PolarDB for MySQL 优化器查询变换系列 - IN-List 变换
Author: 陈江
引言
PolarDB mysql作为一款HTAP数据库,在复杂sql查询能力上有许多深入的优化工作,可以大大加速了查询的时延。具体优化工作比如并行能力,查询变换能力,优化器join order额外支持hash join&bush join等能力。今天我们就从浩瀚的优化器中选取其中的一个点来深入阐述,从中我们对polardb的优化器管孔窥豹,略见一瞥。我们选取最近解决客户的一个共性问题,线上客户抱怨比较多的一类IN-List SQL,如下:
select sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem
where
l_partkey in (
9628136,19958441,10528766,.......); #in list里面有数千甚至上万个常量值。
常见的单表过滤查询,然后进行agg汇总,但In list里面有上千甚至上万个常量值。这种sql mysql执行时间很长,往往造成客户抱怨。
原生mysql
我们先看下原生的mysql是如何执行的,先看下执行计划
+---------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------+
| -> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Filter: (lineitem.L_PARTKEY in (9628136,19958441,10528766,....) (cost=60858714.81 rows=297355930)
-> Table scan on lineitem (cost=60858714.81 rows=594711859)
|
+---------------------------------------------------------------------------------------------------+
执行过程是线性scan lineitem 5.9亿条数据,逐条去判断是不是在In-list里面,这个算子是Item_func_in,因为in集合元素个数10W,比较多,这个算子比较重。整体耗时完耗时非常高,需要375s. 我们具体看下Item_func_in代码执行逻辑
- 判断是否可以二分查找,如可以in list转成有序数组
- 如果产生了有序数组,则尝试二分查找
- 否则,线性scan,逐一判断左表达式是否等于IN-list里面的item 可以看到内部已经是非常优的了,这个算子基本没有优化空间了。但奈何外层一个扫全表的大loop不可避免。
其实熟悉mysql的同学可能知道,少量的IN-List,mysql会处理成Range Scan的扫描方式,但如果In-List集合比较大,大概率会退化到全表扫描。 上面的badcase就是因为range_optimizer_max_mem_size触发了上限导致无法走range优化只能进行全表扫描,性能急剧恶化,另外即使可以做range optimizer,如果in value过多超过eq_range_index_dive_limit限制,导致无法走index dive而只能走索引统计信息,而大量value所对应的只有NDV这样一个简单的统计值,很有可能出现估算不准确的情况,导致性能回退
polardb
polardb解决问题的思路是对该sql做查询变换, 把IN-list转变成一张物化表,加入join list,具体变换过程如下
step1-转成in子查询,上述sql改写为
select ... from lineitem where l_partkey in (...)
====>
select ... from lineitem where l_partkey in
(select dt._col_1 from (values (9628136),(19958441),...) dt)
其实PolarDB会在query-block tree上再挂载一个新的query-block,这个query block作用就是输出临时表所有的常量值。上面的IN-list常量值都会物化到这张临时表里面了。 PolarDB里面会创建SELECT_LEX_UNIT及SELECT_LEX,Derived TABLE_LIST等对象来完成上面的转换,但这些知识点太过小众,不深入内核不会有太多感官,略过不表了。
step2-SubQuery Unnest-消除子查询
子查询已经是非相关的,通过子查询消除技术,可以转化为semi-join。物化表经过去重(IN-List重复值可以消除),并且join列非空,进而可以转化为inner-join. sql改写为:
====>
select ... from lineitem, (values (9628136),(19958441),...) dt) where l_partkey = dt._col_1
通过这种变换能到得如下好处:
- 不用逐条去做filter,因为火山模型,有大量虚函数开销其实空转了。
- join有join buffer,其实可以一个batch一个batch的join
- 转成join list,join的优化太多了,如join order&access path,优化手段丰富。
- 如果是Not IN-list, 同样的方式转成Not in子查询后,我们重新做function dependency推导,如果外表上该查找列非空的话,我们可以将Not In子查询转换为anti-join,这样得到了进一步消除了子查询
最后执行的plan如下:
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join
-> Table scan on dt
-> Materialize with deduplication
-> scan on in-list: 100000 rows
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=dt._col_1), with index condition: (lineitem.L_PARTKEY = dt._col_1) (cost=7.34 rows=29)
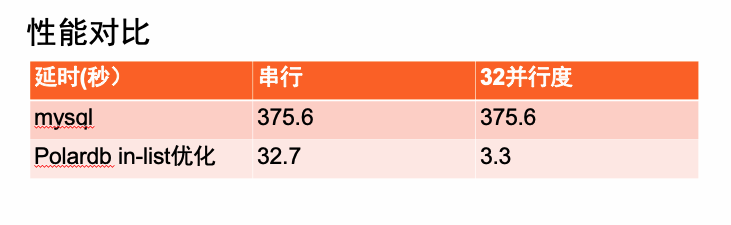
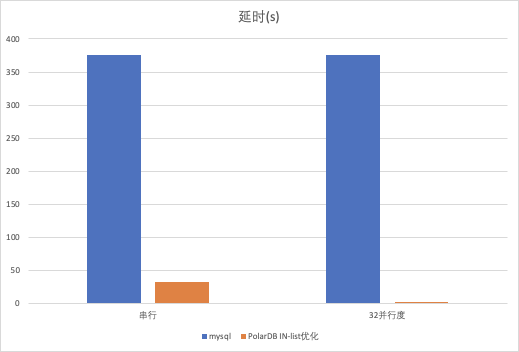
物化小表在前,并且成功利用上了lineitem的索引,只要扫10w条物化表记录,然后再ref查找即可。整条sql执行下来只需要32s, 加上PolarDB原生的并行技术,32线程可以加速到3s。
执行期-零拷贝技术
IN-List如果数据比较多,也是会占用大量内存的,并且对于延时敏感的业务,多余的内存拷贝也是不可接受的。实际上我们在内存中用一段连续的数组空间存放这些in-list常量值,整个内存里面只有一份,在并行查询场景即便开启了多线程查询,因为IN-List是只读,不会改变的,多个线程同时访问一份数据也是安全的。相反每个线程访问这个全局in-list数组时,会分别创建各自的游标,用于记录当前访问到数组的哪个位置。各线程互不干扰,从而能做到线程安全。整个执行期间只有in-list写入物化表的一次拷贝,再无额外拷贝。
测试效果
Polardb in-list优化后在tpch100G数据集上比原生方式提升11.5倍,又因为Polardb天生就是支持并行的,32并行度模式下提升上百倍。
竞品比较
我们注意到mariadb也有类似的优化,不过我们做的优于mariadb,主要体现在如下两点
- 我们IN子查询解相关,semi-join可以继续优化成inner join,mariadb只能优化成semi-join
- 我们的Not IN-List,会尽量优化成anti-join解子查询, mariadb只能转成not in 子查询,没解子查询的话,执行代价是非常高的。
总结
原理上讲polardb 做完IN-list to Join-list后,能得到如下俩方面提升
- IN-list 里面的常量都经过物化去重,基数可能会有不小的下降,这取决于重复值。
- IN-list表达式消去,变成了一张物化表,参与join-list后,有更多access path选择,比如更好的index,更多的join方式hash join 还是nest loop join。
细微之处见真功夫,mysql代码质量不高,模块化奇差,变形需要适配各种协议,比如适配prepare statement协议,在PolarDB上需要适配并行协议,一个看似不大的查询变换就需要大量的工作,polardb能做到各个特性均遥遥领先aws auraro,离不开背后众多工程师的踏实工作. IN-List优化新特性将在PolarDB for MySQL 8.0.2.2.10版本开始支持,欢迎大家使用。