PolarDB MySQL · 功能特性 · Fast Query Cache技术详解与最佳实践
Author: 勉仁
PolarDB MySQL在2020年推出了Fast Query Cache(查询结果缓存),且在PolarDB MySQL各个大版本(5.6 5.7 8.0)中均已支持。Fast Query Cache做了大量无锁的设计和自适应优化,能够支持高并发,能够使业务享受缓存命中带来的性能提升而无需担心有不适配场景使业务受影响。这两年已经积累了大量不同领域(包括零售、电商、教育、SAAS等)的客户,主动使用该功能,提升查询性能,提供数据库吞吐,优化数据库负载。 在PolarDB MySQL官网文档和之前的内核月报都做过了功能介绍。本文会对比社区Query Cache,对Fast Query Cache做一个技术详解和最佳实践的介绍。
社区MySQL Query Cache介绍
Query Cache(查询缓存)是将查询的结果缓存在数据库中,当下一次同样的查询命中该缓存的时候,就可以直接将缓存结果返回客户端,从而不需要对查询做解析、优化、执行,极大的缩短查询响应时间,减少系统开销。对于一些更新较少、存在重复查询的业务,Query Cache非常适用。对系统开销的减少,用户可以用更小的实例规格来支撑业务。
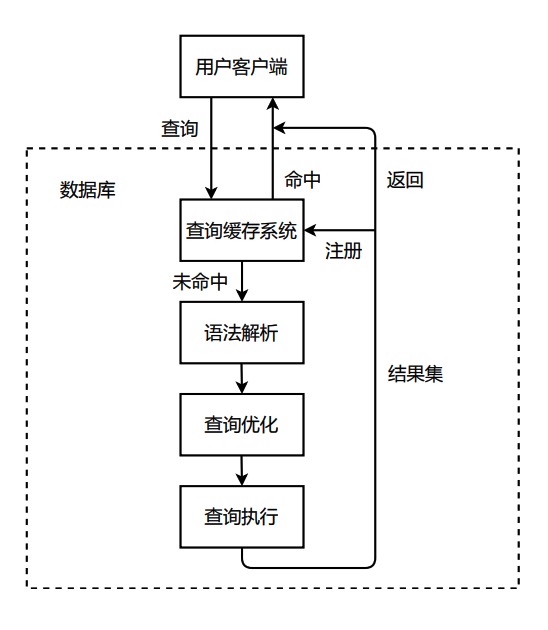
但社区QueryCache一直以来又存在以下的缺陷,导致其用户使用量逐渐减少,最终从社区版本移除。
- 并发控制
社区MySQL Query Cache是在2001年4.0.1版本引入的,在这之后一直未做重构,然后MySQL8.0将该功能移除。社区MySQL Query Cache在并发支持上考虑很少(2001年首个多核处理器才由IBM发布),直接使用一把大锁来保护整个Query Cache。我们使用社区Query Cache的话,在多并发场景下可以经常看到session在等待query cache lock。
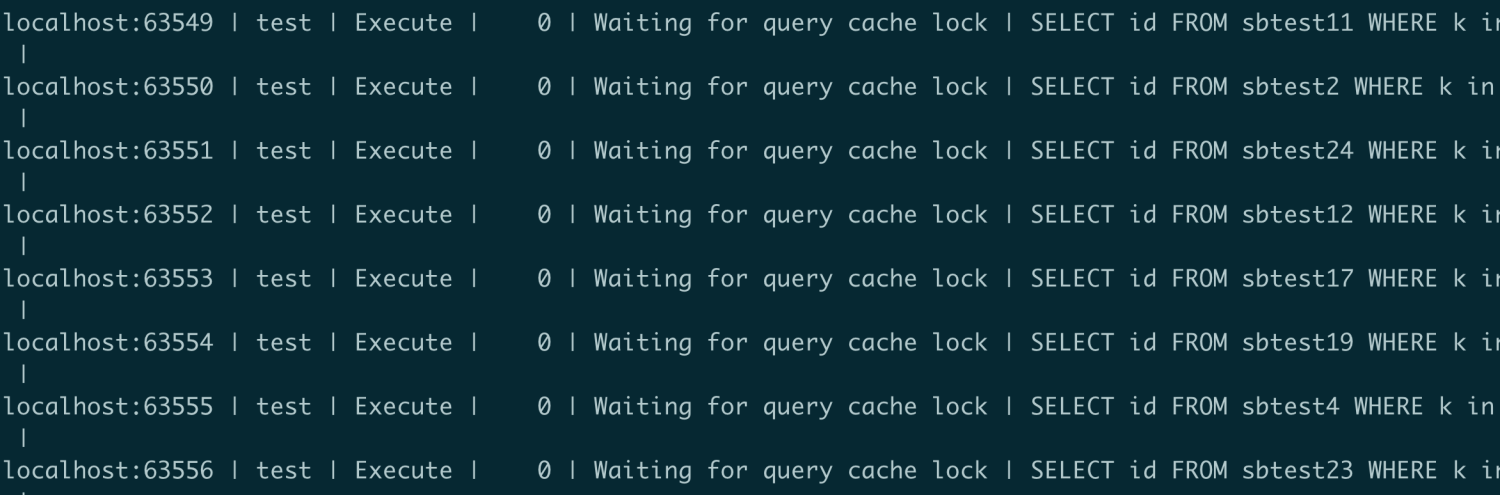
而且其数据结构设计中,每个表都用链表将引用的各个查询链接起来。对于会失效的DML、DDL语句,要逐个访问释放。这就会导致命中缓存的SELECT语句会阻塞DML语句的执行。
- 内存管理
社区Query Cache在内存管理上,会在启动的时候就直接申请一整块内存。早期服务器内存很小,在2012年,query_cache_size的默认值才由0变成1M。对于现在,业务的复杂性高很多,内存分配的小只能缓存极少的查询,缓存也很容易因内存不足被淘汰。而如果直接分配大块内存,而又会即使没有被使用也被占用,造成内存浪费。
- 场景支持
社区Query Cache一直未做更多场景的支持。现在很多都是集群部署,用户会添加只读节点,通过Proxy来路由查询做负载均衡。这其中很重要的技术就是session tracker,数据库可以返回客户端需要的事务状态信息、变量变化等信息,使路由中间件可以根据这些信息决定后续查询是否可以发给其他节点、及在其他节点上需要配置的变量。而社区Query Cache未做支持,其命中查询缓存后是返回客户端固定的packet。因为这一点也存在bug,参见 https://bugs.mysql.com/bug.php?id=99773。 MySQL返回的OK报文参加https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_basic_ok_packet.html。
- 机制缺陷
社区Query Cache也在一些机制上存在结果正确性的问题。InnoDB事务会记录trx_id,Query Cache会利用该值的大小决定Repeatable-read隔离级别下缓存是否可见。而该值却不是事务的提交顺序,trx_id小的可能是后提交的事务。这就导致在REPEATABLE-READ隔离级别下,社区Query Cache会有正确性问题,参见 https://bugs.mysql.com/bug.php?id=99759。
PolarDB Fast Query Cache技术详解
虽然社区MySQL在8.0中移除Query Cache,但查询缓存对很多业务的价值不可否认,商业数据库也有类似的功能,例如Oracle在09年11gR2版本中也引入了Result Cache功能。 PolarDB重新设计实现了Query Cache,解决了社区Query Cache存在的不足,同时引入了基于系统代价的自适应控制能力来适应各种业务场景。下面介绍PolarDB Fast Query Cache所做的优化。
极致并发能力
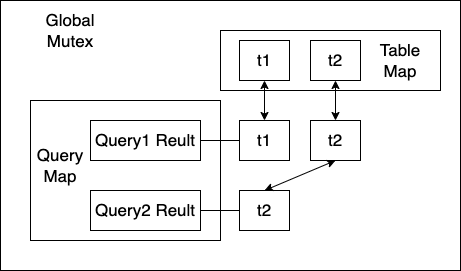
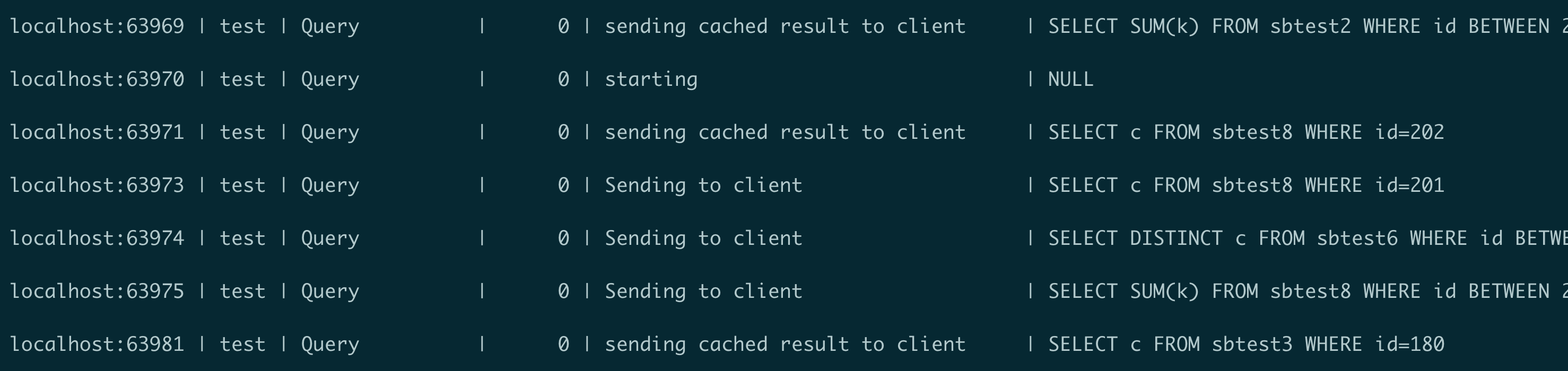
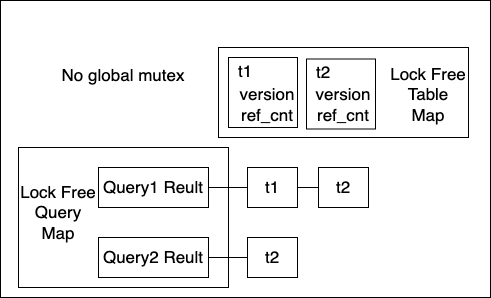
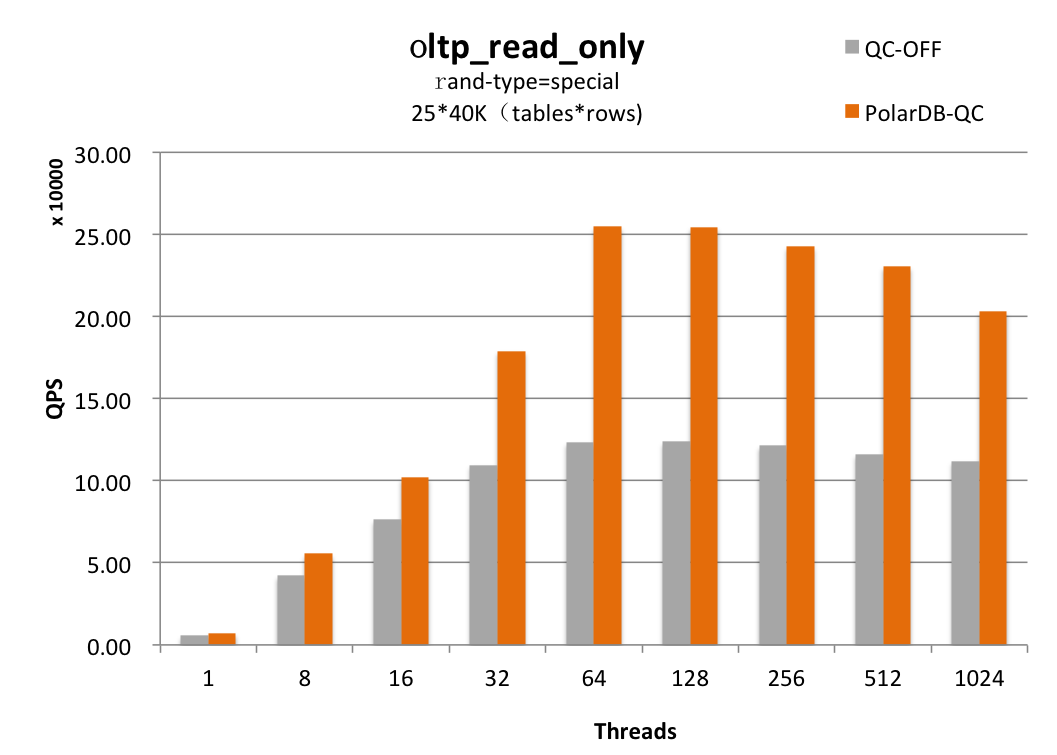
PolarDB Fast Query Cache设计中没有任何全局锁,查询缓存节点和table的map均使用无锁HASH结构,并发控制大量使用原子操作。整体设计可以充分利用多核的处理能力,对于命中率高的压测场景,可以看到session主要在返回结果给客户端。
在Fast Query Cache中,引用相同table的查询缓存不再使用链表链接。失效和淘汰逻辑通过table上的版本号和引用计数来处理。这样使DML、DDL等失效Query Cache的操作变成一个原子操作,不会被查询命中缓存而阻塞。
动态的内存使用和回收
与社区直接分配一大块内存不同,Fast Query Cache的内存在生成新的查询缓存时候才会向内存分配器动态申请。同时查询缓存会因DML、DDL而失效,也可能因超过lease时间未访问而失效,后台线程会回收这些失效的查询缓存。这样我们不必担心在ast Query Cache未使用时候依然占用较大内存。
同时在Fast Query Cache中,我们维护了LRU链表,新写入的缓存和命中的缓存会移动到链表尾端。当内存使用率高,后台会淘汰最老的未被命中的缓存。
场景支持
Fast Query Cache支持PolarDB集群访问。PolarDB集群版采用多节点集群的架构,集群中有一个主节点(可读可写)和至少一个只读节点。 开启Fast Query Cache后,主节点上的写事务会在事务提交时,在Redo中记录该事务修改的表。在只读节点上会通过解析Redo获得哪些表的数据做了更改,在更新只读节点最新read view的时候同时失效这些表的查询缓存,以此来保证只读节点不会读到已经失效的数据。
当应用程序使用集群地址时,PolarDB通过通过内部的代理层(PolarProxy)对外提供服务,做到读写分离。这样Fast Query Cache支持session tracker就是一个必须项。与社区直接返回历史缓存的所有packet不同,Fast Query Cache会在命中缓存后,自动识别是否需要tracker信息并动态生成OK报文。因此Fast Query Cache支持集群地址访问,也不存在社区tracker信息错误的问题。
正确性保证
在Fast Query Cache的设计中详细的考虑了各个隔离级别下的各类场景,确保结果的正确性。例如对于前文叙述的社区Query Cache中不恰当的通过trx_id来判断缓存是否可以使用的问题,在PolarDB中是通过维护事务提交的committed version来判断Repeatable-read隔离级别下的缓存可见性。相对trx_id,事务提交时候的版本号可以准确描述事务提交顺序。 对于只读节点的支持,由于我们是在解析到事务提交日志时才能解析到更改的表,并在更改最新read view的时候失效对应表的缓存。在只读节点上Fast Query Cache不支持Read-Uncommitted隔离级别。
自适应缓存
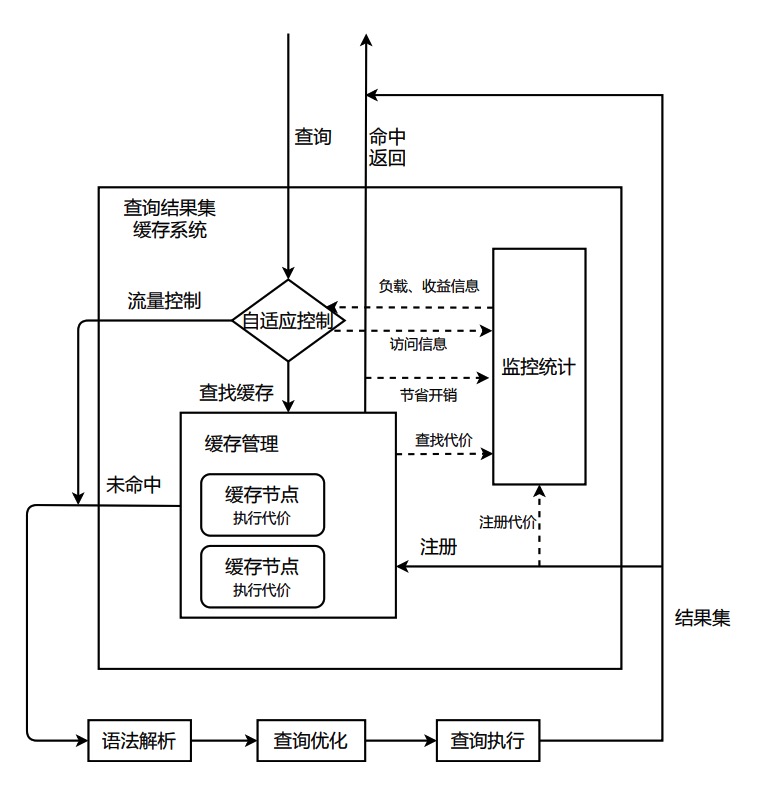
虽然查询缓存命中后能大幅节省系统开销,但是当所有查询都不一样或者表的数据在频繁更新导致查询都无法命中缓存时,查询缓存会带来额外的开销。在这些场景下如果不做自适应调整,及时做到极致的并发优化,sysbench读写场景仍会有超过10%的吞吐影响。为了能够消除对系统的负面影响,Fast Query Cache中包含了自适应控制模块。该模块并不是简单根据缓存命中率做自适应调整,因为慢查询的命中给系统带来的收益明显高于简单的查询。自适应模块会动态的统计收集Query Cache带来的系统收益和缓存的开销、监控系统负载,进而做自适应调整,在开销明显大于收益的时候减少缓存的写入。基于该自适应模块,Fast Query Cache在各个场景高并发压力下对系统吞吐的影响都可以控制在3%以内。同时对于一直在高频写入的表,Query Cache会不做缓存,避免查询无意义的缓存与失效开销。
PolarDB Fast Query Cache最佳实践
什么业务场景适合使用Fast Query Cache
前面我们介绍了PolarDB Fast Query Cache关键的技术详解,因为其具有的高并发能力、动态内存使用和自适应能力,所以对于不同业务场景都可以开启。Fast Query Cache会自动在适宜的场景优化系统开销、加速查询,同时避免其他场景对系统吞吐产生影响。
单就适宜的场景,举一些例子。例如一些营销系统,数据批量导入然后做数据访问分析,数据并不会频繁更新,而同样的数据可能在任务中多次访问。例如教育行业,学生名单和成绩等也往往是一次性导入,可能被多次访问。而且对于一个看起来数据不断更新的业务系统,也往往有一些表的数据并不是每一刻都在变化。例如订单系统,其区域和地理信息相关的表、商品类目和一些商品明细表、供应商表、用户表中就有一些表基本不更新或者偶尔更新。而即使是订单表,也会在一天之中有产生大量订单的消费高峰时间段,同时有订单较少的业务低峰。业务低峰时候,往往下游任务会消费订单信息,不同任务会对同一个订单做访问,也会有任务做一些数据分析产生报表。
一个数据库实例还可能存在不同业务,业务又在不断变化,那又如何选择。而PolarDB Fast Query Cache的自适应技术恰恰让数据库的用户省去了这部分困扰。
Fast Query Cache相关变量与状态
- 相关变量
可以通过配置query_cache_type开启Fast Query Cache。
| 参数名 | 取值 | 说明 |
|---|---|---|
| query_cache_type | OFF | 禁用Fast Query Cache。 |
| ON | 默认在查询中使用Fast Query Cache功能,但可通过SQL_NO_CACHE关键字跳过缓存。 | |
| DEMAND | 默认在查询中不使用Fast Query Cache功能,但可通过SQL_CACHE关键字对特定语句使用缓存。 |
可以通过query_cache_size来设置Query Cache可以使用的最大内存
| 参数名 | 取值 | 说明 |
|---|---|---|
| query_cache_size | 0-18446744073709551615 | 默认值与规格相关。Query Cache可以使用的最大内存 |
可以通过query_cache_limit来设置Query Cache可以缓存的最大结果集。
| 参数名 | 取值 | 说明 |
|---|---|---|
| query_cache_limit | 0-18446744073709551615 | 默认值1M(1048576)用于配置Query Cache可以缓存的最大结果集。 |
可以通过query_cache_lease_time来设置缓存的节点在多长时间未命中后主动失效。
| 参数名 | 取值 | 说明 |
|---|---|---|
| query_cache_lease_time | 0-18446744073709551615 | 当缓存的节点超过该时间未被命中后即失效,相应的内存会被回收。单位秒。 |
- 相关Status
| Status | 取值范围 | 说明 |
|---|---|---|
| Qcache_queries_in_cache | 0-18446744073709551615 | 查询缓存中缓存节点的数目 |
| Qcache_flow_control | 0|1 | 自适应缓存是否正在对查询的缓存做限流 |
| Qcache_free_memory | 0-18446744073709551615 | 剩余可申请的内存空间 |
| Qcache_hit_ratio | 0-100 | 数据库启动以来的查询缓存命中率 |
| Qcache_hit_ratio_1m | 0-100 | 查询缓存1分钟内的命中率 |
| Qcache_hits | 0-18446744073709551615 | 查询命中的次数 |
| Qcache_inserts | 0-18446744073709551615 | 查询缓存写入的次数 |
| Qcache_lowmem_prunes | 0-18446744073709551615 | 内存不足导致回收缓存的次数 |
| Qcache_not_cached | 0-18446744073709551615 | 查询没有做缓存的次数 |
| Qcache_prune_state | 0|1 | 后台线程状态 |
| Qcache_total_blocks | 0-18446744073709551615 | 总的block数目 |
Fast Query Cache使用限制
Fast Query Cache对社区Query Cache原有部分使用限制做了支持,但还有很多查询缓存机制上的限制是保留的。Fast Query Cache仅支持SELECT语句,同时有如下限制:
- 语句中含有时间类函数、随机函数等无法缓存。函数列表如下:
AES_DECRYPT()\AES_ENCRYPT()\BENCHMARK()\CONNECTION_ID()\CONVERT_TZ()\CURDATE()\CURRENT_DATE()\CURRENT_TIME()\CURRENT_TIMESTAMP()\CURRENT_USER()\CURTIME()\DATABASE()\ENCRYPT() with one parameter\FOUND_ROWS()\GET_LOCK()\IS_FREE_LOCK()\IS_USED_LOCK()\LAST_INSERT_ID()\LOAD_FILE()\MASTER_POS_WAIT()\NOW()\PASSWORD()\RAND()\RANDOM_BYTES()\RELEASE_ALL_LOCKS()\RELEASE_LOCK()\SLEEP()\SYSDATE()\UNIX_TIMESTAMP() with no parameters\USER()\UUID()\UUID_SHORT() - 语句中包含用户自定义函数
- 语句中包含用户变量
- 语句引用mysql、performance_schema库下的表。(Fast Query Cache支持information_schema库下的缓存)
- 语句引用了分区表
- 语句为下面的形式
SELECT ... LOCK IN SHARE MODE SELECT ... FOR UPDATE SELECT ... INTO OUTFILE ... SELECT ... INTO DUMPFILE ... SELECT * FROM ... WHERE autoincrement_col IS NULL - SERIALIZABLE隔离级别不支持。同时在只读节点上不支持Read-Uncommitted隔离级别。
- 语句引用临时表
- 语句中没有引用任何表
- 语句有warning产生
- 用户在语句相关的表上是通过列权限获得访问权限
总结
PolarDB Fast Query Cache拥有极致的并发能力,更合理的内存使用策略,支持集群访问。可以基于代价自适应调整加速系统查询、优化系统性能,同时避免出现影响系统吞吐性能的场景。