PolarDB MySQL - InnoDB冷数据表OSS归档
Author: 缪哲语(蛰语)
背景
对于某些数据库用户会存在如下类似的案例场景:随着时间或业务的变迁,数据库中部分数据的访问频次下降,成为低频访问的冷数据,比如归档历史相关数据, 但是仍存在(潜在的)在线访问需求。若仍保持原有的存储模式,则无可避免的维持了较高的存储成本;若将数据迁移至另外一套冷系统存储中,则需要额外的迁移代价且需要兼容并维护多套存储系统。
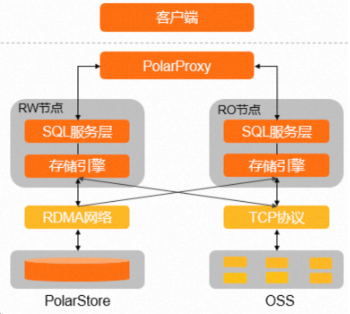
对于云数据库来说,在云端有对象存储和块存储两种主流可选服务。在底层硬件上,由于用户期望块存储提供低延时的块级数据随机访问能力,因此能够发现云服务厂商在块存储服务中提供更高性能的网络和存储,如RDMA网络和高性能NVMe SSD盘;而对于对象存储,云服务厂商更多的是采用标准网络及HDD盘。在软件接口方面,使用块存储时需要关联计算和存储(mount),且需要挂载文件系统提供(往往是支持POSIX语义)文件接口,这里就会分为两类:本地文件系统和分布式文件系统,搭建本地文件系统的服务通常同一时间只能挂载到单个计算节点上,而搭建分布式文件系统的服务可以挂载到多个计算节点;而对象存储直接面向最终用户,可直接当成云网盘来访问且具备原子性,天然支持多用户并发访问。由于前述的使用功能差异,两者在软件栈深度上也完全不同,对象存储具有更高的用户访问兼容性但同时也有更长的软件处理栈,而块存储服务则会尽量将软件栈做浅以实现更高的访问效率。总的来说,两者都具有高可用、弹性存储等能力,但对象存储服务更匹配低成本、低频率或延时不敏感、大I/O的数据应用,块存储服务则更适合高性能、延时敏感、高IOPS的数据应用。
为了能够更好的使用多样化的云原生存储服务,我们在原有PolarDB-InnoDB存储引擎中新增内置的OSS存储支持, 使PolarDB支持面向OSS的数据表迁移操作。
使用方式
我们通过InnoDB on OSS功能实现InnoDB存储引擎的冷数据表归档能力,该方案是在InnoDB存储引擎下使用OSS,而不用修改表所在的引擎。仅通过归档语句手动将IBD格式文件的存储位置从块存储PolarStore迁移至对象OSS。归档完成后,PolarStore中的这部分数据会被自动删除,存储费用会随存储空间容量的降低而减少。归档至OSS的IBD文件仍具有DML能力及原有索引结构。
当表中的数据为冷数据且对延时不敏感,或访问集中可被缓存且尾访问延迟不敏感时,可以通过DDL语句将PolarStore块存储表转换为OSS对象存储表;类似的可以使用DDL语句将数据切回PolarStore块存储模式:
ALTER TABLE table_name STORAGE_TYPE OSS;
ALTER TABLE table_name STORAGE_TYPE NULL;
执行冷数据归档的过程中,正在归档中的表数据将被锁定。OSS归档后的表能正常执行DML操作,使用方法与存储在InnoDB引擎上的表一致,但出于性能考虑无法执行DDL操作。
技术实现
I/O定向及元数据维护 由于表数据存在两种存储方式(PolarStore或OSS),因此需要增加额外的元数据描述符表征数据的存储位置。开启InnoDB on OSS功能后InnoDB的I/O层具有存储定向功能,会依据元数据定向存储目标。OSS二级存储完全内置于PolarDB-InnoDB引擎中,因此复用原有的InoDB相关数据字典和FSP信息,增加额外的持久化信息,保证重启时能正确的识别表的存储方式。引擎在内存中构建了相应的元信息内存结构以加速访问,其在启动时通过持久化的元数据构建,在执行时相应DDL语句进行内存和持久化数据的修改。
OSS访问及存储模式 OSS对象存储的访问特性与块存储完全不同,它支持单对象的增删查及尾追加,但不支持部分修改。对于OSS来说,64KB以下对象占用64KB对象传输模式(包括访问费用),这与InnoDB原生页IO模式通常为16KB并且走文件系统接口的特性不兼容,需要改造InnoDB支持相应接口,并依据存储定向目标选择接口。默认OSS对象大小为1MB(可配置),在进行DDL将数据切换到OSS上时,会先将数据表在BP中的残留页刷脏,然后对目标表分片进行多线程拷贝任务,每个工作线程进行大IO文件读取并写入OSS目标。对OSS上的表数据进行修改时,需要完整写入一个OSS对象大小,因此存在写放大问题。进行读取时接口支持限定范围读,即比如读取一个1MB对象中的某16KB。
DDL原子性实现 InnoDB on OSS使用MySQL8.0的原子DDL特性,Server Layer以及Storage Engine使用同一份数据字典来存储元数据,通过新增OSS切换相关的DDL LOG类型实现存储种类切换语句的原子性。
一写多读架构支持 PolarDB采用基于share storage的一写多读架构,通过物理复制方案实现RW节点和RO节点的同步。我们同样是通过物理复制实现在一写多读架构上支持存储切换能力。在进行相应DDL操作时,RW节点将相应的OSS元数据维护日志写入share storage,RO节点应用相应日志更新内存元信息。同时,在HA过程中结合DDL LOG及元数据实现HA操作正确性。
性能优化
InnoDB on OSS性能优化主要包括迁移DDL语句优化和,on OSS情况下的DML性能优化。
对于迁移操作,实际上就是mysql的原子DDL操作,目前我们采用的是parallel DDL来实现迁移性能的提升,InnoDB层通过主DDL线程作为coordnater将目标IBD分片,下发至临时建立的多个OSS迁移任务线程来提升迁移任务吞吐。
对于on OSS情况下的DML性能,主要是表数据I/O受影响(Redo文件仍在块存储上): 1、buffer pool miss情况下的page read时延增加; 2、flush page时的page write时延增加。 对于前者,我们主要采用本地SSD扩展buffer pool(ebp)和逻辑预读(logical read)来尽可能减少高延时page read直接出现在用户访问路径上;对于后者,由于刷脏本身是后台操作,我们主要采用无锁刷脏(shadown page)来避免刷写page时持有page sx-lock。
对于BP内数据高频暂态或低频写入(更新):不存在cache miss,暂态下主要影响写入性能的是WAL的落盘,oss场景和poalrstore场景一致,优化后两者性能接近;
对于BP内数据持续高频写入(更新):持续写入情况下,WAL不断快速写入(redo位于poalrstore上),checkpoint的推进相对缓慢(表文件位于oss上),redo不断堆积增加,两端差距不断增加,因为DB限制两者lsn的差距(避免redo文件的大量堆积、过长的recovery过程等问题),此时制约性能的变成了OSS的(多线程)刷写,由于存在I/O聚合效果,整体性能中等;
如果访问BP外数据:存在cache miss,使用oss读取数据较慢(时延是块存储的近百倍),因此性能较低。