PolarDB MySQL 冷数据查询性能优化
Author: yifei
PolarDB for MySQL 在优化冷数据查询性能方面,聚焦于两项核心技术策略:OSS 数据筛选与OSS冷数据并行查询技术。
首先,OSS数据筛选机制通过利用高度针对性的列属性预处理,实现对数据对象的智能过滤。这一策略能够显著缩减数据扫描范围,避免不必要的时间消耗于无关数据的检索上,从而大幅提升查询效率与系统响应速度。
另一方面,OSS冷数据并行查询技术,则是通过并发查询执行模型,即增加并发查询线程或任务的数量,来并行处理大规模数据集。此方法充分利用了现代计算资源的多核特性,实现了查询负载在多个处理单元间的均衡分配,极大缩短了查询响应时间。特别是针对数据量庞大的冷数据查询场景,该技术能够有效克服单线程处理的瓶颈,确保查询操作的高效执行与资源的最大化利用。
以下详细介绍二者的使用方法和适用场景。
OSS_FILE_FILTER 查询优化
8.0.2.2.25 版本的冷数据查询功能已经支持了OSS文件筛选 OSS FILE FILTER 功能,该功能通过利用查询条件预前锁定数据存储位置,实现了数据检索策略的优化升级。相较于传统的并行查询方法,OSS FILE FILTER 展现出更高的资源效率,在具备有利筛选条件的场景下,其查询性能的提升效果尤为显著,这不仅归功于减少了不必要的数据扫描,还有效提升了处理速度与系统响应能力。
使用方法
这里以经典的 lineitem 表作为分析案例,介绍如何使用 OSS FILE FILTER 加速查询。我们提前生成了一个大约 10G 的 TPCH lineitem 标准数据集,表定义如下:
mysql> show create table lineitem \G
*************************** 1. row ***************************
Table: lineitem
Create Table: CREATE TABLE `lineitem` (
`l_orderkey` int(11) NOT NULL,
`l_partkey` int(11) NOT NULL,
`l_suppkey` int(11) NOT NULL,
`l_linenumber` int(11) NOT NULL,
`l_quantity` decimal(10,2) NOT NULL,
`l_extendedprice` decimal(10,2) NOT NULL,
`l_discount` decimal(10,2) NOT NULL,
`l_tax` decimal(10,2) NOT NULL,
`l_returnflag` char(1) NOT NULL,
`l_linestatus` char(1) NOT NULL,
`l_shipDATE` date NOT NULL,
`l_commitDATE` date NOT NULL,
`l_receiptDATE` date NOT NULL,
`l_shipinstruct` char(25) NOT NULL,
`l_shipmode` char(10) NOT NULL,
`l_comment` varchar(44) NOT NULL
) ENGINE=CSV DEFAULT CHARSET=utf8 /*!99990 800020204 NULL_MARKER='NULL' */ /*!99990 800020223 OSS META=1 */ CONNECTION='default_oss_server'
1 row in set (0.01 sec)
可以看到,当前表已经开启了 OSS META,这是冷数据 OSS File Filter 的前提,我们以 Q6 为例,查看其执行计划:
首先,打开 ` OSS File Filter` 的开关:
SET csv_oss_file_filter = ON;
执行计划为:
mysql> explain select
-> sum(l_extendedprice * l_discount) as revenue
-> from
-> lineitem
-> where
-> l_shipdate >= date '1994-01-01'
-> and l_shipdate < date '1994-01-01' + interval '1' year
-> and l_discount between 0.06 - 0.01 and 0.06 + 0.01
-> and l_quantity < 24;
+----+-------------+----------+------------+------+---------------+------+---------+------+----------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+----------+----------+-------------+
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 59986051 | 0.41 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+----------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
实际执行时间大约为 5min
mysql> select
-> sum(l_extendedprice * l_discount) as revenue
-> from
-> lineitem
-> where
-> l_shipdate >= date '1994-01-01'
-> and l_shipdate < date '1994-01-01' + interval '1' year
-> and l_discount between 0.06 - 0.01 and 0.06 + 0.01
-> and l_quantity < 24;
+-----------------+
| revenue |
+-----------------+
| 1230113636.0101 |
+-----------------+
1 row in set (5 min 11.25 sec)
而 Q6 上主要用了 l_shipdate ,l_discount ,l_quantity 做 Filter,我们在这几列上增加 OSS FILE FILTER,语法为:
mysql> ALTER TABLE lineitem OSS_FILE_FILTER = 'l_shipdate,l_quantity,l_discount';
执行完成后,可以看到表定义变为:
mysql> show create table lineitem \G
*************************** 1. row ***************************
Table: lineitem
Create Table: CREATE TABLE `lineitem` (
`l_orderkey` int(11) NOT NULL,
`l_partkey` int(11) NOT NULL,
`l_suppkey` int(11) NOT NULL,
`l_linenumber` int(11) NOT NULL,
`l_quantity` decimal(10,2) NOT NULL,
`l_extendedprice` decimal(10,2) NOT NULL,
`l_discount` decimal(10,2) NOT NULL,
`l_tax` decimal(10,2) NOT NULL,
`l_returnflag` char(1) NOT NULL,
`l_linestatus` char(1) NOT NULL,
`l_shipDATE` date NOT NULL,
`l_commitDATE` date NOT NULL,
`l_receiptDATE` date NOT NULL,
`l_shipinstruct` char(25) NOT NULL,
`l_shipmode` char(10) NOT NULL,
`l_comment` varchar(44) NOT NULL
) ENGINE=CSV DEFAULT CHARSET=utf8 /*!99990 800020204 NULL_MARKER='NULL' */ /*!99990 800020223 OSS META=1 */ /*!99990 800020223 OSS_FILE_FILTER='l_shipdate,l_quantity,l_discount' */ CONNECTION='default_oss_server'
1 row in set (0.00 sec)
此时,再执行 Q6,explain 看了看到使用了查询加速功能,同时执行时间缩短了很多。
mysql> explain select
-> sum(l_extendedprice * l_discount) as revenue
-> from
-> lineitem
-> where
-> l_shipdate >= date '1994-01-01'
-> and l_shipdate < date '1994-01-01' + interval '1' year
-> and l_discount between 0.06 - 0.01 and 0.06 + 0.01
-> and l_quantity < 24 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 59986051
filtered: 0.41
Extra: Using where; With pushed engine condition ((`multiply`.`lineitem`.`l_shipDATE` >= DATE'1994-01-01') and (`multiply`.`lineitem`.`l_shipDATE` < <cache>((DATE'1994-01-01' + interval '1' year))) and (`multiply`.`lineitem`.`l_discount` between <cache>((0.06 - 0.01)) and <cache>((0.06 + 0.01))) and (`multiply`.`lineitem`.`l_quantity` < 24.00))
1 row in set, 1 warning (0.01 sec)
mysql> select
-> sum(l_extendedprice * l_discount) as revenue
-> from
-> lineitem
-> where
-> l_shipdate >= date '1994-01-01'
-> and l_shipdate < date '1994-01-01' + interval '1' year
-> and l_discount between 0.06 - 0.01 and 0.06 + 0.01
-> and l_quantity < 24;
+-----------------+
| revenue |
+-----------------+
| 1230113636.0101 |
+-----------------+
1 row in set (3 min 59.63 sec)
由于 Q6 的查询条件筛选率并不高,如果是在 l_orderkey 上做等值查询,查询时间可以直接缩短到秒级。首先,在 l_orderkey 上增加 OSS FILE FILTER:
mysql> ALTER TABLE lineitem OSS_FILE_FILTER = 'l_orderkey,l_shipdate,l_quantity,l_discount';
随后执行一个等值查询:
mysql> select * from lineitem where l_orderkey = 70;
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+------------------+------------+-----------------------------------------+
| l_orderkey | l_partkey | l_suppkey | l_linenumber | l_quantity | l_extendedprice | l_discount | l_tax | l_returnflag | l_linestatus | l_shipDATE | l_commitDATE | l_receiptDATE | l_shipinstruct | l_shipmode | l_comment |
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+------------------+------------+-----------------------------------------+
| 70 | 641279 | 91292 | 1 | 8.00 | 9761.92 | 0.03 | 0.08 | R | F | 1994-01-12 | 1994-02-27 | 1994-01-14 | TAKE BACK RETURN | FOB | ggle. carefully pending dependenc |
| 70 | 1961552 | 11591 | 2 | 13.00 | 20974.98 | 0.06 | 0.06 | A | F | 1994-03-03 | 1994-02-13 | 1994-03-26 | COLLECT COD | AIR | lyly special packag |
| 70 | 1798088 | 73140 | 3 | 1.00 | 1186.00 | 0.03 | 0.05 | R | F | 1994-01-26 | 1994-03-05 | 1994-01-28 | TAKE BACK RETURN | RAIL | quickly. fluffily unusual theodolites c |
| 70 | 457332 | 7341 | 4 | 11.00 | 14182.41 | 0.01 | 0.05 | A | F | 1994-03-17 | 1994-03-17 | 1994-03-27 | NONE | MAIL | alongside of the deposits. fur |
| 70 | 371307 | 21314 | 5 | 37.00 | 50996.73 | 0.09 | 0.04 | R | F | 1994-02-13 | 1994-03-16 | 1994-02-21 | COLLECT COD | MAIL | n accounts are. q |
| 70 | 556542 | 31558 | 6 | 19.00 | 30371.88 | 0.06 | 0.03 | A | F | 1994-01-26 | 1994-02-17 | 1994-02-06 | TAKE BACK RETURN | SHIP | packages wake pending accounts. |
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+------------------+------------+-----------------------------------------+
6 rows in set (2.13 sec)
性能测试
OSS_FILE_FILTER 技术的核心机制在于预计算并存储表内各数据块的统计概况,从而在查询过程中依据这些信息迅速锁定目标数据块的位置。此机制的性能优化效果显著依赖于 File Filter 的过滤效率(Selectivity),即返回结果占总数据量的比例。最理想的应用场景是对主键(primary key)或唯一键(unique key)执行 FILE FILTER,因为这类键值具有高度区分度,能极大提升过滤效率。
我们在 TB 量级的 TPCH 测试数据集上,对 OSS_FILE_FILTER 的筛选效率与查询响应时间之间的关系进行了分析。结果如下图所示,可以观察到,当查询操作基于主键或唯一键执行时,意味着 OSS_FILE_FILTER 能够展现出极高的过滤效能。这种高度针对性的查询策略,几乎无一例外地确保了查询结果在秒级内的迅速反馈。相比之下,若采取全表扫描的方式进行数据检索,则面临着迥异的情境。全表扫描因其遍历整个数据集的特性,导致查询成本急剧增加,几乎达到了不可承受的程度,特别是在如此大规模的数据体量下。
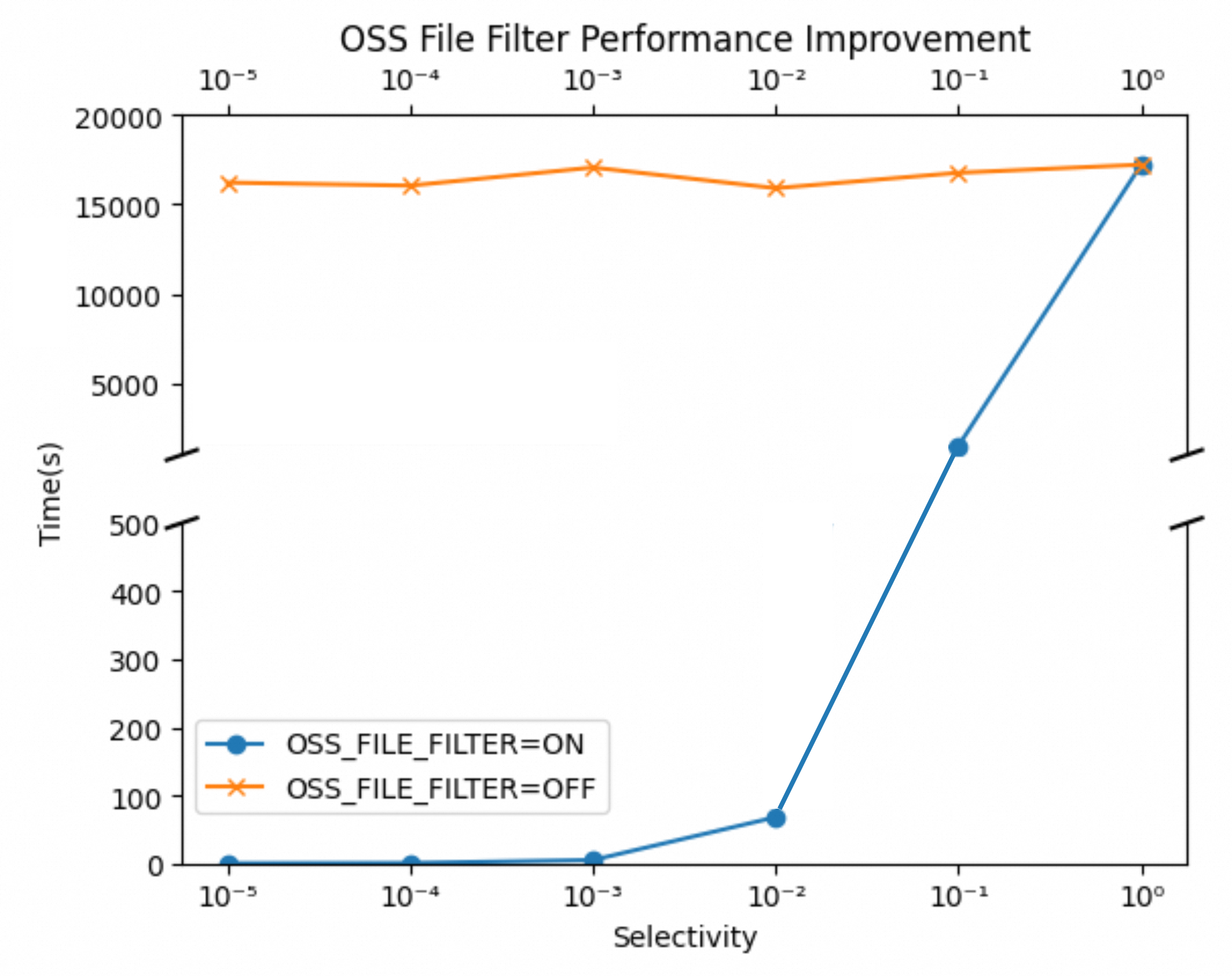 > NOTE: Selectivity 是过滤效率,主要看查询的结果占总数据量的比重。在以上例子中,如果筛选条件为
> NOTE: Selectivity 是过滤效率,主要看查询的结果占总数据量的比重。在以上例子中,如果筛选条件为 l_orderkey = 70,则 Selectivity 为 10-6,如果 l_orderkey < 5000,则 Selectivity 为 10-3。
OSS 冷数据并行查询
OSS 冷数据并行查询也是一种查询加速的方法,可以不依赖 OSS FILE FILTER统计信息,通过增加并行度来提升查询速度。提升的效果和并行查询的并行度正相关。需要注意的是,一个并行查询线程需要 128MB 内存,在实际过程中需要留意实例内存余量,以避免·。以下介绍如何使用并行查询OSS冷数据。
使用方法
- 在控制台调大参数
loose_csv_max_oss_threads。这个参数表示一个节点可以并行执行的OSS线程数量,默认是1。 - 开启并行查询功能
可以通过多种方法开启并行查询。这里仍以lineitem为例,通过hint开启并行查询后,执行计划上会显示Parallel scan标记。
mysql> explain SELECT /*+ PARALLEL(4) */
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 15390122 | 0.41 | Parallel scan (4 workers); Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
2 rows in set, 1 warning (2.17 sec)
如果有多个节点,也可以开启ePQ,进一步提升查询性能。开启ePQ后,查询计划会显示有几个节点,总并行度为多少:
mysql> explain SELECT /*+ PARALLEL(4) */
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 59986051 | 0.41 | Parallel scan (8 workers); MPP (2 nodes); Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
性能测试
并行查询技术的核心机制在于通过多个线程并发地执行查询操作,从而提升查询效率。因此性能主要依赖并行度的大小。我们在 10GB 的TPCH数据集上测试Q6的性能,节点规格为32c128g,共有两个只读节点,测试结果如下图所示:
 > 上图中的横坐标为单节点并行度,纵坐标为查询时间。
> 上图中的横坐标为单节点并行度,纵坐标为查询时间。ePQ场景下单节点并行度如果为2的话,由于测试实例的总节点数为2,所以总并行度为4。
可以看到,并行查询也能极大的加快查询速度,如果只是临时对某个冷存表有查询需求,开启并行查询也可以满足这一要求。
总结
PolarDB MySQL针对冷数据查询性能的优化策略聚焦于两点:OSS文件筛选与OSS冷数据并行查询技术。OSS文件筛选机制通过目标列的预筛选,有效过滤无关数据,极大提升了查询效率,而OSS冷数据并行查询技术,则是用户可以灵活地灵活调节并行度,结合ePQ多节点并行进一步缩减查询延迟。