PolarDB MySQL 大表实践-分区表篇
Author: 道客
#背景:分区表到底是什么?
分区作为传统企业级数据库的特性,早已经在很多大数据和数仓场景中得到广泛应用。基于维基百科的解释,分区是将逻辑数据库或其组成元素如表、表空间等划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性的原因,或者是为了负载平衡。它在分布式数据库管理系统中很流行,其中每个分区可能分布在多个节点上,节点上的用户在分区上执行本地事务。这提高了具有涉及某些数据视图的常规事务的站点的性能,同时保持可用性和安全性。分区包含Oracle有专门的技术专题文档系列《Database VLDB and Partitioning Guide》来介绍整个分区技术及分区场景,包括云原生数据库上基本都有至少10%的客户来使用分区技术来解决自己的业务上的大数据大表问题。
分区技术通常包含数据库分区(Database Partition)、分区表(Table Partition)和多维数据分区(MDC)技术。 数据库分区通常指的是多计算节点的场景,包括包含Share Storage的逻辑数据库分区和Share Nothing的物理数据库分区。
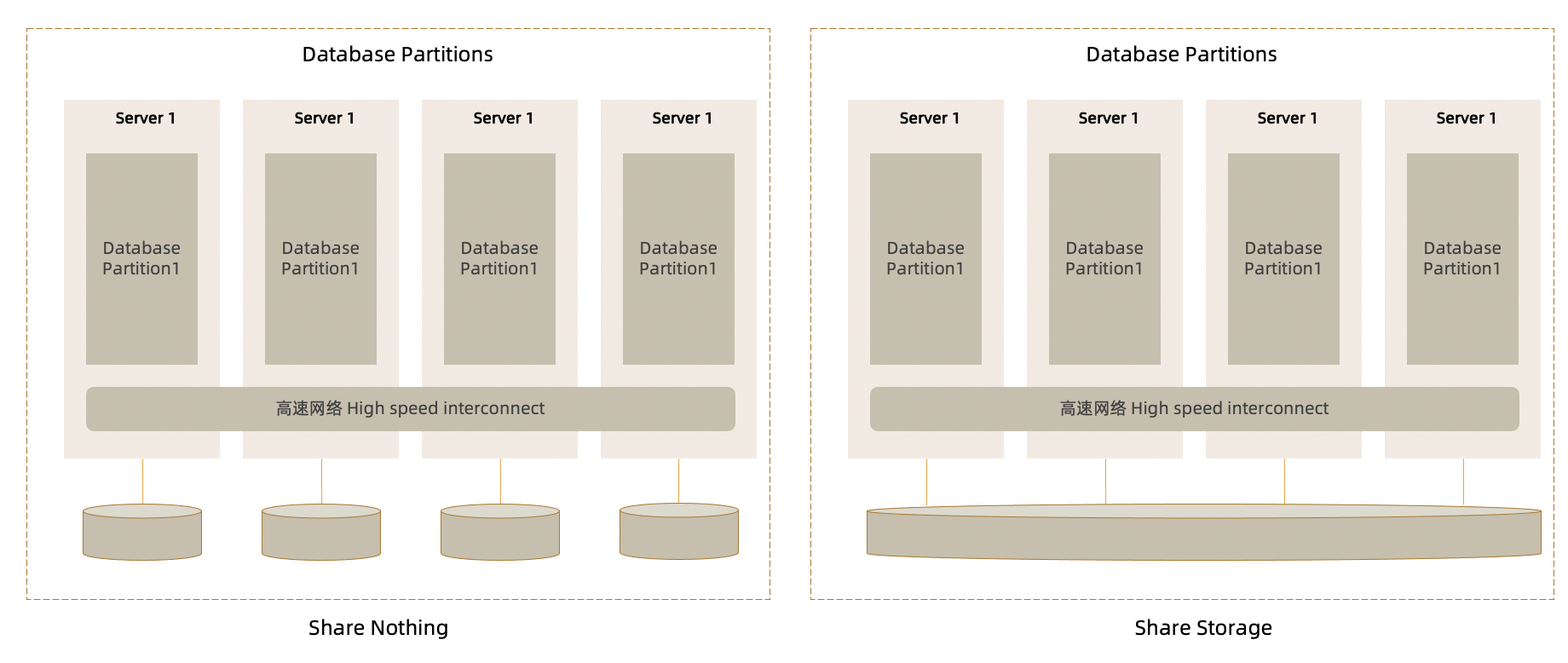
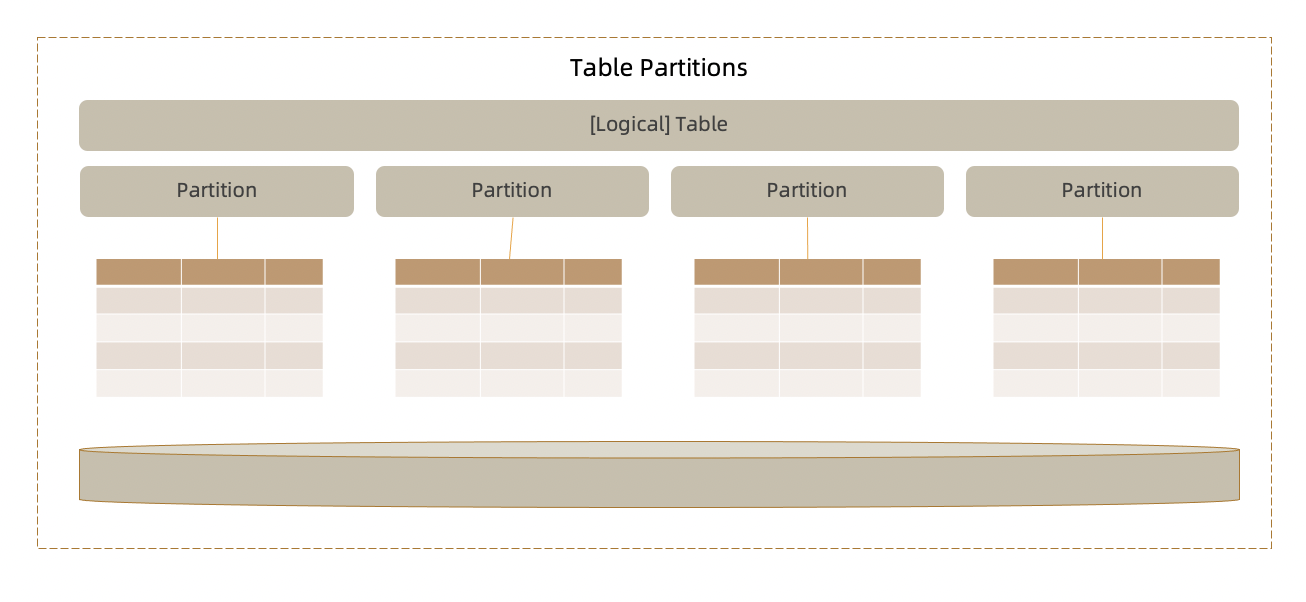
分区表功能提供了一种创建表的方法,将数据按照一定规则如Hash/Range/List或者组合的方式,拆分成不同的分区(数据块),对外提供逻辑表,而对用户的应用程序透明。
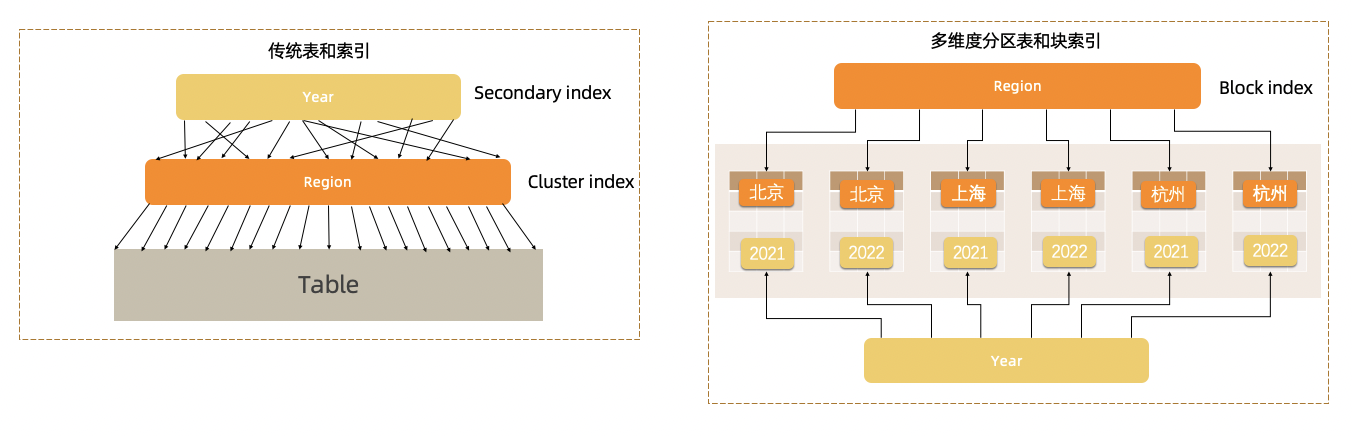
多维数据分区 (MDC) 是非常灵活、 沿多个维度对数据进行连续和自动聚类。 MDC是主要用于数据仓库和大型数据库环境,但其实也可以在 OLTP 环境中使用。 MDC 使表在物理上同时聚集在多个分区键(或维度)上。
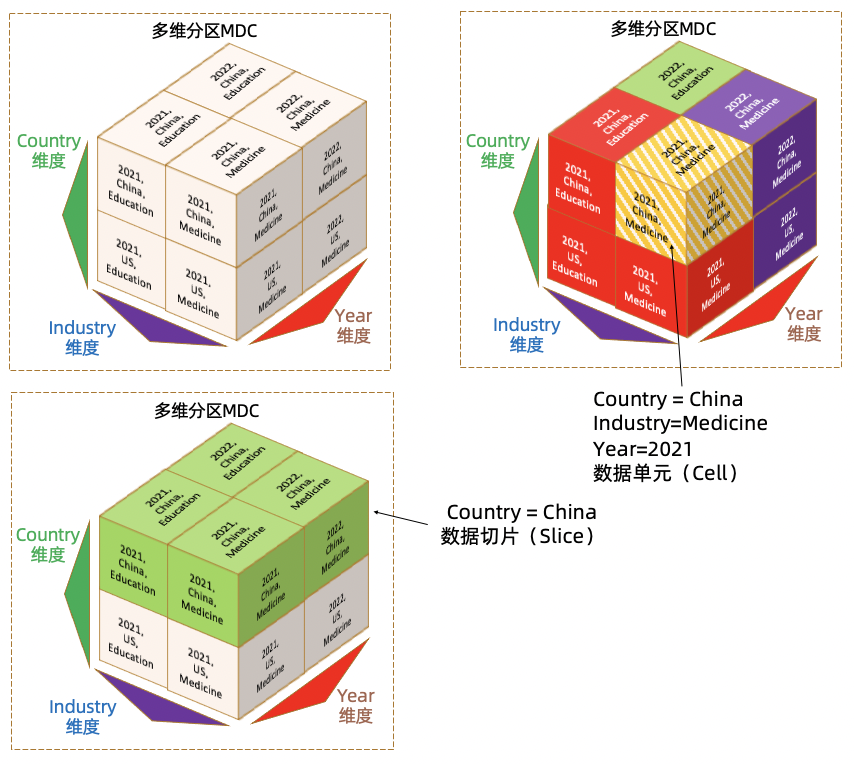
多维分区不止一个维度,通过Slice和Cell的概念来组织数据的存储。
MySQL分区为什么在云托管RDS时代被分库分表概念所代替?这个我们不得不回到用户场景中,由于MySQL是单机版本加上主备模式部署,除了其自身优化器执行器能力差和基于索引组织存储的限制外,还受到硬件资源的限制。虽然在云托管时代通过一写多读的系统部署架构来解决读写的吞吐,但由于MySQL的设计之初并没有想到有这么大规模的使用需要,即使它在8.0的最新版本中仍然努力的不断演进和重构,仍然无法满足用户场景的需要,这也让MySQL的分区表只是一个支持的功能,更没法说通过使用MySQL分区表来彻底解决大表的痛点,例如:
- 无法支持更多更丰富的分区类型组合,导致用户使用受限
- 无法支持分区锁,导致用户在运维分区(增加和删除分区等)的时候,影响了其他分区上的业务(数据增删改查)
- 无法支持并发处理能力,导致数据存储后无法进行大规模分析
- 优化器不支持分区相关的优化(只有静态pruning剪枝),导致执行计划和执行层不能很好的选择合适的计划,也没有能够选择的执行手段,从而带来性能问题
- 无法支持数据生命周期的管理,只能借助用户自己的脚本或者外部工具的配置
- 不支持多机访问,无法达到资源隔离的读写扩展能力
因此,由于当前的云原生数据库自身发展的不成熟,退而求其次的方案诞生了,那就是使用分库分表。虽然对用户不友好,但是架不住使用灵活方便,简单易用也是非常占优势的方式。另外,可以通过加强JDBC驱动或者Proxy的增强,如Sharding JDBC,TDDL等,也能够解决客户的问题。当然分库分表作为中间的历史产物,也终究在云原生的时代所淘汰,因为它也带来了很多问题:
- 不同异构软件的系统架构部署,交互无法做到高效,运维复杂
- 元数据信息等冗余存储
- SQL语句兼容性弱,解析等步骤重复执行
- 无法支持复杂查询,跨库查询性能极差
- 各个数据节点各自为政,很难做到高效交互,依赖于下层的适配改造
- 分布式事务问题
- 横向扩容的问题
- 结果集合并、排序的问题
当然,很多中间件希望努力解决上述的问题,将它改造成为非常强大的“数据库系统”,来解决上述问题,虽然是快捷的方式,但是无疑是忽略了已经沉淀的下层的数据库的计算。简单将数据库看做需要联邦的异构数据库,或者看成是存储下推计算的引擎,只会让整体系统更为复杂,兼容性变的更差,难以运维,本文由于单独介绍分区技术,这里就不再赘述。
#PolarDB MySQL大表解决方案 - 分区特性增强(PolarDB Partitioning Feature) 虽然MySQL可以支持原则上64T(16KB Page)的数据量,但是实际上由于数据存储的格式是b+tree,增删改造成的索引分裂和大数据量查询性能都急剧下降,常常让用户对大表后续的维护难以下手。分区表提供了解决支持非常大的表和索引的关键技术,方法是将它们分解为更小且更易于管理的部分,称为分区(Partition),这些部分对应用程序完全透明。无需修改 SQL 查询和数据操作语言 (DML) 语句即可访问分区表。在定义分区之后,数据定义语言 (DDL) 语句可以访问和操作单个分区,而不是整个表或索引。这就是分区如何简化大型数据库对象的可管理性。表或索引的每个分区可以具有单独的物理属性,例如启用或禁用压缩、物理存储设置和表空间,而不需要存储更多共用的元数据信息。
分区对于管理大量数据的用户应用有很大的帮助。OLTP 系统可以受益于可管理性和可用性的改进,而OLAP数据仓库系统可以受益于其性能改进和可管理性。
分区具有以下优点:
- 它支持在分区级别而不是在整个表上进行数据加载、索引创建和重建以及备份和恢复等数据管理操作。这导致这些操作的时间大大减少。
- 它提高了查询性能。通常可以通过访问分区的子集而不是整个表来获得查询的结果。对于某些查询,分区修剪技术可以提供数量级的性能提升,减少无效IO访问。
- 分区维护操作的分区独立性,允许用户对同一表或索引的一些分区执行维护操作,而同时保证无运维操作的分区运行并发和DML操作不受影响。查询以及 DML 和 DDL 支持并行执行。
- 如果将关键表和索引划分为分区以减少维护窗口,则可以提高关键应用的数据库的可用性。
- 无需重写应用就可以利用分区能力。
- 更容易的数据生命周期管理能力。
云原生PolarDB MySQL数据库一直在为解决大表问题而不懈努力,首先采用存计分离的整体架构,彻底移除了存储对单机的限制,为了应对后续的大表数据规模,针对索引访问和修改等进行大量的优化,包括页锁、行锁、空间回收、并行创建二级索引,并行查询等等。同时,PolarDB MySQL支持跨机事务写入、跨机查询、列存查询和数据分区都有重大的改进。
##PolarDB Partitioning功能增强 ###分区表类型增强 组合分区中的二级分区支持更多类型Range/List,满足客户不同场景如时间
| 复杂分区类型(分区+子分区) | MySQL | PolarDB MySQL |
|---|---|---|
| Range + Hash | Y | Y |
| List + Hash | Y | Y |
| Hash + Range | N | Y |
| Hash + List | N | Y |
| Range + Range | N | Y |
| Range + List | N | Y |
| List + Range | N | Y |
| List + List | N | Y |
| Hash + Hash | N | Y |
其中List Default [Hash] 分区重点解决客户长尾数据问题带来的数据隔离问题。
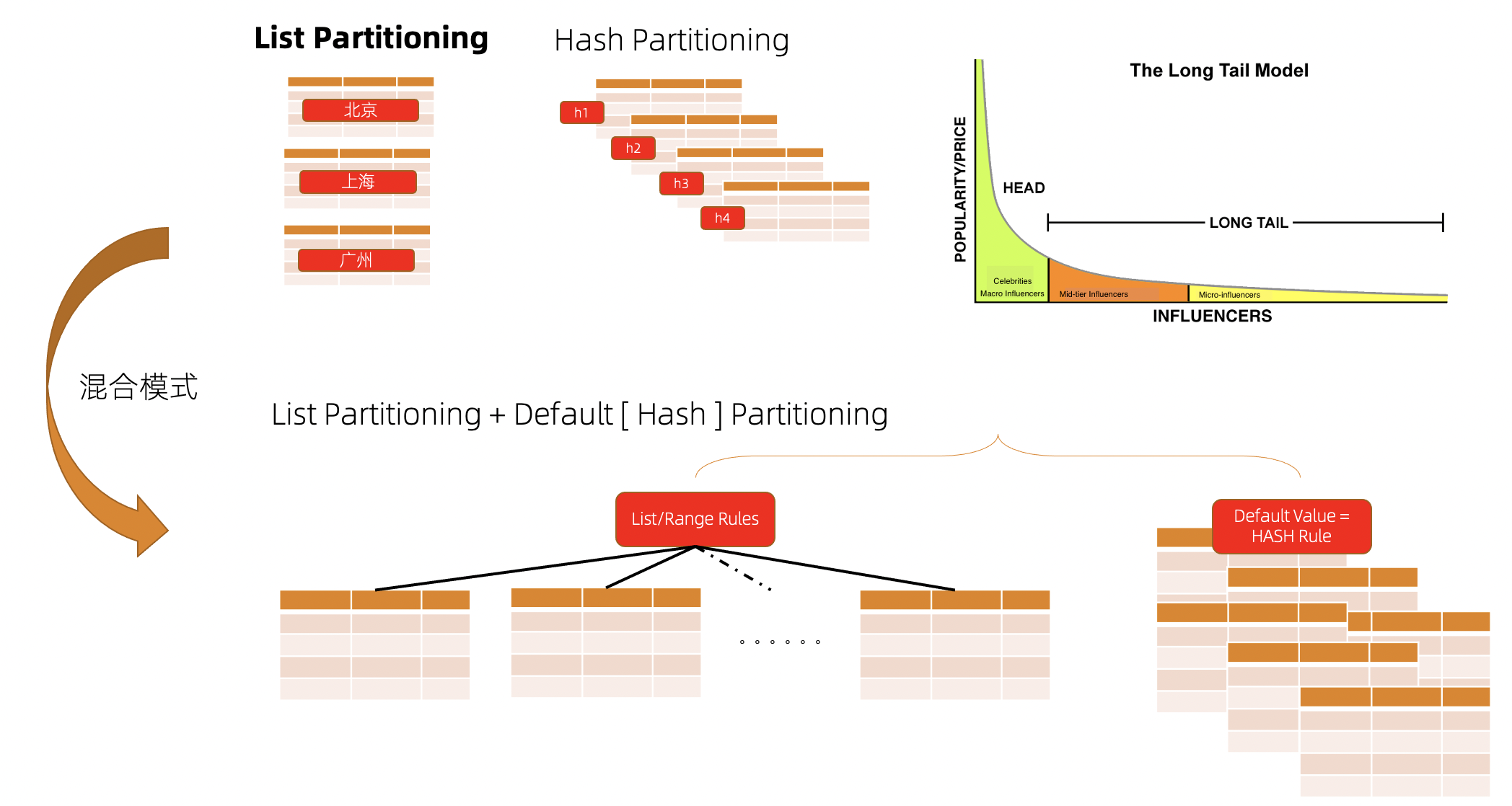
###Interval分区支持 MySQL对RANGE分区添加新的分区都需要DBA手动定期添加,或都使用事件来进行管理。 Interval Partition不再需要DBA去干预新分区的添加,PolarDB会在Insert新数据时自动去执行这样的操作,减少了DBA的工作量。Interval Partition是Range分区的一个扩展。

举例说明:
CREATE TABLE t1 (order_date DATE, ...) PARTITON BY RANGE (order_date)
INTERVAL 1 MONTH (PARTITION p_first VALUES LESS THAN ( '2021-01-01');
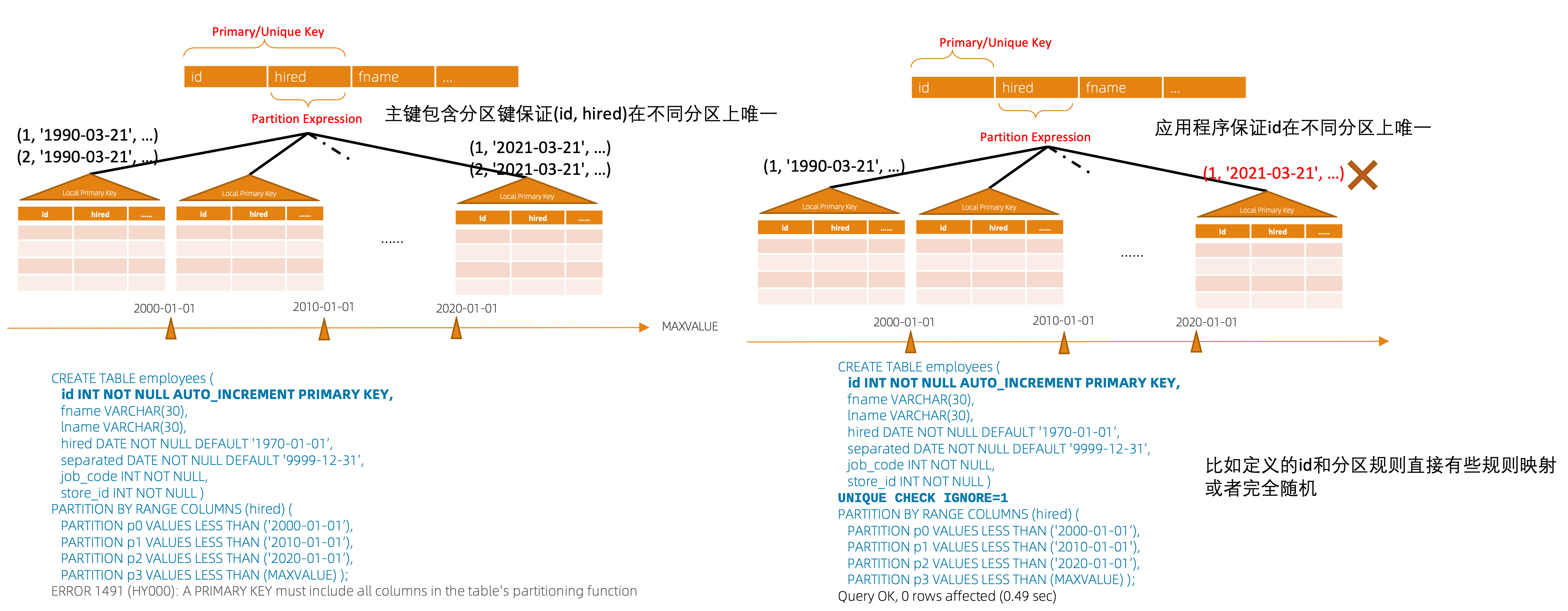
###分区键和主键解耦(UNIQUE CHECK IGNORE)
MySQL要求主键、唯一键必须包含分区键,增加选项忽略该检查,可以更好的解耦唯一约束和分区的矛盾,客户应用程序来保证唯一性,这样可以带来性能提升5-7%。互联网好多用户的应用主键和分区键中的维度并无关系,大部分用于避免delete、update带来的全表扫描的问题,有部分用户直接采用全局UUID作为主键,还有部分用户的分区键和主键有一定的函数映射关系,因此不需要强制该限制。
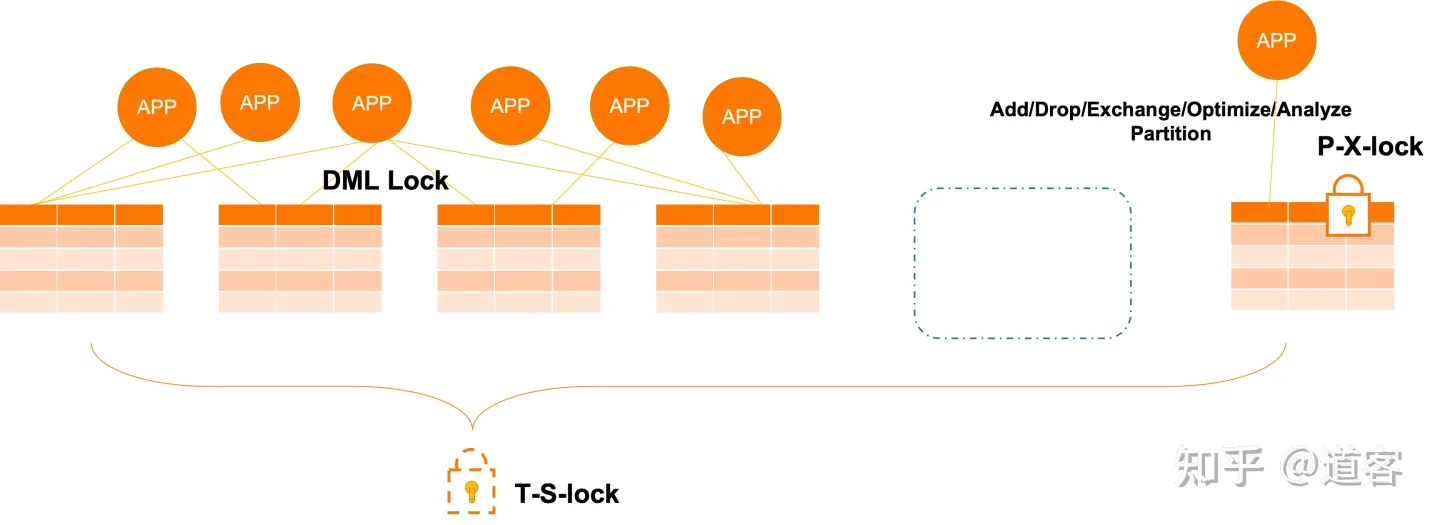
###分区锁支持
分区锁是PolarDB对于分区的重要增强,真正将锁直接从表粒度降低为分区粒度,增强分区了分区的DML和DDL(目前支持DROP/EXCHANGE/REBUILD/REORGANIZE PARTITION操作、RANGE和LIST分区方式的ADD PARTITION操作的在线分区维护功能,其他DDL操作将在后续版本支持)的并行能力,更好的让用户对分区表进行Roll-In和Roll-Out。
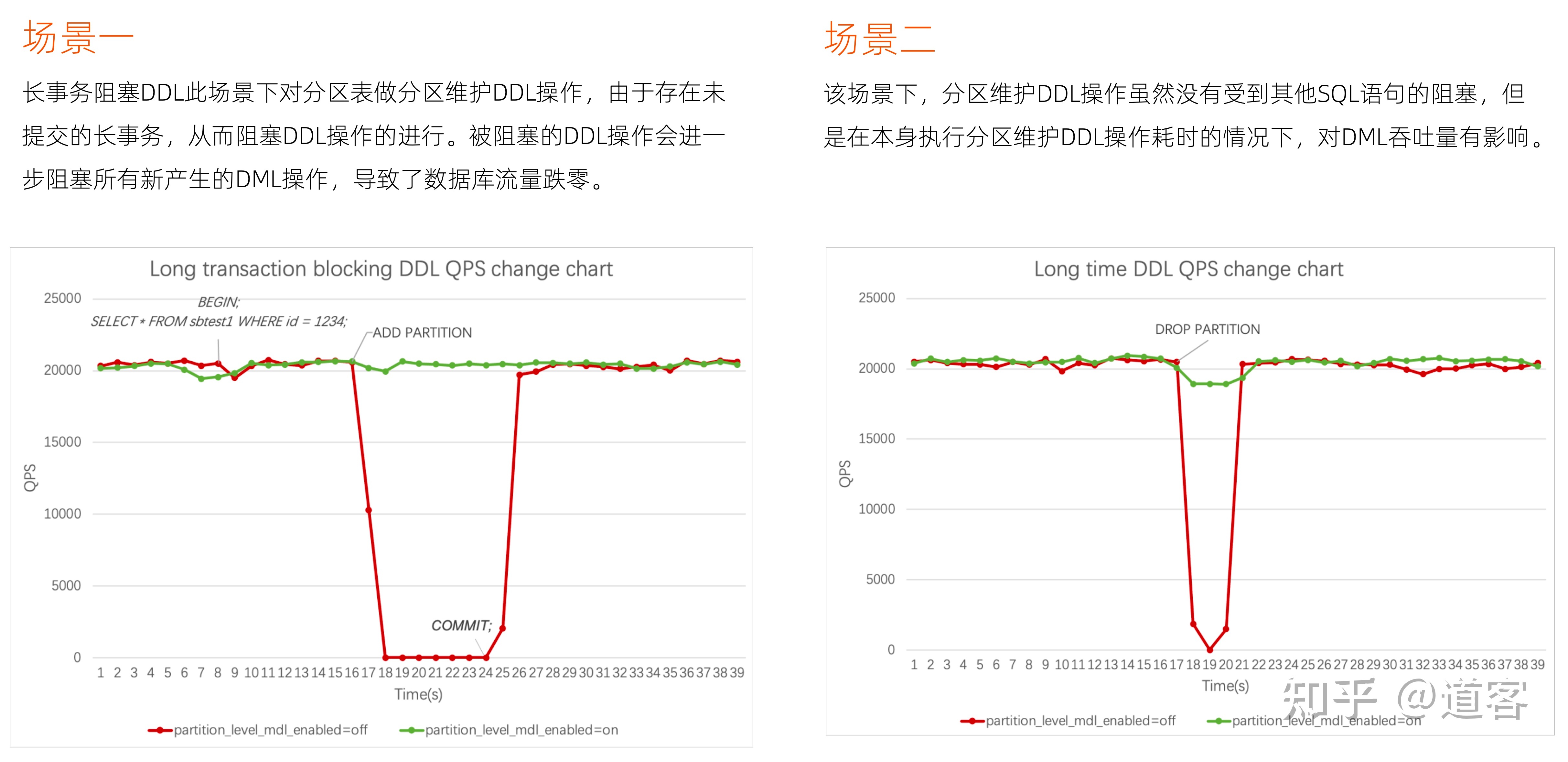
 带来的性能显而易见,还支持EXCHANGE等DDL。有人可能好奇DDL已经是online DDL了,为什么还需要分区锁,一个简单的rename操作就会带来无限的灾难,因为DDL和DML始终是有并发的影响,即使窗口非常小,下面是分区锁带来的性能优化场景。
带来的性能显而易见,还支持EXCHANGE等DDL。有人可能好奇DDL已经是online DDL了,为什么还需要分区锁,一个简单的rename操作就会带来无限的灾难,因为DDL和DML始终是有并发的影响,即使窗口非常小,下面是分区锁带来的性能优化场景。
###分区统计信息增强
分区统计信息是采用成熟的hyperloglog技术,来解决动态分区产生的统计信息不准确问题,尤其是计算索引上每一个唯一键值的平均个数,对于多表连接有重大的性能改进。

##PolarDB Partitioning场景 ###分区管理 ####何时选择RANGE分区 RANGE分区是对历史数据进行分区的一种方便的方法。RANGE分区用边界定义了表或索引中分区的范围和分区间的顺序。 RANGE分区通常用于在DATE类型的列上按时间间隔组织数据。因此,大多数访问RANGE分区的SQL语句都关注时间范围。这方面的一个例子是类似于“从特定时间段选择数据”的SQL语句。在这样的场景中,如果每个分区代表一个月的数据,那么查询“查找21-12的数据”必须只访问2021年的12月份的分区。这将扫描的数据量减少到可用数据总量的一小部分,这种优化方法称为分区修剪(Partition Purning)。 对于定期加载新数据和清除旧数据的场景,RANGE分区也是理想的分区方式。例如,通常会保留一个滚动的数据窗口,将过去36个月的数据保持在线。RANGE分区简化了这个过程。要添加新月份的数据,需要将其加载到一个单独的表中,对其进行清理、建立索引,然后使用EXCHANGE PARTITION语句将其添加到RANGE分区表中,同时原始表保持在线状态。添加新分区后,可以使用DROP PARTITION语句删除最后一个月。 以下情况下可以考虑使用RANGE分区:
- 经常在某些列上的按照范围扫描非常大的表(例如订单表ORDER或购买明细表LINEITEM)。在这些列上对表进行分区可以实现分区剪枝。
- 希望维护数据的滚动窗口。
- 不能在指定的时间内完成大型表的管理操作,例如备份和恢复,但是可以根据分区范围列将它们划分为更小的逻辑块。
示例:创建为期9年+的表orders,并根据列o_orderdate按范围对其进行分区,将数据分成8个年度,每个年度对应一个分区。通过短时间间隔分析销售数据可以利用分区修剪。销售表也支持滚动窗口方法。
CREATE TABLE `orders` (
`o_orderkey` int(11) NOT NULL,
`o_custkey` int(11) NOT NULL,
`o_orderstatus` char(1) DEFAULT NULL,
`o_totalprice` decimal(10,2) DEFAULT NULL,
`o_orderDATE` date NOT NULL,
`o_orderpriority` char(15) DEFAULT NULL,
`o_clerk` char(15) DEFAULT NULL,
`o_shippriority` int(11) DEFAULT NULL,
`o_comment` varchar(79) DEFAULT NULL,
PRIMARY KEY (`o_orderkey`,`o_orderDATE`,`o_custkey`),
KEY `o_orderkey` (`o_orderkey`),
KEY `i_o_custkey` (`o_custkey`),
KEY `i_o_orderdate` (`o_orderDATE`)
) ENGINE=InnoDB
PARTITION BY RANGE (TO_DAYS(o_orderdate))
(PARTITION item1 VALUES LESS THAN (TO_DAYS('1992-01-01')),
PARTITION item2 VALUES LESS THAN (TO_DAYS('1993-01-01')),
PARTITION item3 VALUES LESS THAN (TO_DAYS('1994-01-01')),
PARTITION item4 VALUES LESS THAN (TO_DAYS('1995-01-01')),
PARTITION item5 VALUES LESS THAN (TO_DAYS('1996-01-01')),
PARTITION item6 VALUES LESS THAN (TO_DAYS('1997-01-01')),
PARTITION item7 VALUES LESS THAN (TO_DAYS('1998-01-01')),
PARTITION item8 VALUES LESS THAN (TO_DAYS('1999-01-01')),
PARTITION item9 VALUES LESS THAN (MAXVALUE));
EXPLAIn select * from orders where o_orderDATE = '1992-03-01';
+----+-------------+--------+------------+------+---------------+---------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | orders | item2 | ref | i_o_orderdate | i_o_orderdate | 3 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------------+---------+-------+------+----------+-------+
由于RANGE本身的限制,使用TO_DAYS分区后,再执行SHOW CREATE TABLE后可能看不到原来的DDL。示例如下:
show create table orders;
| orders | CREATE TABLE `orders` (
`o_orderkey` int(11) NOT NULL,
`o_custkey` int(11) NOT NULL,
`o_orderstatus` char(1) DEFAULT NULL,
`o_totalprice` decimal(10,2) DEFAULT NULL,
`o_orderDATE` date NOT NULL,
`o_orderpriority` char(15) DEFAULT NULL,
`o_clerk` char(15) DEFAULT NULL,
`o_shippriority` int(11) DEFAULT NULL,
`o_comment` varchar(79) DEFAULT NULL,
PRIMARY KEY (`o_orderkey`,`o_orderDATE`,`o_custkey`),
KEY `o_orderkey` (`o_orderkey`),
KEY `i_o_custkey` (`o_custkey`),
KEY `i_o_orderdate` (`o_orderDATE`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
/*!50100 PARTITION BY RANGE (to_days(`o_orderDATE`))
(PARTITION item1 VALUES LESS THAN (727563),
PARTITION item2 VALUES LESS THAN (727929),
PARTITION item3 VALUES LESS THAN (728294),
PARTITION item4 VALUES LESS THAN (728659),
PARTITION item5 VALUES LESS THAN (729024),
PARTITION item6 VALUES LESS THAN (729390),
PARTITION item7 VALUES LESS THAN (729755),
PARTITION item8 VALUES LESS THAN (730120),
PARTITION item9 VALUES LESS THAN MAXVALUE) */ |
RANGE COLUMNS分区是RANGE分区的扩展,是基于多个列值使用范围定义分区,可以使用非整数类型的列作为分区列。 RANGE COLUMNS分区与RANGE分区的区别如下:
- RANGE COLUMNS不接受表达式,只接受列的名称;
- RANGE COLUMNS接受一个或多个列的列表。RANGE COLUMNS分区基于元组(列值列表)之间的比较,而不是标量值之间的比较。RANGE COLUMNS分区中的行位置也基于元组之间的比较;
- RANGE COLUMNS分区列不限于整数列;字符串类型、DATE和DATETIME列也可以用作分区列。
创建RANGE COLUMNS分区的示例如下:
CREATE TABLE `orders` (
`o_orderkey` int(11) NOT NULL,
`o_custkey` int(11) NOT NULL,
`o_orderstatus` char(1) DEFAULT NULL,
`o_totalprice` decimal(10,2) DEFAULT NULL,
`o_orderDATE` date NOT NULL,
`o_orderpriority` char(15) DEFAULT NULL,
`o_clerk` char(15) DEFAULT NULL,
`o_shippriority` int(11) DEFAULT NULL,
`o_comment` varchar(79) DEFAULT NULL,
PRIMARY KEY (`o_orderkey`,`o_orderDATE`,`o_custkey`),
KEY `o_orderkey` (`o_orderkey`),
KEY `i_o_custkey` (`o_custkey`),
KEY `i_o_orderdate` (`o_orderDATE`)
) ENGINE=InnoDB
PARTITION BY RANGE COLUMNS(o_orderdate)
(PARTITION item1 VALUES LESS THAN ('1992-01-01'),
PARTITION item2 VALUES LESS THAN ('1993-01-01'),
PARTITION item3 VALUES LESS THAN ('1994-01-01'),
PARTITION item4 VALUES LESS THAN ('1995-01-01'),
PARTITION item5 VALUES LESS THAN ('1996-01-01'),
PARTITION item6 VALUES LESS THAN ('1997-01-01'),
PARTITION item7 VALUES LESS THAN ('1998-01-01'),
PARTITION item8 VALUES LESS THAN ('1999-01-01'),
PARTITION item9 VALUES LESS THAN (MAXVALUE));
####何时选择HASH分区 对于分布规则不明显的数据,并没有明显的范围查找等特征,可以使用HASH分区,将数据分区列的值按照HASH算法打散到不同的分区上,将数据随机分布到各个分区。 使用HASH分区的目的如下:
- 使分区间数据分布均匀,分区间可以并行访问;
- 根据分区键使用分区修剪,基于分区键的等值查询开销减小;
- 随机分布数据,以避免I/O瓶颈。
- 分区键的选择一般要满足以下要求:
- 选择唯一或几乎唯一的列或列的组合;
- 为每个2的幂次分区创建多个分区和子分区。例如:2、4、8、16、32、64、128等。
示例:使用列c_custkey作为分区键为表customer创建4个HASH分区。
CREATE TABLE `customer` (
`c_custkey` int(11) NOT NULL,
`c_name` varchar(25) DEFAULT NULL,
`c_address` varchar(40) DEFAULT NULL,
`c_nationkey` int(11) DEFAULT NULL,
`c_phone` char(15) DEFAULT NULL,
`c_acctbal` decimal(10,2) DEFAULT NULL,
`c_mktsegment` char(10) DEFAULT NULL,
`c_comment` varchar(117) DEFAULT NULL,
PRIMARY KEY (`c_custkey`),
KEY `i_c_nationkey` (`c_nationkey`)
) ENGINE=InnoDB
PARTITION BY HASH(c_custkey)
( PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4
);
指定HASH分区的数量将自动生成各个分区的内部名称。示例如下:
CREATE TABLE `customer` (
`c_custkey` int(11) NOT NULL,
`c_name` varchar(25) DEFAULT NULL,
`c_address` varchar(40) DEFAULT NULL,
`c_nationkey` int(11) DEFAULT NULL,
`c_phone` char(15) DEFAULT NULL,
`c_acctbal` decimal(10,2) DEFAULT NULL,
`c_mktsegment` char(10) DEFAULT NULL,
`c_comment` varchar(117) DEFAULT NULL,
PRIMARY KEY (`c_custkey`),
KEY `i_c_nationkey` (`c_nationkey`)
) ENGINE=InnoDB
PARTITION BY HASH (`c_custkey`)
PARTITIONS 64;
同样针对于列的HASH分区方法KEY COLUMNS,也是可以使用非整数类型的列作为分区列,这里就不再赘述。
####何时选择LIST分区
LIST分区根据数据的枚举值进行分区。 以下示例为北京、天津、内蒙、河北的所有客户存储在一个分区中,其他省市的客户存储在不同的分区中。按区域分析帐户的管理人员可以利用分区剪枝。
| 区域 | 编号 |
|---|---|
| 华北(p_cn_north) | 1:BJ,2:TJ,3:HB,4:NM |
| 华南(p_cn_south) | 5:GD, 6:GX, 7:HN |
| 华东(p_cn_east) | 8:SH, 9:ZJ, 10:JS |
创建具有LIST分区的表:
CREATE TABLE `accounts` (
`id` int(11) DEFAULT NULL,
`account_number` int(11) DEFAULT NULL,
`customer_id` int(11) DEFAULT NULL,
`branch_id` int(11) DEFAULT NULL,
`region_id` int(11) DEFAULT NULL,
`region` varchar(2) DEFAULT NULL,
`status` varchar(1) DEFAULT NULL
) ENGINE=InnoDB
PARTITION BY LIST (`region_id`)
(PARTITION p_cn_north VALUES IN (1,2,3,4),
PARTITION p_cn_south VALUES IN (5,6,7),
PARTITION p_cn_east VALUES IN (8,9,10),
);
LIST COLUMNS分区是LIST分区的扩展,它允许使用多个列作为分区键,并允许使用非整数类型的数据类型列作为分区列,您可以使用字符串类型、DATE和DATETIME列。与使用RANGE COLUMNS进行分区一样,不需要在COLUMNS()子句中使用表达式将列值转换为整数。事实上,在COLUMNS()中不允许使用列名以外的表达式。 创建具有LIST COLUMNS分区的表:
DROP TABLE IF EXISTS accounts;
CREATE TABLE accounts
( id INT,
account_number INT,
customer_id INT,
branch_id INT,
region_id INT,
region VARCHAR(2),
status VARCHAR(1)
)
PARTITION BY LIST COLUMNS(region)
PARTITION BY LIST (`region_id`)
(PARTITION p_cn_north VALUES IN ('BJ','TJ','HB','NMG'),
PARTITION p_cn_south VALUES IN ('GD','GX','HN'),
PARTITION p_cn_east VALUES IN ('SH','ZJ','JS'),
);
####何时选择LIST DEFAULT HASH分区 如果您想用LIST规则进行分区,但是分区键字段无法全部枚举,或者枚举值非常多,而对应的数据量很少。数据分布符合二八原则,20%的分区键值包含了80%的数据量,剩余80%的分区键值包含了20%的数据量。在这种场景下,您就可以选择LIST DEFAULT HASH分区类型,80%的数据按照LIST规则进行分区,不符合LIST规则的数据放到默认的DEFAULT分区里,按照HASH规则进行分区。 例如,对于多租户的业务系统,每个租户产生的用户数据量不均衡,您可以把大数据量的租户按照LIST规则分区,然后中小数据量的租户按照HASH规则分成多个分区,如下:
| 租户ID | 数据量 | 分区 |
|---|---|---|
| 大客户1 | 3000万 | p1 |
| 大客户2 | 2600万 | p2 |
| 大客户3 | 2400万 | p3 |
| 大客户4 | 2000万 | p4 |
| 中小客户群 | 3000万 | p_others |
CREATE TABLE cust_orders
(
customer_id VARCHAR(36),
year VARCHAR(60),
order_id INT,
order_content text
) PARTITION BY LIST COLUMNS(customer_id)
(
PARTITION p1 VALUES IN ('大客户1'),
PARTITION p2 VALUES IN ('大客户2'),
PARTITION p3 VALUES IN ('大客户3'),
PARTITION p4 VALUES IN ('大客户4'),
PARTITION p_others DEFAULT PARTITIONS '中小客户群'
);
同样LIST DEFAULT模式也支持COLUMNS,举例说明
CREATE TABLE t1 (a INT, b CHAR(5) )
PARTITION BY LIST COLUMNS(a, b)
(PARTITION p0 VALUES IN ((1,'AB'),(2,'AC'),(3,'AE'),(4,'AF'),(5,'AR')),
PARTITION p1 VALUES IN ((6,'NC'),(7,'ND'),(8,'NA'),(9,'NU'),(10,'NE')),
PARTITION p_default DEFAULT PARTITIONS 4
);
explain select * from t1;
+----+-------------+-------+---------------------------------------------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+---------------------------------------------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t1 | p0,p1,p_default0,p_default1,p_default2,p_default3 | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
+----+-------------+-------+---------------------------------------------------+------+---------------+------+---------+------+------+----------+-------+
####何时选择间隔(Interval)分区 Interval Range分区是Range分区的扩展,在数据到达时自动创建间隔分区,不需要再手动创建新分区,方便了Range分区维护操作。 向RANGE分区表插入数据时,如果插入的数据超出当前已存在分区的范围,将无法插入并且会返回错误;而对于INTERVAL RANGE分区表,当新插入的数据超过现有分区的范围时,允许数据库自动创建新分区,根据INTERVAL子句指定的范围来新增分区。 如果分区范围设置为1个月,新插入的数据为当前转换点(当前存在的分区的最大边界值)两个月后的数据,将会创建该数据所在月份的分区,以及中间月份的分区。例如,您可以创建一个INTERVAL RANGE分区表,该表分区范围为1个月且当前的转换点为2021年9月15日。如果您尝试为2021年12月10日插入数据,那么将创建2021年9月15日至12月15日所需的3个分区,并将数据插入该分区。 下列情况下建议您使用间隔分区:
- 数据按时间维度维护。
- 维护滚动的数据窗口。
- 不希望手动运维增加新的分区。
以下示例将orde_time作为分区键,按间隔划分sales表。创建Interval Range分区表需要一个初始的转换点,然后才能在转换点之外自动创建新的分区。
在数据库中创建一个新的Interval Range分区表,并向表中插入数据,示例如下:
CREATE TABLE sales ( id BIGINT, uid BIGINT, order_time DATETIME ) PARTITION BY RANGE COLUMNS(order_time) INTERVAL(MONTH, 1) ( PARTITION p0 VALUES LESS THAN('2021-9-1') );在Interval Range分区表中插入数据,示例如下:
INSERT INTO sales VALUES(1, 1010101010, '2021-11-11');插入数据后,通过SHOW CREATE TABLE查询sales表定义。新的表定义如下:
CREATE TABLE `sales` ( `id` int(11) DEFAULT NULL, `uid` int(11) DEFAULT NULL, `order_time` datetime DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE COLUMNS(order_time) INTERVAL(MONTH, 1) (PARTITION p0 VALUES LESS THAN ('2021-9-1'), PARTITION _p20211001000000 VALUES LESS THAN ('2021-10-01 00:00:00'), PARTITION _p20211101000000 VALUES LESS THAN ('2021-11-01 00:00:00'), PARTITION _p20211201000000 VALUES LESS THAN ('2021-12-01 00:00:00'))Interval Range分区自动新增加了_p20211001000000、_p20211101000000和_p20211201000000三个分区。
说明 _p作为前缀的分区名将会保留为系统命名规则,手动管理分区(创建新分区或者重命名分区的操作)时,将不允许使用此类型的分区名。例如,ADD PARTITION和REORGANIZE PARTITION操作将不允许使用‘_p’作为前缀的分区名;但是DROP PARTITION操作可以使用‘_p’作为前缀的分区名。
在这样的业务场景下,此前通常需要DBA在插入值触及转换点之前手动增加分区,但操作不当就有可能导致新的数据插入失败。通过创建Interval Range分区表,可以由系统自动增加分区,避免数据不能及时插入的问题。
由于分区数量最多只能达到8192,自动增加分区的数量也会受限制,可以配合分区表的生命周期管理解决方案使用,定期增加分区,同时定期将冷数据所在的分区自动迁移到OSS上。
####何时选择虚拟列分区 虚拟列分区可以对表达式进行分区,该表达式可能使用来自其他列的数据,并使用这些列进行计算。
虚拟列分区支持所有分区类型。如果查询条件不是某一个列上的原始数据,而是经过计算过的,又不想添加一个单独的列来存储计算过的正确值,可以考虑添加一个虚拟列。
在以下示例的sales表中,客户的确认号包含两个字符的省市名称,作为取车的地点,租车分析通常评估地区模式,因此可以按照省市划分:
CREATE TABLE `sales` (
`id` int(11) NOT NULL,
`customer_id` int(11) NOT NULL,
`confirmation_number` varchar(12) NOT NULL,
`order_id` int(11) DEFAULT NULL,
`order_type` varchar(10) DEFAULT NULL,
`start_date` date NOT NULL,
`end_date` date DEFAULT NULL,
`province` varchar(12) GENERATED ALWAYS AS (substr(`confirmation_number`,9,2)) VIRTUAL
) ENGINE=InnoDB
PARTITION BY LIST COLUMNS(province)
SUBPARTITION BY HASH (`customer_id`)
SUBPARTITIONS 16
(PARTITION p_cn_north VALUES IN ('BJ','TJ','HB','NMG'),
PARTITION p_cn_south VALUES IN ('GD','GX','HN'),
PARTITION p_cn_east VALUES IN ('SH','ZJ','JS'),
......);
####何时选择二级分区 组合分区提供了二维分区的优点。从性能的角度来看,您可以根据SQL语句在一个或两个维度上利用分区修剪。
二级分区允许将表、索引和索引组织的表细分为更小的块,从而能够以更细的粒度级别管理和访问这些数据库对象。例如可以为分区实现一个滚动窗口来支持历史数据分区,同时在另一个维度上进行二级分区。
数据库将二级分区表中的每个子分区存储为一个单独的物理表。因此,子分区的属性是独立的,可以与表的属性或子分区所属的一级分区不同,使用中更加灵活。
####何时使用Range-Hash分区 Range-Hash分区是指一级分区是Range分区,二级分区是Hash分区的组合分区类型。
Range-Hash分区对于存储历史数据的大表很常见,并且经常与其他大表连接。对于这些类型的表(典型的数据仓库系统),组合Range-Hash分区提供了在Range级别进行分区修剪的优势,并有机会在Hash级别执行并行的全分区或部分分区连接。对于特定的SQL语句,特定的情况可以从两个维度上的分区修剪中受益。
组合Range-Hash分区还可以用于使用Hash分区的表,但需要使用滚动窗口的方法。随着时间的推移,数据可以从一个存储层移动到另一个存储层进行压缩,存储在只读表空间中并最终清除。信息生命周期管理场景通常使用Range分区来实现分层存储的方法。
以下示例为TPCH的orders表采用Range-Hash分区:
CREATE TABLE `orders` (
`o_orderkey` int(11) NOT NULL,
`o_custkey` int(11) NOT NULL,
`o_orderstatus` char(1) DEFAULT NULL,
`o_totalprice` decimal(10,2) DEFAULT NULL,
`o_orderDATE` date NOT NULL,
`o_orderpriority` char(15) DEFAULT NULL,
`o_clerk` char(15) DEFAULT NULL,
`o_shippriority` int(11) DEFAULT NULL,
`o_comment` varchar(79) DEFAULT NULL,
PRIMARY KEY (`o_orderkey`,`o_orderDATE`,`o_custkey`),
KEY `o_orderkey` (`o_orderkey`),
KEY `i_o_custkey` (`o_custkey`),
KEY `i_o_orderdate` (`o_orderDATE`)
) ENGINE=InnoDB
PARTITION BY RANGE COLUMNS(o_orderdate)
SUBPARTITION BY HASH (`o_custkey`)
SUBPARTITIONS 64
(PARTITION item1 VALUES LESS THAN ('1992-01-01'),
PARTITION item2 VALUES LESS THAN ('1993-01-01'),
PARTITION item3 VALUES LESS THAN ('1994-01-01'),
PARTITION item4 VALUES LESS THAN ('1995-01-01'),
PARTITION item5 VALUES LESS THAN ('1996-01-01'),
PARTITION item6 VALUES LESS THAN ('1997-01-01'),
PARTITION item7 VALUES LESS THAN ('1998-01-01'),
PARTITION item8 VALUES LESS THAN ('1999-01-01'),
PARTITION item9 VALUES LESS THAN (MAXVALUE));
####何时使用Range-Range分区 Range-Range分区是指一级分区是Range分区,二级分区也是Range分区的组合分区类型。
Range-Range分区适用于在多个时间维度上存储与时间相关的数据应用程序,这些应用程序通常不使用某个特定的时间维度来访问数据,而是使用另一个时间维度,有时两者同时使用。
Range-Range分区的其他业务用例包括ILM场景和存储历史数据,并期望按另一个维度上的范围对其数据进行分类的应用程序。
以下示例为Range-Range分区表orders_history。银行可以使用对单个子分区的访问来联系用户,以获得低积分提醒或与某一类客户相关的特定促销:
CREATE TABLE `orders_history` (
`id` int(11) NOT NULL,
`customer_name` varchar(50) NOT NULL,
`customer_id` int(11) NOT NULL,
`order_date` date NOT NULL,
`credit` int(11) NOT NULL
) ENGINE=InnoDB
PARTITION BY RANGE (to_days(`order_date`))
SUBPARTITION BY RANGE (`credit`)
(PARTITION p0 VALUES LESS THAN (TO_DAYS('2021-01-01'))
(SUBPARTITION low VALUES LESS THAN (100),
SUBPARTITION normal VALUES LESS THAN (1000),
SUBPARTITION high VALUES LESS THAN (10000),
SUBPARTITION max VALUES LESS THAN MAXVALUE));
####何时使用Range-List分区 Range-List分区是指一级分区是Range分区,二级分区是List分区的组合分区类型。
Range-List分区通常用于存储历史数据的大表,并且在多个维度上访问。数据的历史视图通常是一个访问路径,但是某些业务用例向访问路径添加了另一种分类。例如,区域客户经理非常感兴趣的是,在特定的时间段内有多少新客户在他们的区域注册。ILM及其分层存储方法是创建Range-List分区表的常见原因,以便可以移动和压缩旧数据,但列表维度上的分区修剪仍然可用。
以下示例创建一个Range-List分区order_records表。电信公司可以使用这个表格来分析特定类型的电话:
CREATE TABLE `order_records` (
`id` int(11) DEFAULT NULL,
`order id` int(11) DEFAULT NULL,
`description` varchar(200) DEFAULT NULL,
`record_date` date DEFAULT NULL,
`status` int(11) DEFAULT NULL
) ENGINE=InnoDB
PARTITION BY RANGE (to_days(`record_date`))
SUBPARTITION BY LIST (`status`)
(PARTITION p0 VALUES LESS THAN (TO_DAYS('2021-01-01'))
(SUBPARTITION `normal` VALUES IN (1),
SUBPARTITION close VALUES IN (2),
SUBPARTITION inflight VALUES IN (3),
SUBPARTITION abnormal VALUES IN (4)));
###基于分区的生命周期管理 基于时间维度的数据增长非常适合基于分区粒度的数据生命周期管理,可以有两种模式,第一种基于单一引擎的分区和基于混合分区的管理。PolarDB在混合分区的支持上有很大改进,一是从语法上支持了生命周期的全方位管理,二是支持数据的自动老化能力,三是基于不同的引擎可以支持不同分区的索引数量和类型,更加便捷的支持混合负载查询。
使用场景是在某些行业中,固定周期内可能会产生大量的数据,同时也会通过删除大量数据的方式来节省存储空间。如果新产生的数据和需要删除的数据保存在同一张表中,周期性的大批量数据更新,极有可能影响业务的连续性。且在分区表使用不够普遍的情况下,通常的做法是,由DBA在运维时间内定期手动创建新表来承载新的数据,并且需要删除无用数据所在的表。
这种场景存在一系列痛点:
- 周期性的大批量更新表,可能会对业务的连续性有影响。
- DBA在运维时间内手动更新表数据,会增加运维成本。
####单一引擎的生命周期管理(未来支持DLM) #####定时新增分区 如果您需要为orders分区表定时新增分区,可以通过创建定时任务的方式定时触发新增分区,示例如下:
DELIMITER ||
CREATE EVENT IF NOT EXISTS add_partition ON SCHEDULE
EVERY 1 DAY STARTS '2022-05-20 22:00:00'
ON COMPLETION PRESERVE
DO
BEGIN
set @pname = concat("alter table orders add partition (partition p",date_format(date_add(curdate(), interval 2 day), '%Y%m%d'), " values less than('", date_add(curdate(), interval 2 day), "'))");
prepare stmt_add_partition from @pname;
execute stmt_add_partition;
deallocate prepare stmt_add_partition;
END ||
DELIMITER ;
假设当前已经存在的最大的分区范围为:2022-05-20 00:00:00~2022-05-20 23:59:59,该定时任务可以从2022-05-20 22:00:00开始,每天创建一个新的分区,来保存第二天的数据。
如果分区表orders为INTERVAL RANGE分区,也可以通过INSERT方式定时触发新增分区,示例如下:
CREATE EVENT IF NOT EXISTS add_partition ON SCHEDULE
EVERY 1 DAY STARTS '2022-05-20 00:00:00'
ON COMPLETION PRESERVE
DO INSERT INTO orders VALUES(id, DATE_ADD(NOW(), INTERVAL 1 DAY));
假设当前最大的分区范围是2022-05-20 00:00:00~2022-05-20 23:59:59,定时任务会从2022-05-20 00:00:00开始执行,每天新增一个新分区,而且是提前一天新增下一天的分区。
#####定时删除分区 如果业务上需要定期清理orders表中无用的数据,可以创建一个定时任务删除对应的分区。示例如下:
DELIMITER ||
CREATE EVENT IF NOT EXISTS drop_partition ON SCHEDULE
EVERY 1 DAY STARTS '2022-05-21 02:00:00'
ON COMPLETION PRESERVE
DO
BEGIN
set @pname = concat('alter table orders drop partition p', date_format(curdate(), '%Y%m%d'));
prepare stmt_drop_partition from @pname;
execute stmt_drop_partition;
deallocate prepare stmt_drop_partition;
END ||
DELIMITER ;
假设运维时间从02:00开始,该定时任务会从2022-05-21 02:00:00开始,在每天的02:00删除前一天创建的分区。
#####定时转换分区 如果您不想直接删除orders表中的分区,也可以通过exchange_partition将不再需要的分区转成一张表,这张表与orders分区表完全独立,您可以自行决定如何处理这张表中的数据。示例如下:
// 创建一个与分区表相同表结构的非分区表来做exchange, DDL结束后分区数据会被交换出去,原来的分区会变为空分区。
DELIMITER ||
CREATE EVENT IF NOT EXISTS exchange_partition ON SCHEDULE
EVERY 1 DAY STARTS '2022-05-21 02:00:00'
ON COMPLETION PRESERVE
DO
BEGIN
set @pname = concat('create table orders_', date_format(curdate(), '%Y%m%d'), '(id int, ordertime datetime)');
prepare stmt_create_table from @pname;
execute stmt_create_table;
deallocate prepare stmt_create_table;
set @pname = concat('alter table orders exchange partition p', date_format(curdate(), '%Y%m%d'), ' with table orders_', date_format(curdate(), '%Y%m%d'));
prepare stmt_exchange_partition from @pname;
execute stmt_exchange_partition;
deallocate prepare stmt_exchange_partition;
END ||
DELIMITER ;
该任务会从2022-05-21 02:00:00开始,在每天的02:00,将前一天创建的分区与一个空表进行交换,分区中原有的数据都会保存在被交换的表中。
#####混合分区能力支持 混合分区(Hybrid Partition)是PolarDB对Partition功能的增强。 通过混合分区功能,PolarDB提供了访问存储在不同介质上的数据的能力。OSS引擎可以让PolarDB直接查询OSS存储上的CSV数据,有效地降低存储的成本。
###在线事务处理(OLAP)中使用分区 由于在线事务处理 (OLTP) 系统及其用户数据的爆炸式增长,分区对于 OLTP 系统特别有用。OLTP 系统通常使用分区来减少争抢,同时支持非常大的用户群。它还有助于解决OLTP系统面临的数据隔离问题,包括以高效的方式存储大量数据。在OLTP中使用分区有下面好处: ####支持更大的数据库表 作为高可用性策略的一部分,备份和恢复都可以在低粒度级别上执行,以有效管理数据库的大小。 分区有助于减少 OLTP 系统的空间需求,因为数据库对象的一部分可以压缩存储,而其他部分可以保持未压缩。针对未压缩行更新事务比更新压缩数据更有效。 分区可以将数据透明地存储在不同的存储层上,以降低保留大量数据的成本。 ####更小粒度数据维护的分区维护操作 对于数据维护操作(DROP和EXCHANGE是最常见的操作),可以利用分区维护操作和数据库的在线索引维护的能力。分区粒度的MDL能让该维护更加高效,用户间可以不受影响。 ####通过消除热点潜在的更高并发性 OLTP 环境的一个常见场景是使用单调递增的索引值来强制执行主键约束,从而创建高并发和潜在争用区域:每个新插入都尝试更新同一组索引块。分区索引,特别是哈希分区索引,可以帮助缓解这种情况。
####单分区优化 MySQL中对于分区的访问有专门的分区接口,进行数据的汇聚和排序,但是一些用户场景都是经过剪枝后变成一个分区,或者希望用分区在单分区的所有场合都性能不下降,PolarDB MySQL针对单分区进行了特殊的优化,能够让单分区性能和单表的性能保持一致。另外,对于跨分区的并行扫描有很大限制,但是对于单分区的访问无该限制。
####分区Hybrid索引优化
OLTP 环境中的性能在很大程度上依赖于高效的索引访问,因此选择最合适的索引策略变得至关重要。PolarDB MySQL可以支持在不同分区上创建不同类型和不同数量的索引,已支持通过分区进行数据隔离的业务能够根据数据特征和查询特征进行索引访问。

有了该能力后,PolarDB MySQL每个分区维护操作都可以扩展为以原子方式对本地索引维护,从而能够执行任何分区维护操作,而不会影响 整个OLTP 环境的可用性。
####全局二级索引 OLTP环境中,经常要使用全局索引来加速数据的访问,如果查询的条件与分区键不同,会产生跨分区查询。跨分区查询会增加更多性能损耗,全局二级索引正式为了消除性能瓶颈而存在。全局二级索引,不同于局部索引,全局索引的构建来自于不同分区的数据,主要用于快速确定查询涉及的数据的分区,而局部索引仅仅是针对其中一个分区数据而创建的索引,和普通物理表一样。目前全局二级索引也支持并行扫描。
####常见OLTP运维操作 #####删除(清除)旧数据 使用DROP or TRUNCATE操作会根据分区键标准删除较旧的数据。 删除数据和分区元数据,而TRUNCATE操作仅删除数据但保留元数据。所有本地索引分区都被分别删除和截断。异步全局索引维护针对分区全局索引完成,并且完全可用于查询和 DML 操作。 #####将旧分区移动或合并到低成本存储层设备COALESCE 使用REORGANIZE/COALESCEorEXCHANGE操作作为数据生命周期管理的一部分,可以通过该命令将旧分区重新移动到成本本效益的存储层,如OSS存储或者压缩率高的XENGINE引擎。
###在混合负载查询(HTAP)中使用分区
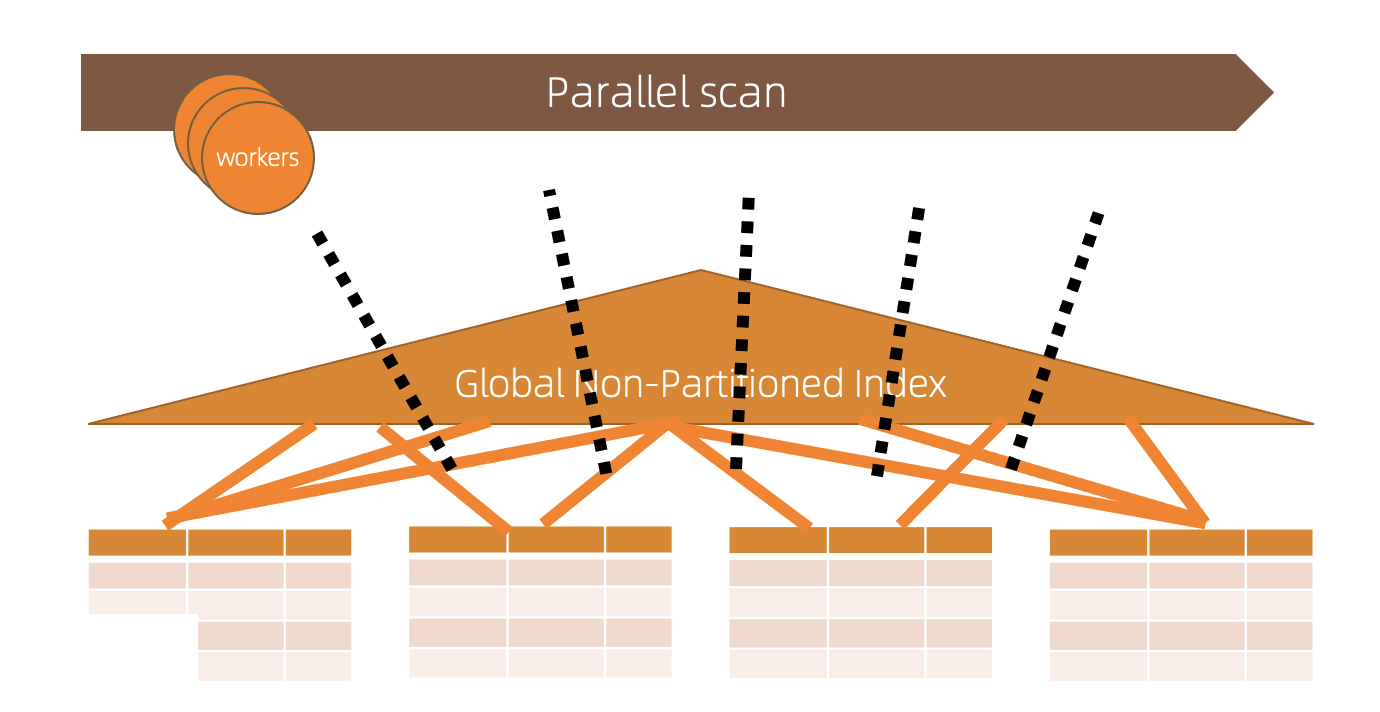
分区已经支持并行查询(SMP)和跨机并行查询(MPP on Share Storage),扫描方式分两种, Btree内部Granule粒度和分区partition粒度
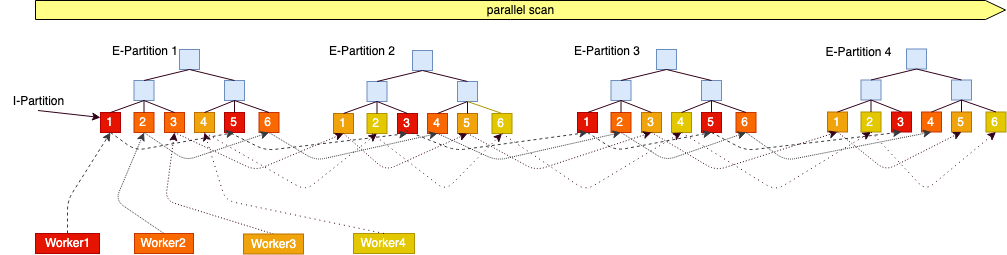
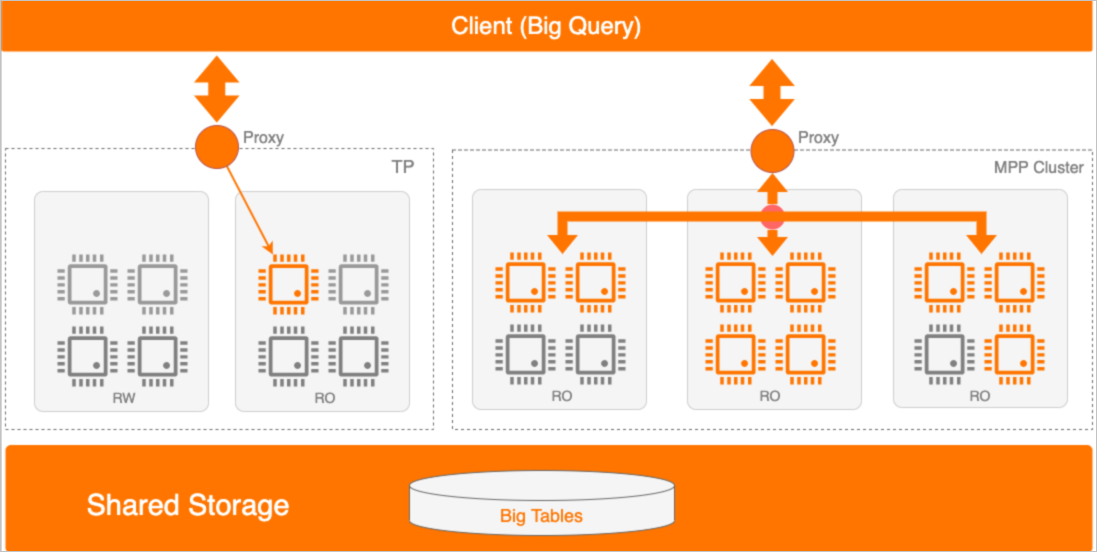
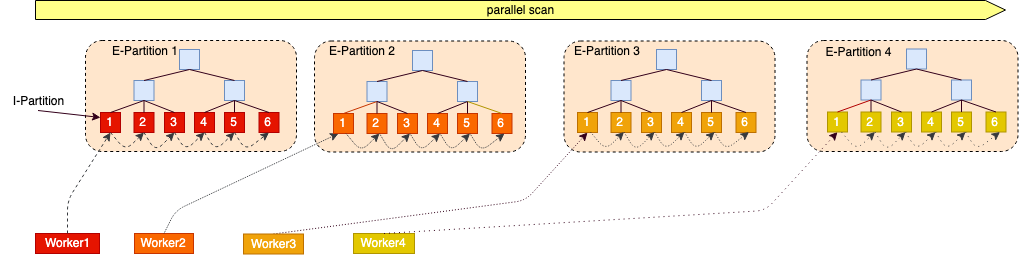 对于跨机并行的分区支持是建立在整体MPP框架的基础上的,可以了解下跨级并行能力
对于跨机并行的分区支持是建立在整体MPP框架的基础上的,可以了解下跨级并行能力
#未来展望 分区不是解决大表的银弹,但是是强有力的手段,我们后续也会在分区性能上如动态剪枝、分区感知的连接、统计信息、混合复杂查询等做更多改进和增强。这里顺便讲个故事,技术过时和技术创新之间的辩证关系。技术过时是指该技术已经不再适合工业领域的技术,技术创新是指从某个领域进行从未尝试过的突破,可以看到这两种情况都无法明确证明该项技术是否可以在未来广泛运用或者继续运用到工业界中。学术界一直是在不断探索中,数据库作为老牌技术,其实在这个领域创新已经很“难”了,转而求其次是更加精细化的创新,比如如何利用云技术以及最新前沿的其他硬件、系统框架、领域、甚至是行业结合进行创新。当然这里要特别强调云计算的普及使得数据库技术有了二次革命和创新的土壤,比如利用云原生技术通过存计分离甚至是内存池化技术,让数据库拥有更强大的高可用、高可扩展和高吞吐能力。回顾这些“新技术”,可以看到我们并没有淘汰老的技术,老的技术依旧坚挺在业界中。未来的云原生数据库和分布式数据库,不再光是拥有漂亮的架构图展示,更多的是外部看不到的,真正能够在技术架构细节上做到设计极致和完美,高效利用模块之间的交互和接口设计,清晰的模块划分,充分的利用云技术的可扩展高可用的能力,PolarDB MySQL一直在不断探索和追求创新。
#参考资料
- VLDB and Partitioning Guide
- Database Partitioning, Table Partitioning, and MDC for DB2 9