PolarDB MySQL · 功能特性 · Cube, grouping sets功能介绍与实现
Author: 凡绪 热沉
背景
SELECT语句中有一个可选的GROUP BY子句,根据跟在后面的grouping_element,会将所有被选择的行中共享相同分组表达式值的那些行压缩成一个行。如果分组元素中存在GROUPING SETS、ROLLUP或者CUBE,则GROUP BY子句整体上定义了数个独立的分组集。其效果等效于在子查询间构建一个UNION ALL,子查询带有分组集作为他们的GROUP BY子句。
ROLLUP(mysql本身实现)
Group by (a,b,c) with rollup;
表示给定的表达式列表及其所有前缀(包括空列表),等效于:
Group by (a,b,c) union all
Group by (a,b) union all
Group by (a) union all
Group by ();
CUBE
Group by (a,b,c) with cube;
表示给定表达式列表的所有组合,等效于:
Group by (a,b,c) union all
Group by (a,b) union all
Group by (a,c) union all
Group by (b,c) union all
Group by (a) union all
Group by (b) union all
Group by (c) union all
Group by ();
GROUPING SETS
Group by grouping sets((a,b),(b,c),());
表示给定表达式列表的分组,等效于:
Group by (a,b) union all
Group by (b,c) union all
Group by ();
功能介绍
设计一个表,表格式如下:

向表中插入下列数据

我们可以使用下面的语句分组查询总收益:
select year,country,product,sum(profit)
from sales
group by year,country,product;

当我们想知道某一层次的小计时,比如某年某国所有产品的收益,可以使用ROLL UP
select year,country,product,sum(profit)
from sales
group by year,country,product with rollup;

但ROLL UP只展示所选列某个层次,当我们想知道所选列全部组合时,就可以使用CUBE
select year,country,product,sum(profit)
from sales
group by year,country,product with cube;

我们有时也需要自己选择想要查询的列,此时可以使用grouping sets
select year,country, product,sum(profit)
from sales
group by grouping sets ((year,country),(year,product),());

内核实现
语法分析
语法分析主要负责构建语法树结构,创建语法书节点,修改整理传入的变量。
思路为内部每一个括号内都可看作一个group组,一个grouping sets存储了所有的group组。例如对于((a,b),(a,c)),就存在两个group组a b,a c。
group组的结构没有发生变化,所以在进行上下文初始化时,可以将原来的函数进行修改,对所需要的部分循环调用。
语义分析
group数组
在采用group setting方法时,会有多个group组,每个group组中有不同的组合,在语义分析中,会将各个组中的列进行去重存储到同一个数组中,该数组包含了所有group组中不重复的列。例如group setting (a,b),(b,c),则数组结构应包含(a,b,c)。
标识数组
在将group元素进行去重之后,我们需要设计一个标识数组来标记每一个元素属于哪个group组,从而在执行过程中进行正确的group by过程,我们对每一个列都添加了一个标识数组,下标作为组号,值true代表该列属于该group组,false代表该列不属于该group组。
例如:grouping sets (a,b),(b,c),(a,c),则a的标识数组为(1,0,1),b的标识数组为(1,1,0),c的标识数组为(0,1,1)
对于Cube (a,b,c),虽然并没有多组group的概念,但实际运算中,我们可以将其看作是全组合的grouping sets,因此,也需要标识数组来标记元素的group组情况。其中,a的标识数组为(0,0,0,0,1,1,1,1),b的标识数组为(0,0,1,1,0,0,1,1),c的标识数组为=(0,1,0,1,0,1,0,1)。
对于之后提到的grouping列,其标识数组为空,可以通过标识数组是否为空判断是否为grouping列。
优化器
增加group列
在进行cube和grouping sets过程中,会将相应的item置null,用来区分cube null、grouping sets null与原本value的null,需要对原本group数组中的每一个列增加一列进行标识。
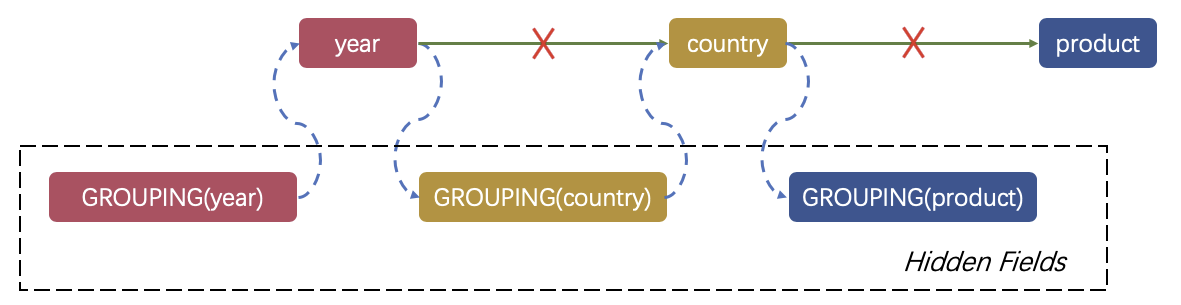
如图,对于原本的group数组(year,country,product),将其扩充为(grouping(year),year,grouping(country),country,grouping(product),product),其中的grouping列用于标识该group列是否为cube null或者grouping sets null,其值为0代表原始列,值为1代表cube null或grouping sets null。
group组数
在优化过程中,我们会统计group组的数量,用于在执行过程中进行相应次数的group by,grouping sets过程的group组数我们在语法分析过程中可以直接获取,而cube过程的group组数则为组合数,也就是2^n,n代表group列的数量。
填充cube的标记数组
在进行cube过程中,会进行两个步骤:
(1)计算group组数的数值,也就是2^n,n代表group列的数量。
(2)给每个group数组中的列添加标记数组,由于cube是所有列的全组合,采用二进制判断相应位数是否为0的算法进行赋值。
优化器执行计划
在优化过程中,优化器会尝试对group by进行优化,会使用sort或者loose index scan的方法来代替临时表的方法,对于rollup统计方法,由于其group组是相互包含,可以采用排序的方式,而在目前的cube和grouping sets方法中,必须使用use temporary的方法。
执行器
执行通过相应的执行器进行执行,cube、groupingsets均采用临时表聚合的执行器进行执行,在初始化过程中完成临时表的填充,最后通过读临时表的方式返回统计结果。
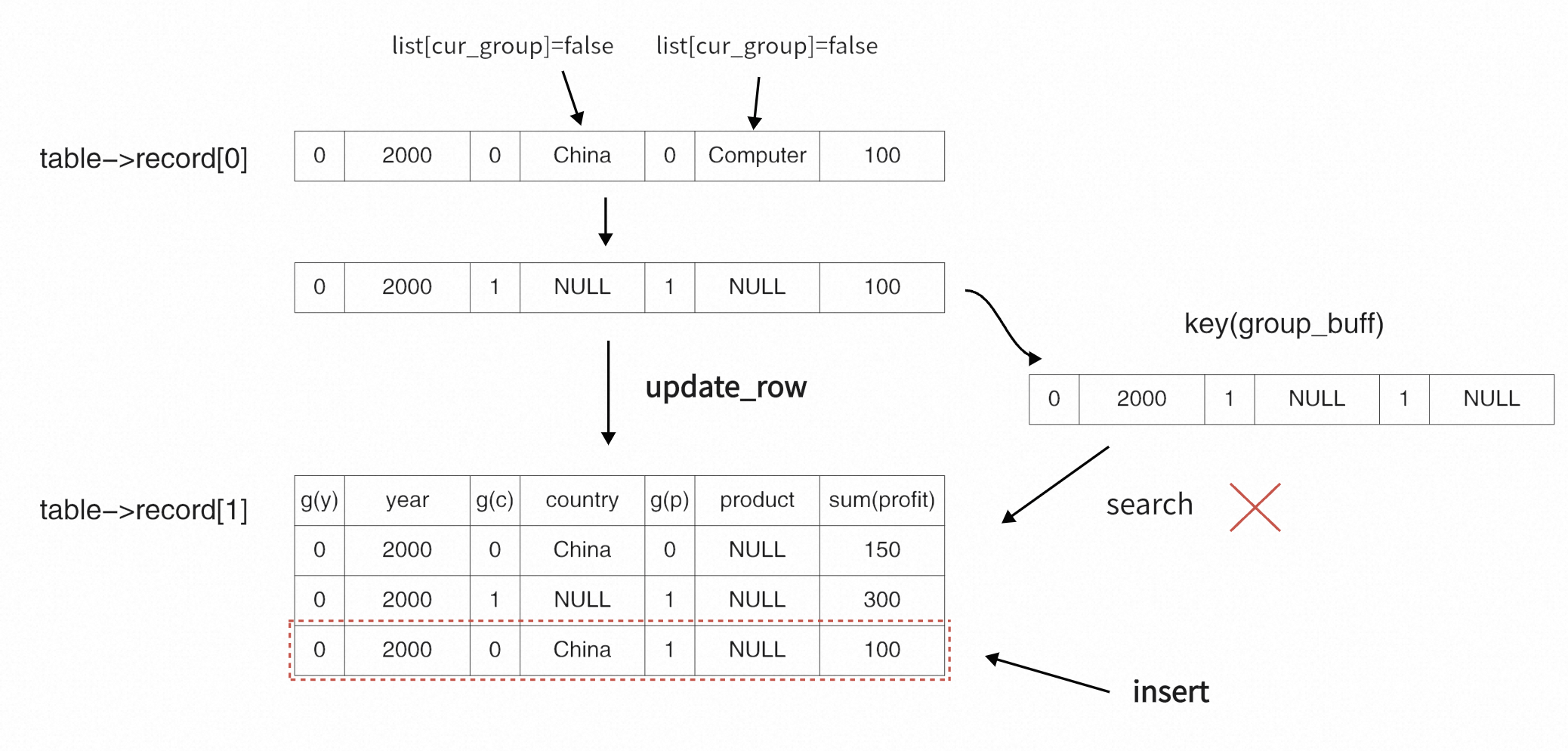
在初始化临时表过程中,每次读入一条数据,根据记录的group数组个数(每个数组代表一个group by),进行相应次数的循环,每次循环进行以下操作:
首先,将当前的数据拷贝到内存提供的地址中(因为后续会将部分item置null,所以每次循环都要重新拷贝当前数据)。
循环group数组中的每一列,在每次循环中,根据当前的group组数,检查标记数组是否为true,若包含,将当前group列的item_field加入到key,相应的grouping列值为0;若不属于当前group组,将当前数据的相应item置null,并将相应的grouping列置为1,加入到key;
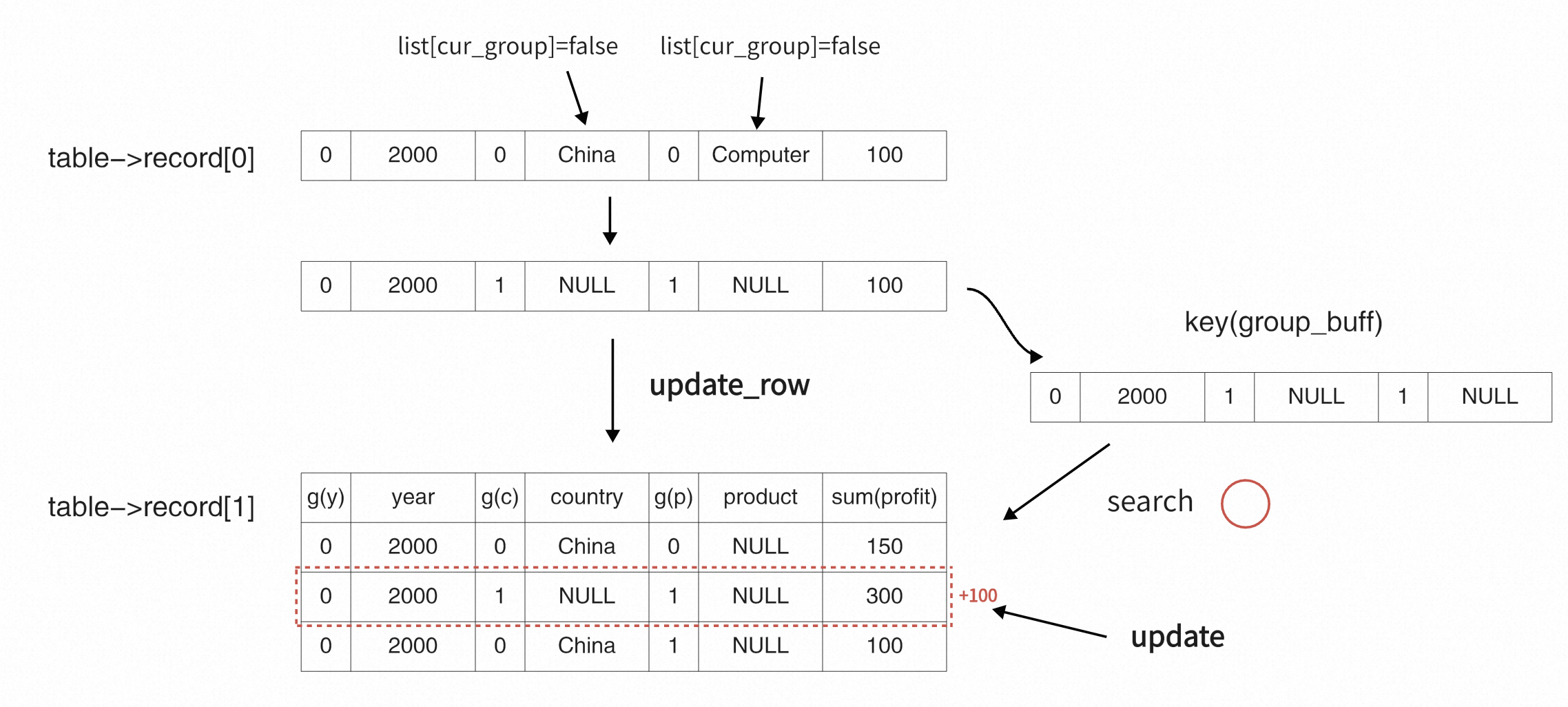
完成所有group的循环后,使用key检索临时表,若没找到当前group的row,则需要插入当前这条数据,此时需要将当前数据修改为key的状态,然后将其插入临时表。
若在临时表中匹配到了当前数组,则更新聚合函数和临时表,进入下一个循环。
总结
rollup、cube以及grouping sets是数据仓库较为常见的三种统计功能,在MYSQL过往的版本更新中,一直没有支持cube和grouping sets的功能,而在PolarDB MySQL中,我们进行了功能的补全,以支持更加广泛的olap场景。