以压缩后的编码存放,并在执行查询时使用字典将查询条件中的字符串”xxx”映射为数字,查询时就能使用字典压缩结果与”xxx”的映射值直接进行比较,从而将string比较转化为int数据比较,可减少内存带宽压力和计算代价,提高性能。
可见在特定的查询和使用了特定的压缩算法下,我们能够直接在压缩数据上查询,由于数据压缩后比较的计算量减少,内存中可cache更多数据,查询性能将有明显的提升。Oracle IMC,DB2 BLU等列存产品实现了尽可能避免解压操作的优化,而且将该优化作为和同类列存产品对比的一个重要特征。本节我们介绍论文[5]的直接查询压缩数据的算法原理。
支持延迟解压的算子
[SCAN下推]
Scan算子的延迟解压加速,主要是谓词下推,在压缩数据上直接过滤。
string类型数据,对于string类型字典压缩:
- 使用保序direct map字典编码,压缩后数据类型由string -> int,通过重写查询,将string比较转化为int数据比较,可支持QE, NE, Between, LT, GE, IN, 前缀的like等比较,适用于cardinality不大的列(50,000~100,000)。

- 使用Pattern map例如FSST, 压缩后仍然是string,可支持QE, NE, IN等操作。由于Pattern map字典不保序摸,因此只支持点查询的延迟解压。
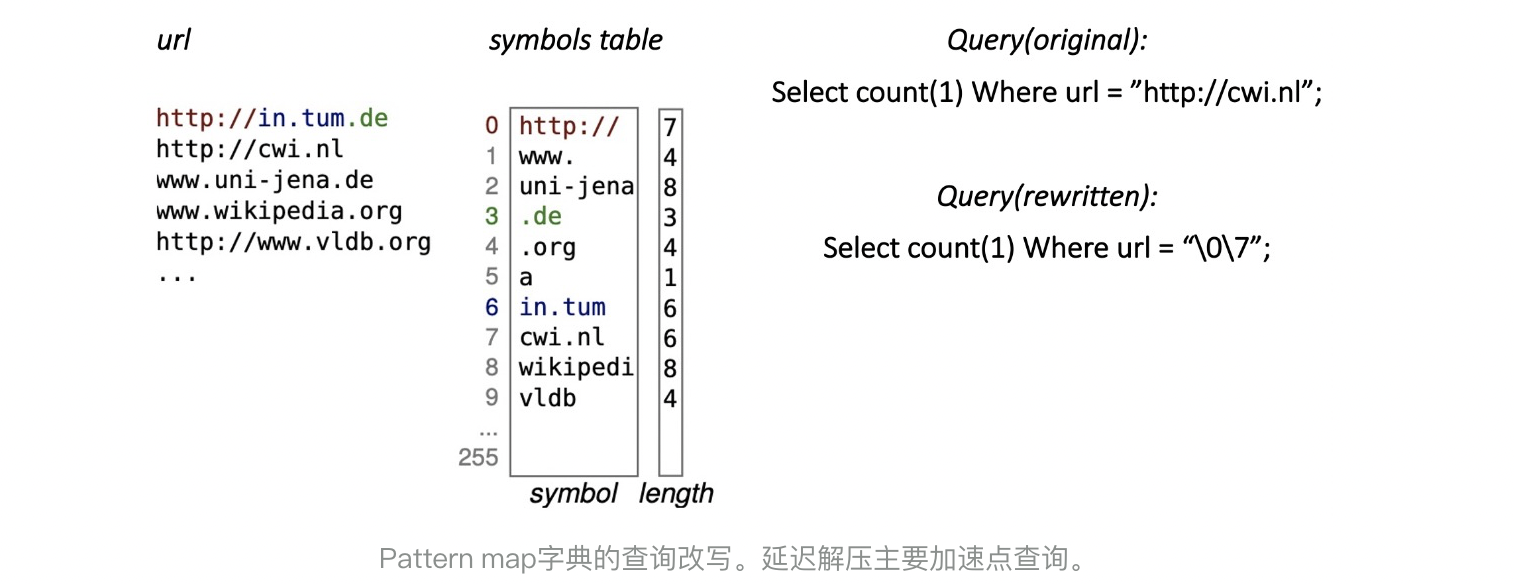
int类型数据,例如int64类型使用FOR算法压缩到15bits,当查询条件为 col = value,则将value改写为value - min即可。
[JOIN]
论文[5]提到RLE和bit vector编码,以nested loop join为例,当发现其中一列为RLE时,便能跳过k次比较(k 是run length)。此为如果使用了全局字典,即不同的列使用了相同的字典压缩,那两列可以直接进行延迟解压的比较操作,返回匹配的行id,从而加速JOIN。
[GROUPBY聚合]
数据以RLE编码,bitmap编码或者字典编码时可以加速groupby聚合。RLE,bitmap和字典相当于已经进行一轮聚类,在这基础上,可以对例如aggregation, distinct计算进行优化,例如RLE编码的求和转化为v * run length的和,distinct相关计算仅需要扫描字典或者返回字典大小。
压缩数据SCAN的谓词下推
AP查询通常需要扫描大量落盘数据。压缩数据SCAN的谓词下推,常与字典压缩算法结合,实现延迟解压加速查询。压缩数据SCAN的谓词下推,主要包括以下3个过程:
1. 元信息检查,是否符合延迟解压的条件。
2. 谓词改写,使用相同的字典改写查询条件。
3. 谓词下推,扫描压缩数据,返回匹配行。
实际上,在数据库中字符串的比较,不仅需要考虑charset,还要考虑collation。Collation定义了字符集中元素的顺序,它本质是一种映射,将字符映射为可比较顺序的编码。如果collation为二进制序binary,直接在压缩数据上比较没有问题,但几乎所有字符集默认的collation不是binary,例如latin1字符集的默认collation为latin1_swedish_ci,下图为该collation的部分截图。可以看到尽管A, a等二进制编码不同,但在比较时被认为是相同。大部分collation问题在于它是n对1的映射关系,而无损压缩算法是1对1映射,因此无法直接使用压缩后的编码进行比较。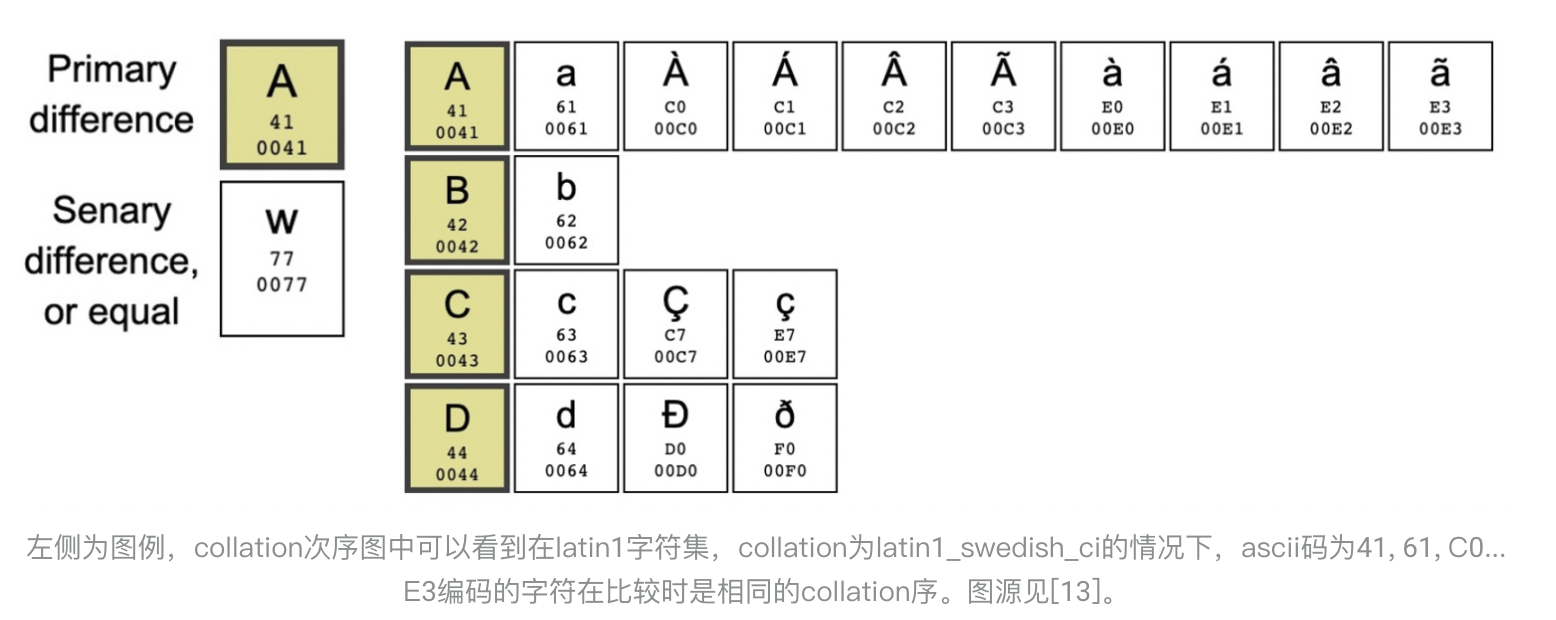
我们举个例子来说明这个问题,字符串“abc”, “abcdef”, “xyz”, “åbc”字典压缩后为“8,17,95,100”,压缩后是保证字典序的,“abc”和 “åbc”仅看压缩的编码“8”和“100”是不同的,在带collation的比较时却被认为是同一个字符串,因此无法运用延迟解压,必须进行解压后使用带collation的比较。那问题是可以使用collation顺序代替字典序吗?显然是不行的,如果我们只保存collation,在这个例子中,如果要解码数字1,它即可以是“abc”,又可以是“åbc”,无法逆映射,可见collation只能用于顺序的比较。 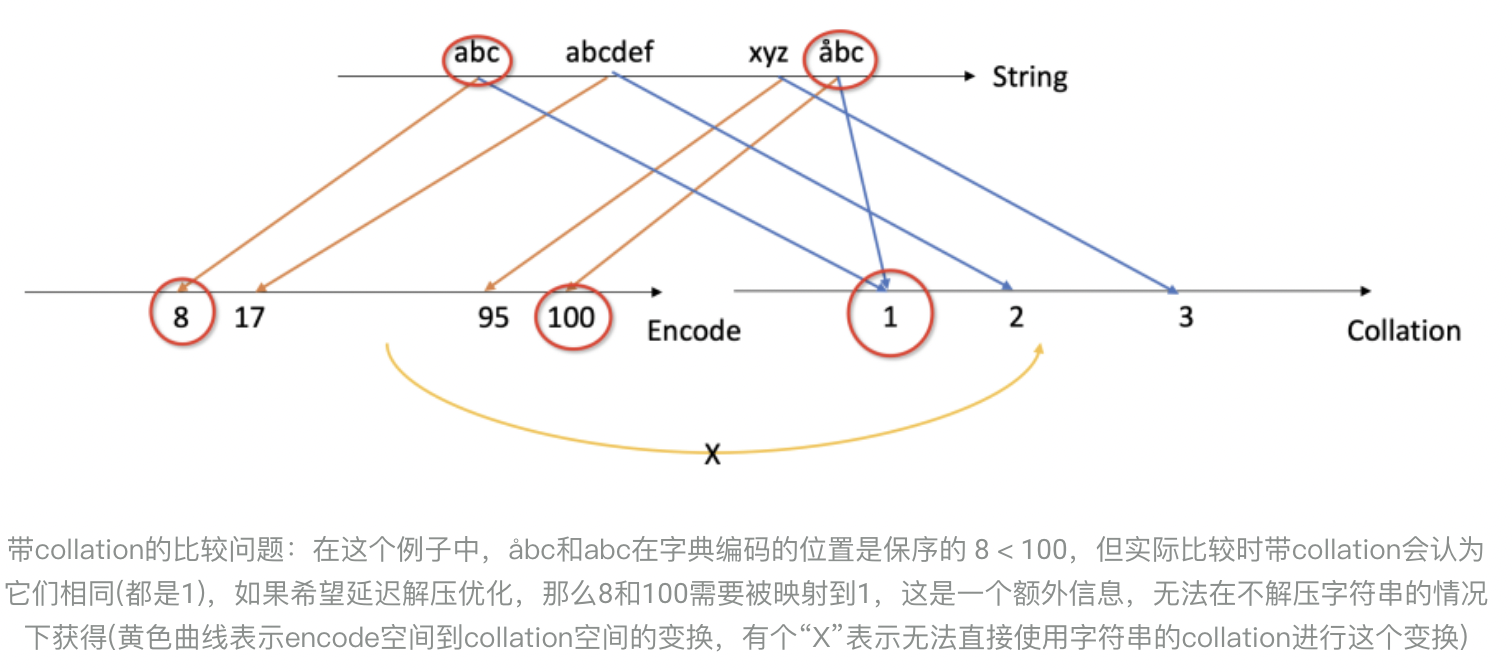
一个解决方案是通过额外保存列默认collation结果,查询时直接使用保存的结果进行比较。通过存储collation结果,可以在字符串比较时节省计算,缺点是存储collation编码需要额外内存和存储空间,对压缩比有更高的要求。在IMCI中,我们验证了压缩数据SCAN的谓词下推效果,在不同的scan查询场景中获得了3 ~ 20倍的查询加速。
总结以及后续工作
数据压缩作为数据库一项重要技术,在列存执行中结合延迟解压,在系统性能和成本的平衡中起到关键作用。本文首先介绍数据压缩的理论基础,信息论,其为压缩效果定义了边界,然后分析了数据压缩在行存和列存数据库中的不同。压缩方法分为通用压缩和轻量压缩,数据库中最常见的通用压缩算法LZ4和ZSTD都基于LZ77算法,然后我们逐一介绍轻量压缩方法。随后我们讨论轻量压缩数据上的直接查询技术,在该部分我们介绍基于字典压缩实现字符串延迟解压的原理,对性能的影响以及需要解决的问题。
IMCI是PolarDB迈向数据分析市场的第一步,接下来我们将始终如一地深挖技术,结合业务场景,优化HTAP细节并落实到客户的实际应用,为客户降本增效持续赋能。最后,我们展望PolarDB HTAP在压缩技术方面的后续工作:
- 探索压缩相关的最新的学术研究成果在用户实际场景的最佳实践。
- 在基于规则的列压缩选择算法上,探索并落地基于schema和数据特征实现按列的智能压缩算法选择。
- 探索数据内存压缩技术,增大内存的数据密度,同时利用延迟解压的技术方案,加速查询,实现性能和成本的兼得。
参考
- 400倍加速, PolarDB HTAP实时数据分析技术解密 阿里云社区
- Introduction to Data Compression. Guy E. Blelloch.
- Daniel J. Abadi, Samuel R. Madden, and Nabil Hachem. 2008. Column-stores vs. row-stores: how different are they really? In Proceedings of the 2008 ACM SIGMOD international conference on Management of data (SIGMOD ‘08). Association for Computing Machinery, New York, NY, USA, 967–980.
- Peter Boncz, Thomas Neumann, and Viktor Leis. 2020. FSST: fast random access string compression. Proc. VLDB Endow. 13, 12 (August 2020), 2649–2661.
- Daniel Abadi, Samuel Madden, and Miguel Ferreira. 2006. Integrating compression and execution in column-oriented database systems. In Proceedings of the 2006 ACM SIGMOD international conference on Management of data (SIGMOD ‘06). Association for Computing Machinery, New York, NY, USA, 671–682.