PolarDB MySQL 新特性 - Partial Result Cache
Author: 之枢
背景
查询缓存(Query Cache)是数据库执行层的一个加速查询的特性,用来缓存一条查询语句的结果集,如果后续再有相同的查询,直接从结果集缓存中读取结果,而不用再重新执行而极大提升查询性能。
官方MySQL在4.0版本就引入了Query Cache,但由于设计缺陷,在最新8.0版本移除了该功能。针对MySQL原生Query Cache的不足,PolarDB进行重新设计和全新实现,推出了Fast Query Cache。
Query Cache适用的场景是对重复的SQL语句进行加速,但在一条查询语句中内部,同样存在一些算子会被反复计算的情况(比如Correlated subquery,NestLoopJoin),即便是驱动算子执行的相关参数项有完全重复的情况,这些算子也依然需要被执行多次,而这些算子一般执行代价都较高,重复计算造成了大量资源的浪费。如果能将这些需要重复计算的算子的结果集缓存起来,优先查看缓存中是否已经存在,来尽量避免算子的重复计算,就可以极大提升查询效率。
鉴于结果集缓存能够带来非常可观的加速效果,我们在PolarDB-MySQL引入了支持查询内部算子级别中间结果集缓存的新特性Partial Result Cache,简称PTRC。
什么是PTRC
Partial result Cache,是针对一个查询内部算子级别粒度的结果集缓存特性,比如缓存Correlated subquery或NestLoopJoin等算子执行的临时结果,后续再次执行该算子时,如果结果集缓存中已存在,则无需再重复执行该算子。
PTRC中的Partial有两层含义:
- PTRC缓存的不是整个查询的结果集,而是查询内部某个或某几个算子执行的中间结果的缓存。
- 并不一定缓存算子所有的中间结果,而是根据内存限制可能只缓存部分中间结果。
相较于传统的Query Cache,PTRC的缓存粒度更小,针对的是查询内部某些算子进行加速,并且可以看出PTRC的生命周期也是跟随查询一起开始和结束的。基于上述原理可以看出,PTRC的适用范围会更广,因为只针对查询内部算子的优化,不存在跨查询的数据一致性的问题,只要一个算子符合要求(即算子执行时依赖的参数不变,执行结果也不会变)就可以使用PTRC,当然我们在选择PTRC时不仅靠规则,还会基于代价决策是否使用PTRC。
PTRC的工作原理
PTRC的核心思想是利用中间结果缓存避免某些算子的重复执行,那哪些算子可以被PTRC加速呢?可以被PTRC加速的算子需要满足如下条件:
- 算子执行是有相关性参数(Correlated Parameters)的依赖,并且会被反复多次执行,比如NestLoopJoin、相关子查询;
- 算子的相关性参数保持不变,无论执行多少次,算子执行的结果是稳定不变的;比如算子中不能有random, now, udf等影响算子重复执行结果稳定性的函数,不然缓存会影响结果正确性。
解释下算子执行的Correlated Parameters,本质就是算子执行所依赖的外部参数,例如 t1 join t2 on t1.a = t2.a,t1表作为驱动表,t1表的每一行都要和t2表完成一次join操作,而 t1.a 则被认为是该NestLoopJoin的Correlated Parameters。如果t1.a 在t1表中存在较多的重复值,那PTRC将会减少这部分的重复计算。
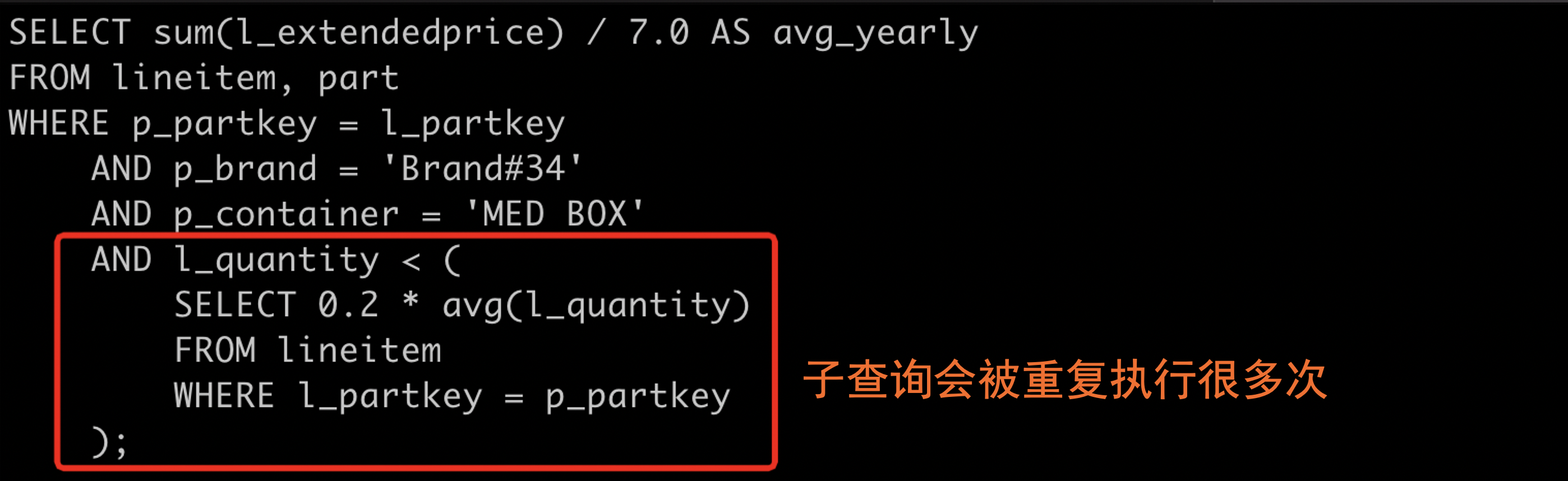
再比如correlated subquery,子查询的每一次执行,都依赖于父查询的一次扫描的结果的基础上作为驱动参数,我们以TPCH-Q17示例说明下PTRC的基本工作原理。
TPCH-Q17:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#34'
and p_container = 'MED BOX'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);
PTRC中会以算子的Correlated Parameters作为key,算子的执行结果作为value存储在缓存中,故Q17中PTRC的缓存存储格式为:key= p_partkey, value = [true/false] 。
Q17中相关子查询的PTRC的主要执行流程如下图所示,当每次要对相关子查询求值时,根据Correlated Parameters (p_partkey)的值在PTRC中查找是否命中,如果未命中,需要真正执行子查询进行求值,并将新求值的结果记录到PTRC的缓存中;如果命中缓存,直接将结果返回,则避免了一次子查询的重复执行。因为Q17是part表join lineitem表后再执行子查询,join之后的结果中p_partkey重复项非常多,而p_partkey又是子查询的correlated parameters,所以Q17的PTRC命中率会很高,性能提升会非常显著。
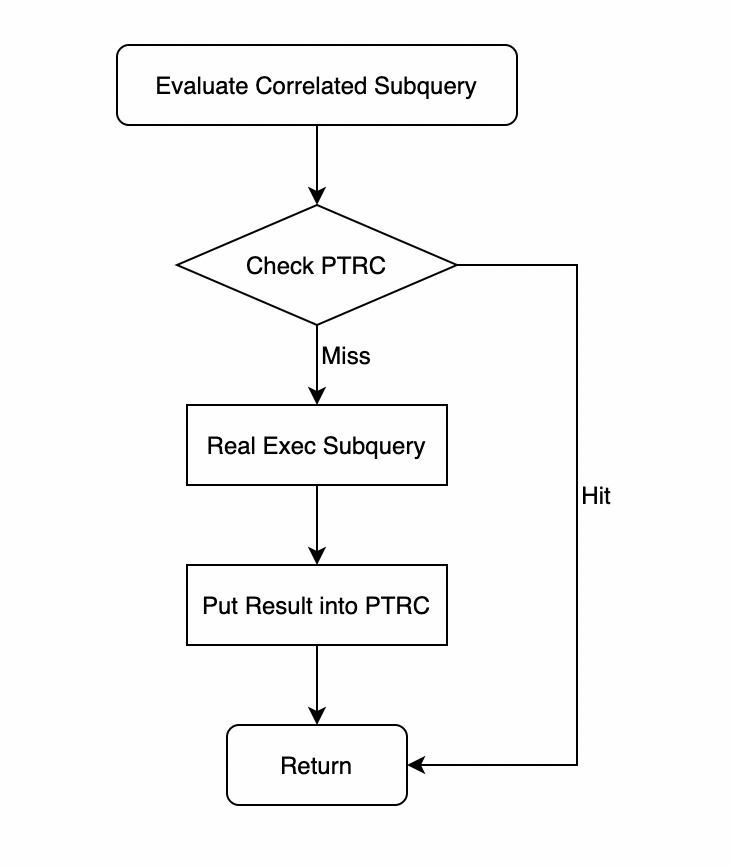
使用explain可以查看计划发生的变化,在子查询真正执行前多了一个Partial Result Cache算子,则说明该子查询正式引入了PTRC,如下图所示:

基于代价选择PTRC
从PTRC执行流程可以了解到,引入PTRC也并不是多多益善,关键是取决于PTRC的命中率,如果命中率不高,引入PTRC也会带来额外的性能开销,比如每一次都要Check Cache,以及额外的内存占用开销等。 为避免不必要的开销,优化器会基于代价的选择是否使用PTRC,主要考虑两个维度:
- 当查询整体cost高于partial_result_cache_cost_threshold时,才考虑引入PTRC;
- 评估算子使用PTRC的命中率,命中率高于partial_result_cache_low_hit_rate时,才考虑引入PTRC;
优化器会先检查partial_result_cache_cost_threshold,当查询的整体cost低于该阈值时,我们认为该查询的执行代价比较低,本身应该就是一个短查询,即便引入PTRC后提升也会比较有限,且额外的Check Cache等操作可能还会对高并发下的短事务类查询的latency造成负面影响,所以提供了一个总的代价阈值控制是否完全忽略PTRC。而且当该阈值不满足时,优化器阶段枚举所有表达式寻找是否使用PTRC的开销也省掉了。
当查询cost满足partial_result_cache_cost_threshold时,优化器会遍历检查所有可能满足PTRC规则的算子,并对满足规则的算计估算它的PTRC 命中率,计算公式为 hit_rate = (fanout - ndv)/ fanout。
命中率估算相关概念:
- fanout, 一个算子需要被重复执行的总次数。
- ndv,PTRC的key的唯一值的个数,也就是Correlated Parameters所有参数组合值的唯一值个数。
当评估出的hit_rate低于partial_result_cache_low_hit_rate时,这个算子就不再考虑使用PTRC。但在Mysql已有代价模型中,它的统计信息非常依赖于表的索引或直方图,如果Correlated Parameters这些相关的列上没有索引或直方图,很难评估出非常准的ndv,在这种情况下我们会尽量引入PTRC,然后交给PTRC执行阶段的动态反馈机制来动态检查是否有必要继续使用PTRC。
PTRC的动态反馈机制
在PTRC执行阶段,每次Cache是否命中都会记录到统计信息中,动态反馈机制负责对PTRC的真实命中率进行计算,如果发现实际命中率低于partial_result_cache_low_hit_rate时,则会直接在执行阶段禁掉PTRC,恢复到没有引入PTRC前的执行状态,用来避免低效的PTRC带来的额外开销。 partial_result_cache_check_frequency 是控制PTRC动态检测命中率频率的参数,它的含义是累计出现cache miss的次数,比如默认值为200,每当cache miss的次数累计达到200次后,就会触发一次动态反馈检测。
因为结果集是缓存在内存中,当PTRC的内存使用量达到上限时,同样也会触发动态反馈机制,但此时的动态反馈不仅要检查命中率是否过低,还会做数据淘汰或者是否转储到Disk的决策。 当内存达到上限时的动态反馈策略为:
- 当hit_rate低于partial_result_cache_low_hit_rate时,认为命中率过低,直接禁用PTRC;
- 当hit_rate高于partial_result_cache_high_hit_rate时,命中率大于高水位,会将内存中缓存数据转存至Disk存储,认为即便是转为Disk存储,依然会有可预期的性能提升;
- 当hit_rate处于低水位和高水位之间时,则会触发LRU数据淘汰,将命中率不符合预期的数据清理掉,后续重新缓存新的数据;若新缓存数据后再次触发内存不足,重复上述几个步骤的检测;
partial_result_cache_max_mem_size 是限制单个查询PTRC最大使用内存的配置参数,因为单个查询内部可能有多个算子使用PTRC,这些PTRC需要共享累计所占用的全部内存空间,一旦查询内总的内存使用超过限制,所有的PTRC都将会触发上述的动态反馈机制。
PTRC的参数配置
下面详细介绍一下PTRC相关的几个配置参数: |变量名 | 级别 | 说明 | |——-|——-|——| | partial_result_cache_enabled | Global/Session | Partial Result Cache的开关。 | | partial_result_cache_cost_threshold | Global/Session | 优化器是否考虑引入PTRC的代价阈值,单个查询的整体cost超过该阈值,才开始考虑是否可以使用PTRC。 | | partial_result_cache_check_frequency | Global/Session | 触发PTRC的动态反馈检测的频率,频率是每累计cache miss的次数达到该值时触发一次检测。 | | partial_result_cache_low_hit_rate | Global/Session | PTRC命中率的低水位阈值。当优化器估算的命中率高于此值时才考虑使用PTRC;如已使用PTRC,动态反馈机制中发现真实命中率低于该值时,将直接放弃继续使用PTRC。 | | partial_result_cache_high_hit_rate | Global/Session | PTRC命中率的高水位阈值。当内存使用达到上限并且命中率高于此值时,内存缓存变更为文件存储缓存,已缓存的数据也会转存至文件中。 | | partial_result_cache_max_mem_size | Global/Session | 单个查询中PTRC最大允许的内存使用量,一个查询内部可能有多个PTRC,多个PTRC累计使用的内存不能超过这个限制大小。 |
PTRC性能表现
通过前述基于代价选择PTRC的描述,可以看出影响PTRC的加速效果的主要有如下两个因素:
- 使用PTRC加速的算子的执行代价要足够大,如果算子本身执行代价不高,缓存加速的提升空间就有限;
- 缓存命中率,PTRC的缓存命中率越高,加速效果越明显;
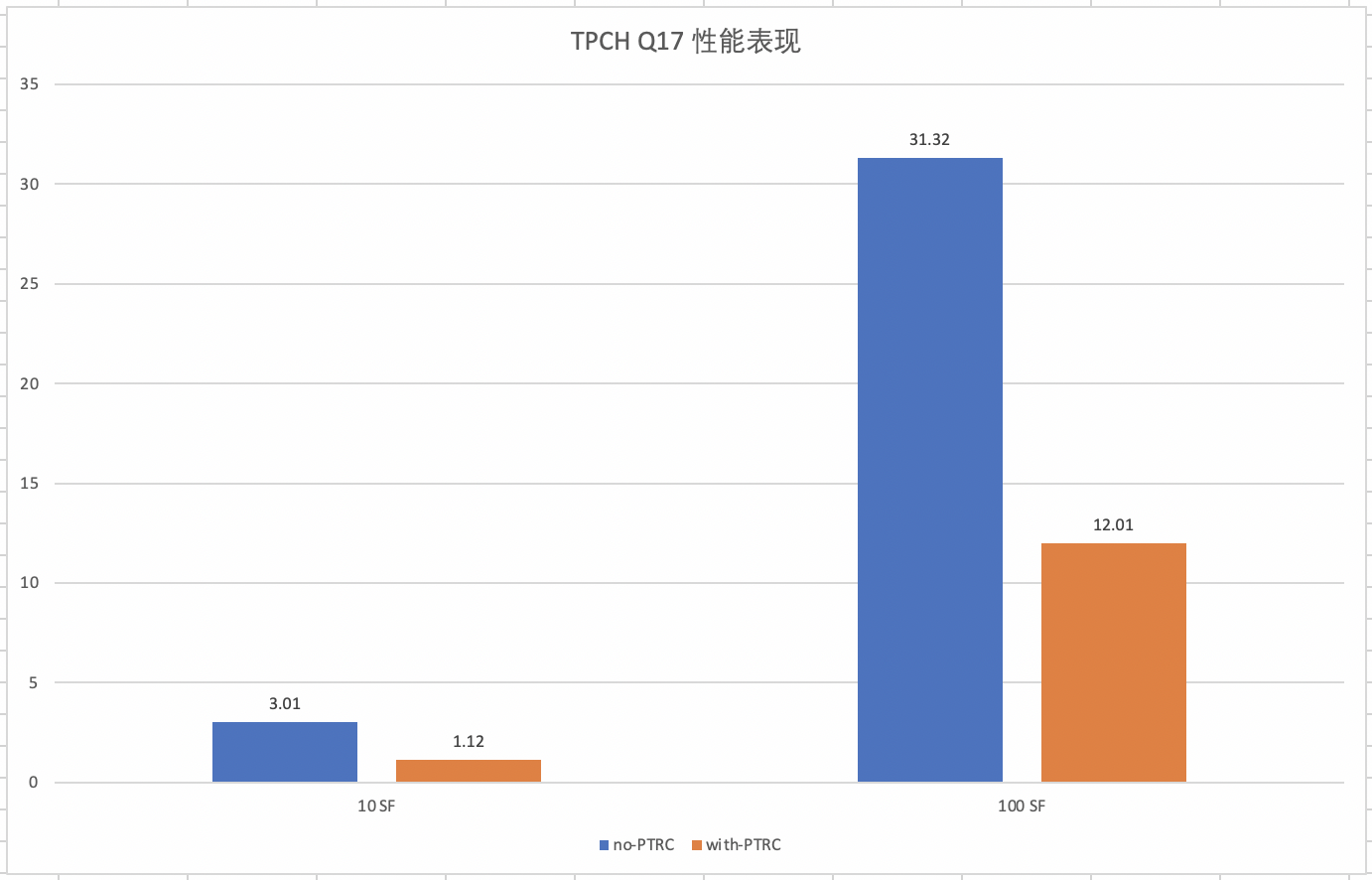
我们再以TPCH-Q17测试为例:
相关子查询引入PTRC后的查询计划后:

经过测试统计信息计算,TPCH-Q17相关子查询引入PTRC的缓存命中率达96%,缓存加速效果非常明显,测试数据如下图:
总结
PTRC是一种缓存优化,针对的是单个查询内部的具有相关性参数依赖的复杂算子,通过缓存算子执行的中间结果集来避免这些复杂算子的重复计算,只要命中率足够,就可以获得非常可观的加速效果。目前查询中Correlated Subquery, Nested Loop Join (包含Inner join, Outer join, Semi join, Anti join) 等多种算子均可以使用PTRC进行加速,PTRC新特性将在PolarDB for MySQL 8.0.2.2.9版本开始支持,欢迎大家使用。