PolarDB MySQL · 功能特性 · 大表扫描优化
Author: 勉仁
背景
社区MySQL从5.1开始引入了插件式引擎体系结构,该结构MySQL的引擎非常便于扩展,使用户可以选择合适的存储引擎。但同时MySQL SQL层和引擎层的紧密融合的优化相对现代数据库则少很多,对于用户需要处理越来越多数据的场景需求,相关的优化缺失导致很多场景下性能成为瓶颈。为了能够加速用户查询,充分融合SQL层和引擎层的特性,PolarDB MySQL做了一系列将计算从SQL层下推到引擎的优化。本篇介绍其中的扫描完全下推。对于事务引擎InnoDB,社区MySQL最初在计算行数COUNT(*)操作的时候,是引擎逐行访问,然后SQL层计数。社区不断优化,最新版本中会基于主键做快速扫描。但其会忽视优化器选择的路径,还有其他实现上的处理可能导致大宽表等场景性能回退。与社区MySQL不同,PolarDB MySQL将扫描行数COUNT(*)完全下推到引擎,使用优化器决定访问路径,极大的提升性能,且避免各类场景的性能回退。同时配合PolarDB MySQL并行执行,在已有数倍的提升基础上,可以进一步获得线性提升。
社区MySQL
社区MySQL在5.7.2版本就曾引入COUNT(*)扫描的优化,将扫描下推的引擎中。但其会忽略优化器选择路径只能选择聚集索引,很多时候相比二级索引反而会慢很多,所以在5.7上又将优化remove掉了。在社区MySQL8.0.14版本,社区再次将COUNT(*)完全下推到引擎中,同时利用社区InnoDB引擎的并行框架实现。但是该实现仍然会忽视优化器的路径,仅使用聚集索引,如下面社区代码(8.0.28)所示。
storage/innobase/handler/ha_innodb.h
int records_from_index(ha_rows *num_rows, uint) override {
/* Force use of cluster index until we implement sec index parallel scan. */
return ha_innobase::records(num_rows);
}
int ha_innobase::records(ha_rows *num_rows) /*!< out: number of rows */
{
...
dict_index_t *index = m_prebuilt->table->first_index();
ut_ad(index->is_clustered());
...
}
这会导致我们EXPLAIN看到的执行计划选择的路径和引擎真实执行的路径是不一致的,同时二级索引的不支持会导致宽表场景性能可能下降。
mysql> EXPLAIN SELECT COUNT(*) FROM lineitem\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: index
possible_keys: NULL
key: i_l_shipdate
key_len: 4
ref: NULL
rows: 59409015
filtered: 100.00
Extra: Using index
同时社区在执行parallel count的时候,是不会将数据load到buffer pool中的,如提给社区这个performance bug所述 https://bugs.mysql.com/bug.php?id=99717 。这一点有利有弊,好处是避免大量数据读取将buffer pool数据冲刷掉,坏处就是行为和之前不一致,用户多次执行该SQL也不会load到buffer pool中,导致count(*)执行慢。
PolarDB MySQL
在PolarDB MySQL中,我们将COUNT(*)下推到引擎中执行,同时保留了优化器的路径选择。引擎会在所选路径的leaf page上做快速数据行计数扫描,同时会保证隔离级别的可见性。当发生回表、mvcc恢复数据版本时可能持有page锁时间较长,这个时候也会采取措施规避对数据并发更新的影响。
性能优化效果
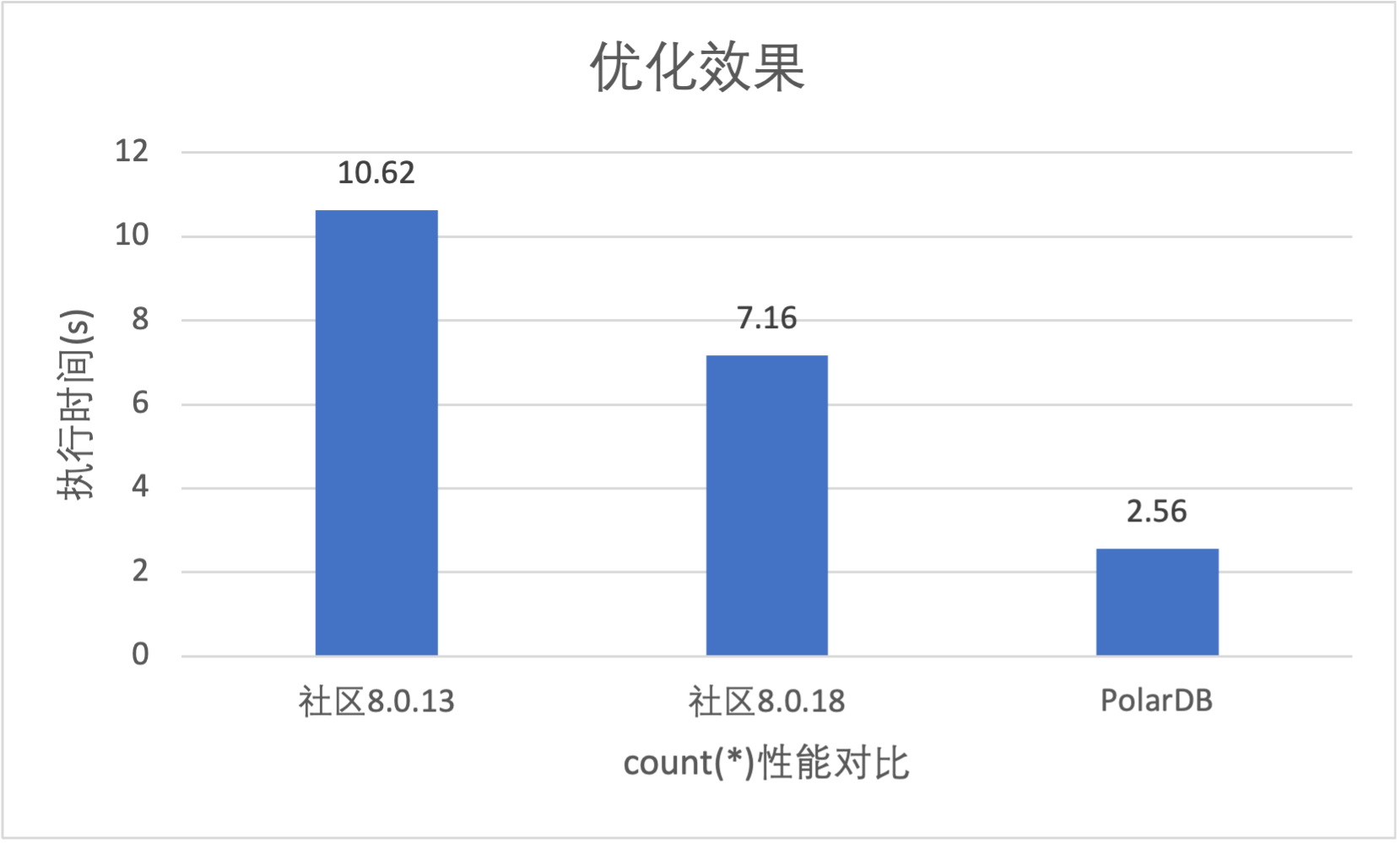
我们基于TPCH 10 scale的数据,测试下面查询PolarDB对比社区8.0.13版本和8.0.18版(innodb_parallel_read_threads为1单线程执行)性能对比如下,分别获得414%和279%的提升。
同时PolarDB MySQL也有并行执行,对比社区innodb parallel执行,会在Server层统计控制资源。配置max_parallel_degree后,还可以进一步获得线性提升。
mysql> EXPLAIN SELECT COUNT(*) FROM lineitem\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: index
possible_keys: NULL
key: i_l_shipdate
key_len: 4
ref: NULL
rows: 59440464
filtered: 100.00
Extra: Using index