PolarDB·引擎特性·PolarDB IMCI中的行列融合执行
Author: gushen
背景
事务处理(OLTP)和分析处理(OLAP)混合的工作负载在当前的业务系统中变得越来越常见。由于实时、易运维等需求,一些业务系统会采用HTAP数据库来代替原有的OLTP-ETL-OLAP架构,所谓的HTAP数据库,可以在一套数据库系统中,同时较为高效地处理TP请求和AP请求。
然而,由于TP请求和AP请求的访问模式截然不同,高效处理两种请求依赖于不同的存储格式和计算模式。因此,一类HTAP数据库会存储两种不同格式的数据,并在处理不同的请求时选择不同的模式对相应数据进行计算。
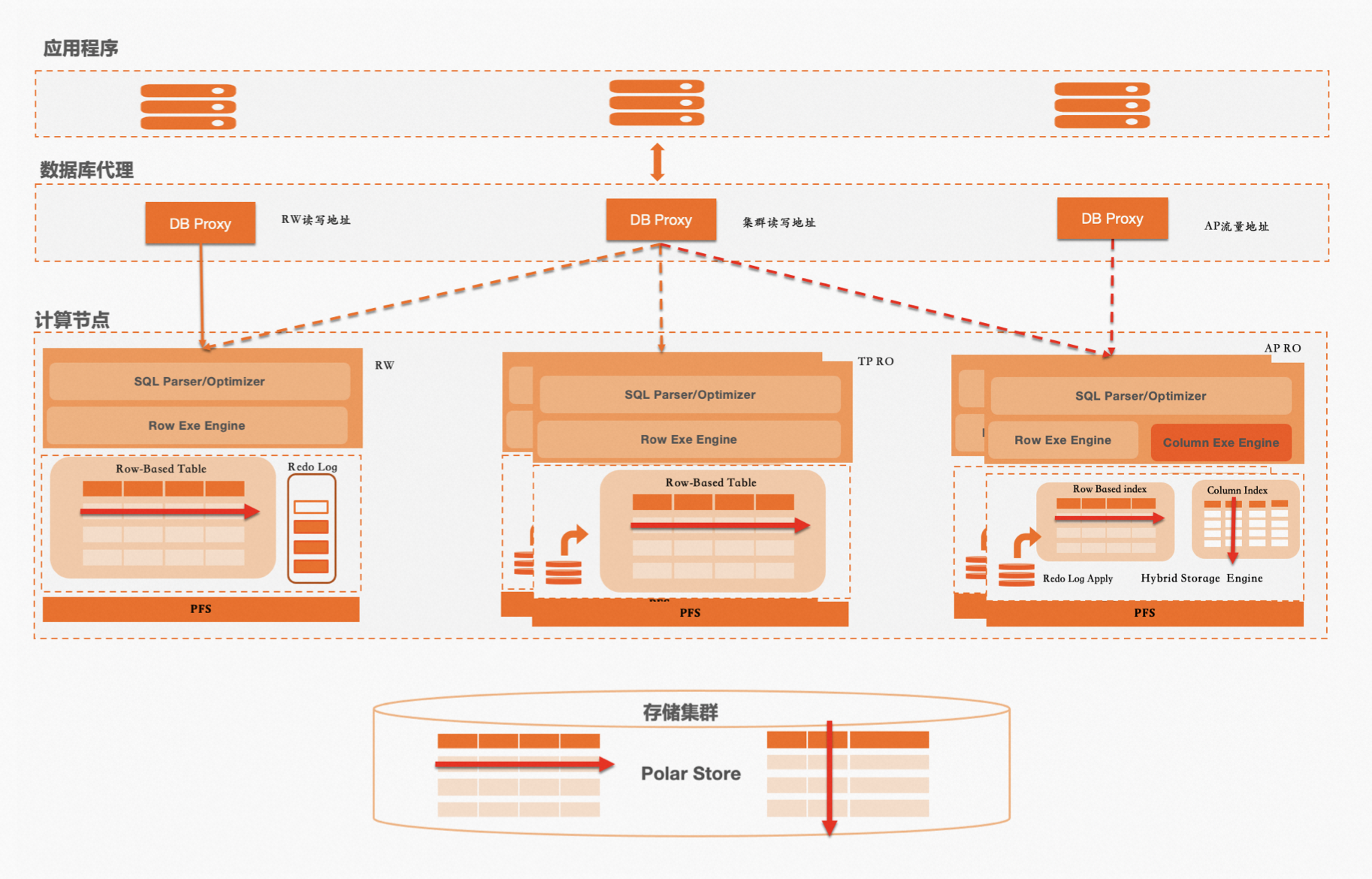 阿里云瑶池旗下的云原生数据库PolarDB也采用了这样的方式来处理混合型的工作负载,开启内存列存索引(In-Memory Column Index,以下简称IMCI)功能的只读节点(RO)会额外维护一份列式索引,并在处理AP请求时采用向量化的方式对列式数据进行计算(列式计算)。而在处理TP请求时依然采用MySQL原有的one-tuple-at-a-time的方式对行式索引的InnoDB数据进行计算(行式计算),列式索引和行式索引都通过物理复制链路回放读写节点(RW)的写入。在这套系统中,处理两种请求的存储、执行器、优化器都彼此独立,TP请求和AP请求在执行路径上完全分离,一条SQL语句要么选择列式计算,或者选择行式计算。
阿里云瑶池旗下的云原生数据库PolarDB也采用了这样的方式来处理混合型的工作负载,开启内存列存索引(In-Memory Column Index,以下简称IMCI)功能的只读节点(RO)会额外维护一份列式索引,并在处理AP请求时采用向量化的方式对列式数据进行计算(列式计算)。而在处理TP请求时依然采用MySQL原有的one-tuple-at-a-time的方式对行式索引的InnoDB数据进行计算(行式计算),列式索引和行式索引都通过物理复制链路回放读写节点(RW)的写入。在这套系统中,处理两种请求的存储、执行器、优化器都彼此独立,TP请求和AP请求在执行路径上完全分离,一条SQL语句要么选择列式计算,或者选择行式计算。
长尾请求问题
从用户的工作负载中,我们观察到,对于混合负载中大部分的请求,“行列分离”的计算方式已经能够以最优的计划执行,然而对于少部分请求,列式计算和行式计算都不是最优的:
- 在大宽表上,对少数列上通过where或join的条件进行过滤,或求top k,最后对筛选出的行,输出所有列的明细。在这样的查询中,table scan或join只涉及很少的列,通过列式计算的方式是最优的,但是project需要获取所有列,列式索引会产生读放大,通过行式计算利用InnoDB主索引查询明细是最优的。
- 执行计划的一个片段是两张大表join(t1 join t2),t1表上where条件的过滤比例很高,且有InnoDB索引,t2表上的join条件没有InnoDB索引,且join条件只涉及少数列。在这样的查询中,通过行式计算走InnoDB索引查询t1表,再通过列式计算扫描t2表进行hash join是最优的。(当然此情况下,列式索引上t1表的data skipping足够准确,也可以使用纯列式计算)
- 仍然是2中的场景,区别是t2表上的join条件有InnoDB索引,此时t1 join t2这个执行片段通过纯行式计算进行index join是最优的,然而,执行计划的其余片段可能通过列式计算的方式是最优的。
为了更高效地处理混合负载中的这部分长尾请求,我们在IMCI的优化器和执行器中,基于两个不同索引,设计并实现了“行列融合”执行架构。本文将介绍云原生数据库PolarDB在“行列融合”执行架构的基础组件(优化器的代价模型,执行器的多引擎访问,存储引擎的日志回放和事务处理)设计,以及针对上述第一种类型的请求所设计的HybridProject算子。通过基础组件,我们可以较为容易的实现HybridIndexScan和HybridIndexJoin来处理上述剩下两种类型的请求。
主要挑战
在一个“行列分离”的系统中实现“行列融合”执行,主要的挑战来自三个方面:
- 优化器代价估计:MySQL优化器和IMCI优化器的代价模型不同,如果直接以MySQL的代价模型计算行式执行片段的代价,再加上以IMCI的代价模型计算列式执行片段的代价,并不能得到整个执行计划的可比较的代价。需要设置统一的CPU和IO代价单位,再根据行列计算的不同算法复杂度和行列索引不同的统计信息计算出可比较的代价。
- 执行器访问不同索引:一套执行器需要同时访问InnoDB和列式索引。MySQL执行器对于一个SQL请求是以单线程的模式执行的,访问InnoDB相关的interface和context也是面向单线程实现的,而IMCI执行器是以单leader+多worker的模式处理一个SQL请求的,那么如果在worker中访问InnoDB就需要一些额外处理。
- 行列索引实现强一致读:列式索引和InnoDB回放RW写入的过程是异步的,两个不同索引的回放redo log的位点可能不一致,并且InnoDB通过基于lsn的read view判断数据可见性,而列式索引通过类似LSM存储引擎的sequence判断数据可见性。在异步回放下,行列索引只能实现最终一致读,而“行列融合”的行式执行片段和列式执行片段可见数据不一致会导致执行结果的错误。
行列融合基础组件
优化器的代价模型
上述三种类型的长尾请求在“行列分离”的执行架构下会基于代价被看作AP请求由IMCI执行,因此我们选择基于IMCI的优化器,引入对行式执行片段的代价估计,从而使这些长尾请求能够选择“行列融合”的执行计划。
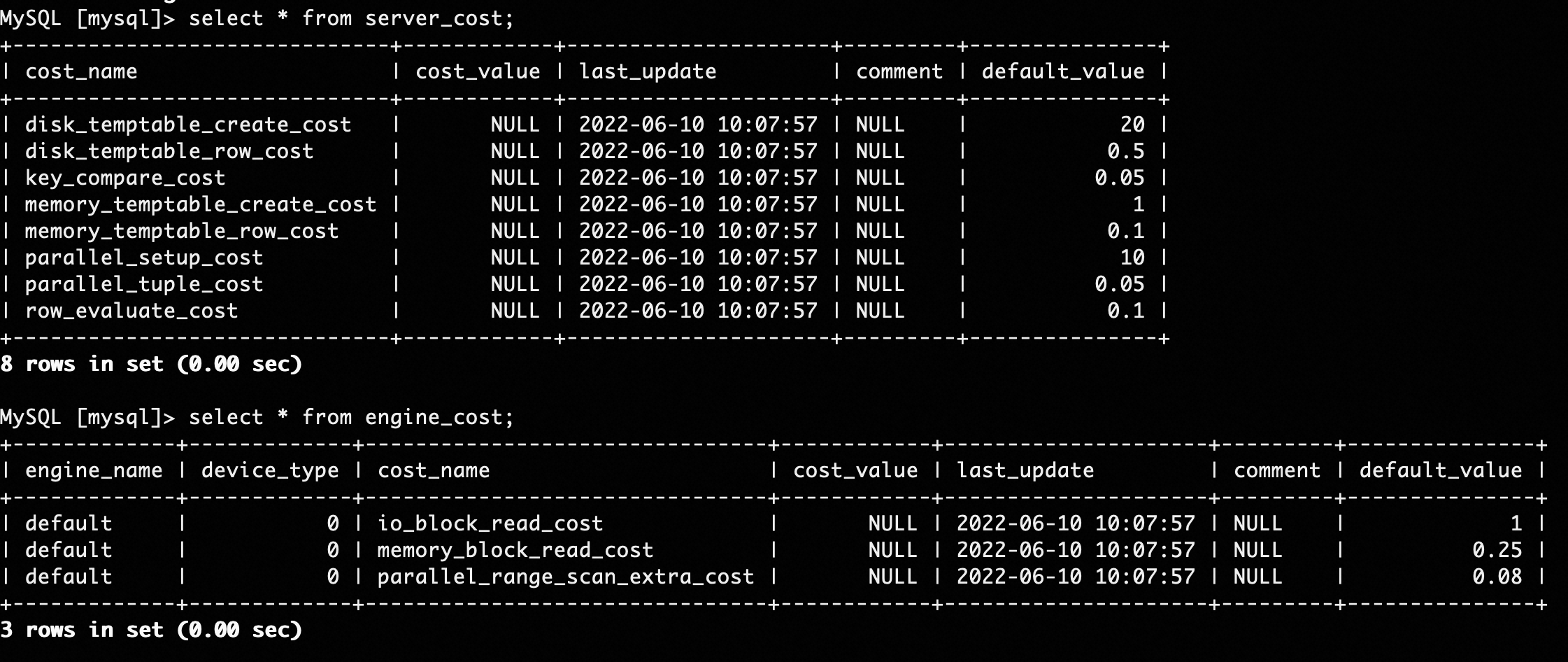 在引入行式执行代价估计的过程中,我们遵循如下两个原则:
在引入行式执行代价估计的过程中,我们遵循如下两个原则: - 对于一个执行片段,相对高估其使用行式执行的代价,相对低估其使用列式执行的代价。因为长尾请求原本会选择纯列式执行,这样的代价估计可以保证当一个长尾请求选择“行列融合”的执行计划时,一定不会比原本的执行计划更差。
- 只参考MySQL优化器的代价常量之间的比例。MySQL优化器的代价常量如上图所示,和IMCI的代价常量具有不同的数量级,因此我们无法直接使用它们的绝对值,但可以参考它们之间的比例关系。
基于上述原则,我们采用如下设计:
- 在IMCI优化器中,InnoDB的io_block_read_cost和列式索引的pack io cost相同。虽然InnoDB一个page是16KB,而列式索引的pack是65536行,比16KB更大,但基于第一个原则,且考虑PolarFS并发下发请求和条带打散粒度,我们设置相同的io代价常量。
- 基于第二个原则,memory_block_read_cost和row_evaluate_cost保持相同比例。基于第一个原则,且考虑向量化执行,row_evaluate_cost要比IMCI的cpu常量要大。
根据上述可比较的代价常量,我们就可以基于MySQL和IMCI各自的算法和统计信息,计算出“行列融合”执行计划的可比较代价。
执行器的多引擎访问
IMCI优化器对长尾请求选择“行列融合”的执行计划后,我们通过在IMCI执行器中引入新的Hybrid算子来计算行式执行片段。
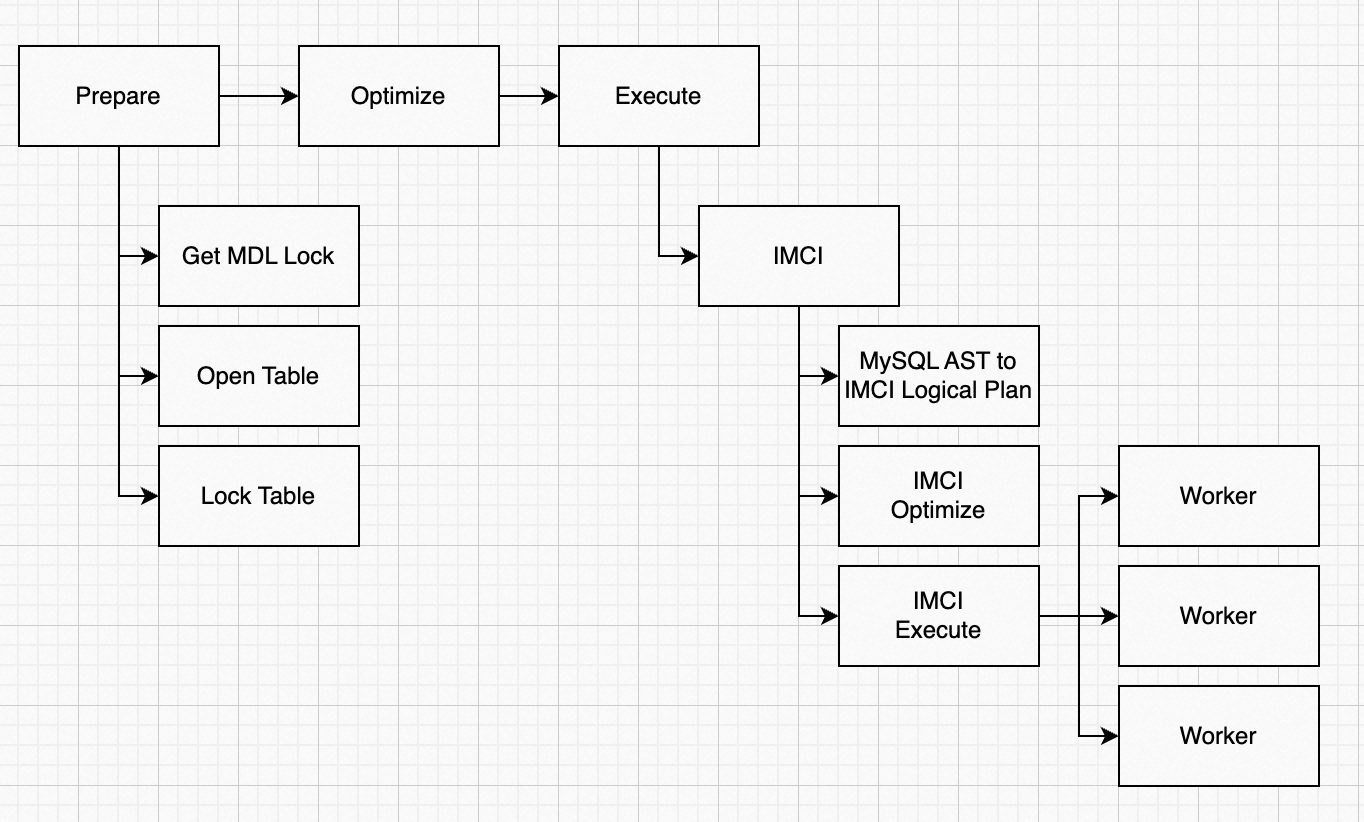 新的Hybrid算子需要在IMCI执行器中访问InnoDB,我们参考MySQL的Server层的实现,通过TABLE对象中的handler来和存储引擎交互。从上图的执行流程可见,虽然Prepare阶段已经Open Table,但相关对象和接口都是面向MySQL单线程执行实现的,因此在IMCI执行器的worker中,需要再次Open Table,并克隆或引用相关对象。这部分主要难度在于兼容MySQL逻辑的工程复杂度。
新的Hybrid算子需要在IMCI执行器中访问InnoDB,我们参考MySQL的Server层的实现,通过TABLE对象中的handler来和存储引擎交互。从上图的执行流程可见,虽然Prepare阶段已经Open Table,但相关对象和接口都是面向MySQL单线程执行实现的,因此在IMCI执行器的worker中,需要再次Open Table,并克隆或引用相关对象。这部分主要难度在于兼容MySQL逻辑的工程复杂度。
存储引擎的日志回放和事务处理
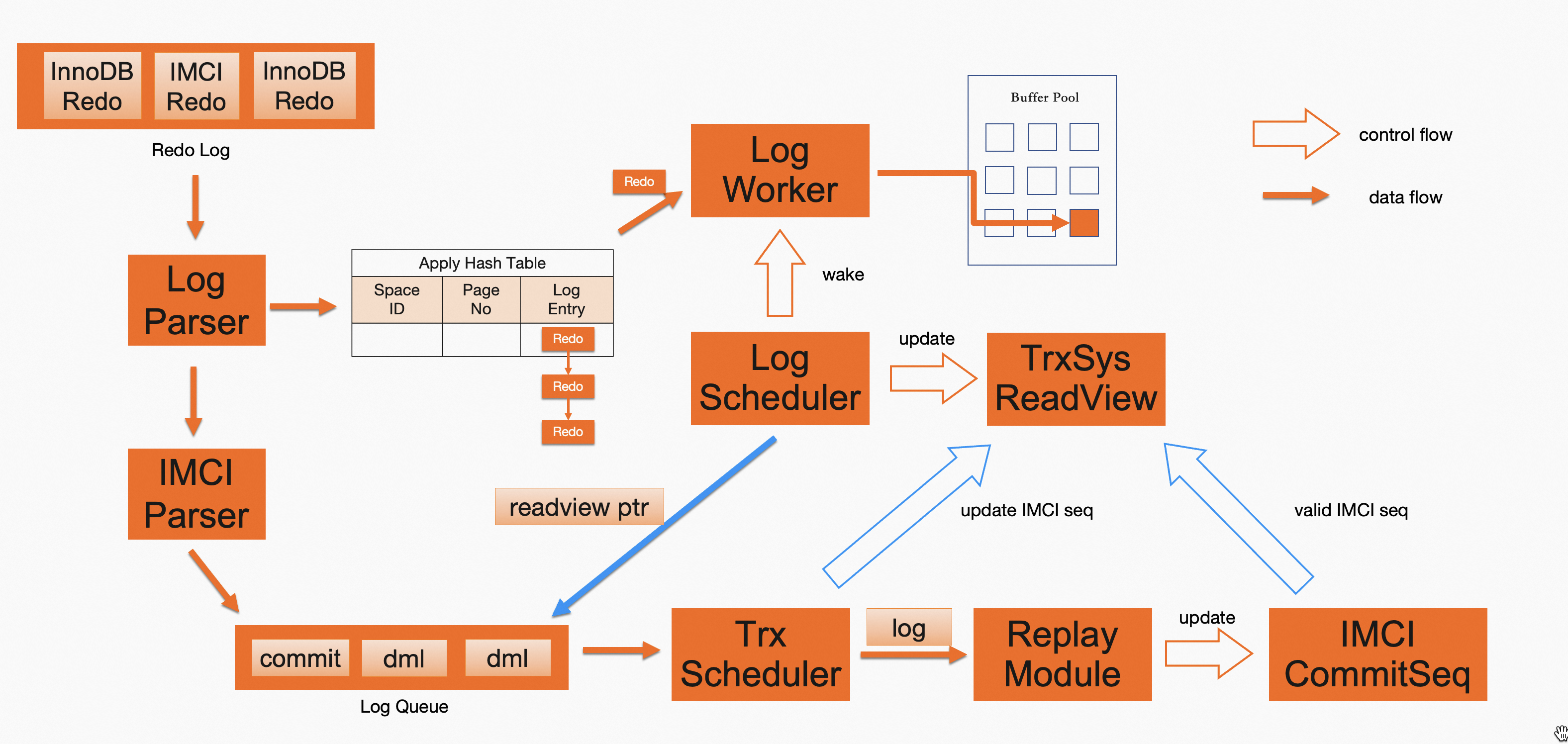 两个不同索引异步回放的流程如上图黄色部分所示,其中InnoDB在回放完成后会更新latest read view,而列式索引在回放完成后会更新列式索引的last commit seq。回放流程每隔一段redo(包含若干条redo log entry)运行一次,一段redo内InnoDB事务和IMCI事务的提交情况是一致的,因此一段redo在两个不同索引上都回放完成后,基于更新的latest read view和last commit seq在两个不同索引上的数据可见性是一致的,我们称上述read view和commit seq为“对应的”。如果查询使用“对应的”read view和commit seq来判断数据可见性,就能实现强一致读。
然而,行列索引的回放流程是异步的,由于回放速度的差异,任意时刻latest read view和last commit seq可能不是“对应的”,这种情况下我们需要找到最近更新的“对应的”read view和commit seq。
为此,我们在异步回放流程中引入上图蓝色部分所示流程:
两个不同索引异步回放的流程如上图黄色部分所示,其中InnoDB在回放完成后会更新latest read view,而列式索引在回放完成后会更新列式索引的last commit seq。回放流程每隔一段redo(包含若干条redo log entry)运行一次,一段redo内InnoDB事务和IMCI事务的提交情况是一致的,因此一段redo在两个不同索引上都回放完成后,基于更新的latest read view和last commit seq在两个不同索引上的数据可见性是一致的,我们称上述read view和commit seq为“对应的”。如果查询使用“对应的”read view和commit seq来判断数据可见性,就能实现强一致读。
然而,行列索引的回放流程是异步的,由于回放速度的差异,任意时刻latest read view和last commit seq可能不是“对应的”,这种情况下我们需要找到最近更新的“对应的”read view和commit seq。
为此,我们在异步回放流程中引入上图蓝色部分所示流程:
- 对于一段redo,InnoDB在更新latest read view后,会在列式索引的Log Queue中添加一个包含当前latest read view的dummy日志对象。
- 列式索引单线程顺序处理Log Queue,先推送常规日志对象到回放模块,并计算该次回放完成后更新的commit seq。接下来处理dummy日志对象,将该commit seq设置到对应的read view上。
- 因为在处理dummy日志对象时,之前的常规日志对象可能还没全部完成回放,因此设置到read view上的commit seq在列式索引上可能尚未生效,回放完成后这个read view和“对应的”commit seq才可以被使用。
引入该流程后,“行列融合”查询会在尚未被purge的read view中,寻找一个“对应的”commit seq已经生效的read view来判断数据可见性。
HybridProject
通过上述基础组件,我们引入了HybridProject来处理第一种长尾case。HybridProject通过primary key从InnoDB的主索引获取完整的行,进行相关表达式的计算后输出。除基础组件提供的能力外,HybridProject需要执行计划中它的孩子算子输出primary key数据,可以通过两种方式实现:
- 优化器支持列裁剪,通过列裁剪使HybridProject的孩子算子只输出primary key数据。
- 强制HybridProject的孩子算子为ComputeScalar,其余执行片段采用延迟物化(如果其余片段采用直接物化,则无需选择“行列融合”的执行计划),ComputeScalar根据延迟物化的执行片段输入的row id,从列式索引上获取primary key输出。
由于目前IMCI优化器还不支持列裁剪,我们采用第二种方式实现。
性能验证
我们在ClickHouse官方提供的OnTime数据集上,验证了“行列融合”执行架构和HybridProject的效果(https://clickhouse.com/docs/en/getting-started/example-datasets/ontime)。 OnTime数据集的表包含110列,是一个典型的大宽表。我们通过如下SQL模拟第一种类型的长尾请求:
select * from ontime order by ArrTime limit 1000;
三种执行计划均为冷启动查询,实验结果如下:
| “行列融合”执行 | 纯列式执行 | 纯行式执行 | |
|---|---|---|---|
| 耗时 | 0.33 sec | 2.56 sec | 232.48 sec |
由实验结果可见,对于混合型工作负载中的长尾请求,通过“行列融合”执行架构和Hybrid算子,PolarDB可以实现最优的性能,相对于纯列式执行或纯行式执行都有数量级的提升。
总结
“行列融合”执行架构可以选择更优的执行计划来处理混合型工作负载中的长尾请求。我们未来将基于此架构引入HybridIndexScan和HybridIndexJoin算子,全面提升长尾请求的性能。