PolarDB 基于代价的查询改写技术解析
Author: 遥凌
这篇文章主要介绍我们在PolarDB MySQL这个产品中,针对优化器组件新构建的一套查询改写框架。这个框架意在解决开源数据库产品中基本都存在的一个基础顽疾,让PolarDB可以为复杂查询生成更优的执行计划,从而提升Ad-Hoc分析查询的执行速度,进一步提升PolarDB处理混合负载的能力。
优化器到底是什么
我们都知道关系型数据库一般使用SQL作为与数据库交流的语言。而作为一种声明式的结构化语言,SQL是简单且相当贴合人类的思维与表述方式的,这应该也是它经久不衰的原因之一,但这种对人类友好的方式对数据库则正好相反,数据库需要基于SQL描述的目标,在内部建立一个真正可以获取或修改数据的执行方式,这个工作就是由优化器来完成的。 优化器本质上是一个搜索器,最粗暴的做法是,我们可以把所有数据的访问方式,各个表的相互join方式、join顺序、各个算子的执行方式等全部枚举+组合起来,形成一系列的执行计划,然后为每个执行计划估算一个代价分数来衡量这个计划的执行情况(延迟、资源…),选择其中最优执行方案。显然这并不现实,但思路也就是这么个思路,其余的工作就落入了如下几个方向:
- 如何尽量丰富的枚举出必要的候选计划,避免漏掉最优的可能
- 如何提升搜索空间中的枚举效率,避免考虑不必要的可能计划
- 如何给每个候选计划一个准确的评估分数,最能反映我们的优化目标
… 最为核心的应该就是前面3个,第3个问题涉及到统计信息、基数估计和代价模型,本篇文章主要关注前2个问题。
经典的优化器框架
虽然优化器理论已经被研究了几十年,但目前为止仍然是以如下两个框架为主流,几乎所有较为成熟的数据库产品都逃不出他们的框框:
- bottom-up搜索,这也是最为经典的优化模式,优化过程被分为了显式的分为了2个阶段
- 基于规则的查询改写,主要完成基于关系代数对原有AST树进行改造,生成更有利于执行的逻辑算子树
- 基于代价的查询优化,对逻辑算子树进行物理优化,主要就是join ordering和join方式的确定,此外还有各个其他算子的计算方式的决定,这部分是基于代价的,需要依赖于统计信息和代价模型
bottom-up最早在System-R系统中被提出并被后续的商业、开源数据库广泛使用,例如Oracle、DB2、MySQL、PostgreSQL等都属于这一类
- top-down搜索,也就是较晚些出现的Volcano/Cascades优化框架,其思想是对优化策略做更好的抽象,从而不再需要显式的区分各种类型的查询优化(如谓词下推、join ordering等都统一视为优化规则)。然后基于一个统一的自顶向下的搜索策略来完成最优执行计划的搜索。
理论上,top-down具有更好的抽象和扩展,也会有更好的搜索效率,因此被SQL Server和后续的很多开源数据库(GreenPlum/CRDB…)/大数据(Spark/Doris…)所使用。
哪个更好?
这是一个争论了很长时间的问题,但始终是没有结论的。在接触优化器理论的初期,我觉得cascades确实是一个更为先进的框架,无论从概念的抽象,规则的扩展等,都是一个更为干净和高效的实现。但随着对各个主流的开源优化器源码的研究,这个看法也有一些改变,个人感觉双方还是各有优劣,本质上殊途同归,所以核心不在于框架是怎样的,而在于优化器的能力是否足够广泛,能覆盖的场景是否足够丰富。
bottom-up搜索的缺点
bottom-up方式最大的特点是优化被比较明确的分为了两个阶段,逻辑优化 => 物理优化,逻辑优化阶段主要做一些启发式的查询改写,物理优化则主要解决join的顺序+算子执行方式这个问题,这就意味着:
- 对于那些无法确定是否能够有效的查询改写动作(如子查询上拉),没有一个合适的时机去做,任何一个阶段都无法独立做出判断,决定一个改写策略是否是更优的
- 物理优化阶段一般采用bottom-up的join ordering算法,这样是无法有针对性的完成基于物理属性的剪枝的
top-down搜索的缺点
top-down方式在理论上消除了优化的两个割裂的阶段,在一套枚举流程中完成查询改写+join ordering等各种优化,过程中考虑代价,这样也就解决了一些复杂的查询改写(如子查询上拉)无法基于代价确定其有效性的问题,这看起来相当完美,但问题则出在工程实践中:
- top-down的搜索策略基于Memo完成逻辑、物理算子的创建和保存,但这个过程很不直观,这带来了调试bug和分析regression的复杂性,对于线上排查和维护会比较不方便
- 如果把一些复杂改写也揉入到Memo的搜索框架中,会导致计划空间的爆炸性膨胀,拖慢优化时间,目前开源界比较流行的Cascades框架优化器,我只看到Orca有这种在搜索过程中考虑复杂查询改写的能力(而这也导致了其比较出名的优化效率问题),其他的top-down优化器仍然采用了类似bottom-up搜索的2阶段搞法,因此也就同样具有无法基于代价决定是否应用优化策略的问题
MySQL 优化器
作为国内甚至世界上最为流行的开源关系型数据库,MySQL的计算引擎一直为人所诟病。大家的共识是MySQL的计算层做的很差,但innodb则非常优秀,客观来说确实如此。MySQL从8.0开始才在计算引擎做了大力度的改造,包括重构了执行层,拥有了真正的Volcano执行器,并支持了anti join/hash join等基础功能,目前针对join ordering,社区也在开发hypergraph optimizer来尝试产生更丰富的join tree形态,找到更优的join计划。 但可能是因为基础太薄弱了,这种发展的速度并不快,而且还有一些根本性的问题,不做大手术是无法解决的,就笔者来说,我认为MySQL8.0目前仍存在一些非常明显的问题:
- 复杂查询改写无法应用的问题,比如社区实现了”subquery_to_derived”这样的子查询解相关能力,但这个优化并一定总是有好的效果,因此默认是关闭的,需要用户基于具体的SQL来利用hint开启,但这样case by case的使用会给业务和运维带来很大的负担,很难在实际中派上用场。
- 非常有限的查询改写功能(e.g 谓词下推),无论在数量,以及每种改写功能覆盖的场景上,都非常单一,无法应对生产环境中有分析需求的各种复杂查询。
- 扩展性差,这个是最致命的,MySQL一个非常大的弊端是功能、子系统之间的耦合严重,这导致内部数据结构的组织很复杂且相互交织,如果想扩展新的功能就更加吃力甚至不可能。例如:
- 在查询改写阶段,各个基本能力之间有比较强的依赖关系,一个改写要依赖于前一个改写完成(因为要依赖上一个改写产生的一些结构)
- 优化期的结构与执行期是耦合的,也就是很多优化结构最终也会用于执行,这同样也导致了结构的复杂相互依赖或引用,作为查询改写最需要做的就是不断调整查询树的结构,这会带来问题。
- 改写之间的相互影响没有被考虑,比如MySQL是在最后进行了谓词下推inline view的操作,但下推之后的谓词,可能会使得内层的query block能够实现一些新的改写动作(e.g left join化简为inner join),但这是无法做到的。
- 除了改写模块,物理优化的统计信息完全依赖索引、代价模型粗糙过时、没有任何计划的管理能力,也没有任何自适应的优化、执行能力。。。 这其中每一个点都是一个方向,有很多可以补强的工作,本文主要关注查询改写因此就不深入了,后续会专项一一介绍。
PolarDB CBQT Rewriter
在解决改写框架的扩展性和耦合性这个问题上,我们面临两种设计方案的选择:
- 重写优化框架,比如改造为top-down的方式
- 保留原有的bottom-up模式,实现对改写规则的抽象和基于代价的改写与枚举策略 (参考Oracle的一篇早期的paper)
方案1确实很有吸引力,原因是改造会更彻底,摆脱MySQL原有的历史包袱,而且目前开源的top-down优化框架很多,借鉴参考也会非常方便。但其缺点对我们来说也是致命的,那就是兼容性:前面也提到了MySQL的各类结构的耦合,这会导致优化器的很多动作会对执行层面产生影响,最终会导致执行结果受到影响,例如类型、精度、执行行为等。虽然具备HTAP的能力,但PolarDB仍是一个以在线业务为主的TP系统,其对MySQL的100%兼容性是客户的基本预期,如果打破这个预期,产生的影响会无法预测。 因此方案2就成为了当下的选择,虽然工程复杂度高,但达到的效果正是我们所期望的。 和Oracle一样,我们也称这个改写框架为CBQT (Cost Based Query Transformation)。总得来说,它做到了两件事情
- 将MySQL原有的和后续PolarDB新实现的各类查询改写,用一套规则框架进行了封装,每一个改写能力都是一个规则,其中包括
- 启发式的规则(总是可以应用,改写后效果更优,e.g 谓词下推)
-
基于代价的规则(不一定更优,需要基于代价确定,e.g scalar相关子查询展开)
有了这套规则框架,后续新实现的查询改写能力,只需要实现几个必要的接口,就可以接入到改写框架中,提升了扩展性,框架会基于一定策略对各个改写规则反复枚举,完成尽可能多的有收益改写,使查询转换为一个尽量更优的形态。
- 对于基于代价的规则,通过对Mini-CBO模块的调用来获取代价信息,并基于代价的比较做出是否应用改写的决策,确保改写后的更优性。
MySQL原有的处理流程如下图:
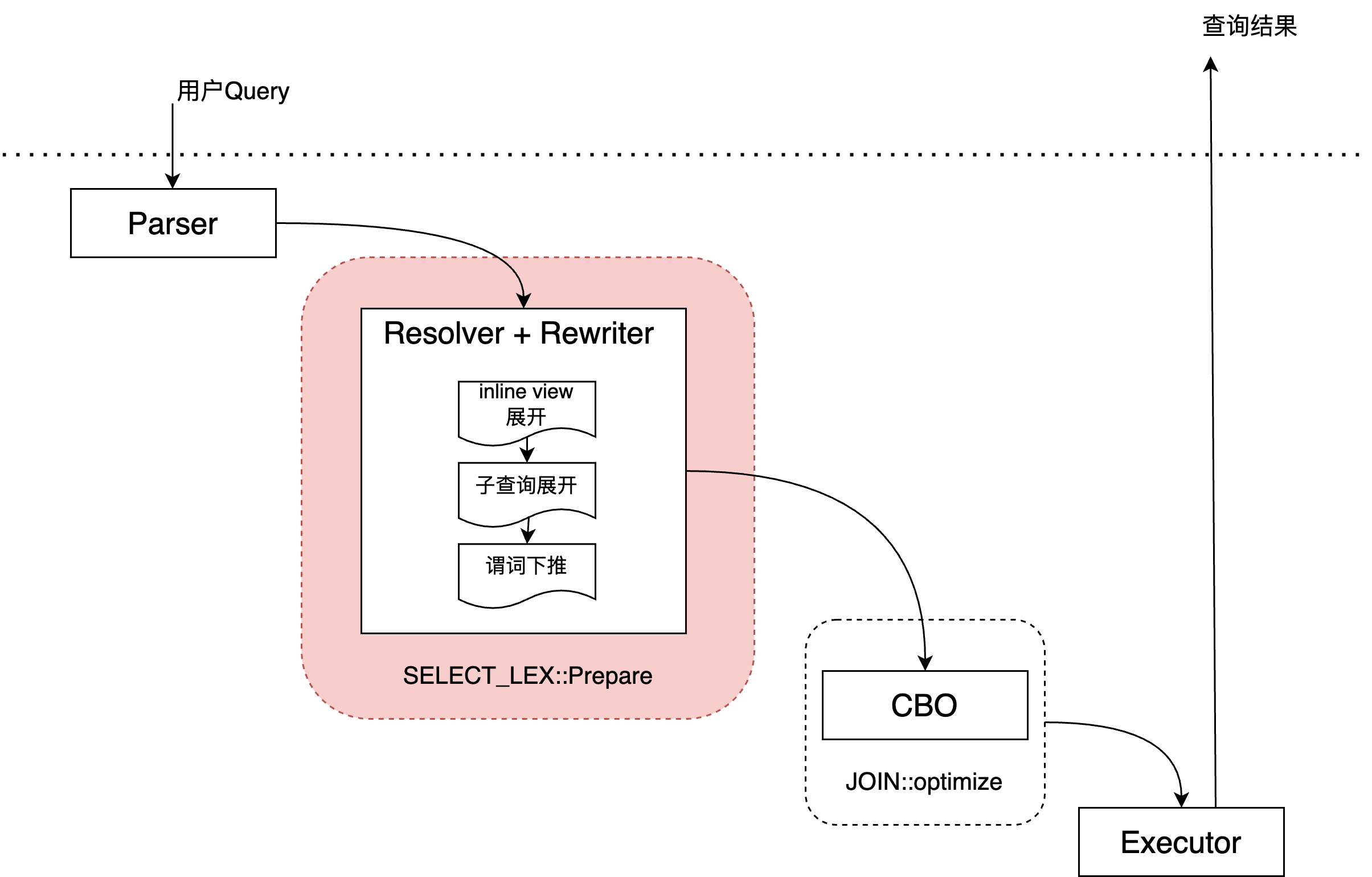 在原有流程中,Resolver和Rewriter是耦合在一起处理的,各个改写动作需要以固定的顺序依次完成,其中一些改写由于不确定其是否能更优需要跳过(除非基于switch/hint强制指定)。
而Rewriter和CBO还是有比较明确的边界,CBO的职责比较明确:确定各个query block中,join的顺序、表的访问方式,代价的估算等。
PolarDB的优化流程如下图:
在原有流程中,Resolver和Rewriter是耦合在一起处理的,各个改写动作需要以固定的顺序依次完成,其中一些改写由于不确定其是否能更优需要跳过(除非基于switch/hint强制指定)。
而Rewriter和CBO还是有比较明确的边界,CBO的职责比较明确:确定各个query block中,join的顺序、表的访问方式,代价的估算等。
PolarDB的优化流程如下图:
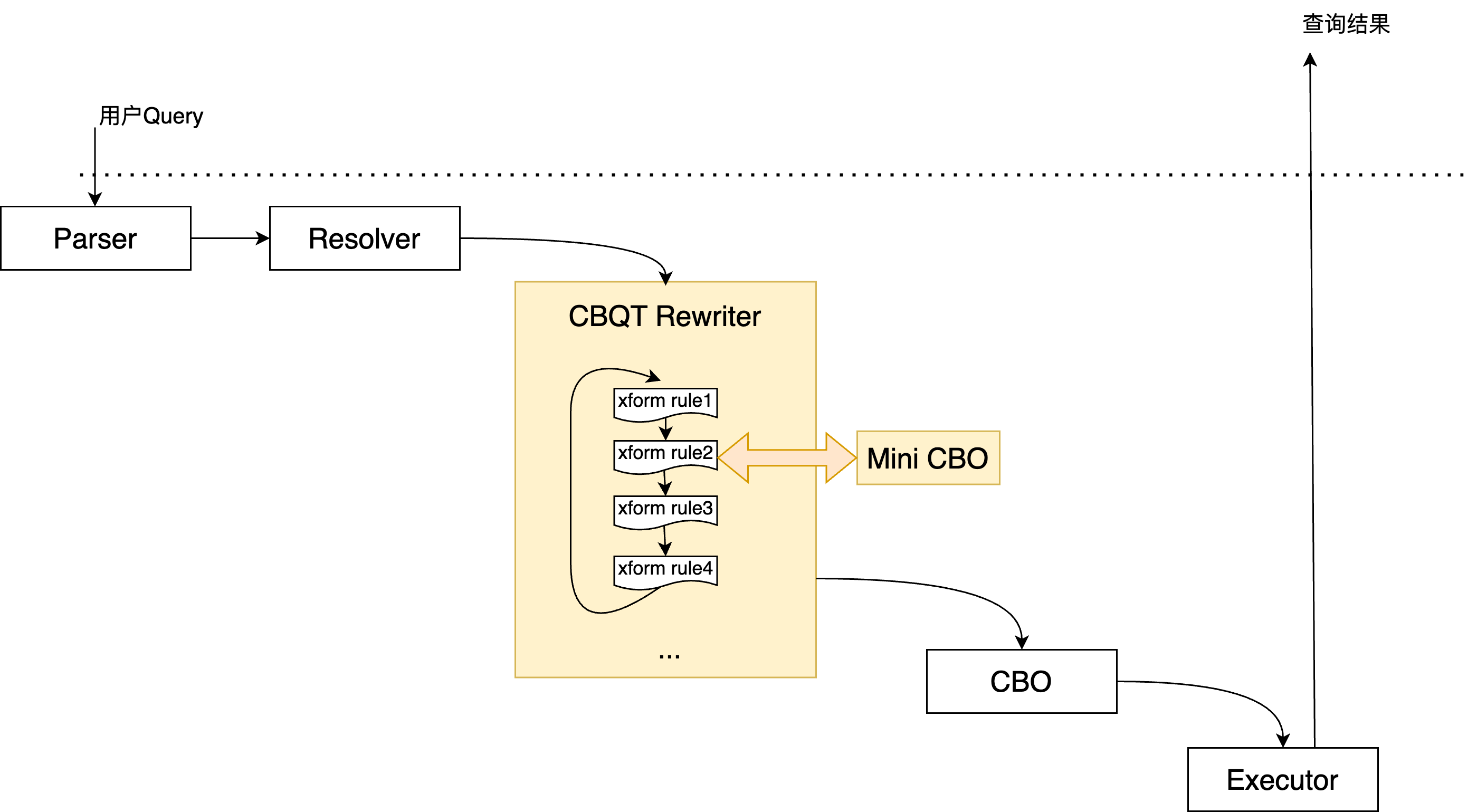 可以看到,在新的优化流程中,Resolver做了解耦,成为了一个独立的流程,这是后续工作的基础,使得Rewriter能够成为一个独立扩展和运行的组件,此外出现了一个Mini-CBO组件,它和Rewriter会反复的交互,实现基于代价的枚举过程。
可以看到,在新的优化流程中,Resolver做了解耦,成为了一个独立的流程,这是后续工作的基础,使得Rewriter能够成为一个独立扩展和运行的组件,此外出现了一个Mini-CBO组件,它和Rewriter会反复的交互,实现基于代价的枚举过程。
更丰富的查询改写
在新的Rewriter中,增加了很多查询改写能力,在长期线上运维的过程中,我们针对用户各种复杂查询的应用场景,积累了大量来自用户的慢SQL,从中是可以提取出一系列的共性特征的,从而构成很多新的改写策略,这些改写能帮助用户查询实现数量级的性能提升。 一个最为简单的例子就是投影列裁剪,在基于列存的系统中,投影列裁剪是最为基础的能力,因为可以尽量减少需要读取的列数量,提升CPU/IO效率。但在基于innodb的行存系统中重要性看起来并没有那么大,因此MySQL原有的处理中,只在一个inline view展开到外层时,会消除外层用不到的投影列。但在我们遇到的很多场景中,用户会在inline view中实现一些通用而复杂的业务计算逻辑,将计算结果物化后,外层再根据各种不同的需求做二次处理,这会导致内层inline view为了保证通用性而加入了大量的投影列。这些投影表达式都会经过计算并物化到临时表中,增加计算+内存开销(尤其当投影列是复杂表达式如子查询等)。而针对任一个具体的SQL,外层二次处理需要的投影一般是较少的,因此对于无法展开的inline view,做投影列的裁剪就很有必要了。
SELECT count(0)
FROM (
SELECT t1.id, t1.factory_code, ...
(
SELECT count(DISTINCT sign.user_id)
FROM sign JOIN m
ON ...
) AS sign_user_num,
(
SELECT count(DISTINCT a.user_id)
FROM a
WHERE a.data_state = 0
AND a.paper_id = t1.paper_id
AND NOT EXISTS (
SELECT 1
FROM b
WHERE b.paper_id = t1.paper_id
AND b.user_id = a.user_id
AND a.create_time < b.create_time
) AS exam_user_num,
...
FROM t1 LEFT JOIN t3
ON ...
) countAlias;
=>
SELECT count(0)
FROM (
SELECT t1.id
FROM t1 LEFT JOIN t3
ON ...
) countAlias;
上面的例子是线上客户的一个真实查询,其内层的投影列有100多个,其中包含一些嵌套子查询的计算,但外部只是做了一个count操作,所以内层的投影列其实只需要保留一个t1.id就好了 目前PolarDB的改写能力还在持续丰富,之前我们写过一个改写系列文章介绍了一部分,后续还会不断补充。
更完备的查询改写
对于查询改写的每一种能力,需要能够实现的尽可能完备、覆盖尽量多的场景,例如社区高版本实现了谓词下推的功能,PolarDB同样也实现了谓词下推,但两者有很大的区别:
- PolarDB 在下推谓词前,首先会做基于等值/非等值的谓词推导,尽量构建可以下推的谓词来做提前过滤,而社区则只基于原始条件做处理,这意味着:
SELECT * FROM t1 JOIN (select * from t2) dt2 ON t1.a = dt2.a AND t1.a > 5;
这样的查询是无法推导出 dt2.a > 5,从而实现下推的,但PolarDB可以转换为
SELECT * FROM t1 JOIN (select * from t2 WHERE t2.a > 5) dt2 ON t1.a = dt2.a AND t1.a > 5;
这样可以让dt2物化的数据尽可能少,也让t2表的读取能够利用t2.a的潜在索引来加速
- PolarDB可以将谓词下推到inline view/subquery中,社区只能下推到inline view中
SELECT * FROM t1
WHERE t1.a > 5 AND t1.a < t1.b
t1.b IN (
SELECT t2.b FROM t2
);
==>
SELECT * FROM t1
WHERE t1.a > 5 AND t1.a < t1.b
t1.b IN (
SELECT t2.b FROM t2 WHERE t2.b > 5
);
在开发的过程中,我们的一个基本设计原则就是,在调研该功能的已知技术方案时,尽可能在场景的丰富度和功能覆盖面上做到更多,避免浅尝辄止的设计与实现。
基于迭代的枚举框架
有了以上这些更多的改写能力后,我们需要把这些能力以合理的方式组织在一起,在MySQL原处理流程中,各个改写依次尝试一遍后结束,但这会导致改写之间的影响被忽略掉,从而可能错过一些更优的计划形态,例如:
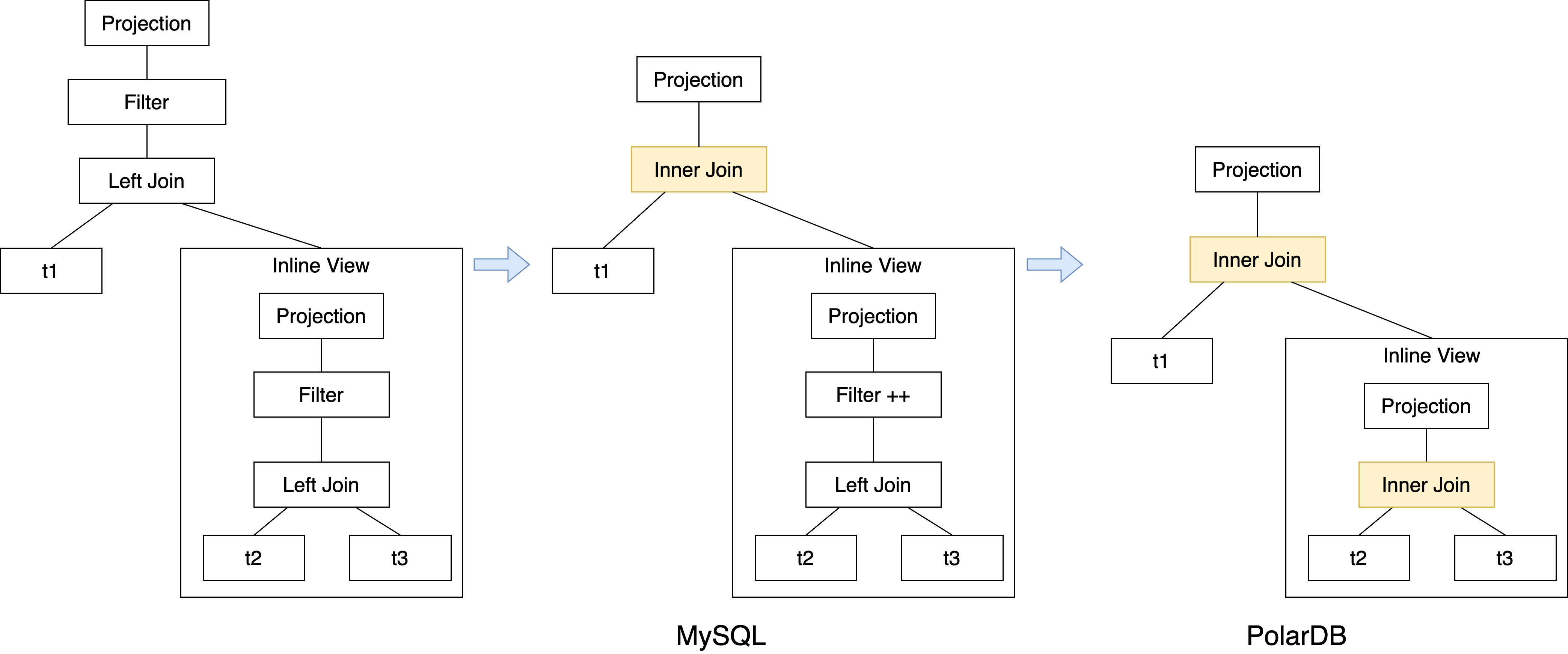 如上图最左侧的一个查询计划图,是t1表和inline view的left join,inline view内部也是一个left join。
MySQL原有流程中,inline view内部和外层查询,会各自考虑基于filter做left join化简为inner join的改写,在这个步骤都完成后,最后会考虑外层的谓词下推到inline view当中,所以在MySQL中,可以看到上图中间的计划树形态。但这错过了基于外层下推条件,将inline view内部的left join做化简的机会,因为谓词下推是所有改写中的最后一个。
相比PolarDB的枚举框架是迭代的,理论上会将所有的规则反复应用,直到没有任何改写能够再次被应用为止,因此是可以获取一个最优的潜在计划形态的。如上图的最右侧,在完成谓词下推后,后续仍会考虑基于新的下推谓词做left join化简,从而保证内层也会转换为一个inner join。
如上图最左侧的一个查询计划图,是t1表和inline view的left join,inline view内部也是一个left join。
MySQL原有流程中,inline view内部和外层查询,会各自考虑基于filter做left join化简为inner join的改写,在这个步骤都完成后,最后会考虑外层的谓词下推到inline view当中,所以在MySQL中,可以看到上图中间的计划树形态。但这错过了基于外层下推条件,将inline view内部的left join做化简的机会,因为谓词下推是所有改写中的最后一个。
相比PolarDB的枚举框架是迭代的,理论上会将所有的规则反复应用,直到没有任何改写能够再次被应用为止,因此是可以获取一个最优的潜在计划形态的。如上图的最右侧,在完成谓词下推后,后续仍会考虑基于新的下推谓词做left join化简,从而保证内层也会转换为一个inner join。
枚举策略
这种反复对改写规则的迭代,自然会造成优化时间的增长,本质上这是优化时间与执行时间的trade-off。因此可以考虑多种可能的枚举策略,对应不同的权衡考虑。 在枚举策略的实现上我们参考了Oracle的处理,在原paper中,共包含有4种策略
- 穷尽式枚举(Exhaustive)
- 迭代式枚举(Iterative)
- 线性枚举 (Linear)
- 两趟式枚举(Two-pass)
在具体解释之前,先明确两个基本概念:
- 规则(Rule)
任何一个改写功能,我们将其抽象为一个Rule,一个改写功能可能会应用到很多查询计划树的多个部件中,但逻辑上这仍是一个Rule。
- 对象(Object)
对于每个改写功能,它可能会应用到多个查询树的部件上,比如子查询展开这个Rule,可以应用在多个子查询上,那每个子查询都可以作为一个Object,去考虑它是否应用当前的改写Rule。
考虑到优化效果与效率的折衷,PolarDB目前实现了Linear和Two-pass两种枚举策略。
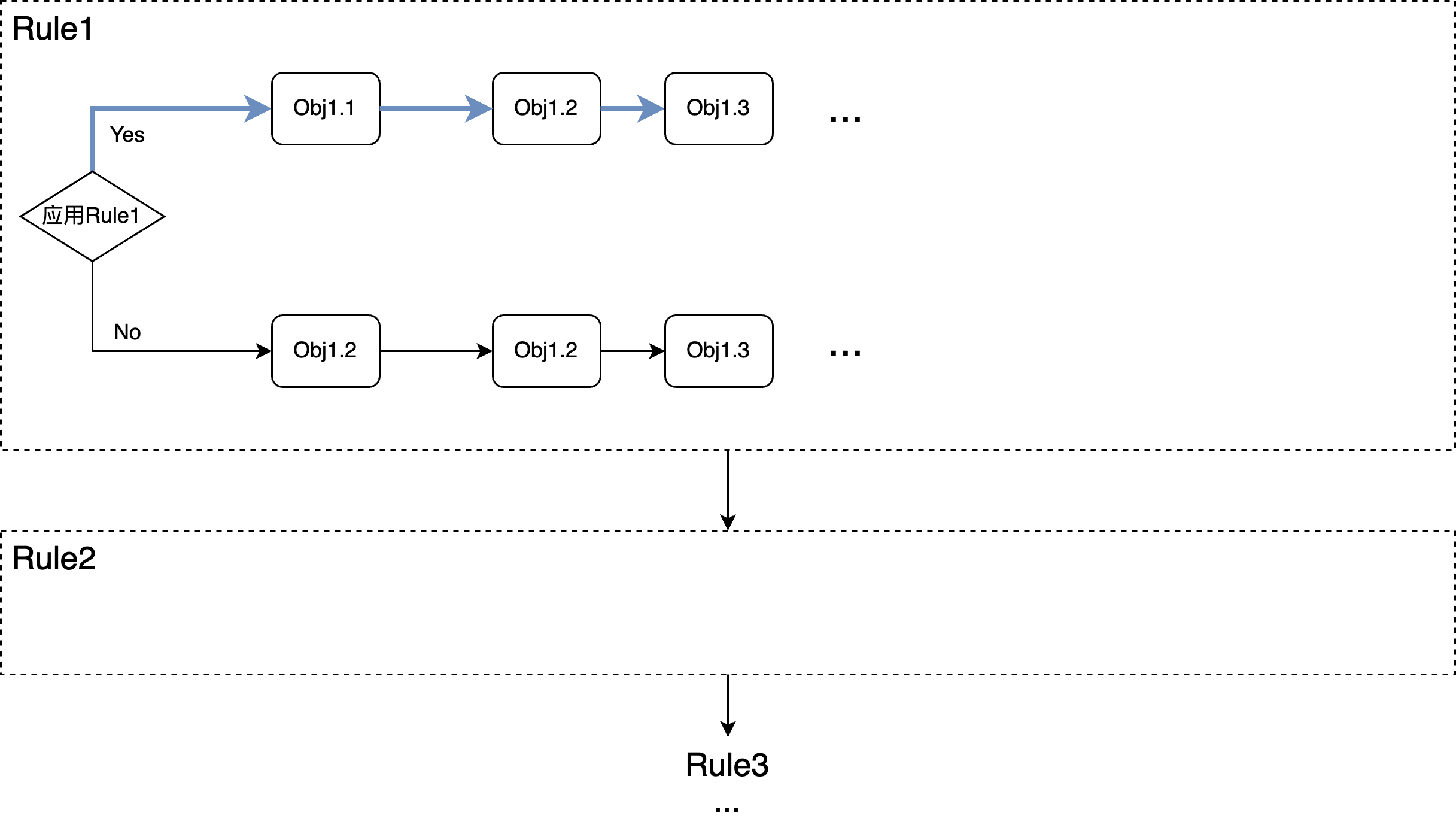
- 线性枚举 (Linear)
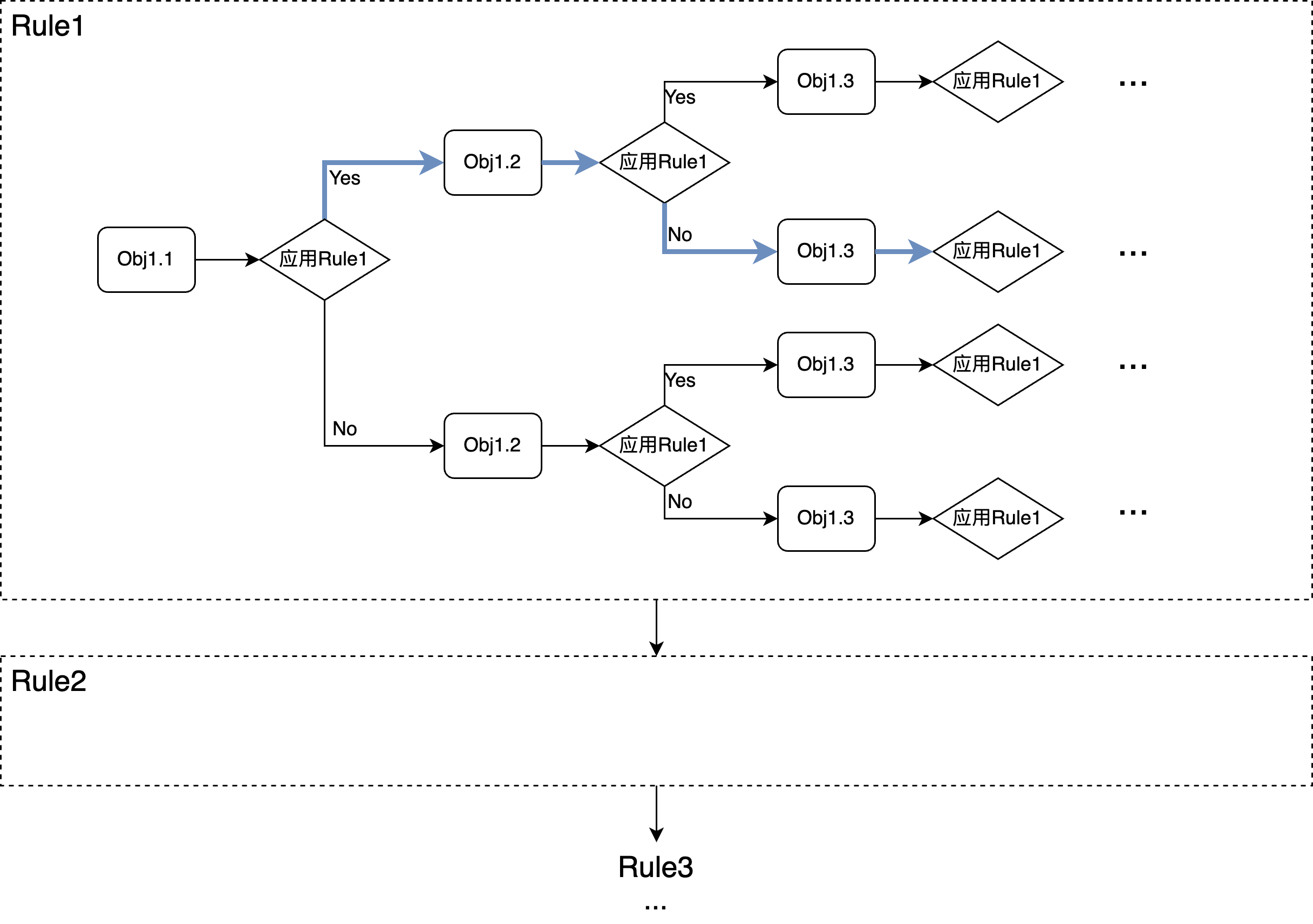 从上图可以看到,在一次迭代中,对所有的rule会依次考虑一遍,相对复杂的部分是在每个rule内部,对每个rule,一个query tree中可能会有很多地方可以应用该rule,也就是图中的多个Obj,对每个Obj,都可能应用或不应用该改写动作,而基于此决定,在考虑下一个Obj是否要应用,所以每个object依次考量一遍并基于当前结果,做下一步的动作。
很明显这是一个对计划空间的局部最优搜索,因此不一定能找到全局最优解,但仍然还是很大程度扩展了原有的计划空间。
从上图可以看到,在一次迭代中,对所有的rule会依次考虑一遍,相对复杂的部分是在每个rule内部,对每个rule,一个query tree中可能会有很多地方可以应用该rule,也就是图中的多个Obj,对每个Obj,都可能应用或不应用该改写动作,而基于此决定,在考虑下一个Obj是否要应用,所以每个object依次考量一遍并基于当前结果,做下一步的动作。
很明显这是一个对计划空间的局部最优搜索,因此不一定能找到全局最优解,但仍然还是很大程度扩展了原有的计划空间。
- Two-pass
当查询的SQL语句非常复杂时,即使是线性的处理方式也会导致优化时间过长,因此还可以进一步退化:
 可以看到,仍然是在一次迭代中,对所有的rule考虑一遍,但每个rule内部则简单了很多,只有2个选择:要么对所有object应用该改写,要么所有object都不应用。相对于MySQL基于静态开关的控制,这里等于只多考虑了额外一种情况。
在PolarDB内部,会基于一些策略去考察当前查询的复杂度,自适应的决定使用哪一种枚举策略,默认是线性枚举(Linear)的方式。
可以看到,仍然是在一次迭代中,对所有的rule考虑一遍,但每个rule内部则简单了很多,只有2个选择:要么对所有object应用该改写,要么所有object都不应用。相对于MySQL基于静态开关的控制,这里等于只多考虑了额外一种情况。
在PolarDB内部,会基于一些策略去考察当前查询的复杂度,自适应的决定使用哪一种枚举策略,默认是线性枚举(Linear)的方式。
对CBO的调用
前面已提到,在MySQL的常规优化流程中,完成查询改写操作后会进入CBO的模块(对应JOIN::optimize函数),执行每个query block的物理优化,这个过程中,基于统计信息+代价模型,MySQL会基于代价,考虑每个query block内部可能的单表访问方式、join顺序、join算法等,从中选择代价最低的最优方案。 这种计算代价的能力,对于CBQT也是非常重要的,因为我们需要有“基于代价决定改写是否应用”的能力,也就是说在枚举过程中,如果一个改写不确定是否会更优,需要能够让CBO告知改写前/后的代价,通过比较来决定。这就要求我们能够在迭代过程中反复调用CBO组件,理论上把它当做一个黑盒,一个可以计算代价的黑盒。
CBO的抽象与精简
MySQL的原始CBO组件是非常重的,熟悉MySQL代码的同学应该了解JOIN::optimize函数中完成的工作,除了计算代价,他还需要做一系列事前、事后的动作,包括:
- 等值、常量传递和一些类型转换处理等
- 计算必要统计信息
- 枚举最优计划并计算代价
- 生成物理执行计划
整个过程很长,如果我们把这些都包含进来,势必造成枚举过程效率过低,因此第一个动作就是对CBO做抽象和精简,实现一个Mini-CBO的组件,它只做为计算代价的最小化动作,尽可能降低调用的开销。 我们把Mini-CBO实现为一个黑盒,传递给它一个query plan的子树,返回这颗子树的最优代价。
CBO的重入与复用
对于Mini-CBO的反复调用,也暴露了一些进一步提升效率的机会,即从各个粒度上,实现对代价计算的复用,尽量避免执行重复的优化过程。这个粒度从小到大是:
- Table level,对于每个table,MySQL会基于谓词,考虑可能的range访问方式,这个过程中会估算range scan要扫描的行数,而这是通过index dive的动态采样来完成的,我们通过缓存+复用dive的结果,即可以节省反复读取page的开销,也可以避免由于采样导致的优化效果不稳定问题。
- Join level,对于一个连续的join序列+join条件,也会缓存其对应的最佳join方式和join代价,后续再遇到直接获取对应代价值,避免了昂贵的join顺序枚举。
- Query Block level,当一个输入的query tree子树中,一些query block与之前计算过的block相同,我们也会复用之前计算的结果,更大幅度提升重入的效率。
- Query Tree Level,query block level的复用一定程度上也意味着query tree的局部复用
Query Tree的复制
在前面介绍枚举框架的图中,我们看到一个object,会同时考虑应用一个改写rule或不应用该rule,这是基于query tree的clone能力来实现的。
具体来说,当Rewriter考虑对一个object应用当前改写Rule时,会先对整个query tree做一次clone,生成一个新tree,并基于新tree完成改写动作,然后将新tree输入到Mini-CBO中计算代价,同时原有的不做改写的tree也会进入Mini-CBO计算代价,通过比较两个结果,保留2颗query tree的一个作为winner,进入下一个步骤。
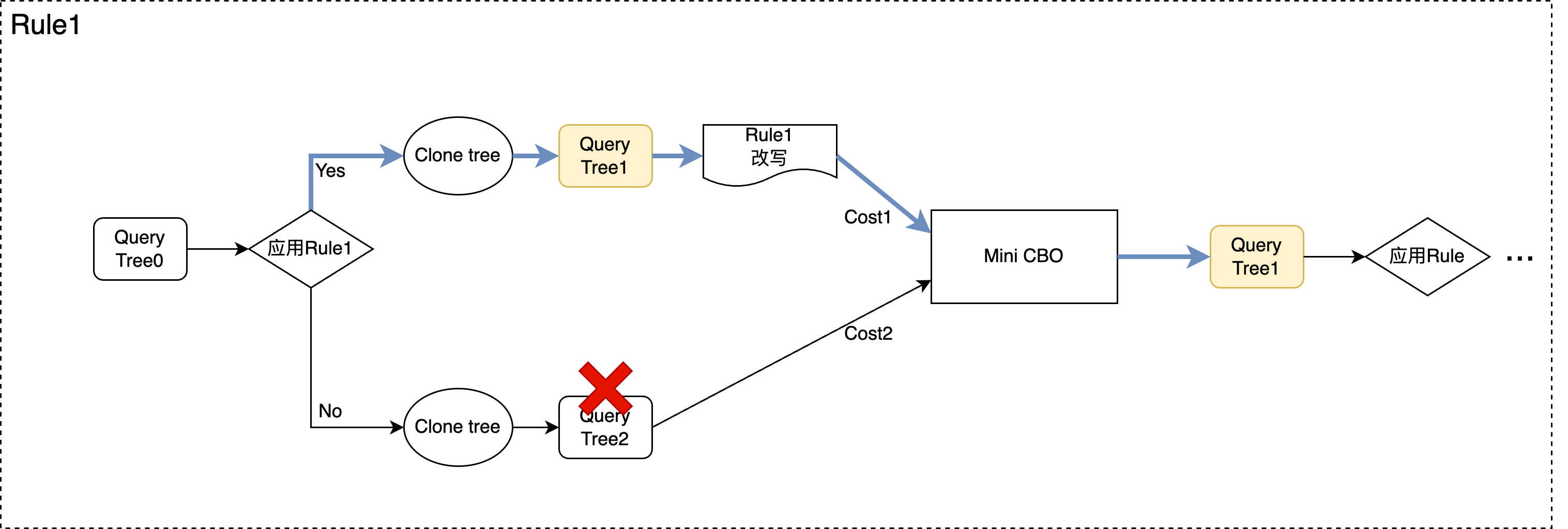 从query tree的角度来看,流程如上图,对于每个需要基于代价确定的改写规则,都需要经过Mini-CBO的”裁决”来选中winner。
当然从原理和工程上,这里还有很多要处理的事情,例如
从query tree的角度来看,流程如上图,对于每个需要基于代价确定的改写规则,都需要经过Mini-CBO的”裁决”来选中winner。
当然从原理和工程上,这里还有很多要处理的事情,例如
- 基于启发式的改写规则与基于代价的改写规则如何交互和影响
- 基于代价的规则之间的Interleaving和Juxtaposition (可参考Oracle paper)
- 流程中针对clone的优化
这些细节这里就不赘述了。
示例
目前我们实现了标量子查询转物化表、GroupBy解关联子查询、物化表合并、子查询折叠等四种基于代价的变换规则以及子查询转SemiJoin、window_function解关联子查询等八种启发式变换规则。下面使用TPCH的数据构造两个场景说明CBQT框架的优势。 测试环境为PolarDB线上实例,规格为polar.mysql.g2.large(4C8G);测试数据为TPCH 1G的数据。
自动选择代价更低的计划
以TPCH Q17为例。 Q17查询为:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#12'
and p_container = 'JUMBO BOX'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
)
limit 1;
对于这个查询,子查询可以直接按照语义以关联的形式迭代执行或者通过GroupBy解关联后进行执行,而何种方式性能更好取决于具体场景,比如索引、数据量等。在TPCH-1G数据下,没有二级索引时,Q17通过GroupBy解关联执行的效率是更高的,对比如下。 关联执行 计划:
mysql> explain format=tree select sum(l_extendedprice) / 7.0 as avg_yearly from lineitem, part where p_partkey = l_partkey and p_brand = 'Brand#12' and p_container = 'JUMBO BOX' and l_quantity < ( select 0.2 * avg(l_quantity) from lineitem where l_partkey = p_partkey ) limit 1;
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit: 1 row(s)
-> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join (cost=7194628.66 rows=297103)
-> Table scan on lineitem (cost=660507.64 rows=5942055)
-> Filter: ((part.P_BRAND = 'Brand#12') and (part.P_CONTAINER = 'JUMBO BOX') and (lineitem.L_QUANTITY < (select #2))) (cost=1.00 rows=0)
-> Single-row index lookup on part using PRIMARY (P_PARTKEY=lineitem.L_PARTKEY) (cost=1.00 rows=1)
-> Select #2 (subquery in condition; dependent)
-> Aggregate: avg(lineitem.L_QUANTITY)
-> Filter: (lineitem.L_PARTKEY = part.P_PARTKEY) (cost=125722.69 rows=594206)
-> Table scan on lineitem (cost=125722.69 rows=5942055)
执行时间:7579.54s
 解关联执行
计划:
解关联执行
计划:
mysql> explain format=tree select sum(l_extendedprice) / 7.0 as avg_yearly from lineitem, part where p_partkey = l_partkey and p_brand = 'Brand#12' and p_container = 'JUMBO BOX' and l_quantity < ( select 0.2 * avg(l_quantity) from lineitem where l_partkey = p_partkey ) limit 1;
+-----------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+-----------------------------------------------------------------------------------------------------------------------+
| -> Limit: 1 row(s)
-> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join
-> Nested loop inner join (cost=7194628.66 rows=297103)
-> Table scan on lineitem (cost=660507.64 rows=5942055)
-> Filter: ((part.P_BRAND = 'Brand#12') and (part.P_CONTAINER = 'JUMBO BOX')) (cost=1.00 rows=0)
-> Single-row index lookup on part using PRIMARY (P_PARTKEY=lineitem.L_PARTKEY) (cost=1.00 rows=1)
-> Filter: (lineitem.L_QUANTITY < (0.2 * derived_1_2.Name_exp_1))
-> Index lookup on derived_1_2 using <auto_key0> (Name_exp_2=lineitem.L_PARTKEY)
-> Materialize
-> Table scan on <temporary>
-> Aggregate using temporary table
-> Table scan on lineitem (cost=660507.64 rows=5942055)
执行时间:25.45s
 可以看到解关联执行只需要25s左右,性能是不解关联执行的数百倍。
如果在各个表上有二级索引,那么不解关联的性能会更好,对比如下。
解关联执行
计划:
可以看到解关联执行只需要25s左右,性能是不解关联执行的数百倍。
如果在各个表上有二级索引,那么不解关联的性能会更好,对比如下。
解关联执行
计划:
mysql> explain format=tree select sum(l_extendedprice) / 7.0 as avg_yearly from lineitem, part where p_partkey = l_partkey and p_brand = 'Brand#12' and p_container = 'JUMBO BOX' and l_quantity < ( select 0.2 * avg(l_quantity) from lineitem where l_partkey = p_partkey ) limit 1;
+-------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+-------------------------------------------------------------------------------------------------------------------------+
| -> Limit: 1 row(s)
-> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join
-> Nested loop inner join (cost=40024.75 rows=57147)
-> Filter: ((part.P_BRAND = 'Brand#12') and (part.P_CONTAINER = 'JUMBO BOX')) (cost=19835.90 rows=1930)
-> Table scan on part (cost=19835.90 rows=192989)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=7.50 rows=30)
-> Filter: (lineitem.L_QUANTITY < (0.2 * derived_1_2.Name_exp_1))
-> Index lookup on derived_1_2 using <auto_key0> (Name_exp_2=part.P_PARTKEY)
-> Materialize
-> Group aggregate: avg(lineitem.L_QUANTITY)
-> Index scan on lineitem using LINEITEM_FK2 (cost=593311.60 rows=5799036)
执行时间:20.58s
 关联执行
计划:
关联执行
计划:
mysql> explain format=tree select sum(l_extendedprice) / 7.0 as avg_yearly from lineitem, part where p_partkey = l_partkey and p_brand = 'Brand#12' and p_container = 'JUMBO BOX' and l_quantity < ( select 0.2 * avg(l_quantity) from lineitem where l_partkey = p_partkey ) limit 1;
+---------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+---------------------------------------------------------------------------------------------------------------------+
| -> Limit: 1 row(s)
-> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join (cost=40024.75 rows=57147)
-> Filter: ((part.P_BRAND = 'Brand#12') and (part.P_CONTAINER = 'JUMBO BOX')) (cost=19835.90 rows=1930)
-> Table scan on part (cost=19835.90 rows=192989)
-> Filter: (lineitem.L_QUANTITY < (select #2)) (cost=7.50 rows=30)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=7.50 rows=30)
-> Select #2 (subquery in condition; dependent)
-> Aggregate: avg(lineitem.L_QUANTITY)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=10.46 rows=30)
执行时间:0.42s
 可以看到解关联执行的查询性能相对关联执行的查询性能下降明显。
可以看到解关联执行的查询性能相对关联执行的查询性能下降明显。
而CBQT框架能够根据查询代价自动确定是否采用解关联执行,对于上述场景下的Q17。
在有索引时的计划选择为:
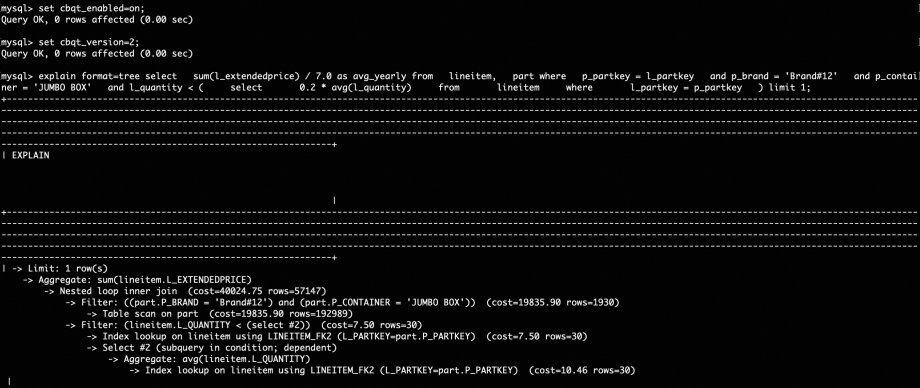 在没有索引时的选择为:
在没有索引时的选择为:
 可以看到CBQT都能够自动选出最优的计划,不需要DBA基于经验人工对不同场景单独进行配置。
可以看到CBQT都能够自动选出最优的计划,不需要DBA基于经验人工对不同场景单独进行配置。
反复枚举变换
CBQT框架的另一个优势在于能够变换规则是反复枚举的,某些不可用的变换规则在其他规则应用后可能变得可用了,从而可以选出一个更优的计划,例如下述查询:
SELECT *
FROM part
WHERE P_PARTKEY IN (
SELECT L_PARTKEY
FROM lineitem
WHERE L_TAX < 100
)
OR P_PARTKEY IN (
SELECT L_PARTKEY
FROM lineitem
WHERE L_TAX < 200
);
由于两个子查询是由OR连接的,因此在PolarDB中无法直接转为semijoin,如果不做任何变换其计划如下:
mysql> explain format=tree select count(*) from part where P_PARTKEY in (select L_PARTKEY from lineitem where L_TAX < 100) or P_PARTKEY in (select L_PARTKEY from lineitem where L_TAX < 200);
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Filter: (<in_optimizer>(part.P_PARTKEY,part.P_PARTKEY in (select #2)) or <in_optimizer>(part.P_PARTKEY,part.P_PARTKEY in (select #3))) (cost=20310.00 rows=198050)
-> Index scan on part using PRIMARY (cost=20310.00 rows=198050)
-> Select #2 (subquery in condition; run only once)
-> Filter: ((part.P_PARTKEY = `<materialized_subquery>`.L_PARTKEY))
-> Limit: 1 row(s)
-> Index lookup on <materialized_subquery> using <auto_distinct_key> (L_PARTKEY=part.P_PARTKEY)
-> Materialize with deduplication
-> Filter: (lineitem.L_TAX < 100.00) (cost=555350.80 rows=1808695)
-> Table scan on lineitem (cost=555350.80 rows=5426628)
-> Select #3 (subquery in condition; run only once)
-> Filter: ((part.P_PARTKEY = `<materialized_subquery>`.L_PARTKEY))
-> Limit: 1 row(s)
-> Index lookup on <materialized_subquery> using <auto_distinct_key> (L_PARTKEY=part.P_PARTKEY)
-> Materialize with deduplication
-> Filter: (lineitem.L_TAX < 200.00) (cost=555350.80 rows=1808695)
-> Table scan on lineitem (cost=555350.80 rows=5426628)
但是可以观察到这两个子查询只有WHERE条件不一样,因此可以做子查询的折叠,折叠后的查询形式如下:
SELECT *
FROM part
WHERE P_PARTKEY IN (
SELECT L_PARTKEY
FROM lineitem
WHERE L_TAX < 100 OR L_TAX < 200
);
子查询折叠后的计划如下:
mysql> explain format=tree select count(*) from part where P_PARTKEY in (select L_PARTKEY from lineitem where L_TAX < 100) or P_PARTKEY in (select L_PARTKEY from lineitem where L_TAX < 200);
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Filter: <in_optimizer>(part.P_PARTKEY,part.P_PARTKEY in (select #3)) (cost=20310.00 rows=198050)
-> Index scan on part using PRIMARY (cost=20310.00 rows=198050)
-> Select #3 (subquery in condition; run only once)
-> Filter: ((part.P_PARTKEY = `<materialized_subquery>`.L_PARTKEY))
-> Limit: 1 row(s)
-> Index lookup on <materialized_subquery> using <auto_distinct_key> (L_PARTKEY=part.P_PARTKEY)
-> Materialize with deduplication
-> Filter: ((lineitem.L_TAX < 100.00) or (lineitem.L_TAX < 200.00)) (cost=555350.80 rows=3014552)
-> Table scan on lineitem (cost=555350.80 rows=5426628)
此时只有一个子查询了,符合了子查询转semijoin的条件,因此可以进一步变换为semijoin的形式,其计划如下:
mysql> explain format=tree select count(*) from part where P_PARTKEY in (select L_PARTKEY from lineitem where L_TAX < 100) or P_PARTKEY in (select L_PARTKEY from lineitem where L_TAX < 200);
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Nested loop inner join
-> Filter: (part.P_PARTKEY is not null) (cost=20310.00 rows=198050)
-> Index scan on part using PRIMARY (cost=20310.00 rows=198050)
-> Single-row index lookup on <subquery3> using <auto_distinct_key> (L_PARTKEY=part.P_PARTKEY)
-> Materialize with deduplication
-> Filter: ((lineitem.L_TAX < 100.00) or (lineitem.L_TAX < 200.00)) (cost=555350.80 rows=3014552)
-> Table scan on lineitem (cost=555350.80 rows=5426628)
在TPCH-1G数据量下,对于该查询,使用CBQT框架进行改写的效果对比如下图:
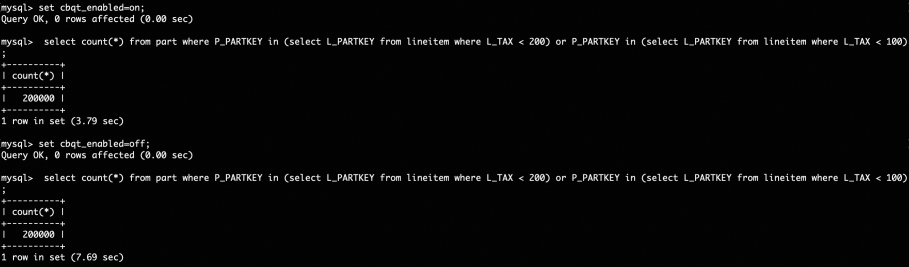 可以看到使用CBQT框架进行改写后,查询性能提升了接近一倍。
可以看到使用CBQT框架进行改写后,查询性能提升了接近一倍。
展望
新的改写框架目前在PolarDB 8.0.22版本已上线,可以通过cbqt_enabled开关做总体的开启和关闭,此外类似optimizer_switch,我们也提供了cbqt_rule_switch这个参数,来控制各个改写动作是否在CBQT框架中生效。 目前的改写框架已基本成型,但还有很多事情需要做,这个框架是PolarDB新一代查询优化器的基础设施,其后续能支持的功能是非常灵活宽广的。一些近期/中期的目标如下:
- 持续增加更多的查询改写能力,覆盖更多用户场景,提升查询执行效果
- 优化Rewriter枚举过程中的效率,通过引入Partial Clone等能力降低复制和CBO的代价
- 利用反复枚举的能力,实现针对PolarDB异构引擎异构计划在优化过程中的融合,更高效的生成针对多引擎的混合执行计划,例如找到最优的行/列存混合计划形态
…