PolarDB MySQL · 引擎特性 · 内核原生的全局索引支持
Author: xige
前言(分区的价值和问题)
不管是Oracle等传统数据库,还是近年来涌现的分布式数据库,分区/分表作为重要的企业级数据库特性,被广泛应用在不同行业的业务场景中。简单来说,分区是将逻辑数据库(例如表、表空间)划分为不同的独立部分,分而治之,从而提高可管理性、整体性能或者负载均衡的效果。例如,Oracle等数据库通过分区,支持更灵活轻量的冷热数据分区管理,达到降本增效的能力。例如,分布式数据库通过分区,将数据均匀打散到多个节点上,获取更好的水平扩展能力。
MySQL作为最流行的开源关系型数据库,同样具备支持分区表的能力。相比于MySQL,PolarDB MySQL对分区表做了大量能力的增强(详情看:PolarDB分区表),例如 1. 细粒度的分区锁,避免增减分区时对其它分区的业务影响;2. 自动新增 / 删除 分区,并通过混合分区提供分区级别冷热数据管理的能力,达到降本增效的能力;3. 优化器层面针对分区表的大量优化。此外,PolarDB MySQL 多主架构(多主架构集群版 - 云原生关系型数据库 PolarDB MySQL引擎 - 阿里云)和多机并行(多机并行(MPP)发布说明 - 云原生关系型数据库 PolarDB MySQL引擎 - 阿里云)也基于多机分区的能力,支持读写能力的水平扩展。
然而,分区并不是一颗银弹。分区往往需要将表,按照某些列/字段的值来确定某行数据应该落在哪个分片。这些用来确定数据应该落在哪个分片的列,就是分区键。分区在达到上述优势的同时,同样受到分区键的限制,引入了一些棘手的问题:
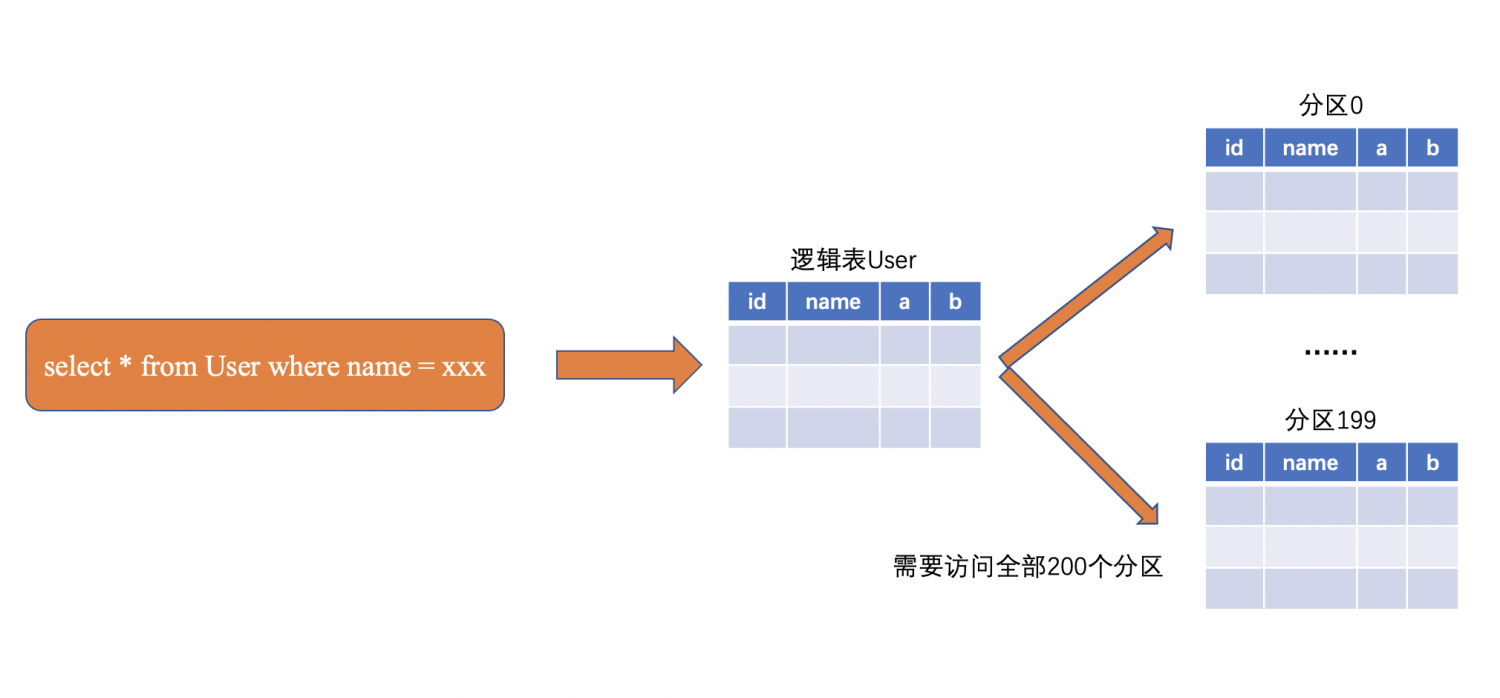
- 不包含分区键的查询,需要扫描所有分区,这将带来明显的<font color=#FF0000 >读放大问题</font>。如下图所示,当User表根据id被割成100/200个分区时,这时候如果查询非分区键name,就需要扫描所有的分区。显然,分区数越多,读放大越严重,尤其在分布式/多机场景中可能引入无法容忍的开销。不仅等值查询操作会受到影响,基于查询操作的范围查询 / 插入 / 删除 / 更新都可能遇到类似的问题。
为了减轻这方面的影响,用户需要仔细设计分区键,必须依赖包含分区键的索引来完成数据的定位,或者查询时指定特定的分区,对分区表的使用提出了很大的挑战。
- 在1的问题基础上,不包含非分区键的查询,即使基于本身有序的local index,也无法保证跨分区之间的全局有序,可能触发<font color=#FF0000 >额外的全局排序操作</font>;
- 唯一索引必须包含全部的分区键,否则无法保证所有分区的<font color=#FF0000 >Unique Constraint</font>,然而Unique Constraint是很多用户业务的刚性需求。
对于熟悉Oracle或者分布式数据库的读者,很快就能想到解决上述问题的究极武器,就是基于多分区的全局索引能力。然而,相比于传统的局部索引,全局索引显然更加复杂。但是众所周知,PolarDB是计算存储分离的架构,单表最大支持100TB,目前线上大表用户会越来越多。为了支持分区表或者多机场景下更强的分区/分表能力,PolarDB推出了MySQL内核原生的<font color=#FF0000 >全局二级索引</font>能力(Global Secondary Index,后文以GSI来简化说明)。
全局二级索引(Global Secondary Index,GSI)
GSI的原理
本章从全局二级索引的整体设计出发,来描述为何能解决前面所说的几个问题。
下图继续以User表为例,它按照主键id拆分(partition by Hash(ID))。首先,我们先解释为什么当等值查询字段是主键/分区键id时,不需要执行全分片检索。在MySQL中,索引是通过B+树来组织维护的,而主键id字段相当于在每个分区都维护了一个独立的B+树,确保主键id有序。因为id字段作为分区键,能够确保不同分区不会包含相同的id值,只需要根据输入的id值定位到具体的分片即可。简单来说,相当于维护了一个基于id字段的全局索引,保证分区内部id字段有序,分区之间id字段不重复。当提供的查询条件是id字段上的等值查询时,比如id = 16,它计算出16的分区哈希值后,就可以马上定位到p0分片。
 但是name字段并不是分区键,所以基于name字段的所有索引,只能保证分区内部name字段有序,无法保证分区之间的name关系。因此,如果根据name字段进行等值查询时,它需要做全分片检索,引入非常高的查询成本。
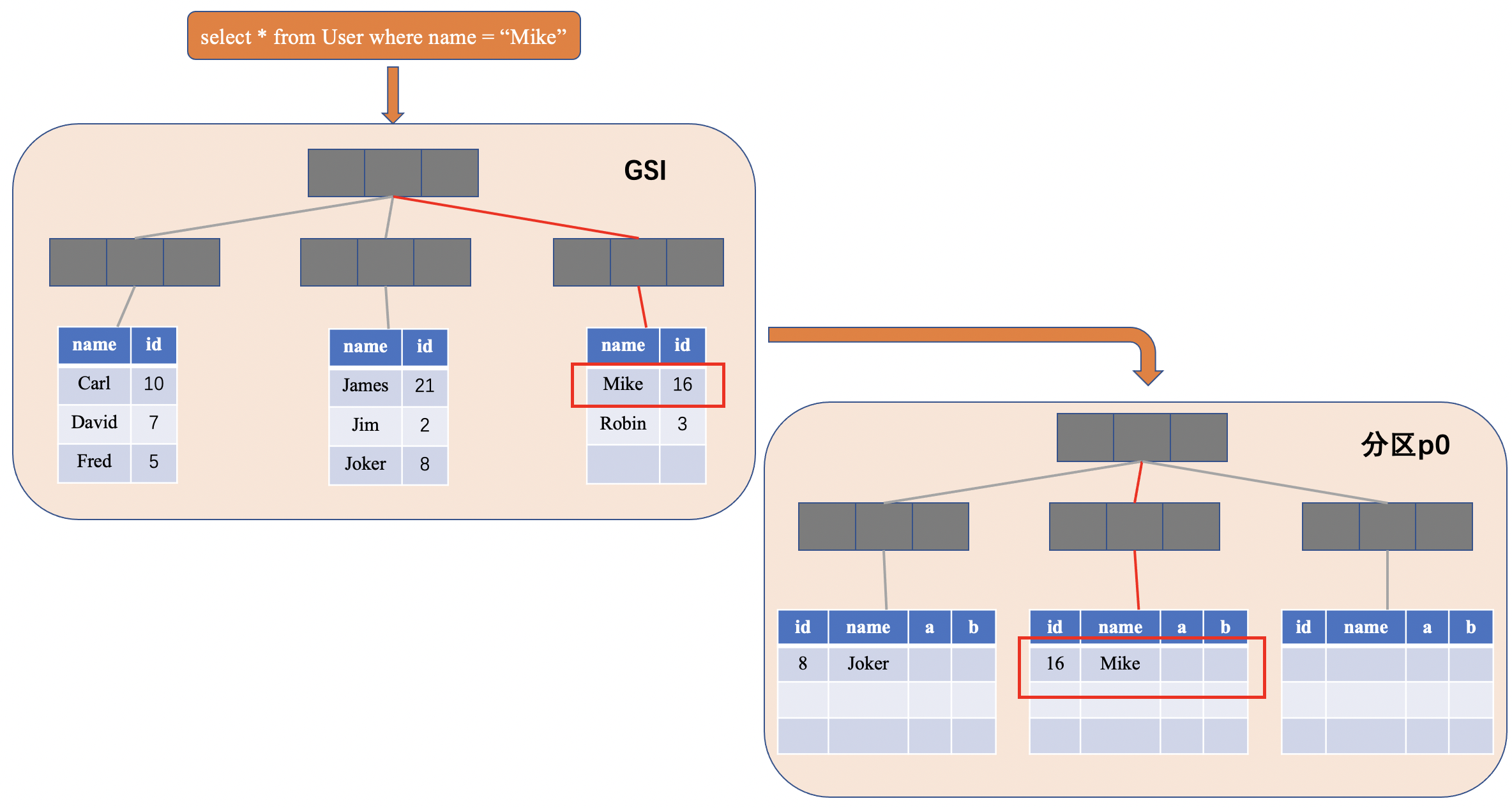
下面,我们看如果基于name字段构建全局二级索引(GSI),就能非常漂亮地解决这个问题。如下图所示,基于name字段的GSI,相当于创建了一颗完整的B+树,<font color=#FF0000 >保证name字段全局有序</font>,叶子结点记录了name以及对应的主键id。以下图的案例举例,根据name字段进行等值查询,数据库会自动根据以下步骤索引到正确的值;
但是name字段并不是分区键,所以基于name字段的所有索引,只能保证分区内部name字段有序,无法保证分区之间的name关系。因此,如果根据name字段进行等值查询时,它需要做全分片检索,引入非常高的查询成本。
下面,我们看如果基于name字段构建全局二级索引(GSI),就能非常漂亮地解决这个问题。如下图所示,基于name字段的GSI,相当于创建了一颗完整的B+树,<font color=#FF0000 >保证name字段全局有序</font>,叶子结点记录了name以及对应的主键id。以下图的案例举例,根据name字段进行等值查询,数据库会自动根据以下步骤索引到正确的值;
- 对于name字段上的等值查询,在GSI上进行二分查找,找到对应的<name, id>,即<Mike, 16>。
- 根据id=16和分区规则,自动路由到具体的分片p0;
- 在分片p0中,在id主键上根据id=16进行二分索引,找到正确的位置;
GSI的强大之处
通过前面的原理介绍,我们知道GSI保证了索引字段的全局有序,我们再看看之前提到的分区问题:
- 读放大问题得到彻底的解决,GSI提供了全局有序的检索能力;
- 额外的全局排序问题得到彻底的解决,基于GSI的索引扫描本身提供了全局有序;
- 唯一索引必须包含全部分区字段的问题,通过GSI的全局有序彻底解决; 马上发布的PolarDB 802新版本中,将搭载GSI能力,有效解决上述的三个问题,欢迎大表/分区表用户使用。在后续的研发中,PolarDB还将支持基于GSI的Parallel Query/DDL,基于GSI的多机并行处理,这将充分发挥出多机多核的处理能力,为用户提供更强的大表解决能力。
PolarDB GSI的实测效果
测试环境
数据量100w条,多个表结构、表数据相同但分区数量不同的分区表
表结构
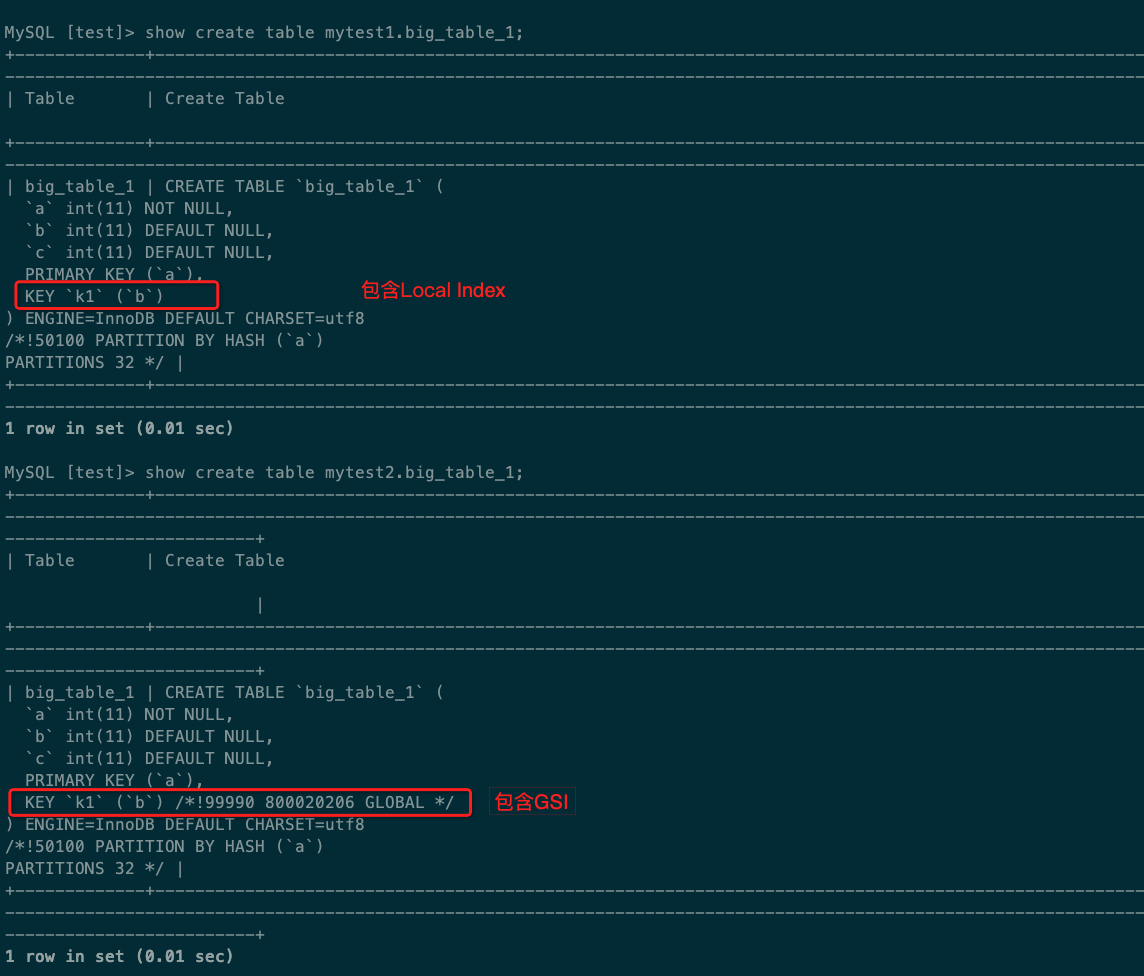
mytest1.big_table_1为包含local index的分区表
mytest2.big_table_1为包含GSI的分区表
测试结果
针对非分区键的条件DML,我们测试对比了使用local index和使用GSI在不同分区数量场景下的耗时对比。如下图所示,横轴为分区数量,纵轴为执行耗时,我们分别测试了select、update和delete场景,黑色线条是使用local index的耗时,红色线条是使用GSI的耗时。可以看到,随着分区数量的上涨,全局二级索引的优势愈发明显。

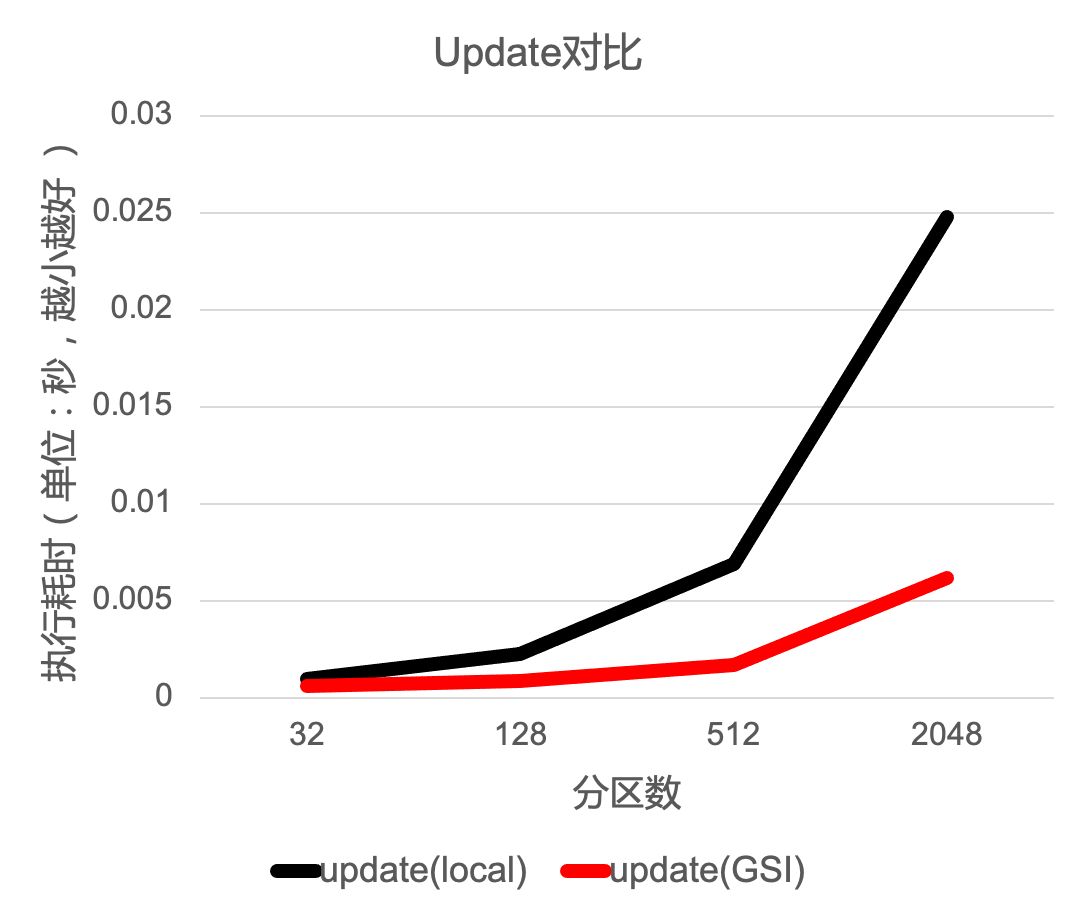
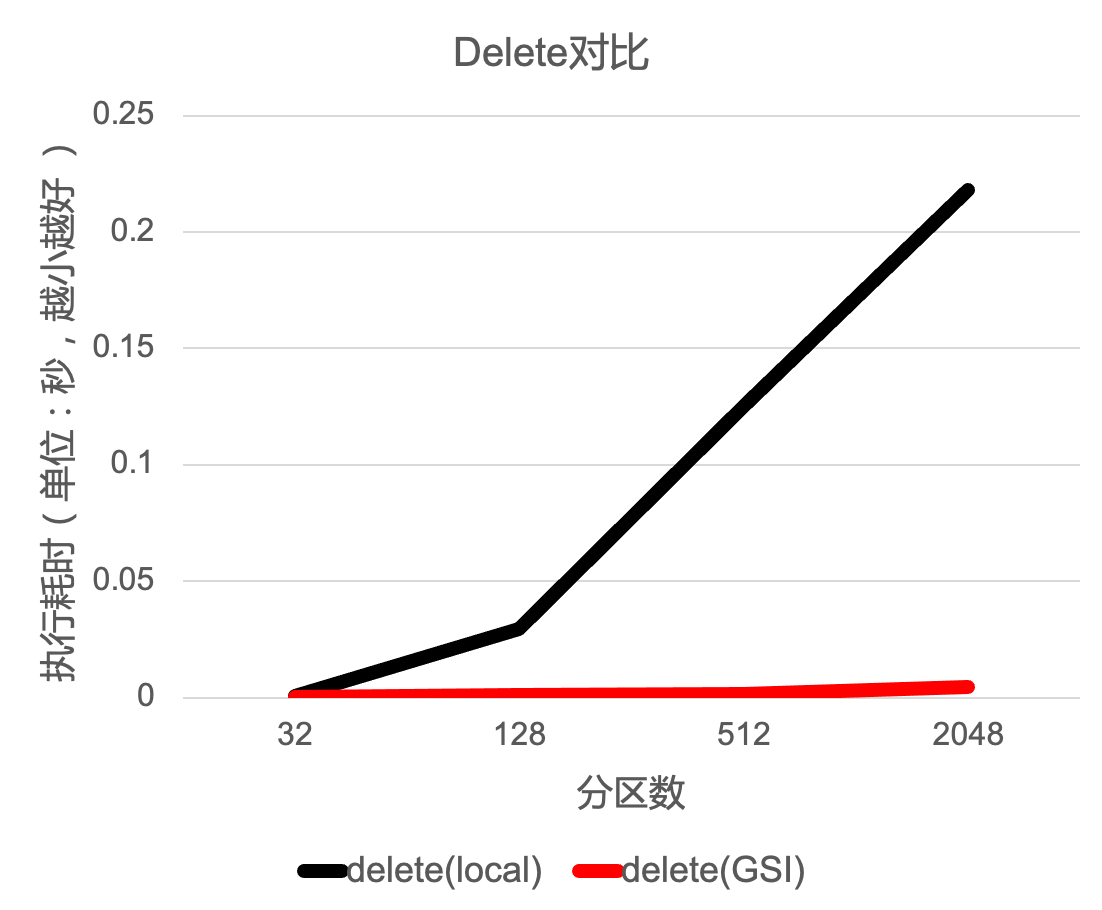
当查询的结果对索引字段有顺序要求的时候,使用local index和使用GSI的耗时对比,也可以看出GSI省去额外的全局排序之后带来性能提升。

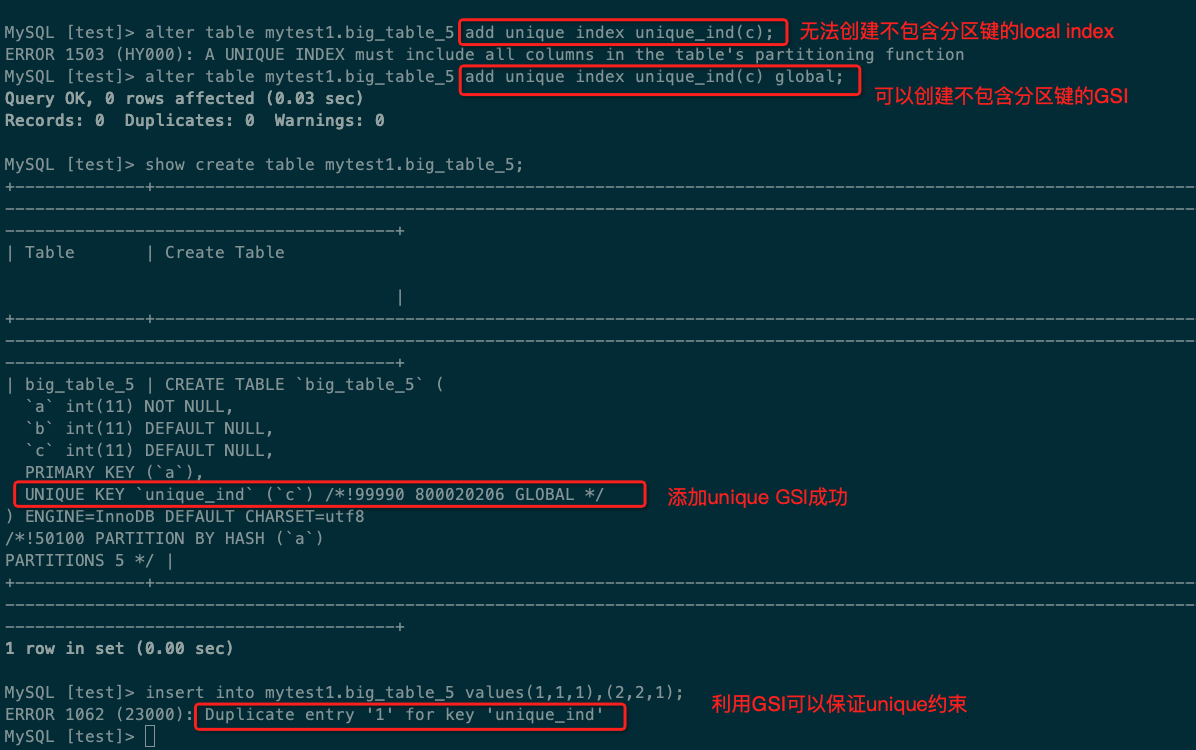
Unique Contraint支持
当试图在b字段上创建local unique index的时候会有报错提示,必须包含全部的分区键。而创建不包含分区键的GSI可以被允许。