PolarDB MySQL自适应查询优化-自适应行列路由
Author: 勉仁
背景
自适应优化背景
优化器在生成执行计划的过程中会利用基数和选择率估算的结果做代价计算,从而选择合适的执行计划。而基数和选择率会通过已有的统计信息或部分针对该查询的数据采样信息做估算,同时还存在很多缺乏统计信息的场景,会基于经验值和一些数学假设做估算。而这些信息可能因为采样精度、采样方式,经验值、假设与实际偏差大等原因导致估算非常不准。
以MySQL为例,表的行数和索引列NDV信息会基于已采样的统计信息估算,索引列对常量范围的扫描行数会通过Index dive方式对具体查询做实际采样估算。对于无索引列且没有直方图信息或者列上包含表达式的Filter会基于经验值计算选择率,多个表达式之间会基于条件独立假设计算选择率。
优化器基数、选择率偏差示例如下:
数据准备
set @@cte_max_recursion_depth=10000;
CREATE TABLE t1 AS WITH RECURSIVE t(id, c1, c2, c3, c4, c5) AS (SELECT 1, 1, 1, 1, 1, 1 UNION ALL SELECT id+1, c1+1, c1 % 20, c1 %20, c1 / 100, c1 % 50 FROM t WHERE c1 < 10000) SELECT id, c1, c2, c3, c4, c5 FROM t;
CREATE TABLE t2 AS WITH RECURSIVE t(id, c1, c2, c3, c4) AS (SELECT 1, 1, 1, 1, 1 UNION ALL SELECT id+1, c1+1, c1 % 20, c1 %20, c1 / 5 FROM t WHERE c1 < 10000) SELECT id, c1, c2, c3, c4 FROM t;
alter table t1 add primary key(id);
alter table t1 add index i_c1(c1);
alter table t1 add index i_c4(c4);
alter table t2 add primary key(id);
alter table t2 add index i_c1(c1);
alter table t2 add index i_c4(c4);
查询
-- Q1
mysql> explain select count(*) from t1 where c2 = 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9904
filtered: 10.00
Extra: Using where
-- Q2
mysql> explain select count(*) from t1 where c2 = 1 and c3 = 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9904
filtered: 1.00
Extra: Using where
-- Q3
mysql> explain select * from t1 where c4 = 99 order by c1 limit 1;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: index
possible_keys: i_c4
key: i_c1
key_len: 9
ref: NULL
rows: 99
filtered: 1.01
Extra: Using where
上述查询中MySQL当没有统计信息可以使用时候,会认为列的等值表达式选择率为0.1,多个条件之间的选择率为独立事件,所以Q1 filtered列展示的选择率为10%,而Q2展示的为1%。实际该查询Q1和Q2的选择率都是5.01%。对于Q3,MySQL优化器认为c4 = 99的值是在索引中均匀分布的,i_c1索引扫描几行数据后就可以遇到满足条件的行,所以选择了i_c1的索引避免排序开销。而实际i_c1索引要扫描9851行,而更优的索引i_c4仅需要扫描101行数据。通过审计日志或者PolarDB MySQL的SQL Trace功能可以跟踪查询扫描行数。
自适应行列路由背景
本文主要是讲述自适应查询优化在行列路由中的应用。PolarDB In-Memory Column Index功能为PolarDB带来列式存储以及内存计算能力,让用户可以在一套PolarDB数据库上同时运行TP和AP型混合负载,在保证现有PolarDB优异的OLTP性能的同时,大幅提升PolarDB在大数据量上运行复杂查询的性能。基于查询代价选择合适的执行引擎就非常重要,而前面所述的统计信息不准、缺失会导致查询代价在一些场景难以正确计算。为获得最高效的执行性能,不得不人工介入加入Outline固化执行引擎,而这样运维成本会很高。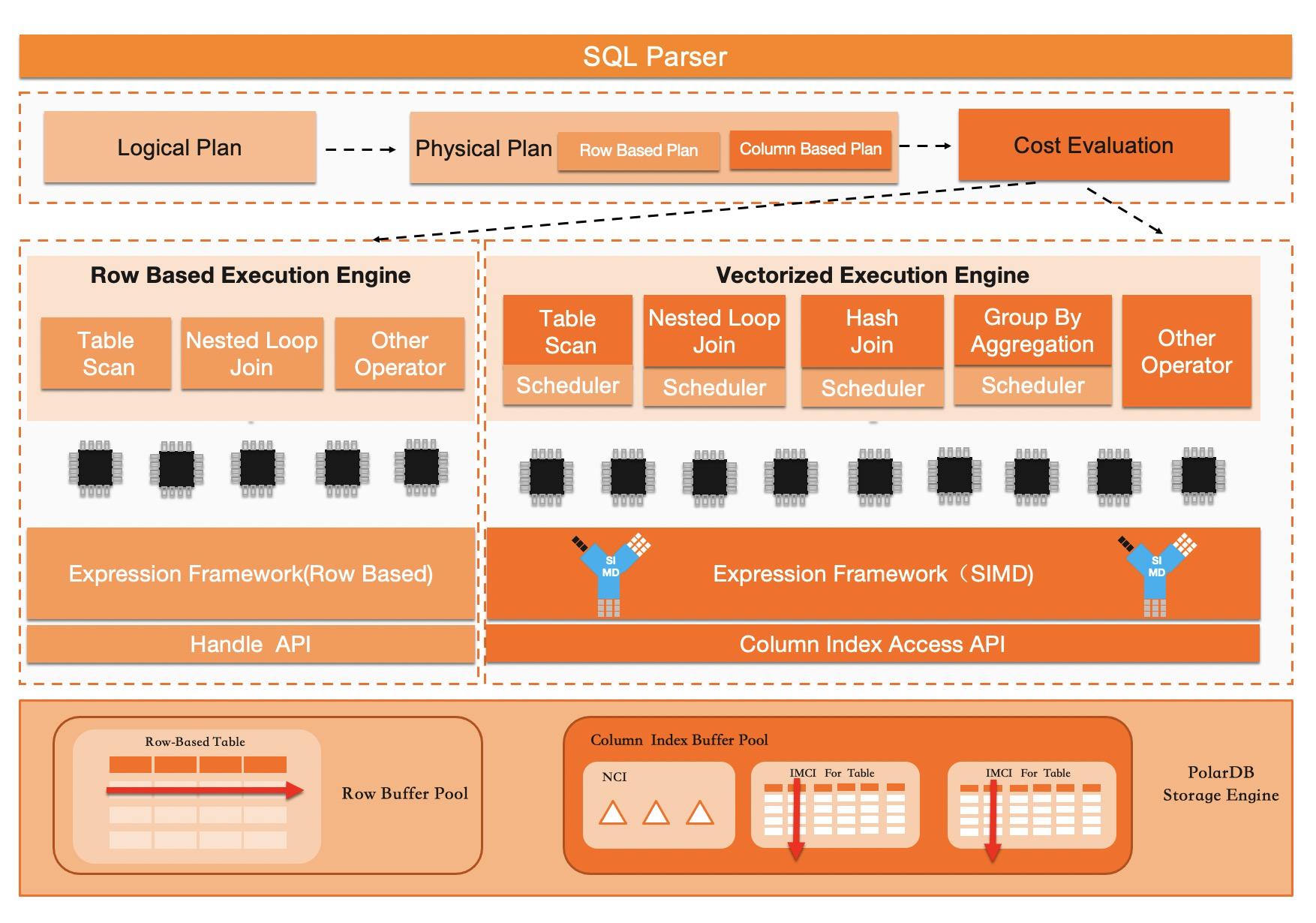
行列路由选择问题示例如下。
数据准备
alter table t1 change column id id int not null auto_increment;
insert into t1 (c1, c2, c3, c4, c5) select c1, c2, c3, c4, c5 from t1;
insert into t1 (c1, c2, c3, c4, c5) select c1, c2, c3, c4, c5 from t1;
insert into t1 (c1, c2, c3, c4, c5) select c1, c2, c3, c4, c5 from t1;
insert into t1 (c1, c2, c3, c4, c5) select c1, c2, c3, c4, c5 from t1;
insert into t1 (c1, c2, c3, c4, c5) select c1, c2, c3, c4, c5 from t1;
insert into t1 (c1, c2, c3, c4, c5) select c1, c2, c3, c4, c5 from t1;
alter table t1 comment 'columnar=1';
查询
-- 这里演示,cost_threshold_for_imci配置为5000,线上默认为50000。
set cost_threshold_for_imci=5000;
-- Q4 选择了行存执行
explain select * from t1 where c5 = 51 order by c4 limit 1;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: index
possible_keys: NULL
key: i_c4
key_len: 9
ref: NULL
rows: 1
filtered: 10.00
Extra: Using where
mysql> show status like "Last_query_cost_for_imci";
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| Last_query_cost_for_imci | 1.009681 |
+--------------------------+----------+
-- 行存执行超过1s
mysql> select * from t1 where c5 = 51 order by c4 limit 1;
Empty set (1.37 sec)
-- 强制列存执行
mysql> set use_imci_engine=forced;
mysql> explain select * from t1 where c5 = 51 order by c4 limit 1;
+----+------------------------+------+---------------------------------------------------------------+
| ID | Operator | Name | Extra Info |
+----+------------------------+------+---------------------------------------------------------------+
| 1 | Select Statement | | IMCI Execution Plan (max_dop = 32, max_query_mem = unlimited) |
| 2 | └─Compute Scalar | | |
| 3 | └─Limit | | Offset=0 Limit=1 |
| 4 | └─Sort | | Sort Key: t1.c4 ASC |
| 5 | └─Table Scan | t1 | Cond: (c5 = 51) |
+----+------------------------+------+---------------------------------------------------------------+
-- Q4列存执行很快结束
mysql> select * from t1 where c5 = 51 order by c4 limit 1;
Empty set (0.00 sec)
优化器对查询Q4选择了行存使用索引i_c4。这样可以利用行存索引序从而避免额外的排序。而优化器不知道c5的数据分布情况,认为扫描很少数据就可以获取满足条件的行。实际上c5 = 51的行不存在,行存需要扫描i_c4索引上的每一行,同时还需要回主表获取c5的值。这就导致行存执行非常慢。而对于列存,仅需要扫描c5列,用列存块内min/max值就可以快速获知没有满足c5=51的行。
基础组件
SQL Sharing是自适应优化的基础组件,存储SQL执行的各类信息包括执行计划、扫描行数、执行时间、物理读、逻辑读等,还有执行反馈的各类信息。整体用无锁HASH结构和细粒度锁控制,具备极好的并发性能,同时内存统一管理,能够动态申请释放,内存占用量小。
除了本文所述的自适应优化,基于SQL Sharing我们已经上线的还有SQL Trace和Auto Plan Cache功能。
SQL Trace能够跟踪执行计划和执行统计信息(包括扫描行数、执行时间等)。
例如下面语句可以统计数据库整体执行时间消耗最大10条SQL模板。
SELECT sql_id,
digest_text,
schema_name,
sum_exec_time / executions,
sum_exec_time,
executions,
sum_rows_examined,
sql_text_sampled
FROM information_schema.sql_sharing
WHERE type = 'sql'
ORDER BY sum_exec_time DESC
LIMIT 10;
SQL Trace功能文档
Auto Plan Cache可以自动监控优化时间占比高的SQL,记录执行计划,重复使用执行计划。
Auto Plan Cache功能文档
自适应执行
面对由于优化器统计信息偏差、假设与实际值不符,导致选择错误执行计划的场景,很多时候优化器很难预先收集对应的信息。对于这类场景自适应执行可以在计划生成阶段收集需要执行时监控的信息选项,在计划生成后,根据整体执行计划对监控的信息选项配置一个阈值。在真实执行阶段,监控信息如果触发该阈值就会重新评审执行计划,根据执行信息选择更合适的执行计划。
在行列路由中,线上客户会查询的行存代价估算低,没有选择列存执行,导致用户查询效率低的场景。对于这类情况,如果直接调低选择列存的代价阈值会导致大量TP查询路由到列存,使列存处理繁忙等待。这就需要对每条出问题的查询模板人工介入加Outline固定执行引擎,而这会大大增加运维压力。
对于行列路由问题,自适应执行会在优化阶段标记将查询中各个Query block和整体的扫描数据行数加入到监控信息中。如果查询在代价计算后没有选择列存,优化器会计算触发自适应执行的阈值。在执行阶段,当query block或整体扫描行数触发自适应执行的阈值,即检查是否切换列存执行。这里扫描行数的监控在核心路径上仅是一个整数比较,并不影响执行性能。同时切换列存前,会保证行存执行的结果集没有返回给客户端。选择切换列存后,会清空已缓存的行存的结果集。

通过自适应执行,错误路由到行存执行的查询会在执行中自动发现路由错误并切换到列存执行。前面行列路由问题的查询Q4会自动切换到列存执行。
mysql> set @@cost_threshold_for_imci=5000;
-- 开启自适应执行
mysql> set adaptive_plans_switch='imci_chosen=on';
-- 优化器选择行存执行
mysql> explain select * from t1 where c5 = 51 order by c4 limit 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: index
possible_keys: NULL
key: i_c4
key_len: 9
ref: NULL
rows: 1
filtered: 10.00
Extra: Using where
-- 执行速度比上文行存快非常多,查询很快返回
mysql> select * from t1 where c5 = 51 order by c4 limit 1;
Empty set (0.01 sec)
-- 查看语句使用了IMCI列存执行
mysql> show status like "Last_stmt_use_imci";
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| Last_stmt_use_imci | TRUE |
+--------------------+-------+
自适应执行已经有大客户使用,在行列路由优化上有非常明显的效果,大大提高了路由准确性,减少了客户慢查。而且客户不需要再手动加Outline固定执行引擎。自适应执行在PolarDB 8.0.1.1.39已经发布,配置adaptive_plans_switch为’imci_chosen=on’即可使用行列自适应执行功能。
执行反馈
自适应执行一方面存在一定的切换开销,另一方面对于复杂查询、复杂的执行计划难以动态切换到合适的执行计划。执行反馈会自动收集查询的执行计划、扫描行数、物理IO、执行时间等信息,当执行信息和计划信息偏差较大,会自动加载到SQL Sharing中。SQL Sharing会对收集的信息做分析和反馈信息拟合。当再次执行该查询,反馈的信息会自动应用到该查询的优化过程中,修正统计信息,帮助生成更优的计划。而且SQL Sharing会持续跟踪该查询的执行,不断修正反馈信息。
在行列路由中,执行反馈会收集各个query block的真实扫描行数、查询真实的执行时间等信息。当再次执行该查询,可以得到更准确的行列代价,从而做合适的行列路由。
PolarDB集群中有多个节点,SQL Sharing会自动将不同节点的执行反馈信息持久化,且在不同节点间同步。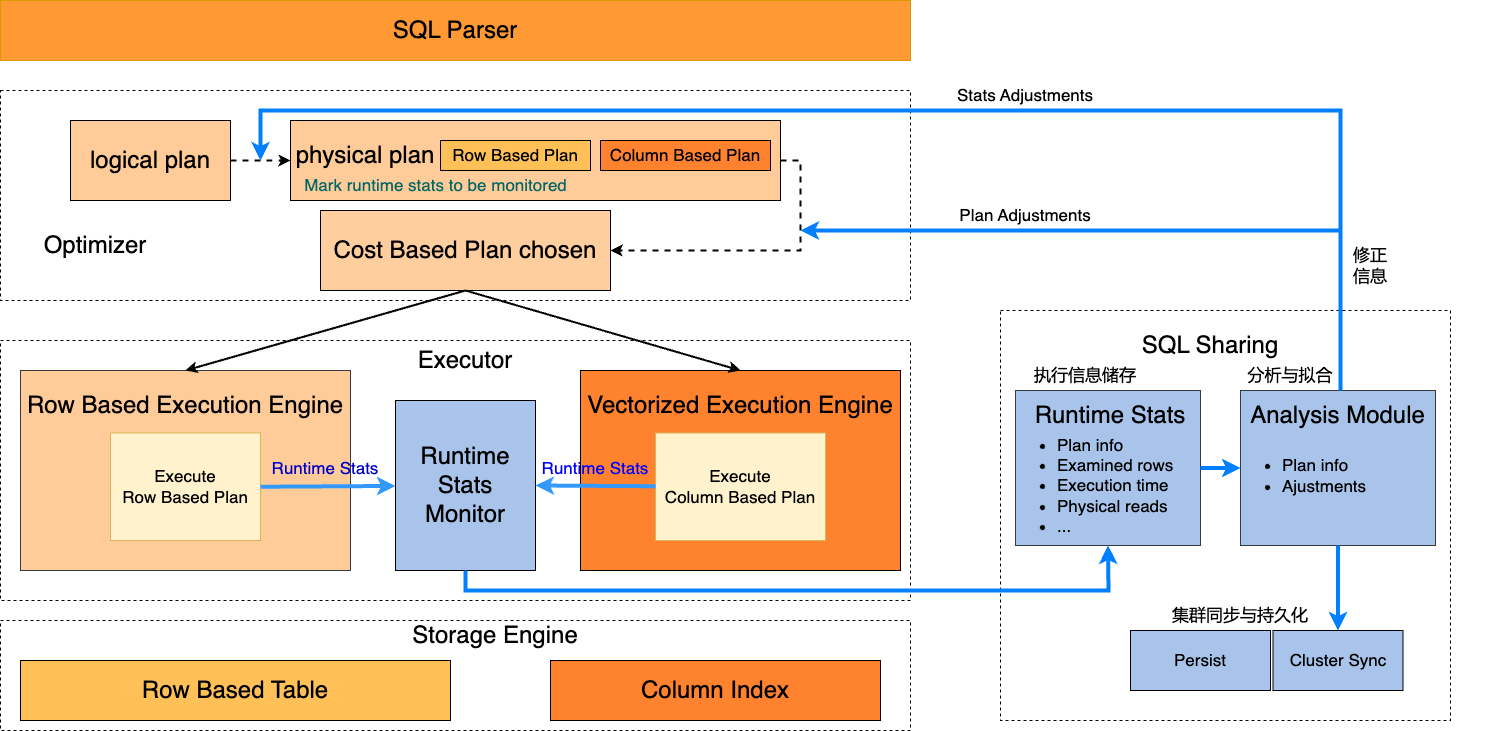
我们可以通过information_schema.sql_sharing查看执行反馈信息。
示例。
下面是行存Query Block扫描行数的反馈信息。
*************************** 7. row ***************************
SQL_ID: 2spu3cs5d6gnx
DIGEST_TEXT: SELECT * FROM `test` . `t1` WHERE `c2` = ? ORDER BY `c1` LIMIT ?
PLAN_ID: NULL
PLAN: NULL
PLAN_EXTRA: NULL
REF_BY: ["STATS_FEEDBACK"]
EXTRA: NULL
*************************** 8. row ***************************
SQL_ID: 2spu3cs5d6gnx
DIGEST_TEXT: NULL
PLAN_ID: 5z81fpq6dgqfc
PLAN: /*+ INDEX(`t1`@`select#1` `i_c1`) */
PLAN_EXTRA: {"access_type":["`t1`:index"]}
REF_BY: ["STATS_FEEDBACK"]
EXTRA: {"STATS_FEEDBACK_INFO:"[[{"type": "qb_cardinality", "basic": 1000.0, "factor": 0.0, "avg_cmp": 1, "select_num": 1, "correlation": 0.0}]]}
下面是列存执行时间的反馈信息。
*************************** 3. row ***************************
SQL_ID: chn9hfsap5ygt
DIGEST_TEXT: SELECT * FROM `t1` WHERE `c2` = ? ORDER BY `c1` LIMIT ?
PLAN_ID: NULL
PLAN_EXTRA: NULL
REF_BY: ["STATS_FEEDBACK"]
EXTRA: NULL
*************************** 4. row ***************************
SQL_ID: chn9hfsap5ygt
DIGEST_TEXT: NULL
PLAN_ID: 5z81fpq6dgqfc
PLAN_EXTRA: {"access_type":["`t1`:index"],"flags":["USE_IMCI"]}
REF_BY: ["STATS_FEEDBACK"]
EXTRA: {"STATS_FEEDBACK_INFO:"[[{"type": "imci_exec_time", "avg_time": 22}]]}
总结
对于优化器中常见的基数、选择率估算偏差很大导致选择错误的执行计划和错误的行列路由问题,PolarDB MySQL正在通过自适应查询优化来完善优化器能力,做到可以自适应的切换到更优执行计划,同时利用真实执行的信息来补充优化器信息修正执行计划。除此之外,PolarDB MySQL也在不断的完善各类统计信息的收集,帮助优化器更准确的选择执行计划。未来更多的功能,敬请期待。