polardb文件元数据多节点一致性同步优化
Author: 照云
polardb一个很大的优势是能够全链路优化,从上层db,到数据文件组织,到io落盘。本文主要内容是,通过从db到分布式文件系统polarfs(下文统一简称pfs)的一体化方案,实现分布式文件系统ro节点文件粒度按需同步元数据,整体提升db ro性能50%的优化实现。
polardb ro节点性能问题分析
polardb一写多读集群ro节点除了在rw节点crash能够快速ha切换以外,还承担线上很大的查询流量,对于文件系统来说,ro节点是以只读形式挂载文件系统的(下文统称ro mount),pfs限制了不允许有任何写操作;
在imci的apro节点和多主集群的master节点上,是以data 读写模式挂载文件系统(data_rw mount),db通过判断io操作是否会产生文件系统元数据变化,来决定操作是在本节点提交还是通过网络转发到集群的rw节点提交,如果是只有文件写操作是可以直接在本地的。
虽然有些不同,不管是ro/apro/master节点都有比较严重的性能问题,这主要体现在io延时高。以一写多读实例为例:
- rw节点ibd文件读写延时:
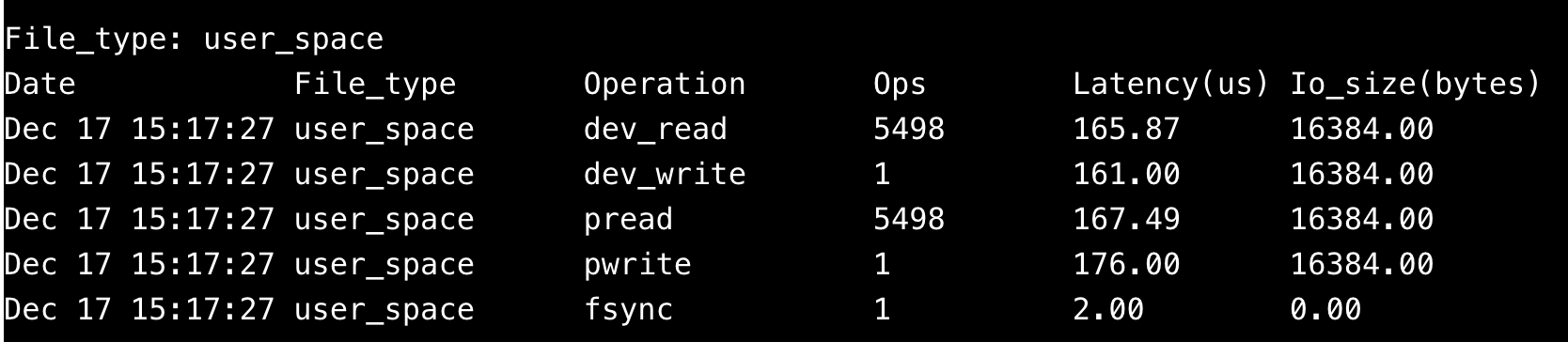
- ro实例ibd文件读写延时:

16k page读上,对比rw/ro上io延时情况,dev_read延时可以近似认为是盘上延时,rw/ro上为165.87u/184.14u,比较接近。但是db侧看到的总io时延rw/ro为167.49u/273.87u,ro上的时延相比rw要高出很多,这也是ro上的性能相比rw低很多的原因。
在标准版实例上,16k page读ro的时延相比rw要高一倍以上,相比polarstore差距更加严重。
我们对rw/ro上的一次pread流程进行对比进行分析:
- ro
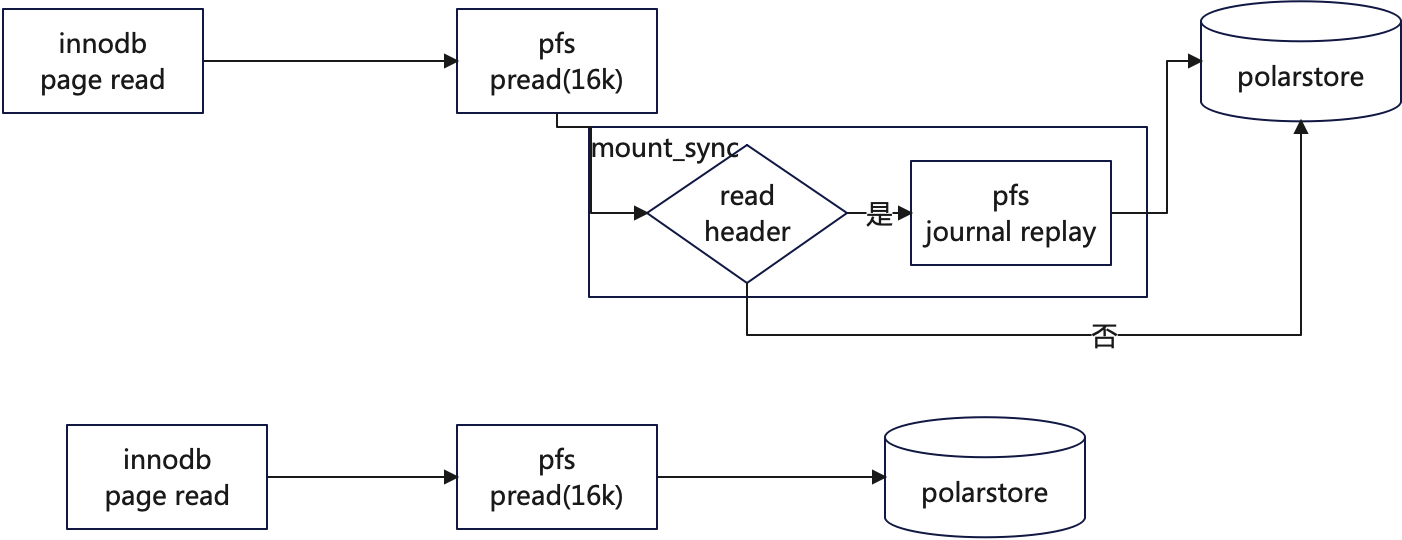
- rw

ro上的耗时主要多了pfs同步元数据(mount_sync),因为在一写多读架构下,ro上实际读取的是一个最新的快照,文件系统的元数据需要通过物理日志回放的方式,同步到ro上。
在imci的apro节点和多主集群的master节点上,除了读io跟普通ro一样以外,情况可能更糟一些: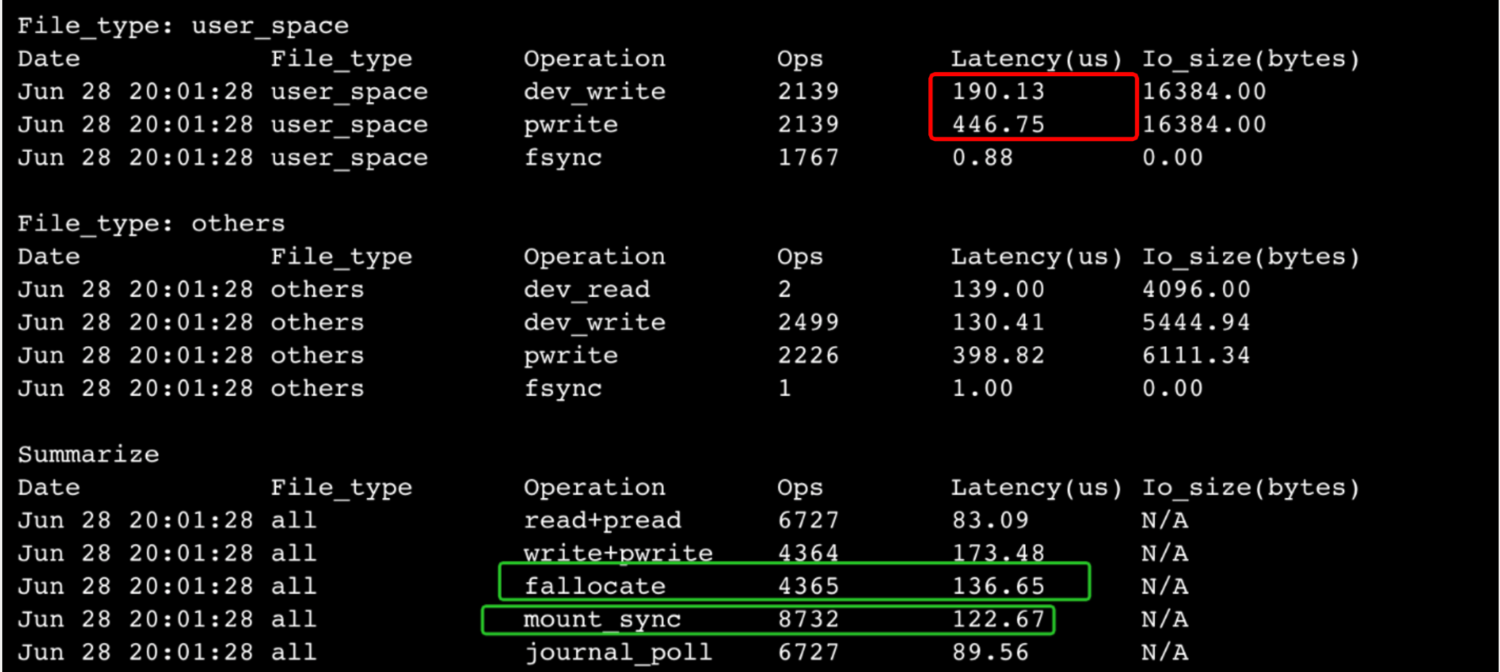
在pfs data_rw mount上有写io,一次写io在当前pfs实现:
pwrite = mount_sync + fallocate + mount_sync + 写盘;
所以与rw节点相比,我们延时高的问题症结在同步元数据(mount_sync)操作上,这主要跟当前文件多写实现机制有关,这里不做更进一步探讨。
pfs文件系统元数据同步
图中的mount_sync操作其实就是对应的pfs ro节点上的元数据同步。元数据是分布式文件系统polarfs用来组织盘上db数据文件的元信息,是常驻db内存的,在一写多读集群场景里,我们当前只允许在rw节点上修改,在ro上通过物理日志的回放来达到最新快照,这样对于分布式文件系统pfs来说,才能在ro上同步到rw的修改。
ro元数据同步
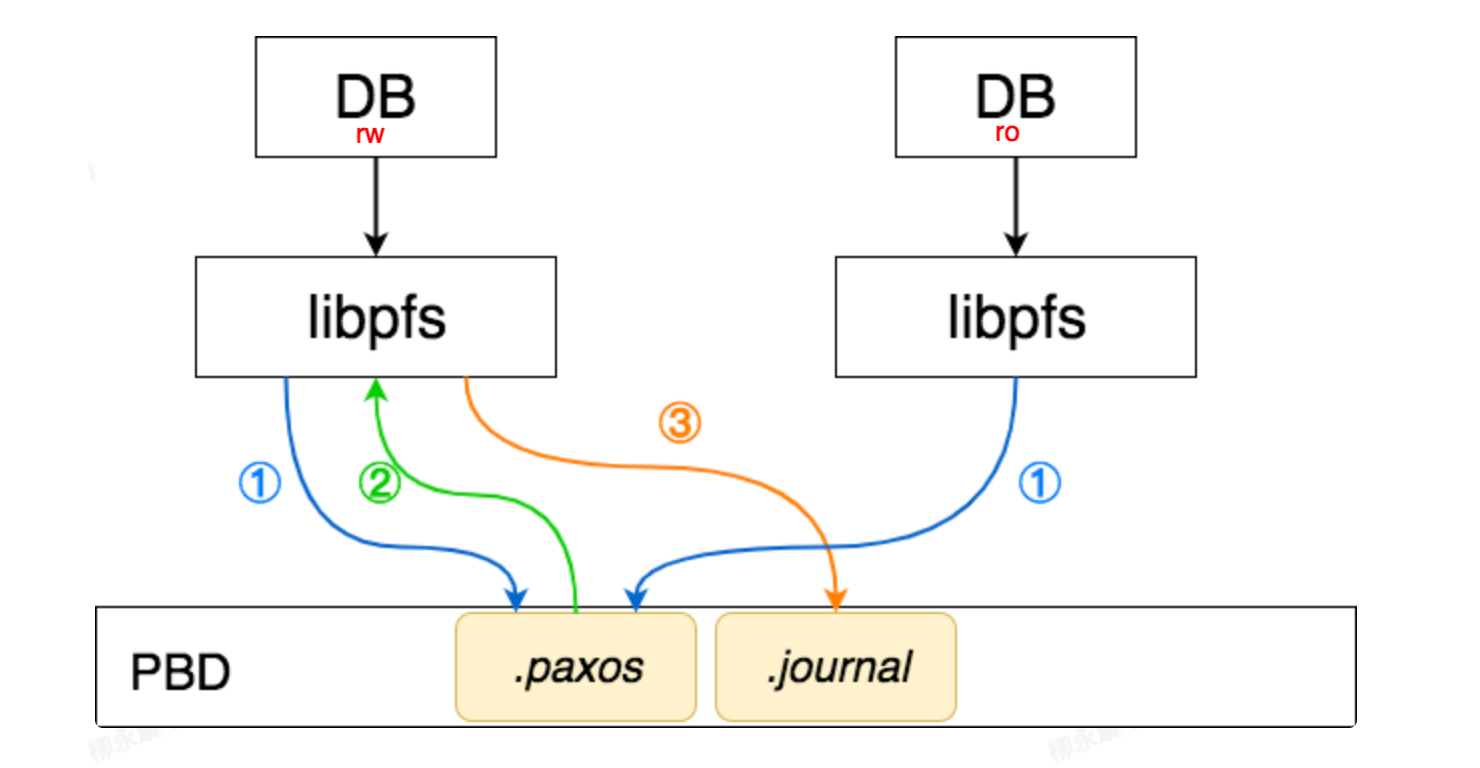
rw上:
第①步
多个PFS实例使用Disk Paxos算法来决定当前由哪个PFS实例可写;
*PFS之间无法相互通信,因此使用Disk Paxos算法来解决并发写冲突。
第②步
Disk Paxos算法选举出的PFS实例获得写权限。
第③步
log模块将写请求封装为log entry,写入journal文件。
*.paxos和.journal文件本质是两个PFS生成的常规PFS文件,初始化PFS时创建。
ro上:
第①步
由于ro目前不知道rw是否有新写元数据变化的日志,所以只能悲观的在每次api调用时,触发同步流程(mount_sync),读盘获取journal的header信息(read_header),记录着最新的jouranl位点,跟本地缓存比对是否有比更新的事务提交)
如果有新的事务log,就读journal文件,加载最新的log_entry,并apply到本地缓存的metaset中(journal_apply)。由于元数据是全量缓存的,这时候能保证所有数据版本一致(但不保证全局最新),io就基于这个最新的快照给用户返回;
pfs在ro上提供快照读语义,主要通过将rw上的修改同步到ro节点上,为了能尽量返回io请求时最新的数据,当前采用的是悲观同步的方式,每次io之前都会调用元数据同步操作,尝试同步rw节点上的最新修改。同样可类比到apro/master节点上。所以相比rw节点,ro上的io请求就多了元数据同步耗时。
元数据按需同步设计
我们分别比对ro节点在rw频繁写元数据时和基本没有元数据变化时的同步耗时(mount_sync):
mount_sync(92.15u) = read_header(63.83u) + journal_apply(19u)
mount_sync(436us) = read_header(74us) + journal_apply(362u)
我们的设计目标有两个:
- 在没有新的journal log提交是,pfs尽量不做元数据同步,减少io链路上读取journal header位点的耗时;
- 在没有当前文件相关的元数据修改时,它上面的io也应该不去做元数据同步,因为正在读的文件没有元数据变化,新增journal可能跟当前的文件无关;
所以实现的方案是,文件粒度的按需元数据同步。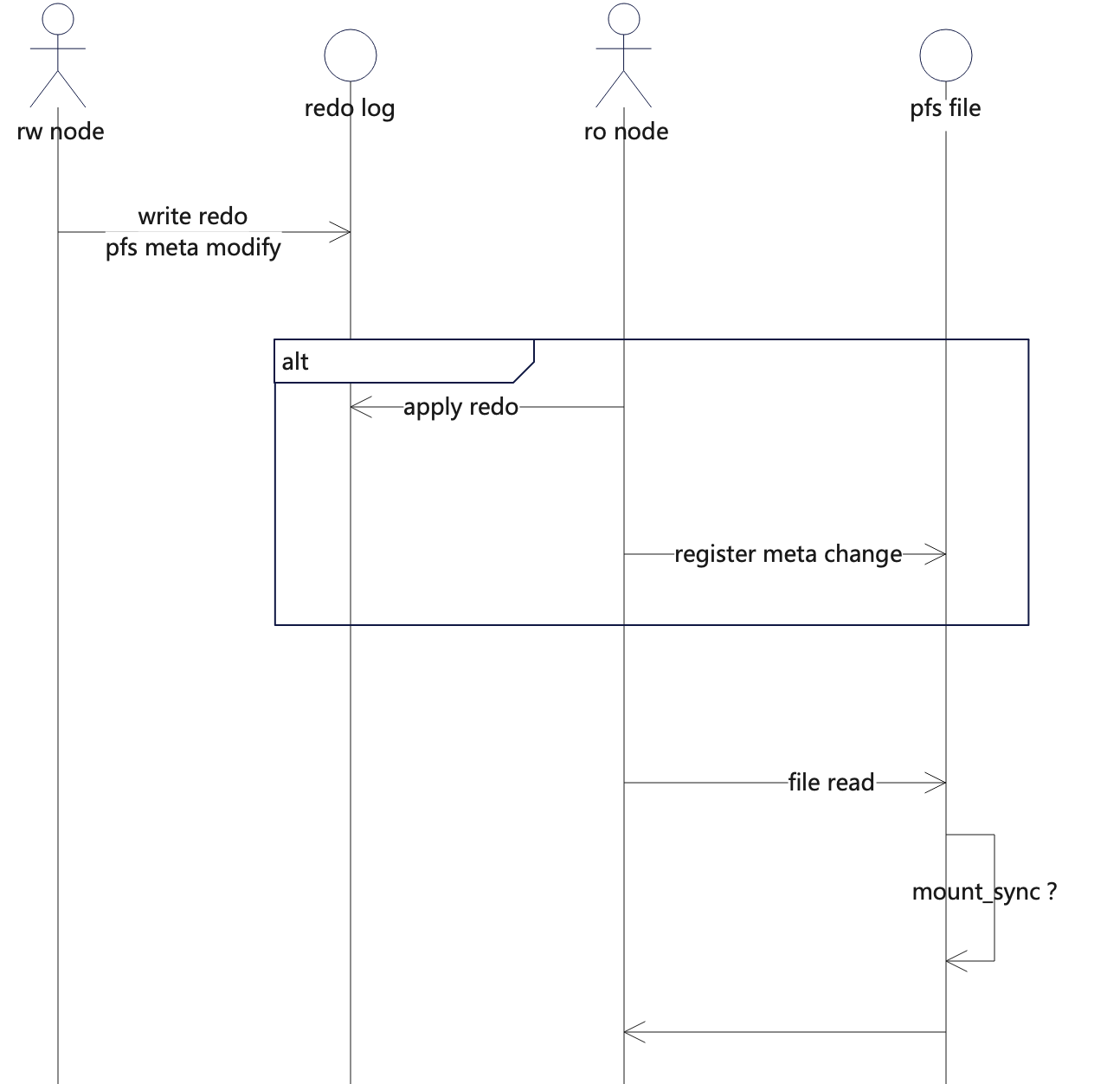
流程大致为:
首先,rw节点在感知到会产生pfs元数据变更的操作时,记录进redo log。ro在apply到对应的redo时,调用pfs提供的接口,在文件inode对象上登记,下一次对这个文件读时,pfs先进行元数据同步,主动同步最新的元数据过来。为了控制风险,我们当前只对ibd文件生效,对应文件系统元数据变化的redo类型有:
- MLOG_FILE_CREATE
- MLOG_FILE_RENAME
- MLOG_FILE_DELETE
- MLOG_FILE_EXTEND
- MLOG_FILE_DELETE_EXTEND
- MLOG_FILE_PUNCH_HOLE
- MLOG_UNDO_TABLESPACE_RECREATE
然后,ro节点在apply redo时,就在对应的fil_space上记录,在对应的Fil_shard::do_io之前,调用pfs提供的接口,告诉pfs对应的文件元数据已经变化了,在接下来pfs在io链路上先执行mount_sync同步元数据,在最新的元数据快照基础上执行file io。
pfs主要向db提供文件语义的pfs_set_sync(int fd, int flag)接口。
pfs要实现的语义是,只要文件在rw上产生了相关的元数据修改,那么在ro上该文件下一次io之前一定要同步原数据修改。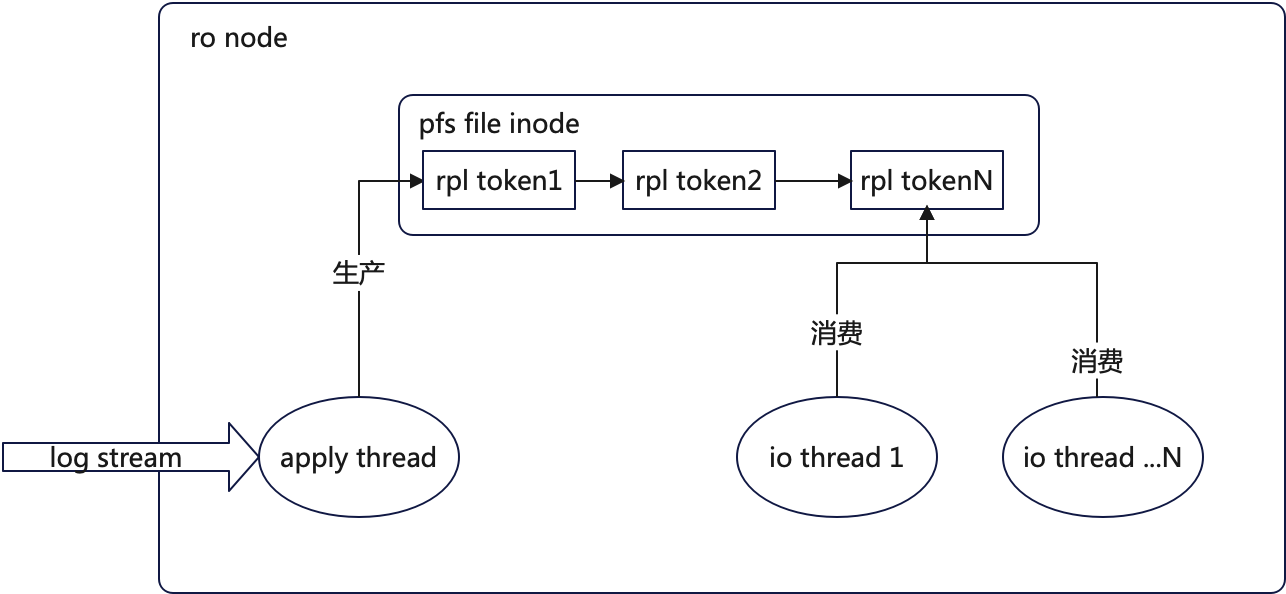
细节描述如下:
- 在pfs inode对象上维护rpl token队列,每个token都有唯一编号token id标识;
- db物理复制流碰到有文件元数据变化的mlog type,就向对应文件inode的rpl token队头上插入一个唯一的rpl token;
- io线程对文件执行io时,先检查对应文件inode上rpl token队列是否为空,不为空则取队尾的token,执行mount_sync操作,同步最新的元数据;
这里有一个细节,为了保证每个rpl token都对应一次成功元数据同步的语义,实际是io线程先取token id,执行元数据同步成功之后,再从rpl token队列中将对应的token删除;这样即可保证即便在多线程并发时,每个token都能至少对应一次元数据同步成功执行,rw上的元数据修改一定能同步到ro上。
场景梳理
| pfs元数据操作 | 策略 |
|---|---|
| extend space (fallocate + pwrite(0)) |
- innodb extend,写MLOG_FILE_EXTEND的redo - rw开始执行extend操作,产生pfs元数据修改日志 - ro读extend page之前,apply对应的redo - 调用pfs_set_sync,插入token通知pfs文件元数据变化 |
| ddl (rename/unlink) |
- rw持mdl锁,此时写start ddl,等待ro同步消息 - ro parse到ddl开始日志,推进applied lsn到start ddl对应的lsn - ro加上mdl锁,阻止表文件访问,并回复给rw - rw开始变更操作,这个过程会有一系列文件操作 - rw写对应的redo,比如MLOG_FILE_RENAME/DELETE - ro先parse到MLOG_FILE_RENAME/DELETE日志 - apply线程会告知pfs文件元数据变化并插入对应token - parse 到end ddl,ro释放mdl锁,这时候允许表文件io - 表文件io会先检查inode上token,并进行元数据同步 |
| undo表空间文件 (fallocate/truncate) |
基本同extend space; |
| 表空间文件创建等目录级操作 | 目录操作默认都是需要先进行文件系统元数据同步 |
| 物理复制异常 | 在Fil_shard::do_io种判断Repl_polar_slave::STOPPED |
有个corner case需要处理:
ro获取mdl锁之后,这时候应该没有表文件io操作了,这时候ro上只有apply redo动作,不会有unlink掉的文件io了。因为apply发现page不在bp是直接跳过的(但是有page 0的pread,这时候原来表文件可能已经删除,并且对应的数据block已经复用在rw上写入了其他文件数据),这久以来db的page数据校验机制来兜底了;
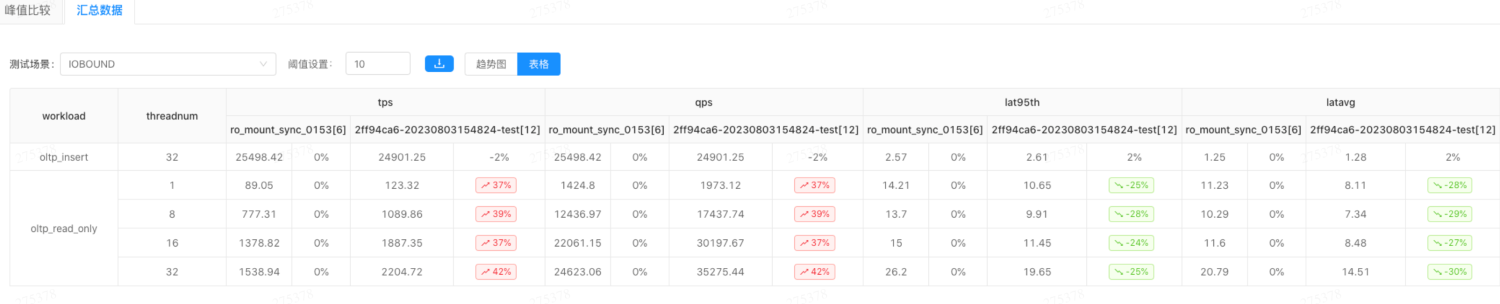
性能压测对比
基本测试场景
实例规格8c32G, IOBOUND 标准测试场景,tables=8, tablesize=32000000
- prepare 灌入完成数据
- rw上做oltp_insert 32持续并发压力
- ro上测试oltp_read_only ,1/8/16/32并发场景对比,非优化(0.1.53)版本和优化版本
mount sync次数:
优化前,执行同步元数据次数22307次/s;
优化后,执行同步元数据242次;
补充测试场景
实例规格8c32G, IOBOUND 标准测试场景,tables=8, tablesize=32000000;
只有ro oltp_read_only 场景测试结果,max_qps ro 优化版本比非优化版本(0.1.53)峰值性能提升接近50%
补充:imci集群ap节点优化
对于imci集群,就简单多了,因为db已经将会产生元数据变化的操作区分出来了,会将这部分请求转发到主节点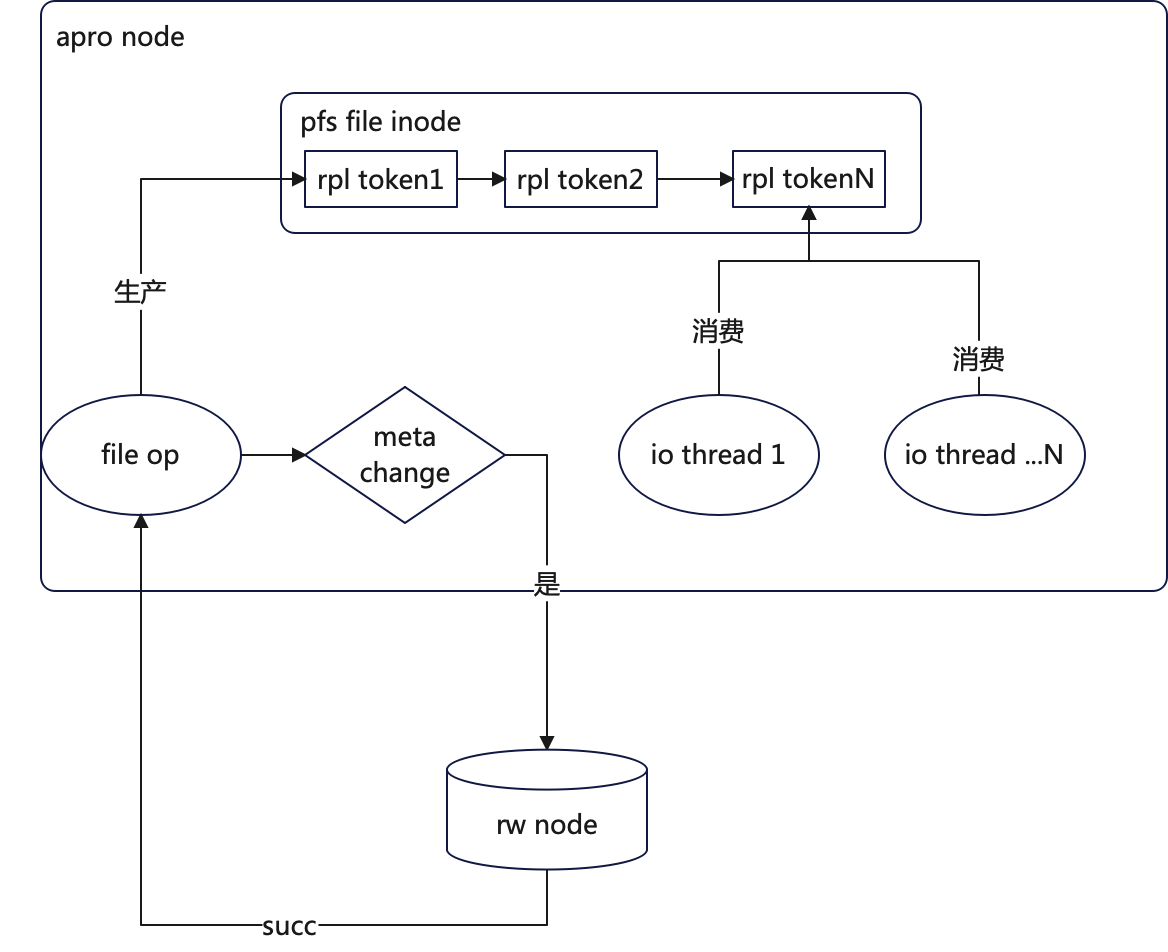
流程为:
- apro感知到文件操作会产生元数据变化,转发到rw节点;
- rw节点返回执行结果,给apro,apro会在文件的rpl token队列上插入一个token;
- 剩下的流程与ro上相同;