PostgreSQL 慢 SQL 优化分享
Author: 李海洋(陌痕)
概述
慢 SQL 是一个 DBA 无法绕过的问题,在云数据库快速崛起的时代背景下,也将成为云客户支持同学必须要面对的一个问题。因此本文将分享一些 PostgreSQL 慢 SQL 的优化思路,希望能够为读者在解决慢 SQL 问题时提供一些参考。文章先介绍了下背景,再提供了几种监控慢 SQL 的方法,然后再以具体的 case 为基础阐述了慢 SQL 产生的多种原因以及对应的解决方案。
背景
慢 SQL 是指执行时间较长的 SQL 语句。其中“慢”是一个相对值,不同场景下的标准也会不一样。例如:在一般场景下,执行时间超过 5s 的 SQL 可以称为慢 SQL;在高并发场景下这个标准可能就提高为 100 ms。
慢 SQL 是影响数据库性能最常见的因素之一,可能会造成以下几种危害:
- 造成 SQL 响应变慢,影响客户业务及用户体验;
- 增加系统负载、消耗系统资源,导致并发处理能力下降,过高的系统负载或资源占用,会导致数据库崩溃;
- 引发长事务,带来长事务的一系列影响,在 PostgreSQL 中可能会导致数据库年龄回卷,无法清理死元组等问题。
监控慢 SQL
首先,我们需要拿到慢 SQL, 因此需要对慢 SQL 进行监控,这里提供几种监控慢 SQL 的手段。
日志监控
PostgreSQL 中主要通过记录日志的方式对慢 SQL 进行监控,所以要确保实例打开日志收集功能,同时记录 SQL 执行时间作为参考。这些功能由对应的参数控制,这里列举出几个核心参数的参考值:
| 参数名 | 参数值 | 功能描述 |
|---|---|---|
| logging_collector | on | 开启日志收集功能 |
| log_min_duration_statement | 5000 | 记录执行时间超过 5s 的SQL语句 |
| log_duration | on | 记录每条执行完成SQL的执行时间 |
| log_statement | all | 记录所有执行过的SQL语句 |
其中,logging_collector控制实例的日志收集功能,修改后需要重启实例生效,日志监控 SQL 需要把这个参数打开。log_min_duration_statement表示记录执行时间超过设定值的 SQL,默认值为 -1,单位 ms,表示关闭功能,设置成 5000 表示记录执行超过 5s 的 SQL,如果有明确的执行时间标准,设定这个参数的值即可。如果没有明确的标准或者想监控其他 SQL 执行时间的情况,可以打开log_duration参数,同时把log_statement设置为'all'在这种场景下,日志会记录所有执行的 SQL,并且当 SQL 执行完成时会记录上它的执行时间。
日志记录内容示例:
LOG: duration: 5203.752 ms statement: insert into tab_test select i from generate_series(1,1000000)i;
pg_stat_statements 插件监控
PostgreSQL 提供了 pg_stat_statements 插件用于追踪一个实例执行的所有 SQL 语句的统计信息。这个插件更详细的介绍可以参考 PostgreSQL pg_stat_statements 插件文档。
如果要对数据库开启监控,需要在某个库创建 pg_stat_statements 插件,因为插件监控可以跨数据库,所以在任意一个数据库创建插件即可。为排除其他干扰,在监控开始之前建议先执行pg_stat_statements_reset()函数,清除之前的统计信息,之后可以通过查询 pg_stat_statements 视图来查看 SQL 执行的统计信息。例如,查看实例平均执行时间 Top 5 的 SQL 可以执行下面的 SQL:
SELECT * FROM pg_stat_statements ORDER BY mean_exec_time DESC LIMIT 5;
假如一个数据库中慢 SQL 较多或者性能影响较大,我们优先查看 pg_stat_statements 视图信息来确定解决慢 SQL 的优先级。因为一条执行时间为 1s 的 SQL 在一段时间内执行了 5000 次带来的性能影响要远比相同时间内一条执行时间为 100s 的 SQL 执行了 1 次带来的影响大。
pg_stat_activity 视图监控
PostgreSQL 提供了 pg_stat_activity 视图,用于查询当前实例的所有进程信息。pg_stat_activity 视图的更多介绍可以参考 pg_stat_activity 视图文档。
上面提到的两种监控方式,都需要 SQL 执行完成才会被监控到。在某些场景下,SQL 执行了很长时间也不会结束,遇到这样的情况可以通过查看 pg_stat_activity 视图,筛选出执行时间超过阈值,状态(state)为 active 的进程,得到执行 SQL 的信息。例如,查看 SQL 执行时间超过 100s 还未结束的进程可以执行下面的SQL:
SELECT (now() - query_start) as d_time, * FROM pg_stat_activity WHERE now() - query_start > interval '100' and state = 'active' order by d_time DESC limit 5;
云数据库厂商监控服务
随着云数据库产品的兴起,部分云厂商会提供云监控服务,其中也包括慢 SQL 监控能力和 SQL 分析能力。用户可以“一键”直达需要的监控信息,省去配置和分析的工作。例如,阿里云数据库提供了免费的慢 SQL 监控能力,以及可选的付费使用SQL洞察功能。
优化慢SQL
慢SQL常见产生原因
优化 SQL 之前,我们还需要了解下慢 SQL 产生的原因。导致 SQL 执行慢的原因有很多种,这里列出常见的几种原因:
- 实例硬件资源限制,例如CPU、内存、磁盘IO性能,服务器规格等影响;
- 客户业务 SQL 不合理,例如多张大表缺少join条件,添加无效、重复条件;
- 实例并发连接数过高,导致资源等待,进一增大连接数,产生“雪崩”现象;
- 实例存在锁阻塞问题,例如对热表进行truncate 操作,长事务长时间持有锁,阻塞其余 SQL;
- SQL 自身执行较慢,例如过滤条件缺少索引,优化器产生较差的执行计划,执行器内存受限,缺少某些场景的优化能力等。
其中 SQL 自身执行较慢涉及的因素较多,较为复杂,也是本文接下来要聚焦的场景。
查看执行计划
排查慢 SQL 首先要分析下 SQL 的执行计划。 PostgreSQL 中通过 EXPLAIN 指令查看执行计划。有关 EXPLAIN 指令使用方法参考介绍和指令。其中分析慢 SQL 常用的选项是 ANALYZE/BUFFERS/VERBOSE。PostgreSQL 的执行计划为树状结构,有关执行计划的解读参考 PostgreSQL 执行计划解读。
使用 EXPLAIN 指令查看 PostgreSQL 优化器给出的执行计划,主要关注下节点的执行方式,代价估计值。这一步能够让我们对优化器产生的计划有一个了解。然后,使用 EXPLAIN (ANALYZE) 得到带有实际耗时以及返回行数的执行计划。注意!添加 ANALYZE 选项会真正执行 SQL,针对 DML 的操作需要开启一个事务操作:
BEGIN;
EXPLAIN (ANALYZE) <DML(UPDATE/INSERT/DELETE) SQL>;
ROLLBACK;
排查优化
对于使用 EXPLAIN (ANALYZE) 能够得到执行计划的慢SQL,排查的基本思路为:自顶向下,筛查出耗时最多的节点(注意!每层节点显示的时间是包含下层所有子节点总共的执行时间,所以每层节点的耗时为本层节点耗时减去下层节点的耗时),重点分析这个节点的耗时的原因。如果优化后,依然不能达到要求,则循环上述步骤,直到满足要求。 在实际场景中,执行计划往往比较复杂,可以借助一些工具查看执行计划,提升效率,这里推荐一个执行计划解读工具。
接下来将通过具体的case来说明常见场景下的慢 SQL 优化方法,无特别说明,测试实例版本均为 PostgreSQL 14.12。
缺少有效索引导致慢 SQL
索引能够加速数据的访问,降低 I/O 访问, SQL 的过滤条件缺少有效索引是导致慢 SQL 的常见原因之一。 对于一个过滤条件,我们将选择率定义为 返回行数 / 过滤行数。数值越低,选择率也就越低,索引的选择性越好,表明对这个条件创建索引的收益越大。Btree 索引是最常用的索引,也是 PG 默认创建索引的类型,下文关于索引相关的分析,没有特别说明,都是指 Btree 索引。
case 1

这个 case 的执行计划比较简单,只有Seq Scan on t1一个计划节点,也是最多耗时节点。这个对应的过滤条件a = 1234的选择率很低,滤除了 999999 行,返回 1 行。这种情况是最常见的场景,即筛选条件列上缺少有效的索引,首要的优化方式为创建索引。
执行CREATE INDEX CONCURRENTLY on t1(a),可以看到执行时间降低了约 3 个数量级,优化效果明显。

注意!这里创建索引创建加上了CONCURRENTLY 选项,是为了避免索引创建过程中阻塞表上的DML操作,影响业务,一般情况下建议添加上这个选项。
case 2
实际使用中,一张表上可能存在多个筛选条件,相应地我们可以创建组合索引。例如:

执行CREATE INDEX CONCURRENTLY ON t1(a,b)后,执行时间降低了约 2 个数量级,优化效果明显。

但是,组合索引的过滤条件越多,对应的空间占用越大,索引更新速度越慢,所以在创建组合索引时,不推荐盲目对所有过滤条件创建索引。这里给出几条创建组合索引的建议:
- 优先选择不同值个数 (n_distinct) 多的列放在左侧:n_distinct 值越高,代表索引选择性越好的概率越大;虽然过滤条件都是 “=” 的条件下,这样并不能降低索引检索的 items,但是如果其他场景下需要这一列的单列索引(因为选择性好的概率大,所以被优化器选择的概率越大),就可以复用这个组合索引;这样既不用创建单列索引,同时也能有相同的加速效果。
- 将范围过滤的列放在等值过滤列右侧:B+ 树的结构决定了范围查询会全部扫描范围内的所有的 items,如果将范围过滤的列放在左侧,右侧的其他条件就起不到减少扫描 items 的作用,所以将范围过滤列放在等值过滤列的右侧,而等值过滤条件的排序则遵循 1 中的规则。
- 限制组合索引列的数量:虽然 PG 允许最多创建 32 列的组合索引,但是一般情况下建议组合索引列数不超过 5 列;对于存在多个组合的过滤条件,可以将组合中的公共组合提取出来创建一个组合索引;对于选择性较差的列,可以考虑从组合索引中剔除。
case2 中,我们拆分过滤条件看下执行情况(a = 1234的情况在 case 1 已经提供了,这里只列出b = 'same'的情况):

可以看到b = 'same'这个过滤条件没有过滤到任何一行数据,所以这个条件是无用的,因此这个场景下只执行CREATE INDEX CONCURRENTLY on t1(a)就能达到较好的加速效果:

对比创建组合索引的执行结果,可以发现,由于b = 'same'这个无用的条件加入了组合索引中,反而导致执行时间要长于只在 a 列上创建索引的场景。
上面提到的 n_distinct 等信息如何获取呢?PG 中会为每张表收集统计信息,统计信息中包含了我们需要的信息。借助 pg_stats 视图,我们可以找到表上每一列的 n_distinct/avg_width/null_frac/correlation 等信息来指导创建索引。例如 case 2 中 t1 的统计信息为:

a 列的 n_distinct 为 -1,表示 a 列中没有重复值(小于 0 表示不同值占总行数的比例),而 b 列中都是重复的值。所以 case2 中只需要对 a 列创建索引即可。
case 3
除了单列和组合索引外,SQL 中还会经常出现表的一列或多列计算而来的一个函数或者标量表达式的过滤条件,这种场景下也可以对表达式创建索引。例如:
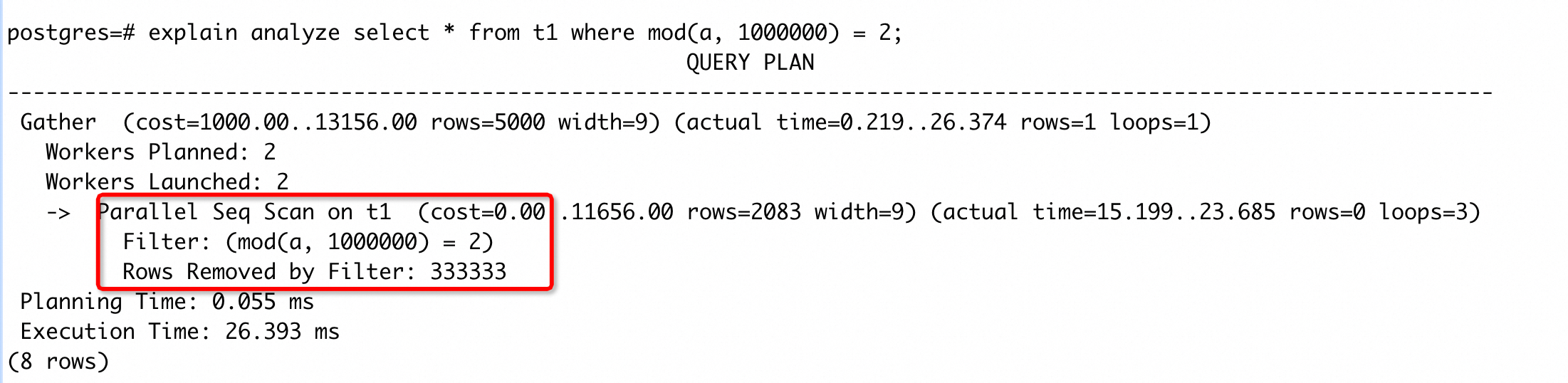
t1 表 a 列上存在索引,但是这种情况下不会使用,因为过滤条件是对 a 进行函数运算。我们可以执行CREATE INDEX CONCURRENTLY on t1(mod(a, 1000000))创建表达式索引。创建后的执行计划变为:

走了表达式索引,执行时间降低了 2 ~ 3 个数量级,加速效果明显。
使用表达式索引时需要注意,对应的函数属性必须要是 immutable(无论是函数还是表达式,最终都是调用到相应的函数,函数的属性可以参考函数易变性分类),这是因为生成表达索引时,每个 key 都是表达式计算后的结果,如果函数属性不满足要求,就可能会存在使用索引检索导致结果集错误的问题。索引表达式在进行索引搜索时不需要重新计算,因为它们的结果已经被存储在索引中了,但是索引的维护代价比较高,因为在每一个行被插入或更新时都得为它重新计算相应的表达式,所以表达式索引在 SELECT 频率远大于 INSERT/UPDATE 频率的场景下非常有用。然而,PG 并不会对表达式收集统计信息,PG 14 开始支持手动创建表达式统计信息(本文后续会进一步补充,这里不展开),但是只提供了机器亲和的视图,并没有提供一个类似 pg_stats 的视图,所以我们需要自己结合函数的行为来估算下表示索引的选择性。
case 4
case3 中表达式的过滤条件明确在 SQL 中给出了,我们会自然地考虑表达式索引是否可以加速 SQL 执行。但实际中还存在另一个常见的情况:隐式类型转换导致列上被加上了类型转换的操作(PG 中使用::操作符表示类型转换)。隐式类型转换是因为系统内部没有完全匹配的操作符,从而将部分类型转化成另外的类型后再匹配操作符进行运算。这种情况经常发生在两个变量的运算中(比如 join 的连接条件中),来看一个具体 case:
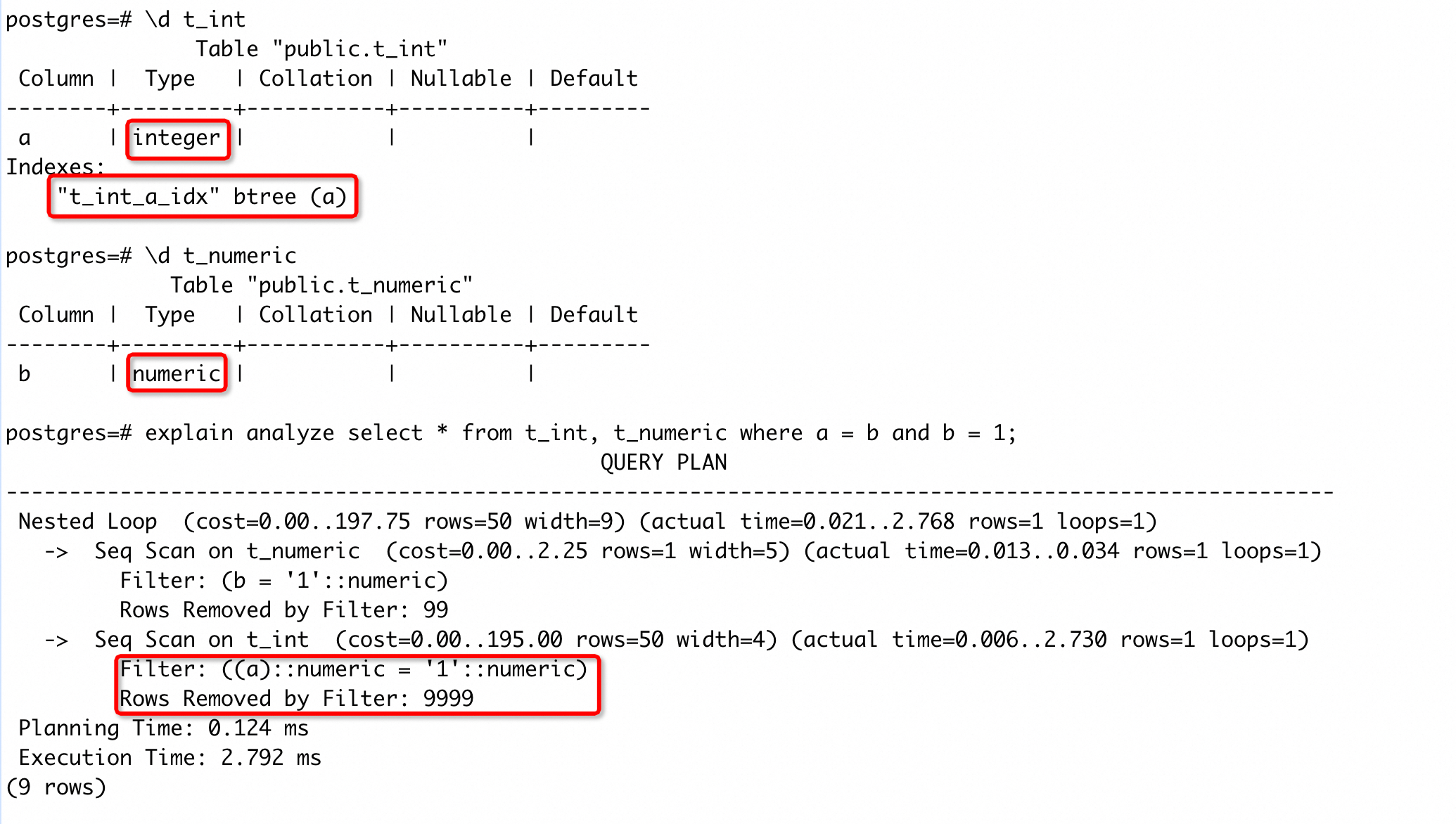
可以看到,t_int 表 a 列上存在索引,但是查询中却没有使用这个索引,执行计划中的过滤条件是(a)::numeric = '1'::numeric。因为 PG 中没有=(int, numeric)的操作符,所以系统会先做(a)::numeric,然后再调用=(numeric, numeric)(具体的转换策略可以参考源码oper_select_candidate()函数)。
经过隐式转化后,列上会带上类型转化的操作(可以通过执行计划看到添加转化),所以 a 列上的索引就不能被使用了。我们执行CREATE INDEX CONCURRENTLY ON t_int((a::numeric))后,再次执行的执行计划为:
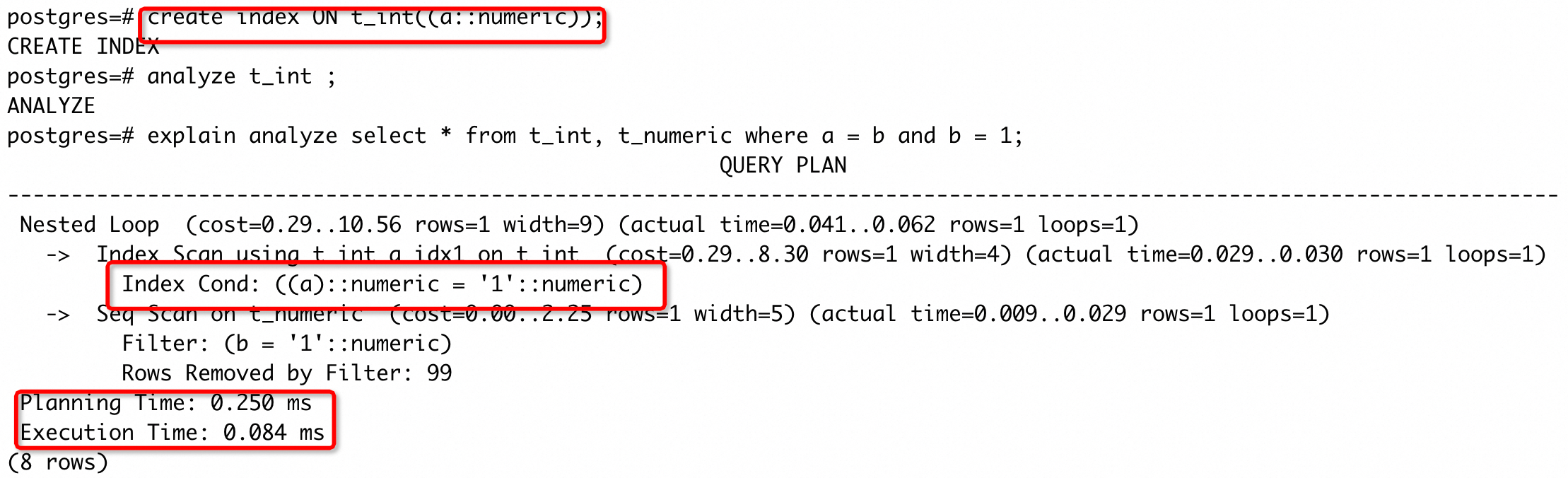
可以看到走索引了,执行时间也降低了两个数量级。
这里再补充一下:创建索引(特别是对大表、热表)是一个重操作,在经过上面的判断之后,我们还可以借助一些虚拟索引的插件(例如 hypopg )来进一步佐证期望创建的索引是否有加速效果(使用 explain 指令看下生成计划会不会选择创建的虚拟索引),尽量避免索引创建后起不到加速的情况出现。
代价估计误差导致慢 SQL
PG 的优化器是基于代价的优化模型(CBO),在执行计划上最直接的体现是每个节点输出的 cost 值。简单理解,优化器在大多数情况下会在候选集中选择总代价最小的执行计划。此外,执行计划节点 cost 后还带有一个返回函数 rows 的估计值,这个估计值也会影响计划的生成(例如在选择 join 方式时)。然而,估计值会存在一定的误差,在某些场景下,会导致优化器输出一个执行较慢的计划,产生慢 SQL(不同场景下 cost 和 rows 的估计策略也不同,这里不作展开)。
估计误差导致慢 SQL 的常见场景,大致可以分为两类:1)计划的总 cost 估计误差导致慢 SQL,2)某些计划节点 rows 估计误差导致慢 SQL。
case 5

这个 case 中 t2 只有 3 条数据 ,并且在过滤条件的列上创建了索引,但是优化器基于代价的估计,选择了 Seq Scan,当前这个计划是最快的执行计划。为模拟数据变动,紧接着在 t2 中插入 1000 行数据,再次执行 SQL 得到的执行计划为:

可以看见执行计划依然没有改变,但此时已经不是最优的执行计划了。产生这个现象的原因是什么呢?
PG 优化器计算代价时要依赖统计信息(主要的统计信息在 pg_stats 中可以看到,还包括一些其他系统表(如 pg_class )记录的信息),但是这些统计信息的更新是异步的(有一定延迟和触发条件)。这就产生了 SQL 操作对象的数据分布已经发生了变化,但是优化器生成计划还是利用变化前的统计信息的情况,很可能会让估计误差进一步加大,产生慢 SQL。
PG 提供了一个 autovacuum 守护进程(本质也是一个后端进程,但是实例启动时会默认拉起),这个进程主要包含两部分工作:定期 vacuum 和 analyze。vacuum 主要是清理数据库的垃圾数据,而 analyze 主要是收集统计信息。autovacuum 中的 analyze 触发需要满足一定的条件,默认情况下受autovacuum_analyze_scale_factor和autovacuum_analyze_threshold控制,也可以单独对某张表单独设置这两个参数的值,定制化触发条件,在大表中调整这两个参数可能会很有用。autovacuum 触发 analyze 的阈值计算逻辑为:
threshold = autovacuum_analyze_threshold + autovacuum_analyze_scale_factor * table_total_row_number;
PG 也提供了 ANALYZE 命令用于手动收集统计信息。对于 case4,我们手动执行ANALYZE t2,再次执行 SQL 得到的执行计划为:

可见优化器已经选择了 Index Only Scan,执行时间也降低了一个数量级。我们再看下手动收集统计信息后,强制走Seq Scan的执行计划:

没有手动更新统计信息前,Seq Scan 的整体cost 为 5.19,而收集后 cost 变为 17.54。收集后 Index Only Scan 的整体 cost 为 8.31 小于 Seq Scan,所以优化器就选择了前者,执行时间更短 。
默认情况下 autovacuum 每 60s 触发一次。我们可以通过 pg_stat_all_tables 视图 来查看表最近一次收集统计信息的时间,如果表的数据更新过快,或者数据变动长时间没有触发自动ANALYZE的条件,可以先尝试对目标表进行手动ANALYZE 收集统计信息,再验证执行计划。
case 6
如果上面的尝试能解决问题,那将是十分愉快的,但是事情可能没有那么顺利。
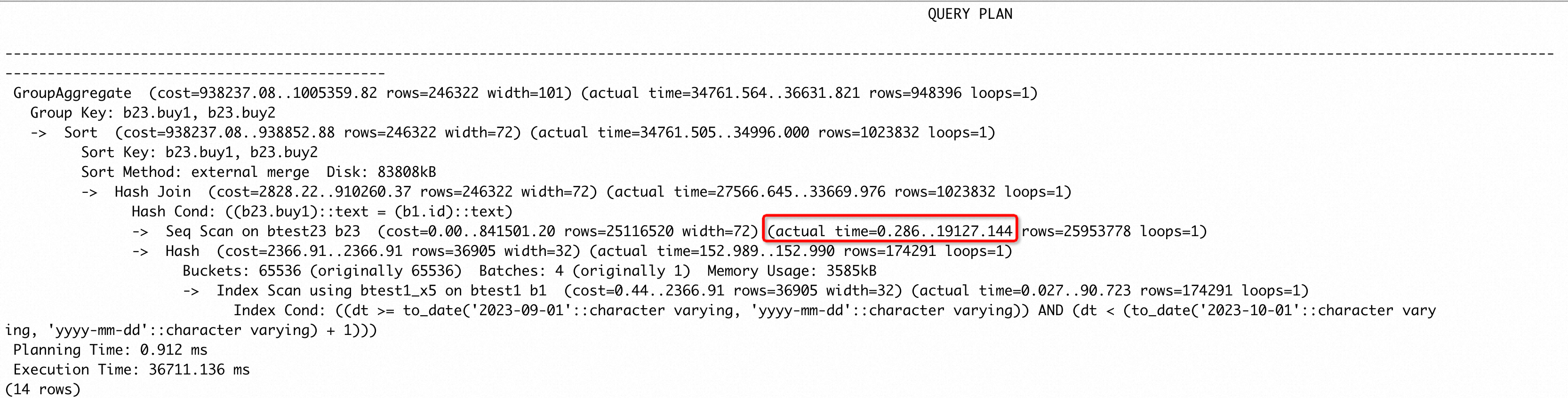
这个 case 中框选的节点耗时超过了整个执行时间的 50%,并且b23.buy1上存在索引,猜测采用nestloop + index scan b23的执行时间会更短(通过set enable_hashjoin to off,强制走 nestloop 发现确实如此)。而对btest1、btest23 两张表进行 ANALYZE 后,发现执行计划并没有改变。这种场景如何处理?
PG 中的统计信息实际是通过对列上采样的样本进行分析得到的,而default_statistics_target就是控制样本数量的参数(默认值为 100),它的值与最终的采样个数呈正相关,具体的采样策略可以参考论文 [1]。对于 tuple 较多的表,样本值占总体数量的比例较小,可能会导致统计信息存在较大误差。因此,可以适当提高default_statistics_target的值,降低统计信息的误差。我们可以通过 set 指令仅在当前 session 提高样本值,然后对目标表进行 ANALYZE;也可以针对目标表列执行 SET STATISTICS,默认提高这一列的采样样本数量。
注意:ANALYZE 会持有最低级别的表锁(AccessShareLock),一般只会和 DDL 有表锁冲突,执行不会对业务有较大的影响,只是调大采样数后会消耗更多的 CPU 和 IO 资源。
观察到 btest23 中有 25953778 行,猜测统计样本量太少导致产生较慢的执行计划。执行set default_statistics_target to 1000,再次 ANALYZE 收集统计信息,得到了我们期望的执行计划:
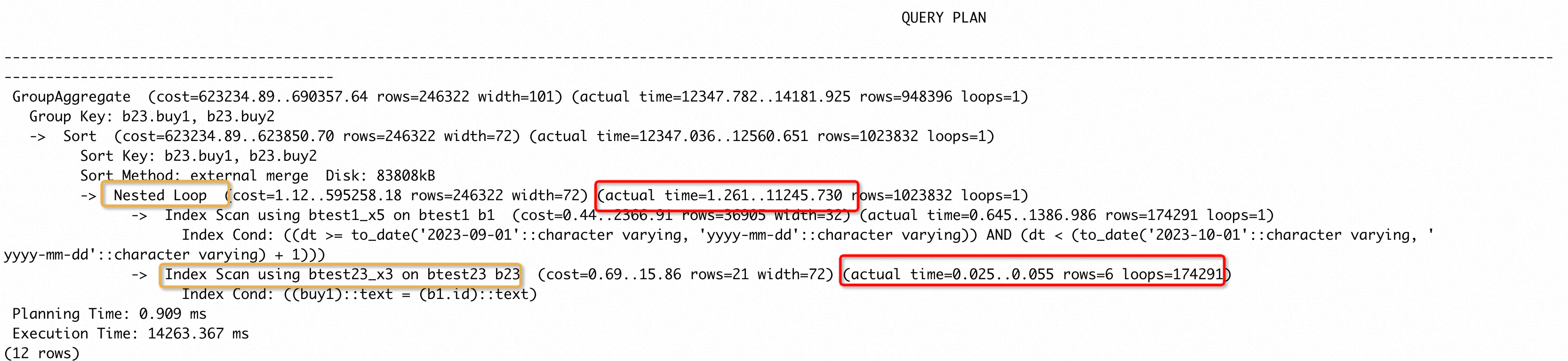
可以看到 btest23 使用了 index scan,并且总耗时为 0.055x174291=9586.005 ms,要远小于原来的 19127.144 ms。这个计划中将连接条件b23.buy1 = b1.id下推到了 b23 表上,作为 index cond,这实际是利用到了 PG 优化器提供的谓词下推能力。同时我们观察到 b23 单次 index scan 的时间很短,因为 nestloop 内表被 loop 了很多次,执行时间变长,那可不可选择 hashjoin 或者 mergejoin,既不会 loop 多次也能使用谓词下推走 index scan 呢?很遗憾,PG 的谓词下推能力只能在 nsetloop 中使用,并且只能作用在内表(非驱动表)。
如果我们遇到对表进行多次 ANALYZE 依然不能改变慢SQL的执行计划,特别是涉及到表行数较大时。这个时候,我们可以考虑调大default_statistics_target参数的值,再次对表进行 ANALYZE。
case 7
有些场景下,即使能够收集到正确的统计信息,优化器也不能给出一个执行时间更短的执行计划。例如,有一张 test 表,表的结构如下:

其中 a、b两列的数据完全一致。执行如下SQL得到执行计划:
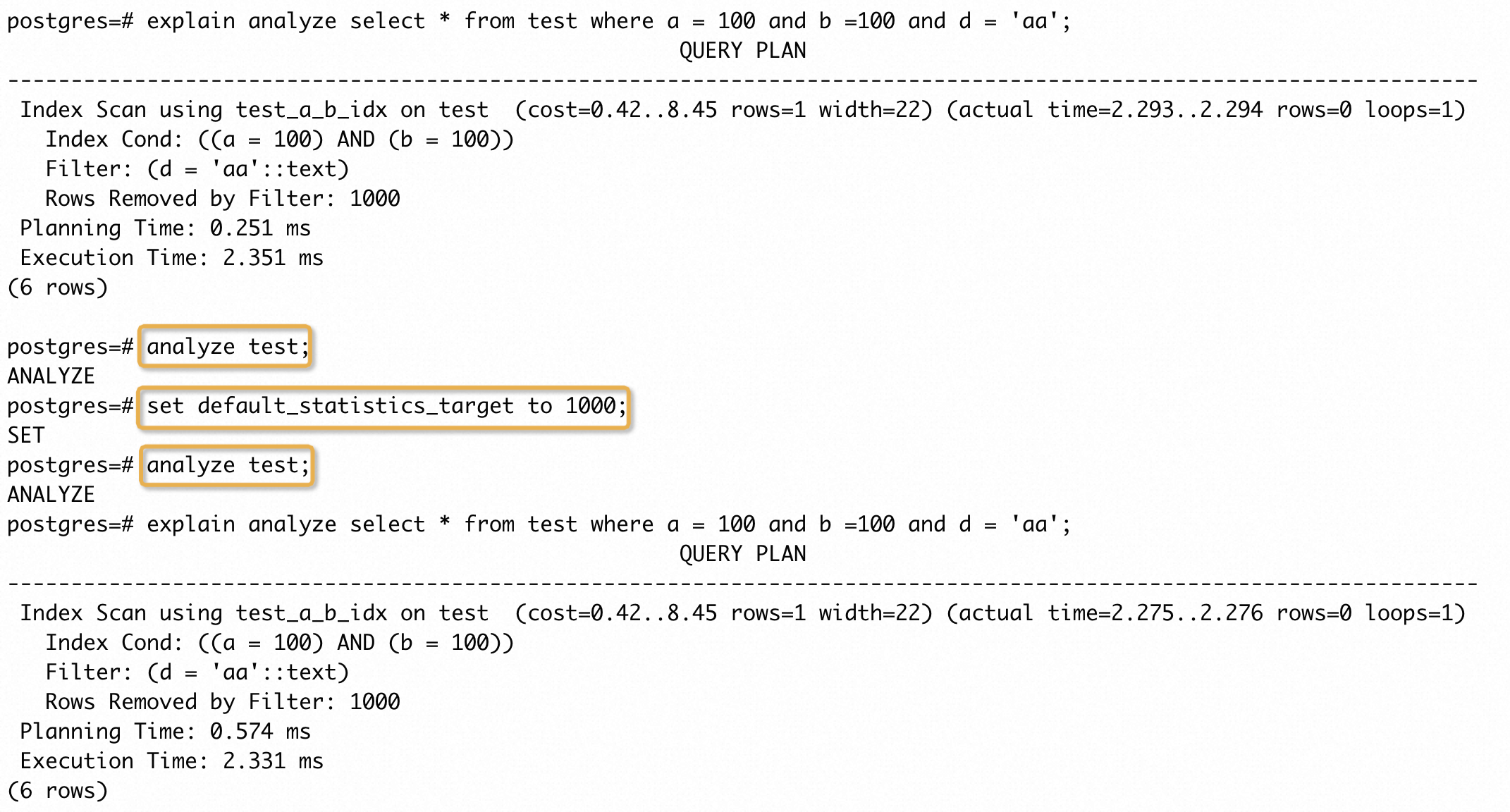
可以看到,按照前面的步骤操作并没有缩短 SQL 执行时间。这个 case 中存在两列完全相同的数据,但是优化器并不知道这个信息,默认情况下,优化器会认为两列完全独立,进行行数估算时很大程度上会严重偏小。这里a = 100 and b =100的行数估计基本为 1(PG 中即使算法得到的行数估计不超过 1,都会设置为 1,这是为了避免后续节点产生额外的处理逻辑和无效结果,比如除以 0 情况)。因此,加上基于整体代价的衡量,优化器大概率会选择列数少的索引,这里就选择了(a, b)的索引。
如果想得到期望的执行计划,需要提供额外的统计信息,PG 提供了创建扩展统计信息的能力,用于解决这类问题。上面就是扩展统计信息支持的最常见的场景,即一张表多个列之间的数据有较强的关联性,可以创建 dependencies 扩展统计信息。
手动创建 a、b 两列的扩展统计信息,再次执行SQL:
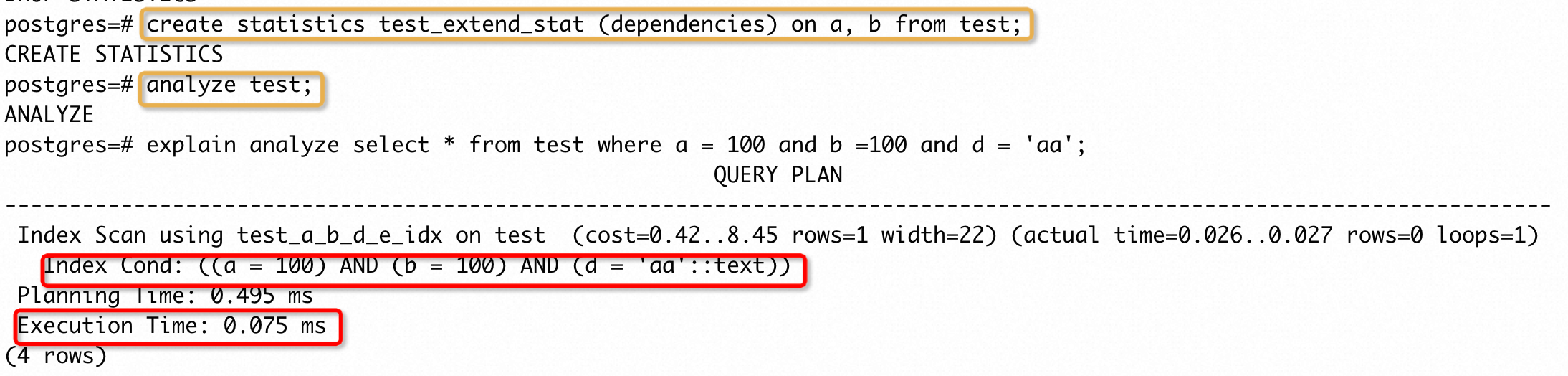
创建扩展统计信息后,优化器不会将 a、 b 列的过滤条件当成是相互独立的存在,所以不会认为只需要 a、b 列的过滤条件就能筛选得到很少数量的结果,因此采用a、b、d、e 的组合索引进行筛选,从而使得执行时间降低了1~2个数量级。需要注意的是,PostgreSQL 中扩展统计信息目前仅对单表生效,在join的条件下不起作用。例如:
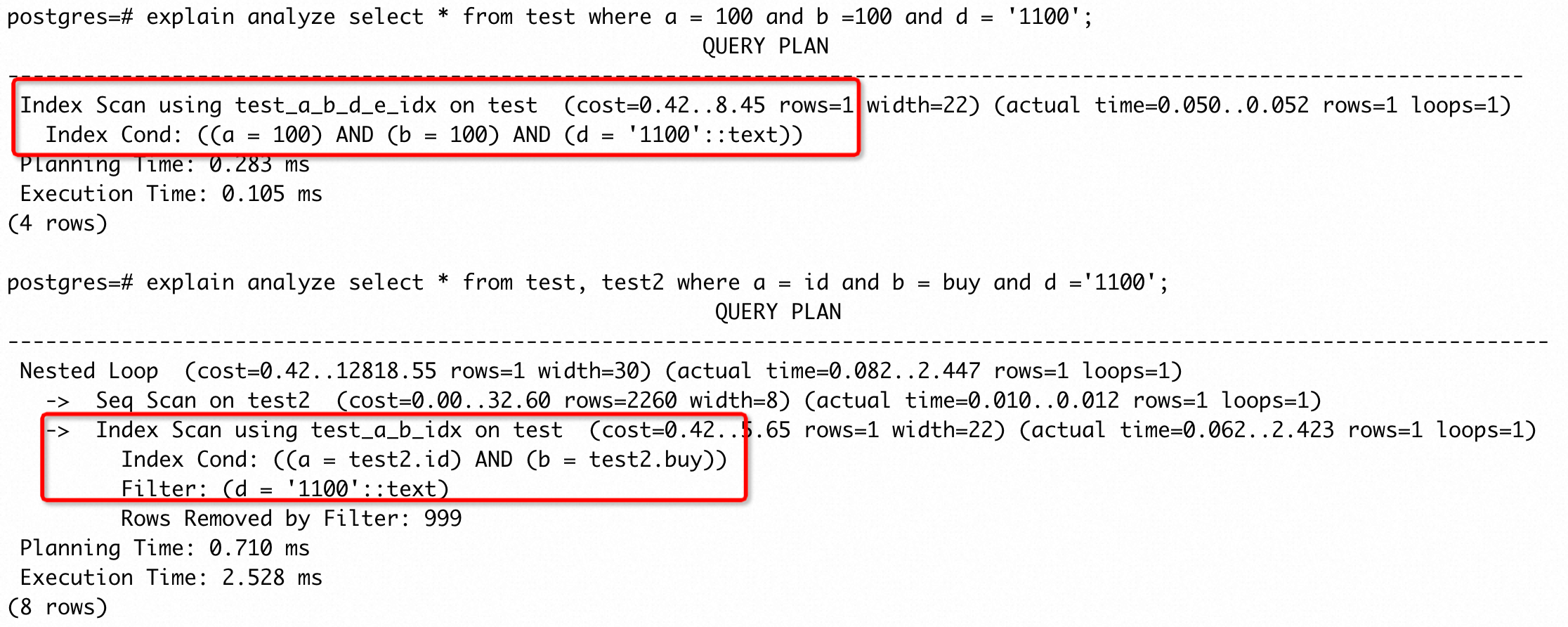
虽然为 a、b 两列创建了扩展统计信息,但是在 join 条件中,扩展统计信息并没有改变执行计划。
case 8
从 14 开始,PG 支持了一个新的扩展统计信息–表达式统计信息,这个提供了类似表达式索引的好处,但是不需要额外维护一个索引。我们再看这样的一个 case:
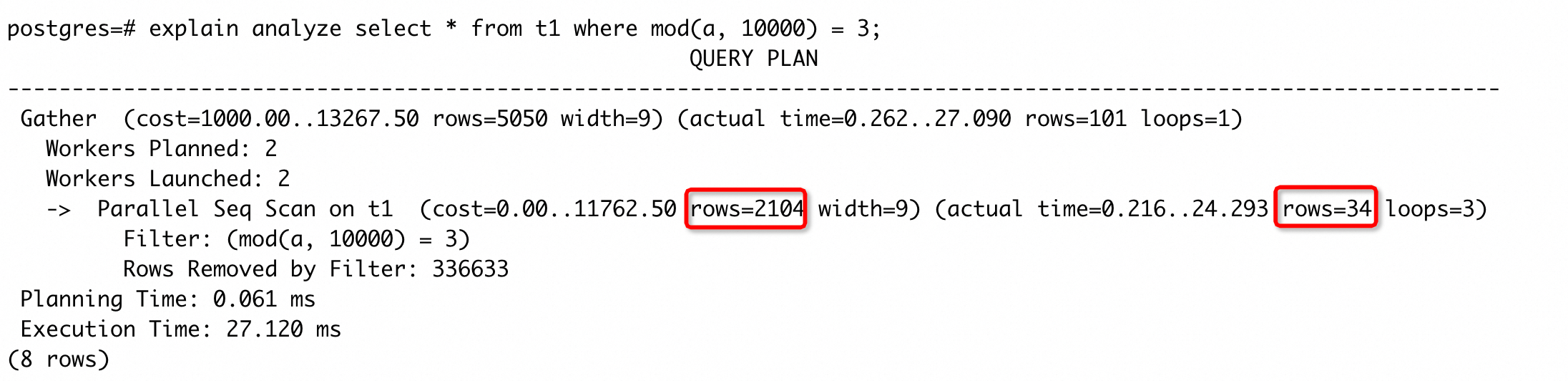
执行计划中估计的 rows 和实际返回的 rows 差距较大。我们执行CREATE STATISTICS t1_mod_stat on (mod(a, 10000)) from t1创建表达式统计信息,然后手动收集统计信息,再次执行 SQL 得到执行计划:
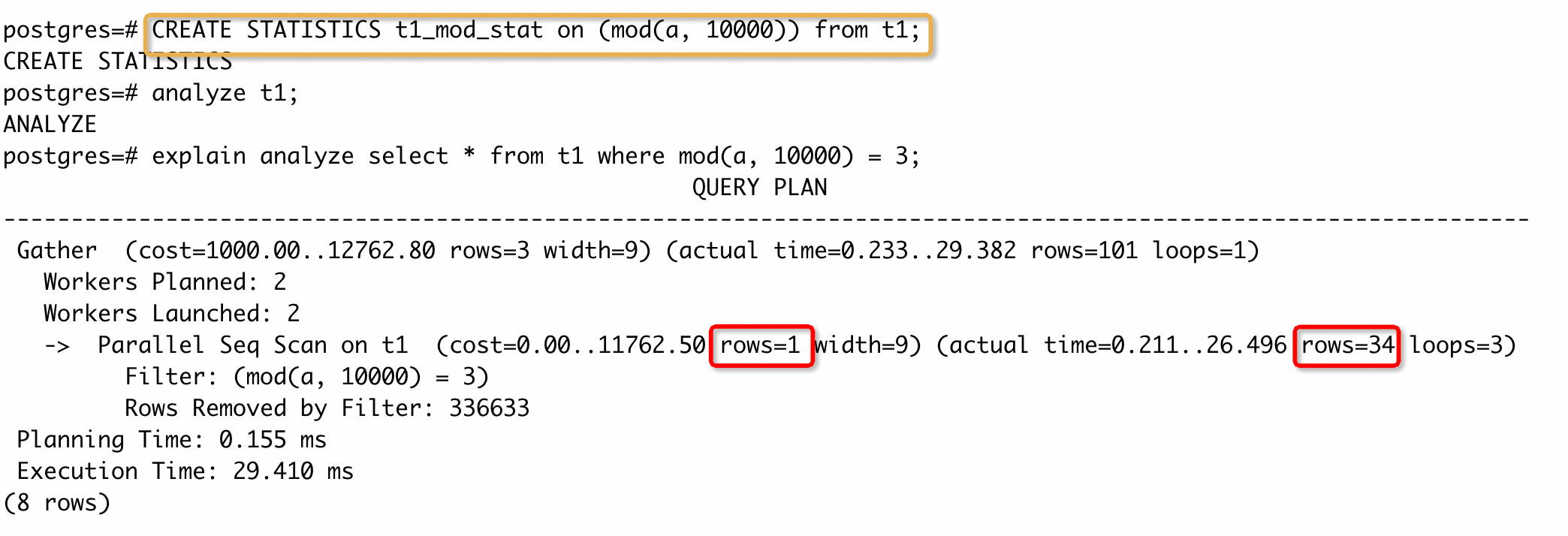
可以看到,rows 估计误差已经明显降低,但是还有一定的差距。这个差距是统计信息采样个数少导致,我们增大default_statistics_target之后,再次收集统计信息,得到执行计划:
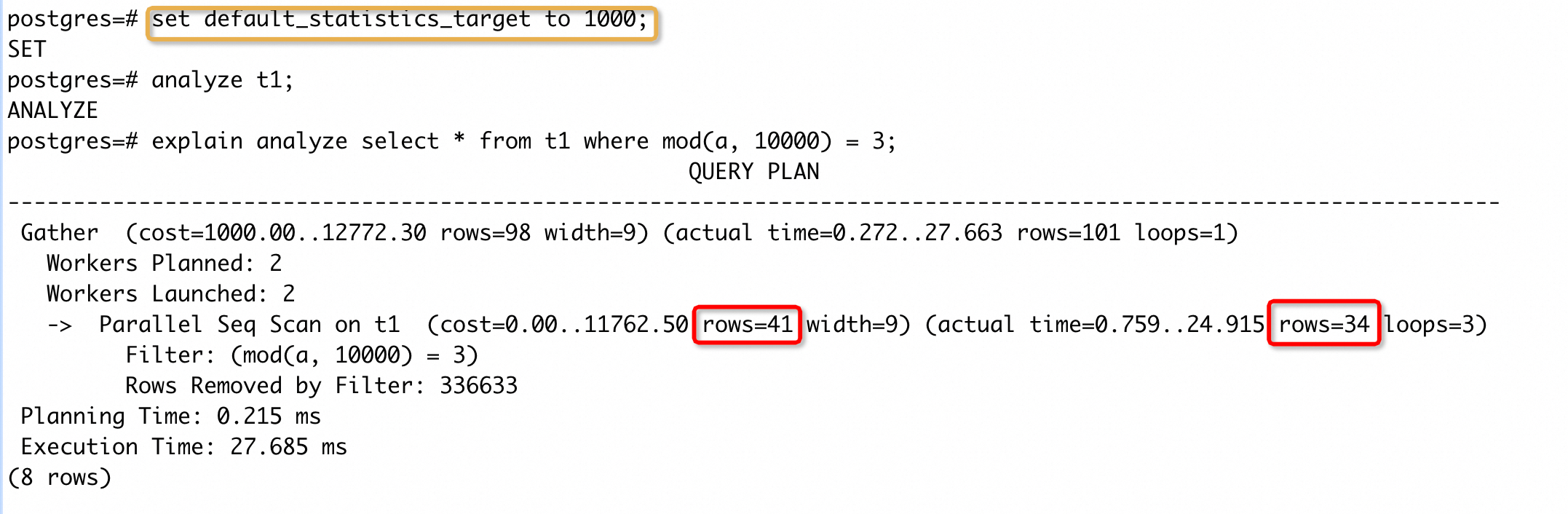
可以看到,rows 估计误差进一步缩小,比较接近实际返回的行数了。这个 case 主要为了展示表达式统计信息的能力,并没有构造一个能加速 SQL 执行的场景,但是 rows 估计误差变小,能大大降低 SQL 变慢的概率,具体能加速的 case 在后文中给出。
除了这里提到的 dependencies 和 表达式扩展统计信息,还存在其它形式的扩展统计信息,感兴趣的同学可以查阅资料进一步了解,这里就不再展开。提供扩展统计信息的本质目的是为了避免优化器在多个过滤条件时,对返回的rows 数量进行严重的低估(比实际返回 rows 低1~2个数量级及以上),产生执行慢的计划。
误选 nestloop join 导致慢 SQL
nestloop/hash/merge 是 PG 支持的三种 join 方式。其中 nestloop join 的特点是外表(驱动表)返回多少行数据,内表就相应被 loop 多少次。因此选择 nestloop join 的主要影响因素就是对外表 rows 估计值,若 rows 估计值很小,优化器有很大概率会选择 nestloop join。如果外表的 rows 被严重低估,优化器选择了 nestloop join,就会导致内表的执行次数被 loop 多次,将执行时间放大,引发慢 SQL。这里产生慢 SQL 的原因本质上还是估计误差大导致,但是这类是比较常见的场景,并且也存在一些特殊情况,因此单独作为一类场景进行说明。
case 9
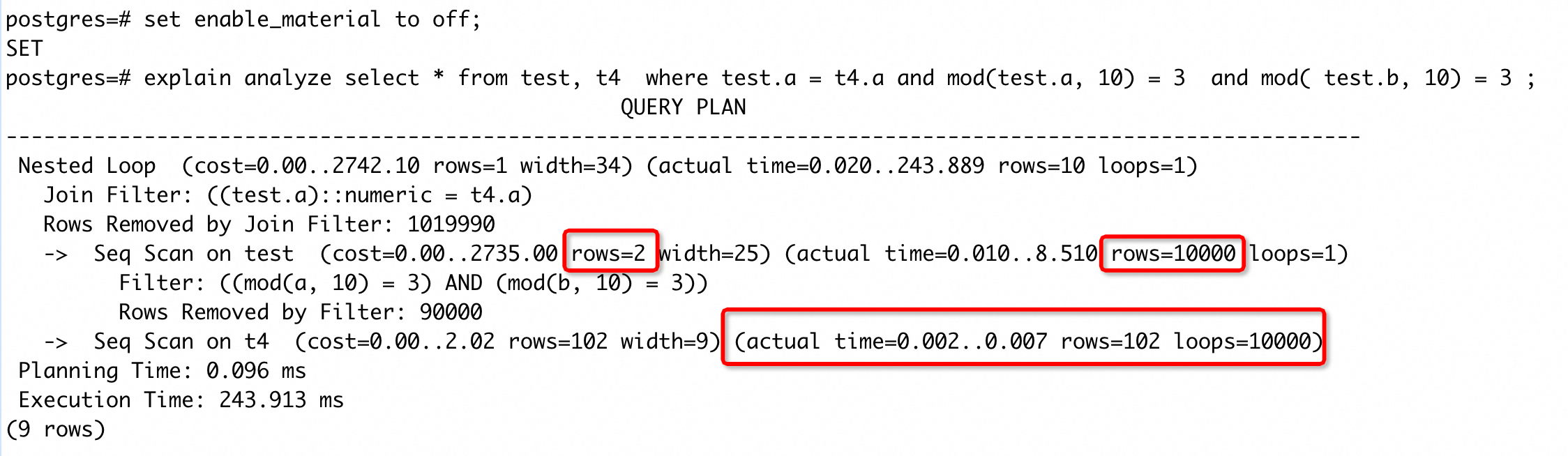
为了避免额外的理解成本,将优化器物化(material)功能关闭,不影响整体执行计划。这个计划中,test 表因为是表达式的过滤条件,导致对 rows 的估计值为 2,而实际返回 rows 为 10000,存在较大误差。而优化器也因为较小的 rows 估计值选择了 nestloop join,导致 seq scan on t4 操作被 loop 了 10000 次,执行时间约为 70ms(虽然这个 SQL 的主要耗时点是在 join filter 上,考虑在 t4(a) 上创建表达式索引也可能是一种解法,但这里旨在说明错选 nestloop 的影响,所以就不考虑这种方式)。
如果 seq scan on test 的 rows 估计值能够尽可能接近实际值,优化器就会倾向选择其他的 join 方式。我们对 test 表创建上表达式统计信息后,再次执行得到执行计划:
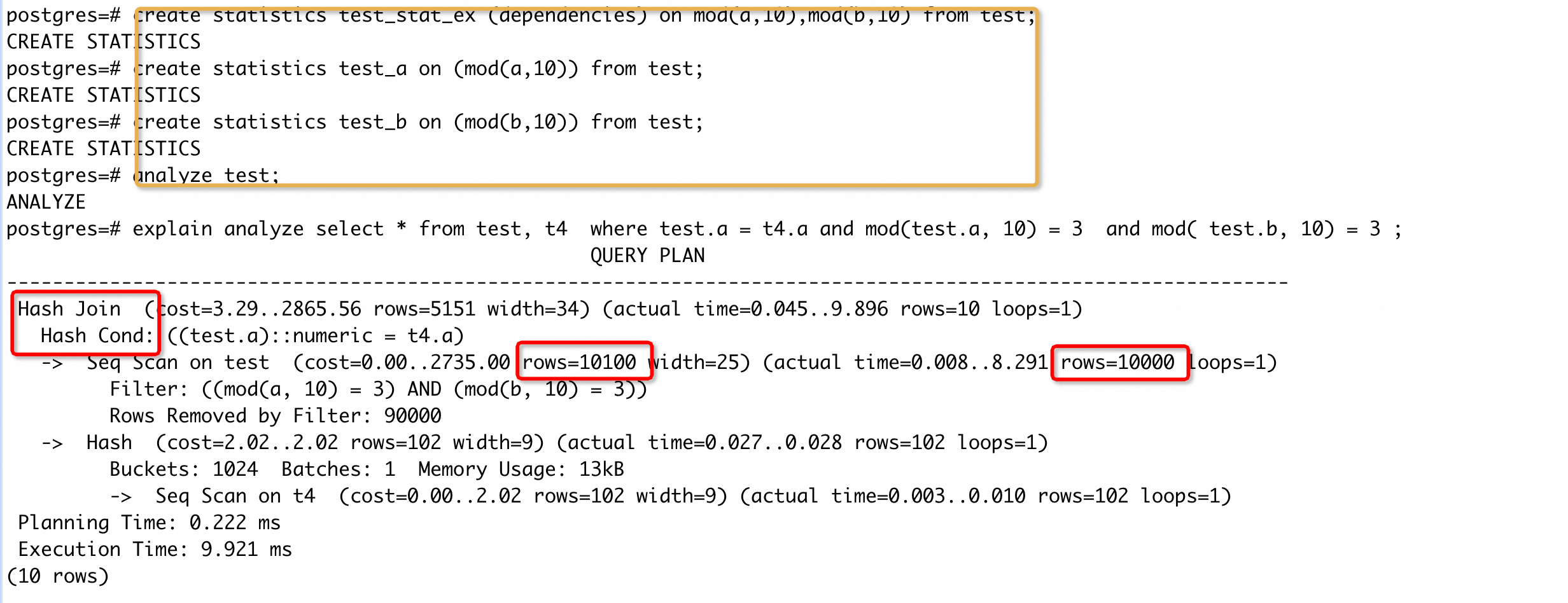
可以看到 seq scan on test 的 rows 估计值很接近实际返回值,优化器选择了 hash join,执行时间降低约两个数量级。
从上面分析中可以看到,错选 nestloop join 很容易将执行时间放大,对于这种情况我们要保持一个敏感度。如果仅使用 EXPLAIN (不加 analyze 真正执行)发现计划中有 nestloop,并且长时间执行不出来,可以先尝试下set enable_nestloop to off再次执行下 SQL,如果能较快执行完成,大概率是错选了 nestloop join。
case 10
有些情况下,即使估计误差较小,优化器还是选择了执行慢的执行计划,或者有些能力在使用的版本中没有,亦或者 SQL 过分复杂分析误差根本原因困难,这种情况下我们应该如何应对呢?
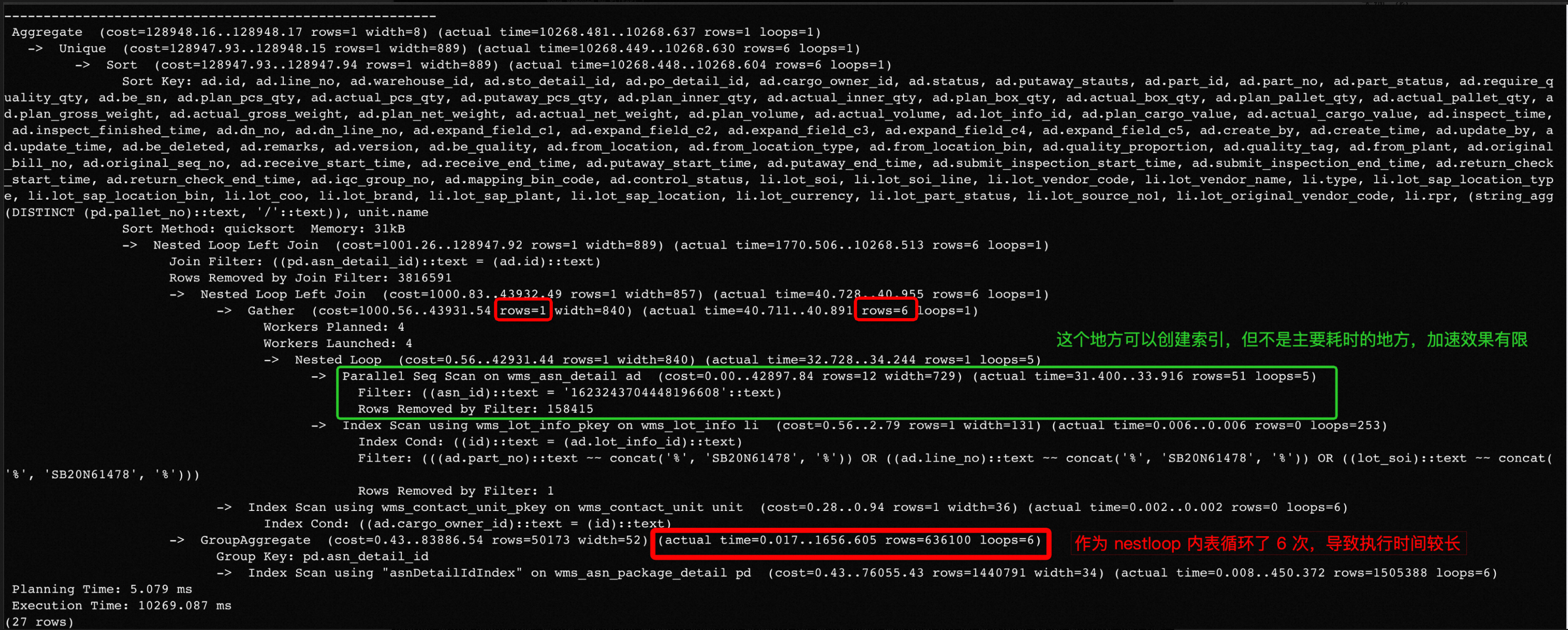
这个执行计划中,主要耗时点是 CroupAggregate 节点被 loop 了 6 次,但是上层 rows 估计误差相对来说较小。增大统计信息采样个数,手动收集统计信息等方式都没能改变执行计划,并且版本缺失表达式统计信息的功能。手动关闭 nestloop join 后,得到的执行计划为:
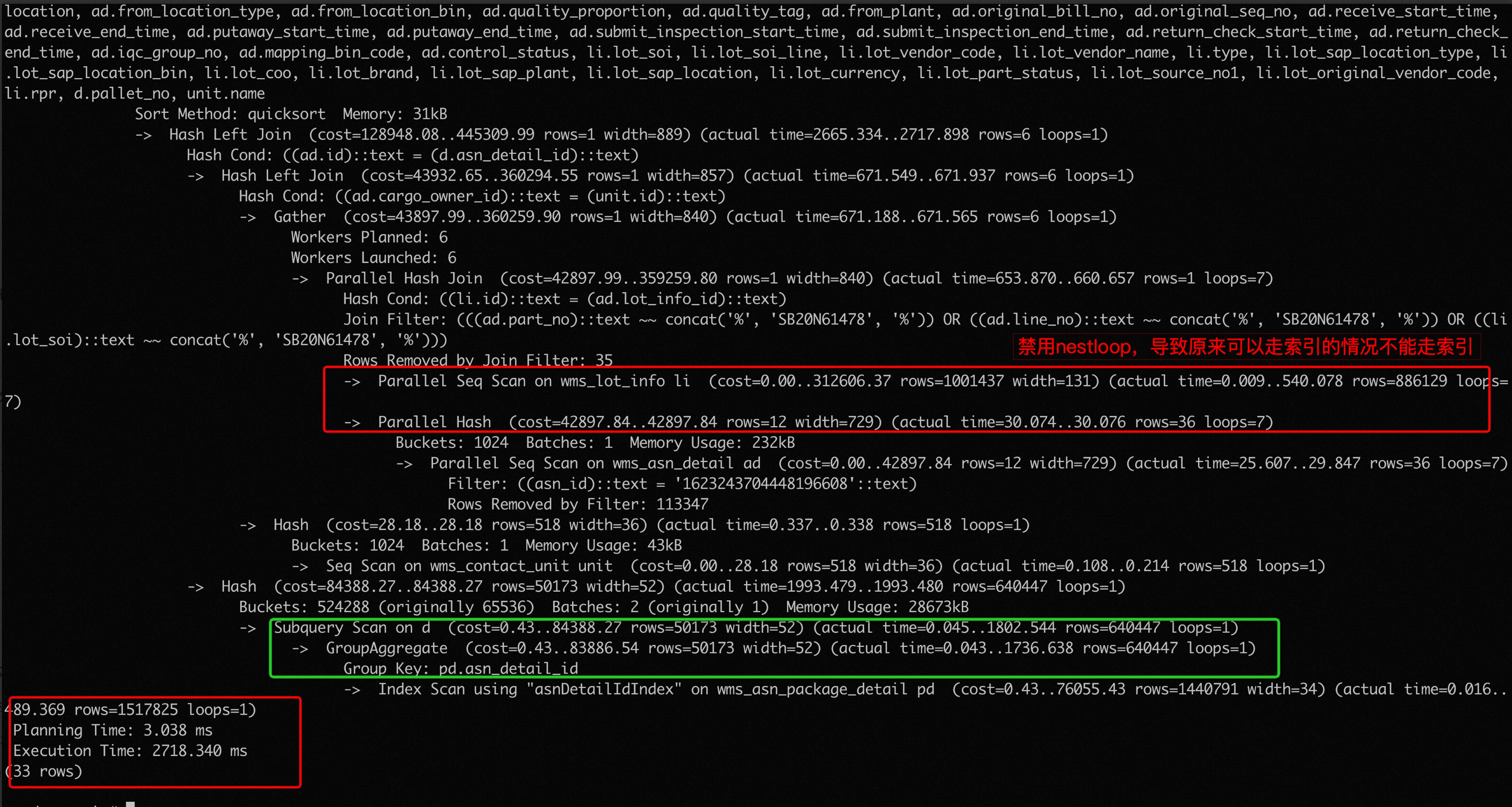
将 nestloop 禁掉后,可以看到选择了 hashjoin,执行时间降低了 80 %。同时可以看到因为禁用 nestloop 导致原来走索引的情况不能走索引,出现了新的耗时点。
上面的做法看似将问题解决了,但是在实际生产中却不能应用。因为无论是 session 内关闭 nestloop join,还是全局关闭,都会影响其 SQL,可能会产生新的慢 SQL,所以我们期望只对目标 SQL 关闭 nestloop,而不影响其他 SQL。
数据库中一般采用 hints 的方式,即在 SQL 注释中给优化器传递一些信息,干预这一次的优化器的行为。PG 内核中没有支持 hint 功能,但是有一个 pg_hint_plan 生态插件提供了丰富的 hint 能力。如果数据库安装了 pg_hint_plan,就可以在 SQL 中添加/*+ Set(enable_nestloop off) */ hint,让这条 SQL 执行期间不能走 nestloop join。这里补充一下,PG 中禁用某种计划方式,是将采用这种计划 cost 设置为一个很大的值(10000000000),然后利用代价淘汰的策略,将计划淘汰掉,假如没有其他路径把它淘汰掉,最终这条路径依然会保留,体现在执行计划上就是 cost 是一个极大的值。
使用 hint 能够让我们的控制只在某个 SQL 中生效,不影响其他 SQL,但是相当于对优化器添加了一条基于规则(RBO)的判断标准,所以也会产生一些负面影响。比如上面 SQL 中,虽然禁用了 nestloop,整体的执行时间降低了 80% ,但是内层如果依然能使用 nestloop,执行时间将进一步降低。因此,我们建议在前面方式都尝试过之后,再考虑添加 hint。另一个理由是,添加 hint 需要修改 SQL,推动修改 SQL 也是一层阻力,比如客户不想改 SQL,或者 SQL 文本由软件自动生成,找不到修改的入口。
函数属性导致慢 SQL
| PG 中支持用户定义函数(UDF),对应的指令是 CREATE FUNCTION。函数中有一些属性会影响执行计划的生成,主要有表示函数稳定性的属性(IMMUTABLE | STABLE | VOLATILE)和并行的属性(PARALLEL SAFE | RESTRICTED | UNSAFE)。下面简单解释下这些属性的含义: |
- 稳定性属性
- IMMUTABLE:表示不能修改数据库,对于给定的参数值总是任何时候返回相同的值,对于优化器来说,可以在 planning 阶段进行优化;
- STABLE:表示不能修改数据库,对于给定的参数值,它在一次扫描中返回的结果相同,在 planning 阶段特别是生成能够复用的计划时不能被优化,因此只能在 execute 阶段做优化;
- VOLATILE:定义函数时的默认属性,在任何一次执行时结果都有可能改变,因此不能做任何优化,实际应用中符合这类要求的函数比较少;PG 中 random()/nextval()/currval() 等内置函数的稳定性为 VOLATILE;如果函数中会修改数据库(具有副作用),即使返回结果是可预测的,也都应该标注为 VOLATILE。
- 并行属性
- PARALLEL SAFE:表示能够进行并行操作,优化器可以生成并行计划,并且每个并行 worker 可以执行这个操作;
- PARALLEL RESTRICTED:表示只能够在 Leader 进程运行,不能出现在 Gather/Cather Merge 节点下面,但优化器能生成并行计划;
- PARALLEL UNSAFE:定义函数时的默认属性,表示不能够进行并行操作,SQL 中只要有一个 UNSAFE 的函数,那整个 SQL 就一定不会生成并行计划。
case 11
创建函数时,如果我们忽视了对函数相关属性的设定,就会采用默认行为。如果 SQL 中使用到了函数,将有可能让数据库的优化能力退化,产生慢 SQL。我们来看这样一个 case:
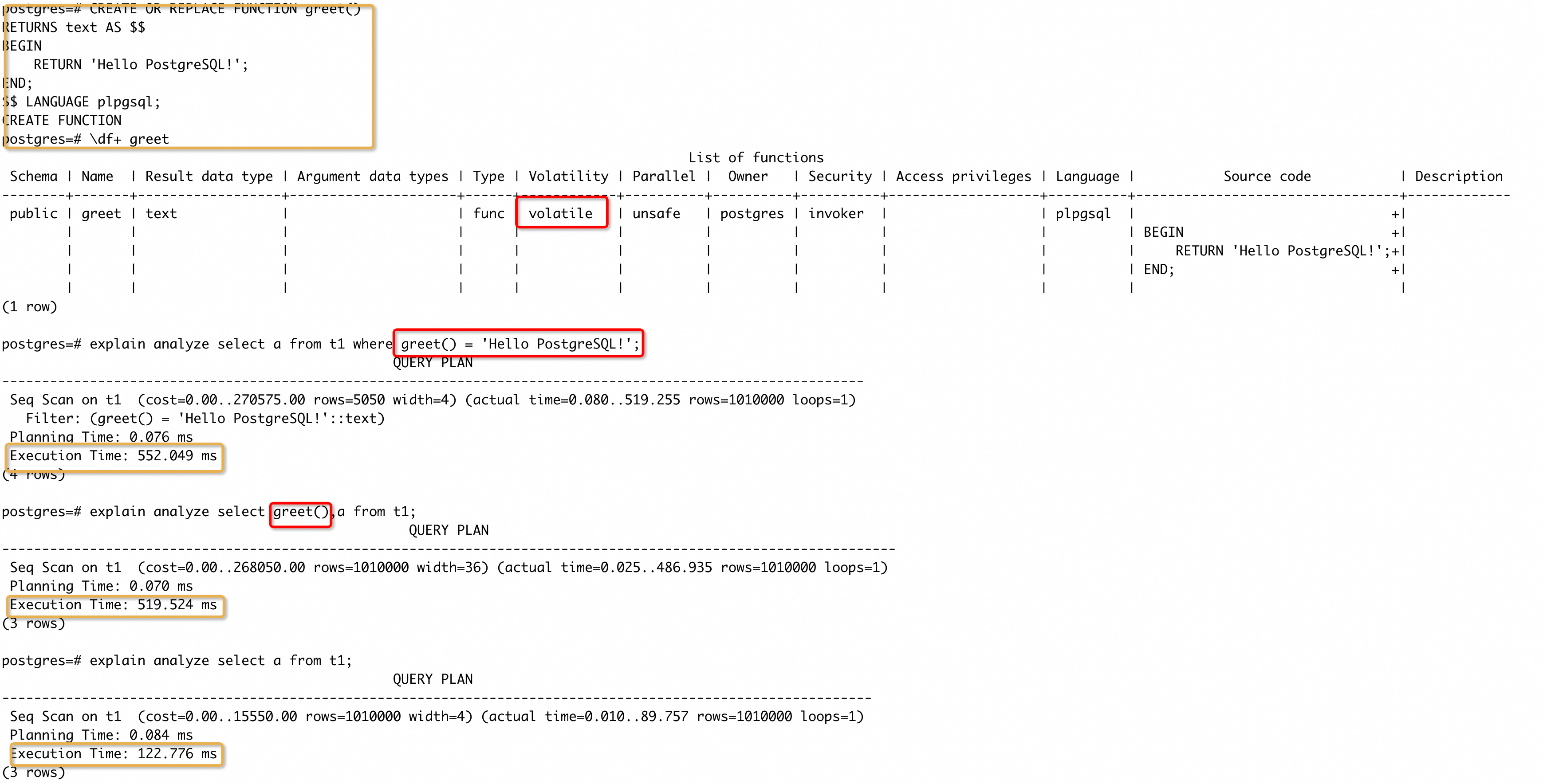
我们创建一个 greet() 函数,只返回一个常量,按照上面的介绍,正确的属性应该是 IMMUTABLE。但是我们在创建的时候没有指定属性,所以使用了默认的属性 VOLATILE。然后我们执行了三条 SQL,分别是在 WHERE 条件中使用函数、在输出列中使用函数和不使用函数。可以看到不使用函数的执行时间明显少于另外两条 SQL,而使用函数的两条 SQL 执行时间基本相同,产生的原因是数据库不会对 greet() 函数做任何优化,每处理 t1 一个 tuple,就会调用一次函数(无论是在输出列中还是在过滤条件中),导致了额外的耗时。
我们再将函数的属性改为 STABLE,看下三条 SQL 的执行情况:
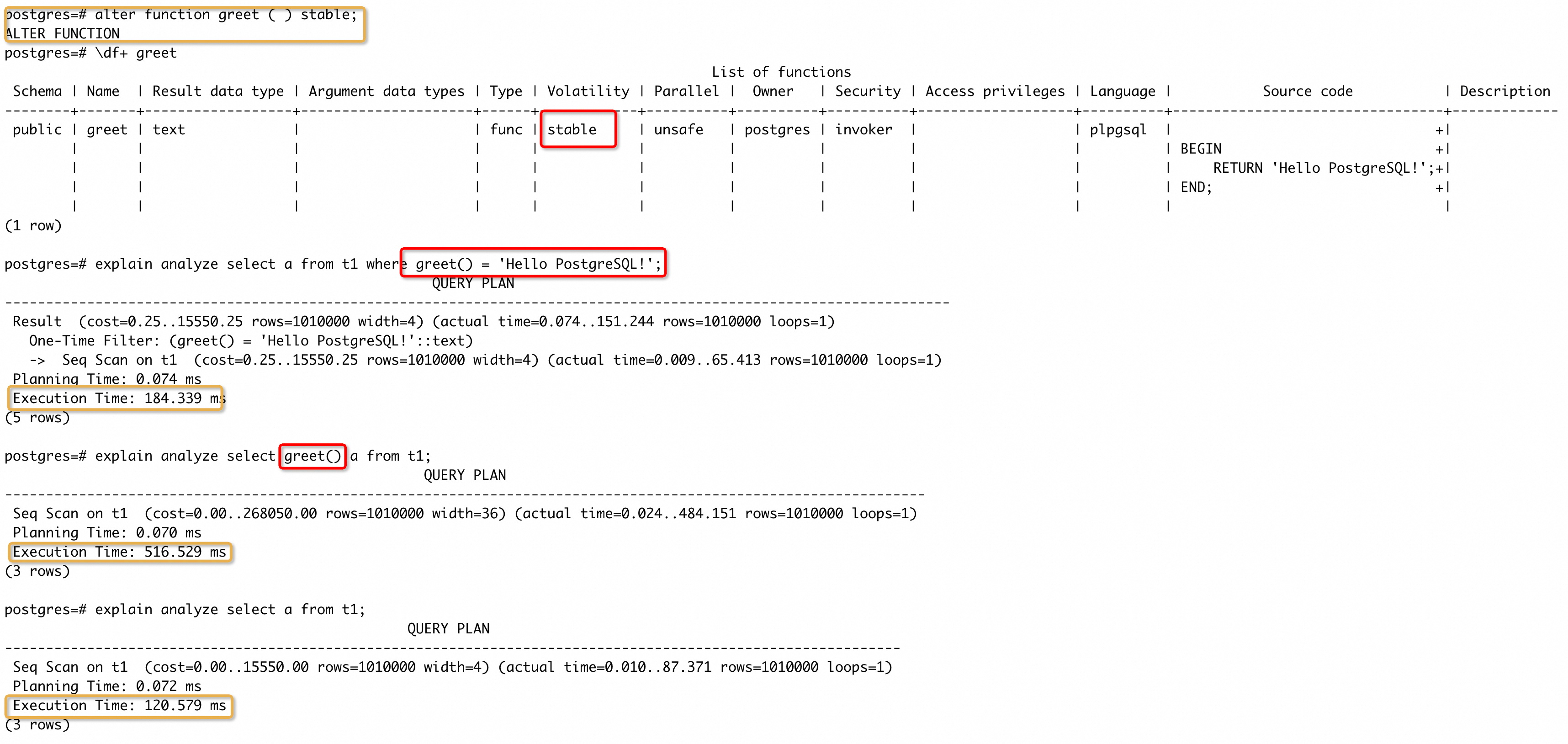
改为 STABLE 属性后,执行时间发生变化的是在 WHERE 中使用函数的 SQL,和不使用函数 SQL 的执行时间基本持平。这里实际上是 PG 会将过滤条件中 STABLE 属性函数在 EXECUTE 阶段只执行一次,后续只使用这个结果,不再多次调用函数。这个优化能让类似a = to_date('2024-01-01', 'YYYY-MM-DD')的过滤条件可以走索引。同时我们也能看到,在输出列中调用的函数仍然被执行了多次,执行的次数等于输出的行数。
那将函数再改为 IMMUTABLE ,看下三条 SQL 的执行情况:
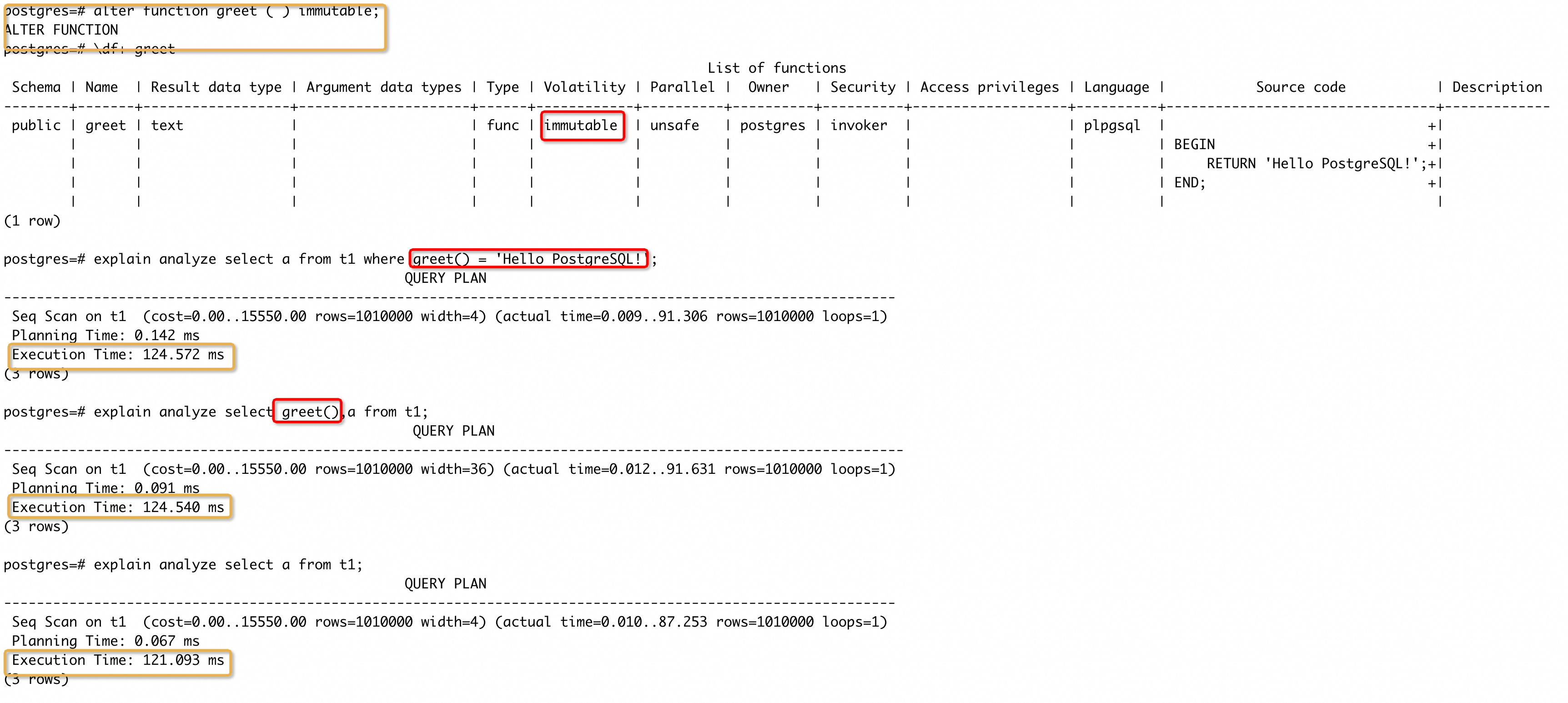
愉快的画面出现了,三条 SQL 的执行时间基本相同了,并且过滤条件使用函数的 SQL 执行计划中都已经没有显示 greet() 函数的调用了。这是因为数据库在 planning 阶段就对函数进行了优化,这个 case 中会将 greet() 优化成一个 ‘Hello PostgreSQL!’ 常量,所以实际生成计划时,相当于执行:
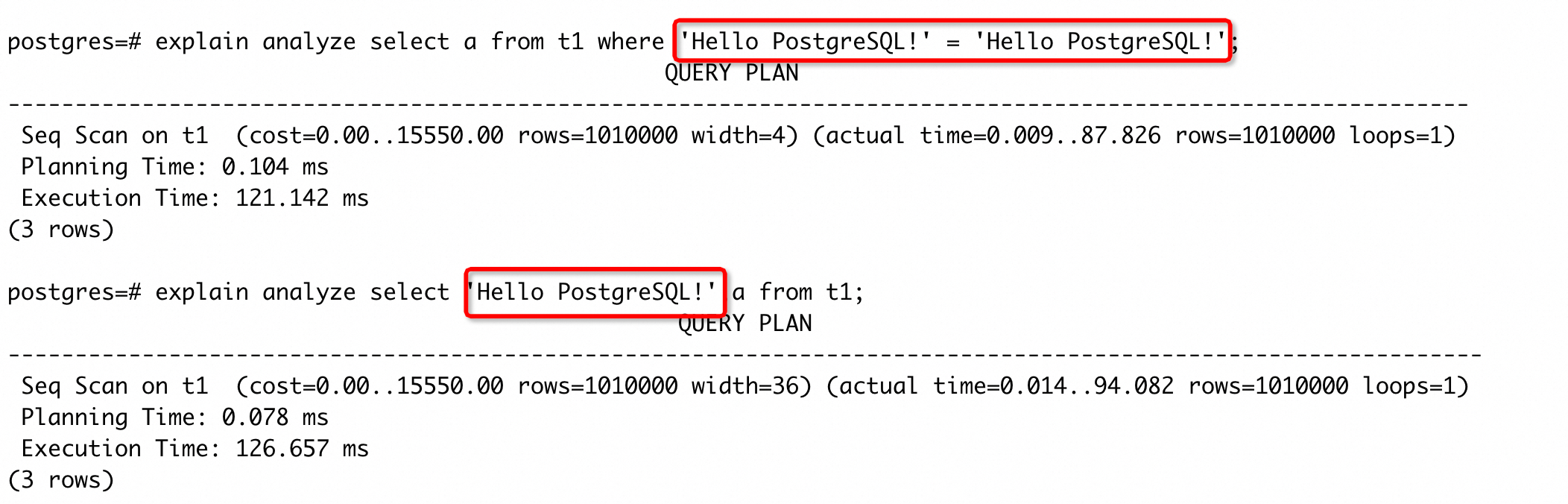
从上面分析中可以看到,函数稳定性属性能够被数据库优化的范围排序是:IMMUTABLE > STABLE > VOLATILE。
case 12
case 11 是说明了稳定性属性对数据库优化能力的直接影响。在实际应用中,更多的是对优化能力的间接影响,比如影响 subquery 上拉、谓词下推等能力。分享一个影响 subquery 上拉的 case:

如果 subquery 中的函数属性为 VOLATILE,则优化器不会将 subquery 上拉。在这个场景中,subquery 不上拉带来的影响就是 t1 上不能进行谓词下推,然后也不能走 Index Only Scan,导致执行时间变慢(这里将函数改为 STABLE 就可以达到目的,但是因为输出行数较少,改为 IMMUTABLE 后执行时间也基本相同)。
case 13
PG 提供了单机并行查询的能力,当处理的数据量较大的时候(实际也是基于代价选择),可能会为一条 SQL 生成并行的计划,期望能够加速 SQL 执行。如果 SQL 中存在 PARALLEL UNSAFE 的函数,优化器则不会考虑生成并行计划(想被淘汰的机会都没有)。简单构造一下 case:
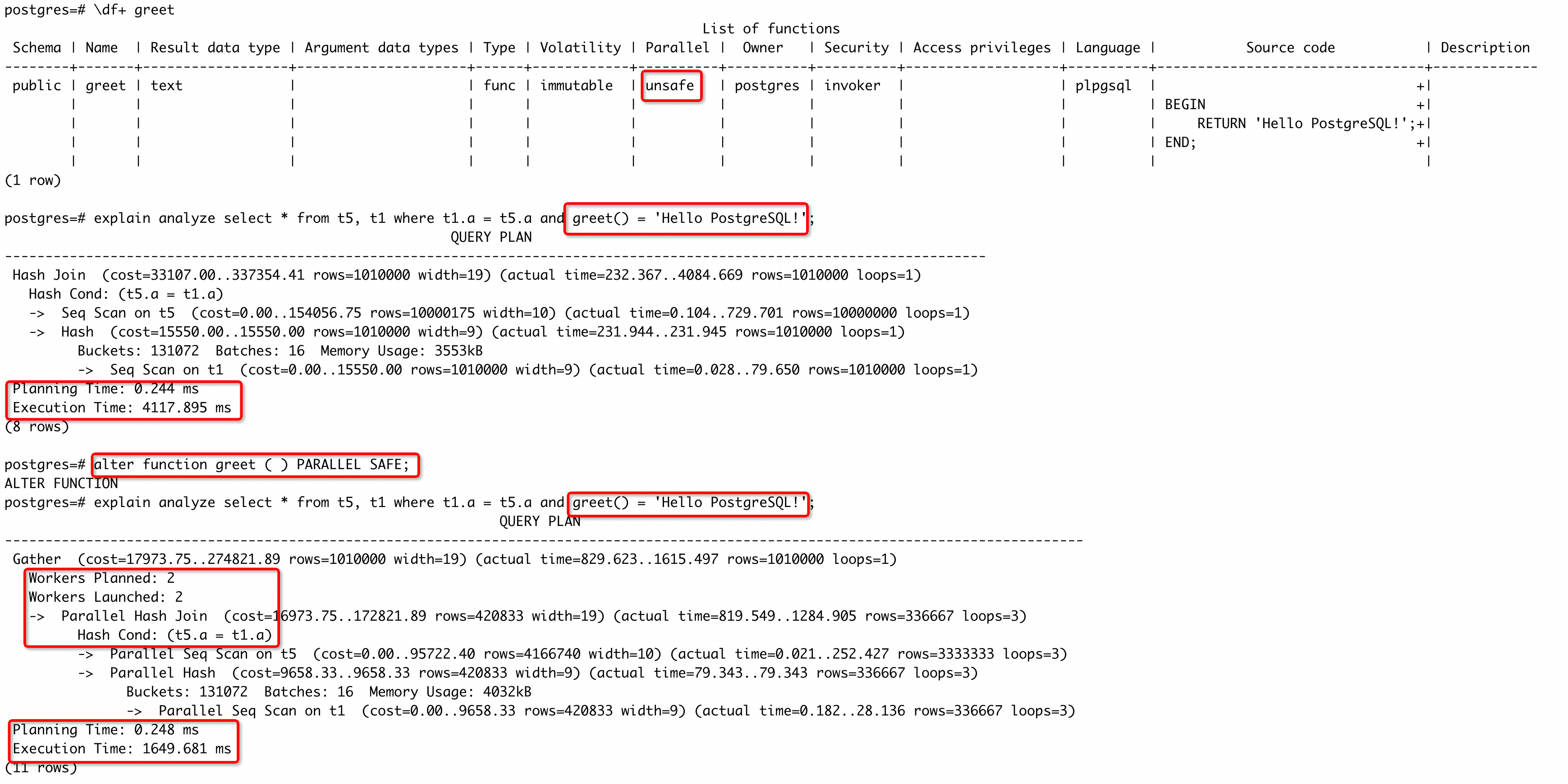
依旧是我们的老演员 greet() 函数,创建时采用默认的 UNSAFE 行为,虽然 IMMUTABLE 的属性让它在 planning 的时刻被优化了,但是这个优化是在判别能否生成并行计划之后做的。因此,函数的 UNSAFE 属性,让执行计划不能并行。然后,我们将函数属性更改成 SAFE ,优化器就生成了一个并行的计划,执行时间也有明显的降低。如果这里我们把函数属性改成 STABLE , PARALLEL RESTRICTED ,case 中的 SQL 也不能产生并行计划,但是使用select greet(), * from t5, t1 where t1.a = t5.a就可以生成并行计划,原因是什么?感兴趣的同学可以去分析验证一下。
从上面的分析中可以看到,创建 UDF 时,如果不清楚函数的属性而采用默认的行为,将会严重退化数据库的优化能力。实际中符合默认行为的函数占比是比较小的,所以建议在创建函数时尽量设置一个合适的属性,同时在排查含有 UDF 函数的 SQL 时,要检查下 UDF 的属性。
资源参数限制导致慢 SQL
PG 中很多优化能力都会有对应的参数控制,便于我们干预数据库的行为(也是 hint 机制依赖的基础)。这些参数按照类型分类包括开关类型、枚举类型、数值类型和字符类型,按照作用分类包括功能启停、资源限制等。功能启停的参数绝大部分都会默认开启,但是资源限制的参数因为和资源相关,所以不同规格的服务器可以有不同的数值,如果资源和数值之间不匹配就会导致一些问题(比如 SQL 执行慢,或者 OOM)。这一小节中给出的 case,只是为了说明存在这种场景,实际的参数调整,还是需要结合服务器资源和业务行为来综合考虑。同时资源限制的参数较多,这里只挑最常见的两类场景。
case 14
上面说了函数属性会影响执行计划并行,但是并行还受多个参数控制,其中主要有:
- max_worker_processes: 同一时刻支持的最大并发后端进程数量;规定了后端进程的进程池,数据库任何时刻的后端进程数量(包括并行 worker 数量)都不会超过它的值。
- max_parallel_workers: 并行操作同一时刻所支持的 worker 的最大数量;限制了数据库并行操作的 worker 最大值,所有 SQL 实际执行的并行 worker 数量不能超过这个值。
- max_parallel_workers_per_gather: 单个 Gather 或者 Gather Merge 节点能够计划并行 worker 的最大数量。
正常情况下,max_worker_processes值会比较大,这里我们 不关心它的数值,重点关注max_parallel_workers和max_parallel_workers_per_gather的数值。看一下这种场景:

虽然max_parallel_workers = 8,但是 SQL 执行计划中只有一个 Gather 节点,因此受max_parallel_workers_per_gather的限制,最多起两个并行。PG 中的并行模式主要包含两类进程,Leader + Worker,其中 Leader 负责调度、数据处理和收集,Worker 只负责处理数据,Leader 有且只有一个, Worker 可以有多个。上面计划中显示Workers Planned: 2表示计划起两个 Worker,再加上一个 Leader,实际上会占用三个进程,所以后面的loops=3。尝试调大 per_gather 的值,再次执行,SQL 起了 4 个 worker,执行时间也缩短了。进一步调大 per_gather 的值:

可以看到虽然 planning 生成了 9 个 worker 的计划,但是实际执行时还会受到max_parallel_workers的限制,所以执行只起了 8 个 worker。从执行时间可以看到,虽然执行 worker 数量又翻了一倍,但是执行时间却没有再次缩短一倍,证明再增加 worker 数量,收益是递减的,但是资源消耗确实是增加了一倍。
既然实际执行时会受max_parallel_workers限制,那可不可以把max_parallel_workers_per_gather全局设成一个比较大的值呢?这样做除了会产生上面说的收益问题外,还很容易让一条 SQL 抢占所有并行资源,以及下面的报错:
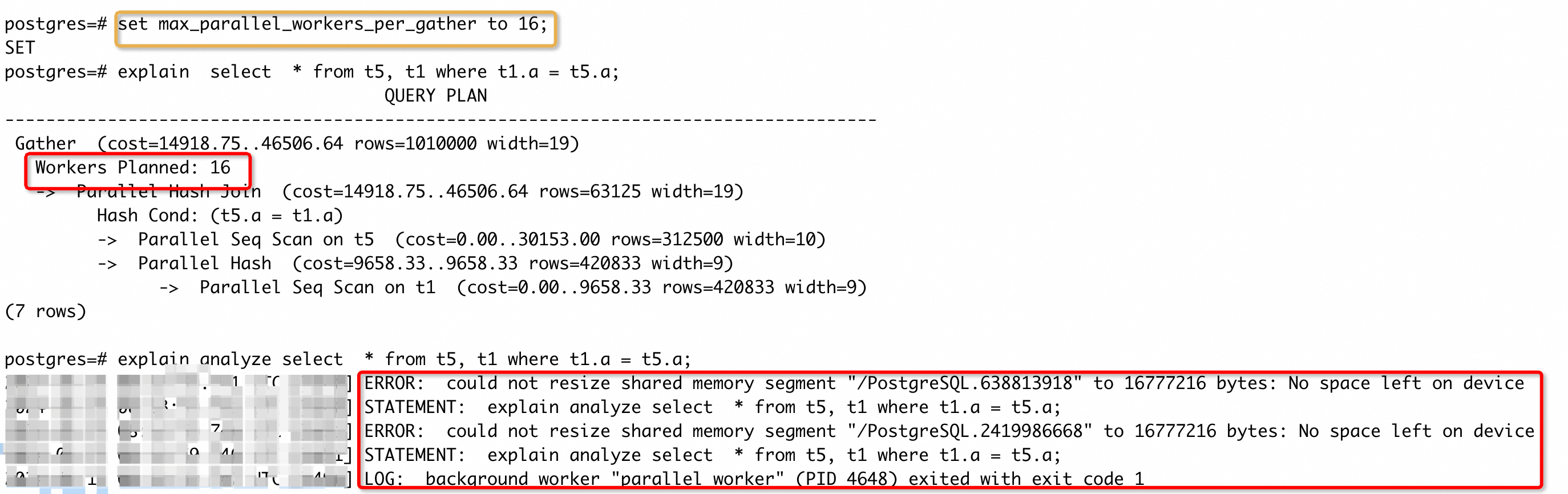
虽然执行时会受限制,但是在申请资源时,还会按照计划的并行规格申请(这里报错的是申请 DSM 内存不足,关于 DSM 的介绍可以参考我的另一篇文章),容易导致报错。
case 15
说完了并行的 case,我们再看下work_mem的 case。work_mem是限制一个排序或者 HASH 操作使用内存的上限值,达到上限后,部分操作会开始写数据到临时文件(比如 SORT/HASHJOIN),部分操作就会被舍弃(比如 HASHAGG/ HASHED SUBPLAN)。对于一个复杂查询,可能会并行运行好几个排序或者哈希操作。同时其他并行 SQL 也有可能进行类似的操作,因此内存的实际使用量可能是work_mem的很多倍。实际应用中,如果work_mem满足要求,将能有效加速 SQL 执行。看一下具体例子:

t7 表筛选出的数据量较多,开始work_mem的值较小,不能够进行 HASH 运算,因此过滤时会在 SUBPLAN 1 的返回结果直接检索,检索空间较大,执行时间较长(最初构建 case 时,没有对 t7 添加过滤条件,执行了 8 个小时没有出结果,因此加上了一个 filter)。将work_mem值调整到能够满足 HASH 运算的内存后,执行计划选择了 HASHED SUBPLAN,因此会对 SUBPLAN 返回的结果使用 HASH 运算,将检索空间变为 HASH BUCKET。对于外层的每一个 tuple 会执行相同的 HASH 算法,然后在每个 BUCKET 中检索,而每个 BUCKET 中的元素数量远小于整个空间,因此执行时间会有明显的提升。
调整资源参数可能会有效缩短 SQL 执行时间,但是也应当结合服务器资源和业务行为,确定一个合适的值,不建议盲目调大参数值,增大数据库运行的稳定性风险。
疑难杂症
这一部分我总结为疑难杂症,一是想博人眼球;二是这里列举出的 case 是之前遇到过比较特殊的情况,没有什么共同特征(可能不太准确,但是也没有想到更好的标题)。
case 16
前面我们分享的所有 case 执行计划都是加上 analyze 选项,表示实际执行过了,这样我们能够明确看到每一节点的实际耗时以及对比估计值和实际值,能够快速帮助我们定位问题。然而,有些复杂的 SQL 可能长时间(比如超过 48 小时)执行不出结果,这种情况下要怎么分析呢?借助一个 case,分享一下分拆定位法:
-- 原始 SQL
with
-- cte s1
temp_yc_v_online_storeinv as(
select
i.goods_id gdgid,
s.orggid orggid,
sum(i.quantity) quantity,
sum(i.amountgross) amountgross
from yc_v_online_storeinv i inner join store s on i.store_id = s.gid
inner join orggoodsh g on i.goods_id = g.gid and s.orggid = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
where 1 = 1 and g.orggid= 1000001
and s.orggid= 1000001
group by
i.goods_id,
s.orggid
),
-- cte s2
temp_businv as(
select
bi.gdgid,
bi.store orggid,
sum(bi.qty) quantity,
sum(bi.alcqty) alcqty,
sum(bi.ordqty) ordquantity
from
businvs bi left join orggoods g on bi.gdgid = g.gid and bi.store = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
inner join warehouse w on w.gid=bi.wrh
where 1 = 1 and g.orggid= 1000001
and w.code in('01','04','13')
and bi.store=1000001
and bi.store= 1000001
group by
bi.gdgid,
bi.store
union all
select
bi.gdgid,
bi.store orggid,
sum(bi.qty) quantity,
sum(bi.alcqty) alcqty,
sum(bi.ordqty) ordquantity
from
businvs bi left join orggoods g on bi.gdgid = g.gid and bi.store = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
inner join warehouse w on w.gid=bi.wrh
where 1 = 1 and g.orggid= 1000001
and bi.store<>1000001
and bi.store= 1000001
group by
bi.gdgid,
bi.store
),
-- cte s3
temp_sale as(
select
a.gdgid,
s.orggid,
sum(a.qty) quantity,
sum(a.amt) saleamt
from
std_sm_outdrpt a left join store s on a.snd = s.gid
inner join v_belongsort_store vb on vb.bcode=s.belongsort
left join orggoods g on a.gdgid = g.gid and s.orggid = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
where 1 = 1 and g.orggid= 1000001
and vb.orggid= 1000001
and a.fildate <= trunc(sysdate) - 1
and a.fildate >= trunc(sysdate) - 35
group by
a.gdgid,
s.orggid
),
-- cte s4
temp_7daysale as(
select
a.gdgid,
s.orggid,
sum(a.qty) quantity,
sum(a.amt) saleamt
from
std_sm_outdrpt a left join store s on a.snd = s.gid
inner join v_belongsort_store vb on vb.bcode=s.belongsort
left join orggoods g on a.gdgid = g.gid and s.orggid = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
where 1 = 1 and g.orggid= 1000001
and vb.orggid= 1000001
and a.fildate <= trunc(sysdate) - 1
and a.fildate >= trunc(sysdate) - 7
group by
a.gdgid,
s.orggid
)
select
st1.code ,
st1.name ,
st2.code ,
st2.name ,
st3.code ,
st3.name ,
st4.code ,
st4.name ,
g.code ,
g.code2 ,
g.name ,
g.spec ,
case when g.defpu like '1*%' then SUBSTRING(defpu,3,6)
else g.defpu end as "测",
g.VALIDPERIOD "保",
r.rtlprc,
--g.inprc,
g.CNTINPRC ,
g.alc ,
gb.name,
v.code,
v.name,
g.country,
g.tm,
g.orggid,
nvl(sum(ts.quantity),0) ,
nvl(sum(ts.saleamt),0) ,
nvl(sum(i.quantity),0) ,
nvl(sum(i.amountgross),0) ,
nvl(sum(bi.quantity),0) ,
nvl(sum(bi.alcqty),0) ,
nvl(sum(i.quantity),0)+nvl(sum(bi.quantity),0)+nvl(sum(bi.alcqty),0) ,
round(nvl(sum(ts.quantity)/35,0),2) ,
round(nvl(sum(ts.saleamt)/35,0),2) ,
round(nvl(case sum(ts.quantity) when 0 then 9999 else
sum(bi.quantity)/sum(ts.quantity)*35 end,0),2) "P",
round(nvl(case sum(ts.quantity) when 0 then 9999 else
(nvl(sum(i.quantity),0)+nvl(sum(bi.quantity),0))/sum(ts.quantity)*35 end,0),2) "G",
nvl(sum(bi.ordquantity),0) ,
gds.jyfa,
nvl(sum(tds.quantity),0) ,
nvl(sum(tds.saleamt),0) ,
round(nvl(case sum(tds.quantity) when 0 then 9999 else
sum(bi.quantity)/sum(tds.quantity)*7 end,0),2) ,
g.amiba
from
orggoods g left join temp_yc_v_online_storeinv i on g.gid = i.gdgid and g.orggid = i.orggid
left join temp_businv bi on g.gid = bi.gdgid and g.orggid = bi.orggid
inner join goodsbusgate gb on g.busgate = gb.gid
inner join vendorh v on g.vdrgid = v.gid --and g.orggid = v.src
left join temp_sale ts on g.gid = ts.gdgid and g.orggid = ts.orggid
left join temp_7daysale tds on g.gid = tds.gdgid and g.orggid = tds.orggid
inner join sort st1 on substr(g.sort,1,2) = st1.code
inner join sort st2 on substr(g.sort,1,3) = st2.code
inner join sort st3 on substr(g.sort,1,4) = st3.code
inner join sort st4 on substr(g.sort,1,6) = st4.code
inner join rpggd r on r.gdgid=g.gid and r.inputcode=g.code and
decode(r.gcode,'9901',1000001,'9902',1000002,'9908',1000311)=g.orggid
left join (select gds.gdgid,array_to_string(array_agg(gd1.name order by gds.code),',') jyfa
from GDSALESCHEMEDTL gds
left join GDSALESCHEME gd1 on gds.code = gd1.code and gd1.orggid= 1000001
where gd1.code <> '9901'
group by gds.gdgid
) gds on g.gid = gds.gdgid
where 1 = 1 and g.orggid= 1000001
and decode(r.gcode,'9901',1000001,'9902',1000002,'9908',1000311)= 1000001
group by
st1.code ,
st1.name ,
st2.code ,
st2.name ,
st3.code ,
st3.name ,
st4.code ,
st4.name ,
g.code ,
g.code2,
g.defpu,
r.rtlprc,
g.CNTINPRC,
g.name ,
g.spec ,
g.alc ,
gb.name ,
v.code ,
v.name ,
g.country,
g.tm ,
g.orggid,
g.VALIDPERIOD,
gds.jyfa,
g.amiba;
这个 SQL 长时间执行不出结果。观察发现,SQL 主要由 4 个 CTE 子句构成,以下是分析的一个思路:
- 尝试将整个SQL 拆解(为了方便表示,4 个CTE字句从上到下依次用 s1 / s2 / s3 / s4 表示,主干用 o 表示)。
- 单独执行 s1 能够出结果,从执行计划上,存在一些小优化点,但不是导致原 SQL 执行较慢的主要原因。s2 / s3 / s4 的情况与 s1 类似。
-- s1
select
i.goods_id gdgid,
s.orggid orggid,
sum(i.quantity) quantity,
sum(i.amountgross) amountgross
from yc_v_online_storeinv i inner join store s on i.store_id = s.gid
inner join orggoodsh g on i.goods_id = g.gid and s.orggid = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
where 1 = 1 and g.orggid= 1000001
and s.orggid= 1000001
group by
i.goods_id,
s.orggid;
GroupAggregate (cost=606436.62..1063893.79 rows=800 width=100) (actual time=30980.228..32298.911 rows=25861 loops=1)
Group Key: t.gduuid, s.orggid
Buffers: shared hit=470700 read=83552 dirtied=40105
I/O Timings: read=21105.287
-> Merge Join (cost=606436.62..911527.62 rows=15235417 width=100) (actual time=30980.195..31933.321 rows=1335487 loops=1)
Merge Cond: ((t.gduuid)::text = ((g.gid)::text))
Buffers: shared hit=470700 read=83552 dirtied=40105
I/O Timings: read=21105.287
-> Sort (cost=539383.70..539479.37 rows=38266 width=100) (actual time=24835.260..25133.891 rows=1335487 loops=1)
Sort Key: t.gduuid
Sort Method: quicksort Memory: 147683kB
Buffers: shared hit=469208 read=46010 dirtied=36643
I/O Timings: read=15263.223
-> Hash Join (cost=532166.01..536470.94 rows=38266 width=100) (actual time=22175.954..23773.152 rows=1335487 loops=1)
Hash Cond: ((t.orguuid)::text = (s.gid)::text)
Buffers: shared hit=469208 read=46010 dirtied=36643
I/O Timings: read=15263.223
-> HashAggregate (cost=531908.22..532482.21 rows=38266 width=232) (actual time=22150.266..23142.250 rows=1587002 loops=1)
Group Key: t.orguuid, t.wrhuuid, t.gduuid
Buffers: shared hit=468653 read=45971 dirtied=36622
I/O Timings: read=15243.038
-> Append (cost=450758.05..523298.28 rows=382664 width=200) (actual time=16507.106..20498.997 rows=1587901 loops=1)
Buffers: shared hit=468653 read=45971 dirtied=36622
I/O Timings: read=15243.038
-> HashAggregate (cost=450758.05..455932.81 rows=344984 width=128) (actual time=16507.104..18401.432 rows=1587001 loops=1)
Group Key: t.orguuid, t.wrhuuid, t.gduuid
Buffers: shared hit=335113 read=29399 dirtied=34691
I/O Timings: read=12093.457
-> Seq Scan on ycstd_store_inv t (cost=0.00..399010.42 rows=3449842 width=38) (actual time=0.104..14082.080 rows=1587001 loops=1)
Buffers: shared hit=335113 read=29399 dirtied=34691
I/O Timings: read=12093.457
-> Subquery Scan on "*SELECT* 2" (cost=12571.42..12659.61 rows=512 width=200) (actual time=403.028..403.907 rows=233 loops=1)
Buffers: shared hit=9862 read=1548 dirtied=546
I/O Timings: read=514.696
-> Finalize GroupAggregate (cost=12571.42..12654.49 rows=512 width=212) (actual time=403.026..403.867 rows=233 loops=1)
Group Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
Buffers: shared hit=9862 read=1548 dirtied=546
I/O Timings: read=514.696
-> Gather Merge (cost=12571.42..12628.05 rows=426 width=84) (actual time=403.008..403.383 rows=237 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=9862 read=1548 dirtied=546
I/O Timings: read=514.696
-> Partial GroupAggregate (cost=11571.40..11578.85 rows=213 width=84) (actual time=389.841..389.963 rows=79 loops=3)
Group Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
Buffers: shared hit=9862 read=1548 dirtied=546
I/O Timings: read=514.696
-> Sort (cost=11571.40..11571.93 rows=213 width=37) (actual time=389.816..389.827 rows=80 loops=3)
Sort Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
Sort Method: quicksort Memory: 31kB
Worker 0: Sort Method: quicksort Memory: 31kB
Worker 1: Sort Method: quicksort Memory: 31kB
Buffers: shared hit=9862 read=1548 dirtied=546
I/O Timings: read=514.696
-> Nested Loop (cost=1.54..11563.16 rows=213 width=37) (actual time=34.155..389.730 rows=80 loops=3)
Buffers: shared hit=9848 read=1548 dirtied=546
I/O Timings: read=514.696
-> Nested Loop (cost=1.12..11470.81 rows=213 width=37) (actual time=33.609..378.333 rows=80 loops=3)
Buffers: shared hit=9204 read=1375 dirtied=503
I/O Timings: read=483.747
-> Nested Loop (cost=0.70..10165.88 rows=53 width=44) (actual time=32.962..360.369 rows=50 loops=3)
Buffers: shared hit=8858 read=1109 dirtied=412
I/O Timings: read=433.195
-> Nested Loop Anti Join (cost=0.42..10139.29 rows=53 width=44) (actual time=32.695..359.205 rows=50
loops=3)
Buffers: shared hit=8482 read=1097 dirtied=412
I/O Timings: read=430.940
-> Parallel Seq Scan on invxf s_1 (cost=0.00..10027.83 rows=54 width=44) (actual time=32.194..
346.071 rows=50 loops=3)
Filter: (((cls)::text = '门店调拨'::text) AND (stat = 700))
Rows Removed by Filter: 63962
Buffers: shared hit=8102 read=905 dirtied=358
I/O Timings: read=395.305
-> Index Only Scan using invxflog_pkey on invxflog lg (cost=0.42..2.06 rows=1 width=28) (actua
l time=0.258..0.258 rows=0 loops=151)
Index Cond: ((num = (s_1.num)::text) AND (cls = (s_1.cls)::text) AND (cls = '门店调拨'::te
xt))
Filter: (stat = ANY ('{710,730}'::integer[]))
Rows Removed by Filter: 1
Heap Fetches: 110
Buffers: shared hit=380 read=192 dirtied=54
I/O Timings: read=35.635
-> Index Only Scan using store_pkey on store st (cost=0.27..0.50 rows=1 width=4) (actual time=0.021.
.0.021 rows=1 loops=151)
Index Cond: (gid = s_1.fromstore)
Heap Fetches: 81
Buffers: shared hit=376 read=12
I/O Timings: read=2.255
-> Index Scan using invxfdtl_pkey on invxfdtl dtl (cost=0.42..24.40 rows=22 width=49) (actual time=0.348..
0.355 rows=2 loops=151)
Index Cond: (((num)::text = (s_1.num)::text) AND ((cls)::text = '门店调拨'::text))
Buffers: shared hit=346 read=266 dirtied=91
I/O Timings: read=50.551
-> Index Only Scan using goods_pkey on goods g_1 (cost=0.41..0.43 rows=1 width=4) (actual time=0.142..0.142 rows
=1 loops=239)
Index Cond: (gid = dtl.gdgid)
Heap Fetches: 95
Buffers: shared hit=644 read=173 dirtied=43
I/O Timings: read=30.949
-> Subquery Scan on "*SELECT* 3" (cost=47670.14..49342.70 rows=37168 width=200) (actual time=1538.632..1540.524 rows=667 loops=1)
Buffers: shared hit=123678 read=15024 dirtied=1385
I/O Timings: read=2634.885
-> Finalize HashAggregate (cost=47670.14..48971.02 rows=37168 width=193) (actual time=1538.630..1540.430 rows=667 loops=1)
Group Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid, s_2.cls
Buffers: shared hit=123678 read=15024 dirtied=1385
I/O Timings: read=2634.885
-> Gather (cost=44663.84..47178.20 rows=21864 width=97) (actual time=1518.119..1538.535 rows=686 loops=1)
Workers Planned: 1
Workers Launched: 1
Buffers: shared hit=123678 read=15024 dirtied=1385
I/O Timings: read=2634.885
-> Partial HashAggregate (cost=43663.84..43991.80 rows=21864 width=97) (actual time=1520.123..1520.584 rows=343 loops=2)
Group Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid, s_2.cls
Buffers: shared hit=123678 read=15024 dirtied=1385
I/O Timings: read=2634.885
-> Parallel Hash Join (cost=1579.71..43281.22 rows=21864 width=44) (actual time=185.958..1501.013 rows=35564 loops=2)
Hash Cond: (dtl_1.gdgid = g_2.gid)
Buffers: shared hit=123678 read=15024 dirtied=1385
I/O Timings: read=2634.885
-> Nested Loop (cost=1.72..41645.83 rows=21864 width=44) (actual time=2.062..1306.370 rows=35564 loops=2)
Buffers: shared hit=114452 read=13403 dirtied=412
I/O Timings: read=2353.242
-> Merge Join (cost=1.29..14321.90 rows=9173 width=40) (actual time=1.460..425.209 rows=11431 loops=2)
Merge Cond: (s_2.client = st_1.gid)
Buffers: shared hit=20276 read=4554 dirtied=58
I/O Timings: read=793.796
-> Parallel Index Scan using idx_stkoutbck_sc on stkoutbck s_2 (cost=0.42..14340.83 rows=15276 width=40) (
actual time=1.375..422.184 rows=11431 loops=2)
Index Cond: (stat = 700)
Filter: ((cls)::text = '统配出退'::text)
Rows Removed by Filter: 1602
Buffers: shared hit=19989 read=4554 dirtied=58
I/O Timings: read=793.796
-> Index Only Scan using store_pkey on store st_1 (cost=0.27..38.75 rows=263 width=4) (actual time=0.077..
0.285 rows=240 loops=2)
Heap Fetches: 332
Buffers: shared hit=287
-> Index Scan using stkoutbckdtl_pkey on stkoutbckdtl dtl_1 (cost=0.42..2.88 rows=10 width=46) (actual time=0.05
6..0.076 rows=3 loops=22862)
Index Cond: (((cls)::text = '统配出退'::text) AND ((num)::text = (s_2.num)::text))
Buffers: shared hit=94176 read=8849 dirtied=354
I/O Timings: read=1559.446
-> Parallel Hash (cost=1262.25..1262.25 rows=25260 width=4) (actual time=183.612..183.613 rows=29330 loops=2)
Buckets: 65536 Batches: 1 Memory Usage: 2848kB
Buffers: shared hit=9222 read=1621 dirtied=973
I/O Timings: read=281.642
-> Parallel Index Only Scan using goods_pkey on goods g_2 (cost=0.41..1262.25 rows=25260 width=4) (actual time=0
.153..174.929 rows=29330 loops=2)
Heap Fetches: 11092
Buffers: shared hit=9222 read=1621 dirtied=973
I/O Timings: read=281.642
-> Hash (cost=255.29..255.29 rows=200 width=8) (actual time=25.665..25.666 rows=200 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 16kB
Buffers: shared hit=555 read=39 dirtied=21
I/O Timings: read=20.186
-> Seq Scan on store s (cost=0.00..255.29 rows=200 width=8) (actual time=0.258..25.600 rows=200 loops=1)
Filter: (orggid = 1000001)
Rows Removed by Filter: 64
Buffers: shared hit=555 read=39 dirtied=21
I/O Timings: read=20.186
-> Sort (cost=67052.92..67251.99 rows=79629 width=12) (actual time=6144.911..6232.422 rows=1368332 loops=1)
Sort Key: ((g.gid)::text)
Sort Method: quicksort Memory: 6583kB
Buffers: shared hit=1492 read=37542 dirtied=3462
I/O Timings: read=5842.064
-> Bitmap Heap Scan on orggoodsh g (cost=6485.92..60570.72 rows=79629 width=12) (actual time=406.573..6113.739 rows=58719 loops=1)
Recheck Cond: (orggid = 1000001)
Heap Blocks: exact=36551
Buffers: shared hit=1492 read=37542 dirtied=3462
I/O Timings: read=5842.064
-> Bitmap Index Scan on idx_orggoodsh_orggdcode_upper (cost=0.00..6466.01 rows=79629 width=0) (actual time=399.571..399.572 rows=59019 loops=1)
Index Cond: (orggid = 1000001)
Buffers: shared hit=110 read=2373
I/O Timings: read=370.332
Planning Time: 4.455 ms
Execution Time: 32384.434 ms
(165 rows)
- 单独执行 o 并观察执行计划,也没有发现能够导致执行慢的主要原因。
-- o SQL 和执行计划
select
st1.code ,
st1.name ,
st2.code ,
st2.name ,
st3.code ,
st3.name ,
st4.code ,
st4.name ,
g.code ,
g.code2 ,
g.name ,
g.spec ,
case when g.defpu like '1*%' then SUBSTRING(defpu,3,6)
else g.defpu end as "测",
g.VALIDPERIOD "保",
r.rtlprc ,
g.CNTINPRC ,
g.alc ,
gb.name ,
v.code ,
v.name ,
g.country ,
g.tm ,
g.orggid ,
gds.jyfa,
g.amiba
from
orggoods g inner join goodsbusgate gb on g.busgate = gb.gid
inner join vendorh v on g.vdrgid = v.gid --and g.orggid = v.src
inner join sort st1 on substr(g.sort,1,2) = st1.code
inner join sort st2 on substr(g.sort,1,3) = st2.code
inner join sort st3 on substr(g.sort,1,4) = st3.code
inner join sort st4 on substr(g.sort,1,6) = st4.code
inner join rpggd r on r.gdgid=g.gid and r.inputcode=g.code and
decode(r.gcode,'9901',1000001,'9902',1000002,'9908',1000311)=g.orggid
left join (select gds.gdgid,array_to_string(array_agg(gd1.name order by gds.code),',') jyfa
from GDSALESCHEMEDTL gds
left join GDSALESCHEME gd1 on gds.code = gd1.code and gd1.orggid= 1000001
where gd1.code <> '9901'
group by gds.gdgid
) gds on g.gid = gds.gdgid
where 1 = 1 and g.orggid= 1000001
and decode(r.gcode,'9901',1000001,'9902',1000002,'9908',1000311)= 1000001
group by
st1.code ,
st1.name ,
st2.code ,
st2.name ,
st3.code ,
st3.name ,
st4.code ,
st4.name ,
g.code ,
g.code2,
g.defpu,
r.rtlprc,
g.CNTINPRC,
g.name ,
g.spec ,
g.alc ,
gb.name ,
v.code ,
v.name ,
g.country,
g.tm ,
g.orggid,
g.VALIDPERIOD,
gds.jyfa,
g.amiba;
Group (cost=40104.02..40104.10 rows=1 width=320) (actual time=1486.783..1561.033 rows=57622 loops=1)
Group Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.cntinprc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.orggid, g.validperiod, (array_to_string(array_agg(gd1.name ORDER BY gds.code), ','::text)), g.amiba
Buffers: shared hit=1474412
-> Sort (cost=40104.02..40104.03 rows=1 width=288) (actual time=1486.772..1497.218 rows=57622 loops=1)
Sort Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.cntinprc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.validperiod, (array_to_string(array_agg(gd1.name ORDER BY gds.code), ','::text)), g.amiba
Sort Method: quicksort Memory: 29145kB
Buffers: shared hit=1474412
-> Gather (cost=37663.23..40104.01 rows=1 width=288) (actual time=753.087..994.759 rows=57622 loops=1)
Workers Planned: 3
Workers Launched: 3
Buffers: shared hit=1474406
-> Merge Left Join (cost=36663.23..39103.91 rows=1 width=288) (actual time=743.794..967.001 rows=14406 loops=4)
Merge Cond: (g.gid = gds.gdgid)
Buffers: shared hit=1474406
-> Sort (cost=19488.91..19488.92 rows=1 width=260) (actual time=490.599..492.432 rows=14406 loops=4)
Sort Key: g.gid
Sort Method: quicksort Memory: 6786kB
Worker 0: Sort Method: quicksort Memory: 6521kB
Worker 1: Sort Method: quicksort Memory: 6604kB
Worker 2: Sort Method: quicksort Memory: 6510kB
Buffers: shared hit=1415591
-> Nested Loop (cost=1.97..19488.90 rows=1 width=260) (actual time=0.104..474.399 rows=14406 loops=4)
Buffers: shared hit=1415579
-> Nested Loop (cost=1.69..19488.60 rows=1 width=245) (actual time=0.093..419.605 rows=14484 loops=4)
Buffers: shared hit=1242057
-> Nested Loop (cost=1.41..19488.30 rows=1 width=224) (actual time=0.079..365.297 rows=14558 loops=4)
Buffers: shared hit=1067662
-> Nested Loop (cost=1.12..19487.99 rows=1 width=203) (actual time=0.068..310.805 rows=14653 loops=4)
Buffers: shared hit=892208
-> Nested Loop (cost=0.84..19487.69 rows=1 width=182) (actual time=0.056..254.105 rows=14666 loops=4)
Buffers: shared hit=716269
-> Nested Loop (cost=0.56..19487.38 rows=1 width=139) (actual time=0.045..216.960 rows=14666 loops=4)
Buffers: shared hit=540278
-> Nested Loop (cost=0.42..19487.22 rows=1 width=127) (actual time=0.035..189.473 rows=14666 loops=4)
Buffers: shared hit=422951
-> Parallel Seq Scan on rpggd r (cost=0.00..16128.81 rows=1505 width=25) (actual time=0.012..61.454 rows=29318 loops=4)
Filter: (DECODE( gcode , '9901'::character varying , 1000001 , '9902'::character varying , 1000002 , '9908'::character varying , 1000311 , NULL::integer ) = 1000001)
Rows Removed by Filter: 205230
Buffers: shared hit=12366
-> Index Scan using orggoods_orggid_idx1 on orggoods g (cost=0.42..2.23 rows=1 width=121) (actual time=0.004..0.004 rows=1 loops=117274)
Index Cond: ((orggid = 1000001) AND (gid = r.gdgid) AND ((code)::text = (r.inputcode)::text))
Buffers: shared hit=410585
-> Index Scan using goodsbusgate_pkey on goodsbusgate gb (cost=0.14..0.16 rows=1 width=20) (actual time=0.001..0.001 rows=1 loops=58662)
Index Cond: (gid = g.busgate)
Buffers: shared hit=117327
-> Index Scan using vendorh_pkey on vendorh v (cost=0.28..0.31 rows=1 width=51) (actual time=0.002..0.002 rows=1 loops=58662)
Index Cond: (gid = g.vdrgid)
Buffers: shared hit=175991
-> Index Scan using sortname_pkey on sortname (cost=0.28..0.30 rows=1 width=21) (actual time=0.003..0.003 rows=1 loops=58662)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '2'::numeric)))
Buffers: shared hit=175939
-> Index Scan using sortname_pkey on sortname sortname_1 (cost=0.28..0.30 rows=1 width=21) (actual time=0.003..0.003 rows=1 loops=58612)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '3'::numeric)))
Buffers: shared hit=175454
-> Index Scan using sortname_pkey on sortname sortname_2 (cost=0.28..0.30 rows=1 width=21) (actual time=0.003..0.003 rows=1 loops=58230)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '4'::numeric)))
Buffers: shared hit=174395
-> Index Scan using sortname_pkey on sortname sortname_3 (cost=0.28..0.30 rows=1 width=21) (actual time=0.003..0.003 rows=1 loops=57935)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '6'::numeric)))
Buffers: shared hit=173522
-> GroupAggregate (cost=17174.32..18998.54 rows=49315 width=36) (actual time=253.118..461.599 rows=37787 loops=4)
Group Key: gds.gdgid
Buffers: shared hit=58815
-> Sort (cost=17174.32..17535.82 rows=144600 width=27) (actual time=253.048..267.791 rows=198698 loops=4)
Sort Key: gds.gdgid
Sort Method: quicksort Memory: 22166kB
Worker 0: Sort Method: quicksort Memory: 22166kB
Worker 1: Sort Method: quicksort Memory: 22166kB
Worker 2: Sort Method: quicksort Memory: 22166kB
Buffers: shared hit=58791
-> Nested Loop (cost=0.42..4780.86 rows=144600 width=27) (actual time=0.222..188.056 rows=198710 loops=4)
Buffers: shared hit=58791
-> Seq Scan on gdsalescheme gd1 (cost=0.00..1.28 rows=8 width=23) (actual time=0.007..0.026 rows=7 loops=4)
Filter: (((code)::text <> '9901'::text) AND (orggid = 1000001))
Rows Removed by Filter: 12
Buffers: shared hit=4
-> Index Only Scan using gdsaleschemedtl_pkey on gdsaleschemedtl gds (cost=0.42..416.70 rows=18075 width=7) (actual time=0.041..23.302 rows=28387 loops=28)
Index Cond: (code = (gd1.code)::text)
Heap Fetches: 173592
Buffers: shared hit=58787
Planning Time: 18.987 ms
Execution Time: 1586.934 ms
(82 rows)
- 尝试将 o 与一个 CTE 字句组合起来,组成 o + s1 / o + s2 / o + s3 / o + s4 。组合后发现任何一组执行 explain analyze 都长时间未出结果,导致原SQL 执行较慢的主要原因应该在这个组合中存在。
-- o + s1 SQL
with temp_yc_v_online_storeinv as(
select
i.goods_id gdgid,
s.orggid orggid,
sum(i.quantity) quantity,
sum(i.amountgross) amountgross
from yc_v_online_storeinv i inner join store s on i.store_id = s.gid
inner join orggoodsh g on i.goods_id = g.gid and s.orggid = g.orggid
left join goodsbusgate gb on g.busgate = gb.gid
where 1 = 1 and g.orggid= 1000001
and s.orggid= 1000001
group by
i.goods_id,
s.orggid
)
select
st1.code ,
st1.name ,
st2.code ,
st2.name ,
st3.code ,
st3.name ,
st4.code ,
st4.name ,
g.code ,
g.code2 ,
g.name ,
g.spec ,
case when g.defpu like '1*%' then SUBSTRING(defpu,3,6)
else g.defpu end as "测",
g.VALIDPERIOD "保",
r.rtlprc ,
g.CNTINPRC ,
g.alc ,
gb.name ,
v.code ,
v.name ,
g.country ,
g.tm ,
g.orggid ,
nvl(sum(i.quantity),0) ,
nvl(sum(i.amountgross),0) ,
gds.jyfa,
g.amiba
from
orggoods g left join temp_yc_v_online_storeinv i on g.gid = i.gdgid and g.orggid = i.orggid
inner join goodsbusgate gb on g.busgate = gb.gid
inner join vendorh v on g.vdrgid = v.gid --and g.orggid = v.src
inner join sort st1 on substr(g.sort,1,2) = st1.code
inner join sort st2 on substr(g.sort,1,3) = st2.code
inner join sort st3 on substr(g.sort,1,4) = st3.code
inner join sort st4 on substr(g.sort,1,6) = st4.code
inner join rpggd r on r.gdgid=g.gid and r.inputcode=g.code and
decode(r.gcode,'9901',1000001,'9902',1000002,'9908',1000311)=g.orggid
left join (select gds.gdgid,array_to_string(array_agg(gd1.name order by gds.code),',') jyfa
from GDSALESCHEMEDTL gds
left join GDSALESCHEME gd1 on gds.code = gd1.code and gd1.orggid= 1000001
where gd1.code <> '9901'
group by gds.gdgid
) gds on g.gid = gds.gdgid
where 1 = 1 and g.orggid= 1000001
and decode(r.gcode,'9901',1000001,'9902',1000002,'9908',1000311)= 1000001
group by
st1.code ,
st1.name ,
st2.code ,
st2.name ,
st3.code ,
st3.name ,
st4.code ,
st4.name ,
g.code ,
g.code2,
g.defpu,
r.rtlprc,
g.CNTINPRC,
g.name ,
g.spec ,
g.alc ,
gb.name ,
v.code ,
v.name ,
g.country,
g.tm ,
g.orggid,
g.VALIDPERIOD,
gds.jyfa,
g.amiba;
- 使用 explain 对比 o + s1 与 o 之间优化器选择计划的差异。
-- o + s1 执行计划
GroupAggregate (cost=952599.68..952599.78 rows=1 width=384)
Group Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.cntin
prc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.orggid, g.validperiod, (array_to_string(array_agg(gd1.name ORDER BY gds.code), ','::text)), g.amiba
CTE temp_yc_v_online_storeinv
-> GroupAggregate (cost=659198.39..867993.33 rows=800 width=100)
Group Key: tt.goods_id, s.orggid
-> Merge Join (cost=659198.39..798452.83 rows=6952850 width=100)
Merge Cond: ((tt.goods_id)::text = ((g_1.gid)::text))
-> Sort (cost=597566.16..597615.52 rows=19744 width=100)
Sort Key: tt.goods_id
-> Merge Join (cost=592305.41..596157.52 rows=19744 width=100)
Merge Cond: (((s.gid)::text) = (tt.store_id)::text)
-> Sort (cost=262.93..263.43 rows=200 width=8)
Sort Key: ((s.gid)::text)
-> Seq Scan on store s (cost=0.00..255.29 rows=200 width=8)
Filter: (orggid = 1000001)
-> Materialize (cost=592042.47..595547.06 rows=19744 width=128)
-> GroupAggregate (cost=592042.47..595300.26 rows=19744 width=232)
Group Key: tt.store_id, tt.wrh_id, tt.goods_id
-> Sort (cost=592042.47..592536.08 rows=197442 width=160)
Sort Key: tt.store_id, tt.wrh_id, tt.goods_id
-> Subquery Scan on tt (cost=406237.88..574676.39 rows=197442 width=160)
-> Append (cost=406237.88..572701.97 rows=197442 width=200)
-> Finalize GroupAggregate (cost=406237.88..505939.39 rows=158209 width=128)
Group Key: t.orguuid, t.wrhuuid, t.gduuid
-> Gather Merge (cost=406237.88..490909.53 rows=632836 width=96)
Workers Planned: 4
-> Partial GroupAggregate (cost=405237.82..414532.61 rows=158209 width=96)
Group Key: t.orguuid, t.wrhuuid, t.gduuid
-> Sort (cost=405237.82..406226.63 rows=395523 width=39)
Sort Key: t.orguuid, t.wrhuuid, t.gduuid
-> Parallel Seq Scan on ycstd_store_inv t (cost=0.00..368467.23 rows=395523 width=39)
-> Subquery Scan on "*SELECT* 2" (cost=12149.83..12206.50 rows=328 width=200)
-> Finalize GroupAggregate (cost=12149.83..12203.22 rows=328 width=212)
Group Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
-> Gather Merge (cost=12149.83..12186.26 rows=274 width=84)
Workers Planned: 2
-> Partial GroupAggregate (cost=11149.81..11154.61 rows=137 width=84)
Group Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
-> Sort (cost=11149.81..11150.15 rows=137 width=37)
Sort Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
-> Nested Loop (cost=1.54..11144.95 rows=137 width=37)
-> Nested Loop (cost=1.12..11085.56 rows=137 width=37)
-> Nested Loop (cost=0.70..10184.52 rows=36 width=44)
-> Nested Loop Anti Join (cost=0.42..10164.18 rows=36 width=44)
-> Parallel Seq Scan on invxf s_1 (cost=0.00..10085.37 rows=37 width=44)
Filter: (((cls)::text = '门店调拨'::text) AND (stat = 700))
-> Index Only Scan using invxflog_pkey on invxflog lg (cost=0.42..2.08 rows=1 widt
h=28)
Index Cond: ((num = (s_1.num)::text) AND (cls = (s_1.cls)::text) AND (cls = '
店调拨'::text))
Filter: (stat = ANY ('{710,730}'::integer[]))
-> Index Only Scan using store_pkey on store st (cost=0.27..0.57 rows=1 width=4)
Index Cond: (gid = s_1.fromstore)
-> Index Scan using invxfdtl_pkey on invxfdtl dtl (cost=0.42..24.81 rows=22 width=49)
Index Cond: (((num)::text = (s_1.num)::text) AND ((cls)::text = '门店调拨'::text))
-> Index Only Scan using goods_pkey on goods g_2 (cost=0.41..0.43 rows=1 width=4)
Index Cond: (gid = dtl.gdgid)
-> Subquery Scan on "*SELECT* 3" (cost=46345.62..51986.79 rows=38905 width=200)
-> Finalize GroupAggregate (cost=46345.62..51597.74 rows=38905 width=192)
Group Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid, s_2.cls
-> Gather Merge (cost=46345.62..49721.15 rows=22885 width=96)
Workers Planned: 1
-> Partial GroupAggregate (cost=45345.61..46146.58 rows=22885 width=96)
Group Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid, s_2.cls
-> Sort (cost=45345.61..45402.82 rows=22885 width=43)
Sort Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid
-> Parallel Hash Join (cost=1503.56..43688.49 rows=22885 width=43)
Hash Cond: (dtl_1.gdgid = g_3.gid)
-> Nested Loop (cost=1.72..42126.58 rows=22885 width=43)
-> Merge Join (cost=1.29..14277.68 rows=9225 width=39)
Merge Cond: (s_2.client = st_1.gid)
-> Parallel Index Scan using idx_stkoutbck_sc on stkoutbck s_2 (cost=0.42..14297.24 rows
=15223 width=39)
Index Cond: (stat = 700)
Filter: ((cls)::text = '统配出退'::text)
-> Index Only Scan using store_pkey on store st_1 (cost=0.27..38.75 rows=263 width=4)
-> Index Scan using stkoutbckdtl_pkey on stkoutbckdtl dtl_1 (cost=0.43..2.91 rows=11 width=46)
Index Cond: (((cls)::text = '统配出退'::text) AND ((num)::text = (s_2.num)::text))
-> Parallel Hash (cost=1187.80..1187.80 rows=25123 width=4)
-> Parallel Index Only Scan using goods_pkey on goods g_3 (cost=0.41..1187.80 rows=25123 width
=4)
-> Sort (cost=61632.22..61808.30 rows=70430 width=12)
Sort Key: ((g_1.gid)::text)
-> Bitmap Heap Scan on orggoodsh g_1 (cost=6017.80..55961.24 rows=70430 width=12)
Recheck Cond: (orggid = 1000001)
-> Bitmap Index Scan on idx_orggoodsh_orggdcode_upper (cost=0.00..6000.19 rows=70430 width=0)
Index Cond: (orggid = 1000001)
-> Sort (cost=84606.35..84606.35 rows=1 width=352)
Sort Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.
cntinprc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.validperiod, (array_to_string(array_agg(gd1.name ORDER BY gds.code), ','::text)), g.amiba
-> Nested Loop Left Join (cost=37460.06..84606.34 rows=1 width=352)
Join Filter: (g.gid = gds.gdgid)
-> Hash Join (cost=20285.74..64498.21 rows=1 width=324)
Hash Cond: ((g.gid = r.gdgid) AND ((g.code)::text = (r.inputcode)::text))
-> Hash Join (cost=2620.33..45399.97 rows=57313 width=318)
Hash Cond: (g.vdrgid = v.gid)
-> Hash Join (cost=1893.75..44522.82 rows=57313 width=275)
Hash Cond: (g.busgate = gb.gid)
-> Hash Left Join (cost=1892.09..44348.74 rows=57313 width=263)
Hash Cond: ((g.orggid = i.orggid) AND ((g.gid)::text = (i.gdgid)::text))
-> Hash Join (cost=1874.03..43746.09 rows=57313 width=199)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '6'::numeric) = (sortname_3.scode)::text)
-> Hash Join (cost=1734.27..43445.83 rows=58257 width=184)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '4'::numeric) = (sortname_2.scode)::text)
-> Hash Join (cost=1594.51..43142.91 rows=59216 width=163)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '3'::numeric) = (sortname_1.scode)::text)
-> Hash Join (cost=1454.75..42837.32 rows=60191 width=142)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '2'::numeric) = (sortname.scode)::text)
-> Bitmap Heap Scan on orggoods g (cost=1314.98..42529.00 rows=61182 width=121)
Recheck Cond: (orggid = 1000001)
-> Bitmap Index Scan on orggoods_orggid_idx1 (cost=0.00..1299.69 rows=61182 width=0)
Index Cond: (orggid = 1000001)
-> Hash (cost=110.15..110.15 rows=2369 width=21)
-> Seq Scan on sortname (cost=0.00..110.15 rows=2369 width=21)
Filter: ((acode)::text = '0000'::text)
-> Hash (cost=110.15..110.15 rows=2369 width=21)
-> Seq Scan on sortname sortname_1 (cost=0.00..110.15 rows=2369 width=21)
Filter: ((acode)::text = '0000'::text)
-> Hash (cost=110.15..110.15 rows=2369 width=21)
-> Seq Scan on sortname sortname_2 (cost=0.00..110.15 rows=2369 width=21)
Filter: ((acode)::text = '0000'::text)
-> Hash (cost=110.15..110.15 rows=2369 width=21)
-> Seq Scan on sortname sortname_3 (cost=0.00..110.15 rows=2369 width=21)
Filter: ((acode)::text = '0000'::text)
-> Hash (cost=18.00..18.00 rows=4 width=100)
-> CTE Scan on temp_yc_v_online_storeinv i (cost=0.00..18.00 rows=4 width=100)
Filter: (orggid = 1000001)
-> Hash (cost=1.29..1.29 rows=29 width=20)
-> Seq Scan on goodsbusgate gb (cost=0.00..1.29 rows=29 width=20)
-> Hash (cost=655.15..655.15 rows=5715 width=51)
-> Seq Scan on vendorh v (cost=0.00..655.15 rows=5715 width=51)
-> Hash (cost=17595.41..17595.41 rows=4666 width=25)
-> Gather (cost=1000.00..17595.41 rows=4666 width=25)
Workers Planned: 3
-> Parallel Seq Scan on rpggd r (cost=0.00..16128.81 rows=1505 width=25)
Filter: (DECODE( gcode , '9901'::character varying , 1000001 , '9902'::character varying , 1000002 , '9908'::character varying , 1000311 , NULL::integer ) =
1000001)
-> GroupAggregate (cost=17174.32..18998.54 rows=49315 width=36)
Group Key: gds.gdgid
-> Sort (cost=17174.32..17535.82 rows=144600 width=27)
Sort Key: gds.gdgid
-> Nested Loop (cost=0.42..4780.86 rows=144600 width=27)
-> Seq Scan on gdsalescheme gd1 (cost=0.00..1.28 rows=8 width=23)
Filter: (((code)::text <> '9901'::text) AND (orggid = 1000001))
-> Index Only Scan using gdsaleschemedtl_pkey on gdsaleschemedtl gds (cost=0.42..416.70 rows=18075 width=7)
Index Cond: (code = (gd1.code)::text)
(140 rows)
-- o 执行计划
Group (cost=40104.02..40104.10 rows=1 width=320)
Group Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.cntin
prc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.orggid, g.validperiod, (array_to_string(array_agg(gd1.name ORDER BY gds.code), ','::text)), g.amiba
-> Sort (cost=40104.02..40104.03 rows=1 width=288)
Sort Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.
cntinprc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.validperiod, (array_to_string(array_agg(gd1.name ORDER BY gds.code), ','::text)), g.amiba
-> Gather (cost=37663.23..40104.01 rows=1 width=288)
Workers Planned: 3
-> Merge Left Join (cost=36663.23..39103.91 rows=1 width=288)
Merge Cond: (g.gid = gds.gdgid)
-> Sort (cost=19488.91..19488.92 rows=1 width=260)
Sort Key: g.gid
-> Nested Loop (cost=1.97..19488.90 rows=1 width=260)
-> Nested Loop (cost=1.69..19488.60 rows=1 width=245)
-> Nested Loop (cost=1.41..19488.30 rows=1 width=224)
-> Nested Loop (cost=1.12..19487.99 rows=1 width=203)
-> Nested Loop (cost=0.84..19487.69 rows=1 width=182)
-> Nested Loop (cost=0.56..19487.38 rows=1 width=139)
-> Nested Loop (cost=0.42..19487.22 rows=1 width=127)
-> Parallel Seq Scan on rpggd r (cost=0.00..16128.81 rows=1505 width=25)
Filter: (DECODE( gcode , '9901'::character varying , 1000001 , '9902'::character varying , 1000002 , '9908'::character va
rying , 1000311 , NULL::integer ) = 1000001)
-> Index Scan using orggoods_orggid_idx1 on orggoods g (cost=0.42..2.23 rows=1 width=121)
Index Cond: ((orggid = 1000001) AND (gid = r.gdgid) AND ((code)::text = (r.inputcode)::text))
-> Index Scan using goodsbusgate_pkey on goodsbusgate gb (cost=0.14..0.16 rows=1 width=20)
Index Cond: (gid = g.busgate)
-> Index Scan using vendorh_pkey on vendorh v (cost=0.28..0.31 rows=1 width=51)
Index Cond: (gid = g.vdrgid)
-> Index Scan using sortname_pkey on sortname (cost=0.28..0.30 rows=1 width=21)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '2'::numeric)))
-> Index Scan using sortname_pkey on sortname sortname_1 (cost=0.28..0.30 rows=1 width=21)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '3'::numeric)))
-> Index Scan using sortname_pkey on sortname sortname_2 (cost=0.28..0.30 rows=1 width=21)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '4'::numeric)))
-> Index Scan using sortname_pkey on sortname sortname_3 (cost=0.28..0.30 rows=1 width=21)
Index Cond: (((acode)::text = '0000'::text) AND ((scode)::text = substr((g.sort)::text, '1'::numeric, '6'::numeric)))
-> GroupAggregate (cost=17174.32..18998.54 rows=49315 width=36)
Group Key: gds.gdgid
-> Sort (cost=17174.32..17535.82 rows=144600 width=27)
Sort Key: gds.gdgid
-> Nested Loop (cost=0.42..4780.86 rows=144600 width=27)
-> Seq Scan on gdsalescheme gd1 (cost=0.00..1.28 rows=8 width=23)
Filter: (((code)::text <> '9901'::text) AND (orggid = 1000001))
-> Index Only Scan using gdsaleschemedtl_pkey on gdsaleschemedtl gds (cost=0.42..416.70 rows=18075 width=7)
Index Cond: (code = (gd1.code)::text)
(42 rows)
可以发现对于两者最上层的GroupAggregate节点

上一层的 join 方式不一样,o + s1 选择了 nestloop

而 o 选择了 mergejoin

,再次观察 o 的 analyze 执行计划发现,这个节点返回行数的估计值与实际值相差很大

而 GroupAggregate 节点执行一次时间也较长,如果循环了几万次,将会很耗时。

- 基于上述分析,尝试禁用 nestloop,再次执行 o + s1 ,发现 23500 ms 出结果。
-- o + s1 analyze 执行计划 (nestloop = off)
GroupAggregate (cost=1129317.30..1129317.40 rows=1 width=384) (actual time=23313.165..23417.385 rows=57661 loops=1)
Group Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.cntin
prc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.orggid, g.validperiod, gds.jyfa, g.amiba
Buffers: shared hit=550447 read=47001 dirtied=26477, temp read=8104 written=8105
I/O Timings: read=9984.454
CTE temp_yc_v_online_storeinv
-> GroupAggregate (cost=781838.24..1040629.41 rows=800 width=100) (actual time=13729.922..14967.845 rows=25909 loops=1)
Group Key: tt.goods_id, s.orggid
Buffers: shared hit=533482 read=8206 dirtied=26249, temp read=8104 written=8105
I/O Timings: read=3472.707
-> Merge Join (cost=781838.24..954439.26 rows=8617815 width=100) (actual time=13729.889..14596.130 rows=1340990 loops=1)
Merge Cond: ((tt.goods_id)::text = ((g_1.gid)::text))
Buffers: shared hit=533482 read=8206 dirtied=26249, temp read=8104 written=8105
I/O Timings: read=3472.707
-> Sort (cost=720206.01..720267.19 rows=24472 width=100) (actual time=13557.541..13766.656 rows=1340990 loops=1)
Sort Key: tt.goods_id
Sort Method: quicksort Memory: 148156kB
Buffers: shared hit=494156 read=8206 dirtied=26210, temp read=8104 written=8105
I/O Timings: read=3472.707
-> Merge Join (cost=713648.15..718422.14 rows=24472 width=100) (actual time=10311.040..12844.988 rows=1340990 loops=1)
Merge Cond: (((s.gid)::text) = (tt.store_id)::text)
Buffers: shared hit=494156 read=8206 dirtied=26210, temp read=8104 written=8105
I/O Timings: read=3472.707
-> Sort (cost=262.93..263.43 rows=200 width=8) (actual time=0.829..0.938 rows=199 loops=1)
Sort Key: ((s.gid)::text)
Sort Method: quicksort Memory: 35kB
Buffers: shared hit=594
-> Seq Scan on store s (cost=0.00..255.29 rows=200 width=8) (actual time=0.029..0.722 rows=200 loops=1)
Filter: (orggid = 1000001)
Rows Removed by Filter: 64
Buffers: shared hit=594
-> Materialize (cost=713385.22..717728.95 rows=24472 width=128) (actual time=10310.202..12556.273 rows=1593104 loops=1)
Buffers: shared hit=493562 read=8206 dirtied=26210, temp read=8104 written=8105
I/O Timings: read=3472.707
-> GroupAggregate (cost=713385.22..717423.05 rows=24472 width=232) (actual time=10310.197..12080.871 rows=1593104 loops=1)
Group Key: tt.store_id, tt.wrh_id, tt.goods_id
Buffers: shared hit=493562 read=8206 dirtied=26210, temp read=8104 written=8105
I/O Timings: read=3472.707
-> Sort (cost=713385.22..713997.01 rows=244717 width=160) (actual time=10310.175..10636.275 rows=1593644 loops=1)
Sort Key: tt.store_id, tt.wrh_id, tt.goods_id
Sort Method: external merge Disk: 64832kB
Buffers: shared hit=493562 read=8206 dirtied=26210, temp read=8104 written=8105
I/O Timings: read=3472.707
-> Subquery Scan on tt (cost=419375.97..691482.12 rows=244717 width=160) (actual time=948.557..8783.079 rows=1593644 loops=1)
Buffers: shared hit=493562 read=8206 dirtied=26210
I/O Timings: read=3472.707
-> Append (cost=419375.97..689034.95 rows=244717 width=200) (actual time=948.555..8548.472 rows=1593644 loops=1)
Buffers: shared hit=493562 read=8206 dirtied=26210
I/O Timings: read=3472.707
-> Finalize GroupAggregate (cost=419375.97..548869.62 rows=205484 width=128) (actual time=948.554..4512.409 rows=1593103 loops=1)
Group Key: t.orguuid, t.wrhuuid, t.gduuid
Buffers: shared hit=364579 read=101 dirtied=25672
I/O Timings: read=19.318
-> Gather Merge (cost=419375.97..529348.64 rows=821936 width=96) (actual time=948.539..2306.924 rows=1593103 loops=1)
Workers Planned: 4
Workers Launched: 4
Buffers: shared hit=364579 read=101 dirtied=25672
I/O Timings: read=19.318
-> Partial GroupAggregate (cost=418375.91..430448.08 rows=205484 width=96) (actual time=925.779..1422.139 rows=318621 loops=
5)
Group Key: t.orguuid, t.wrhuuid, t.gduuid
Buffers: shared hit=364579 read=101 dirtied=25672
I/O Timings: read=19.318
-> Sort (cost=418375.91..419660.18 rows=513709 width=39) (actual time=925.754..993.555 rows=318621 loops=5)
Sort Key: t.orguuid, t.wrhuuid, t.gduuid
Sort Method: quicksort Memory: 40601kB
Worker 0: Sort Method: quicksort Memory: 39103kB
Worker 1: Sort Method: quicksort Memory: 39190kB
Worker 2: Sort Method: quicksort Memory: 39802kB
Worker 3: Sort Method: quicksort Memory: 39654kB
Buffers: shared hit=364579 read=101 dirtied=25672
I/O Timings: read=19.318
-> Parallel Seq Scan on ycstd_store_inv t (cost=0.00..369649.09 rows=513709 width=39) (actual time=0.010..266.51
2 rows=318621 loops=5)
Buffers: shared hit=364411 read=101 dirtied=25672
I/O Timings: read=19.318
-> Subquery Scan on "*SELECT* 2" (cost=48341.48..48398.15 rows=328 width=200) (actual time=1547.404..1548.389 rows=172 loops=1)
Buffers: shared hit=44101 read=2017 dirtied=264
I/O Timings: read=970.485
-> Finalize GroupAggregate (cost=48341.48..48394.87 rows=328 width=212) (actual time=1547.401..1548.358 rows=172 loops=1)
Group Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
Buffers: shared hit=44101 read=2017 dirtied=264
I/O Timings: read=970.485
-> Gather Merge (cost=48341.48..48377.91 rows=274 width=84) (actual time=1547.376..1548.015 rows=172 loops=1)
Workers Planned: 2
Workers Launched: 0
Buffers: shared hit=44101 read=2017 dirtied=264
I/O Timings: read=970.485
-> Partial GroupAggregate (cost=47341.46..47346.26 rows=137 width=84) (actual time=1545.381..1545.640 rows=172 loops=1
)
Group Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
Buffers: shared hit=44101 read=2017 dirtied=264
I/O Timings: read=970.485
-> Sort (cost=47341.46..47341.80 rows=137 width=37) (actual time=1545.356..1545.385 rows=177 loops=1)
Sort Key: s_1.fromstore, s_1.fromwrh, dtl.gdgid
Sort Method: quicksort Memory: 40kB
Buffers: shared hit=44101 read=2017 dirtied=264
I/O Timings: read=970.485
-> Parallel Hash Join (cost=45991.75..47336.60 rows=137 width=37) (actual time=1523.981..1545.285 rows=177
loops=1)
Hash Cond: (g_2.gid = dtl.gdgid)
Buffers: shared hit=44101 read=2017 dirtied=264
I/O Timings: read=970.485
-> Parallel Index Only Scan using goods_pkey on goods g_2 (cost=0.41..1187.80 rows=25123 width=4) (a
ctual time=0.019..15.524 rows=58709 loops=1)
Heap Fetches: 6701
Buffers: shared hit=6780 dirtied=26
-> Parallel Hash (cost=45990.01..45990.01 rows=106 width=37) (actual time=1523.484..1523.496 rows=17
7 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 40kB
Buffers: shared hit=37321 read=2017 dirtied=238
I/O Timings: read=970.485
-> Hash Join (cost=17939.22..45990.01 rows=106 width=37) (actual time=489.094..1523.346 rows=1
77 loops=1)
Hash Cond: (s_1.fromstore = st.gid)
Buffers: shared hit=37321 read=2017 dirtied=238
I/O Timings: read=970.485
-> Parallel Hash Anti Join (cost=17897.18..45947.70 rows=106 width=37) (actual time=488.
854..1522.976 rows=177 loops=1)
Hash Cond: (((s_1.cls)::text = (lg.cls)::text) AND ((s_1.num)::text = (lg.num)::text
))
Buffers: shared hit=37155 read=2017 dirtied=238
I/O Timings: read=970.485
-> Parallel Hash Join (cost=10085.83..38134.72 rows=107 width=65) (actual time=225
.858..1259.841 rows=177 loops=1)
Hash Cond: ((dtl.num)::text = (s_1.num)::text)
Buffers: shared hit=31882 read=1658 dirtied=160
I/O Timings: read=786.374
-> Parallel Seq Scan on invxfdtl dtl (cost=0.00..27497.93 rows=209885 width=
49) (actual time=0.195..1131.472 rows=675648 loops=1)
Filter: ((cls)::text = '门店调拨'::text)
Rows Removed by Filter: 86558
Buffers: shared hit=22875 read=1658 dirtied=110
I/O Timings: read=786.374
-> Parallel Hash (cost=10085.37..10085.37 rows=37 width=44) (actual time=48.
657..48.658 rows=127 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 40kB
Buffers: shared hit=9007 dirtied=50
-> Parallel Seq Scan on invxf s_1 (cost=0.00..10085.37 rows=37 width=4
4) (actual time=5.824..48.590 rows=127 loops=1)
Filter: (((cls)::text = '门店调拨'::text) AND (stat = 700))
Rows Removed by Filter: 192489
Buffers: shared hit=9007 dirtied=50
-> Parallel Hash (cost=7799.12..7799.12 rows=815 width=28) (actual time=262.971..2
62.972 rows=4237 loops=1)
Buckets: 4096 (originally 2048) Batches: 1 (originally 1) Memory Usage: 336k
B
Buffers: shared hit=5273 read=359 dirtied=78
I/O Timings: read=184.111
-> Parallel Seq Scan on invxflog lg (cost=0.00..7799.12 rows=815 width=28) (
actual time=54.218..261.379 rows=4237 loops=1)
Filter: ((stat = ANY ('{710,730}'::integer[])) AND ((cls)::text = '门店
拨'::text))
Rows Removed by Filter: 461072
Buffers: shared hit=5273 read=359 dirtied=78
I/O Timings: read=184.111
-> Hash (cost=38.75..38.75 rows=263 width=4) (actual time=0.230..0.230 rows=264 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 18kB
Buffers: shared hit=166
-> Index Only Scan using store_pkey on store st (cost=0.27..38.75 rows=263 width=4
) (actual time=0.012..0.187 rows=264 loops=1)
Heap Fetches: 190
Buffers: shared hit=166
-> Subquery Scan on "*SELECT* 3" (cost=80888.45..88488.77 rows=38905 width=200) (actual time=2321.665..2330.156 rows=369 loops=1)
Buffers: shared hit=84882 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Finalize GroupAggregate (cost=80888.45..88099.72 rows=38905 width=192) (actual time=2321.664..2330.091 rows=369 loops=1)
Group Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid, s_2.cls
Buffers: shared hit=84882 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Gather Merge (cost=80888.45..85862.70 rows=38904 width=96) (actual time=2321.645..2329.287 rows=452 loops=1)
Workers Planned: 4
Workers Launched: 4
Buffers: shared hit=84882 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Partial GroupAggregate (cost=79888.39..80228.80 rows=9726 width=96) (actual time=2307.572..2313.515 rows=90 loops=5
)
Group Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid, s_2.cls
Buffers: shared hit=84882 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Sort (cost=79888.39..79912.71 rows=9726 width=43) (actual time=2307.547..2308.703 rows=14165 loops=5)
Sort Key: s_2.client, dtl_1.recvwrh, dtl_1.gdgid
Sort Method: quicksort Memory: 1367kB
Worker 0: Sort Method: quicksort Memory: 1673kB
Worker 1: Sort Method: quicksort Memory: 1611kB
Worker 2: Sort Method: quicksort Memory: 1685kB
Worker 3: Sort Method: quicksort Memory: 1675kB
Buffers: shared hit=84882 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Parallel Hash Join (cost=16031.40..79244.16 rows=9726 width=43) (actual time=23.423..2298.853 rows=1416
5 loops=5)
Hash Cond: (dtl_1.gdgid = g_3.gid)
Buffers: shared hit=84854 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Hash Join (cost=14529.56..77716.79 rows=9726 width=43) (actual time=10.252..2281.131 rows=14165 l
oops=5)
Hash Cond: (s_2.client = st_1.gid)
Buffers: shared hit=78033 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Parallel Hash Join (cost=14487.53..77632.21 rows=16050 width=43) (actual time=9.750..2276.6
55 rows=14165 loops=5)
Hash Cond: ((dtl_1.num)::text = (s_2.num)::text)
Buffers: shared hit=77199 read=6088 dirtied=274
I/O Timings: read=2482.904
-> Parallel Seq Scan on stkoutbckdtl dtl_1 (cost=0.00..62460.32 rows=260706 width=46) (a
ctual time=0.007..2220.934 rows=209096 loops=5)
Filter: ((cls)::text = '统配出退'::text)
Rows Removed by Filter: 4132
Buffers: shared hit=53048 read=6088 dirtied=211
I/O Timings: read=2482.904
-> Parallel Hash (cost=14297.24..14297.24 rows=15223 width=39) (actual time=9.570..9.571
rows=4534 loops=5)
Buckets: 32768 Batches: 1 Memory Usage: 2080kB
Buffers: shared hit=24107 dirtied=63
-> Parallel Index Scan using idx_stkoutbck_sc on stkoutbck s_2 (cost=0.42..14297.2
4 rows=15223 width=39) (actual time=0.044..7.112 rows=4534 loops=5)
Index Cond: (stat = 700)
Filter: ((cls)::text = '统配出退'::text)
Rows Removed by Filter: 641
Buffers: shared hit=24107 dirtied=63
-> Hash (cost=38.75..38.75 rows=263 width=4) (actual time=0.479..0.479 rows=264 loops=5)
Buckets: 1024 Batches: 1 Memory Usage: 18kB
Buffers: shared hit=834
-> Index Only Scan using store_pkey on store st_1 (cost=0.27..38.75 rows=263 width=4) (a
ctual time=0.100..0.429 rows=264 loops=5)
Heap Fetches: 950
Buffers: shared hit=834
-> Parallel Hash (cost=1187.80..1187.80 rows=25123 width=4) (actual time=13.016..13.017 rows=11742 l
oops=5)
Buckets: 65536 Batches: 1 Memory Usage: 2880kB
Buffers: shared hit=6789
-> Parallel Index Only Scan using goods_pkey on goods g_3 (cost=0.41..1187.80 rows=25123 width
=4) (actual time=0.231..9.637 rows=11742 loops=5)
Heap Fetches: 6701
Buffers: shared hit=6789
-> Sort (cost=61632.22..61808.30 rows=70430 width=12) (actual time=172.337..261.046 rows=1373840 loops=1)
Sort Key: ((g_1.gid)::text)
Sort Method: quicksort Memory: 6587kB
Buffers: shared hit=39326 dirtied=39
-> Bitmap Heap Scan on orggoodsh g_1 (cost=6017.80..55961.24 rows=70430 width=12) (actual time=28.026..145.077 rows=58767 loops=1)
Recheck Cond: (orggid = 1000001)
Heap Blocks: exact=36833
Buffers: shared hit=39326 dirtied=39
-> Bitmap Index Scan on idx_orggoodsh_orggdcode_upper (cost=0.00..6000.19 rows=70430 width=0) (actual time=21.203..21.203 rows=59967 loops=1)
Index Cond: (orggid = 1000001)
Buffers: shared hit=2493
-> Sort (cost=88687.89..88687.90 rows=1 width=352) (actual time=23313.136..23322.700 rows=57661 loops=1)
Sort Key: sortname.scode, sortname.sname, sortname_1.scode, sortname_1.sname, sortname_2.scode, sortname_2.sname, sortname_3.scode, sortname_3.sname, g.code, g.code2, g.defpu, r.rtlprc, g.
cntinprc, g.name, g.spec, g.alc, gb.name, v.code, v.name, g.country, g.tm, g.validperiod, gds.jyfa, g.amiba
Sort Method: quicksort Memory: 29228kB
Buffers: shared hit=192749 read=42013 dirtied=6514, temp read=8104 written=8105
I/O Timings: read=7966.522
-> Hash Left Join (cost=44475.41..88687.88 rows=1 width=352) (actual time=16338.900..22791.190 rows=57661 loops=1)
Hash Cond: (g.gid = gds.gdgid)
Buffers: shared hit=192746 read=42013 dirtied=6514, temp read=8104 written=8105
I/O Timings: read=7966.522
-> Hash Join (cost=20285.74..64498.21 rows=1 width=324) (actual time=15739.294..22150.254 rows=57661 loops=1)
Hash Cond: ((g.gid = r.gdgid) AND ((g.code)::text = (r.inputcode)::text))
Buffers: shared hit=188907 read=41755 dirtied=6514, temp read=8104 written=8105
I/O Timings: read=7826.643
-> Hash Join (cost=2620.33..45399.97 rows=57313 width=318) (actual time=15176.083..21532.289 rows=57661 loops=1)
Hash Cond: (g.vdrgid = v.gid)
Buffers: shared hit=177553 read=40743 dirtied=6492, temp read=8104 written=8105
I/O Timings: read=7352.515
-> Hash Join (cost=1893.75..44522.82 rows=57313 width=275) (actual time=15149.977..21475.708 rows=57661 loops=1)
Hash Cond: (g.busgate = gb.gid)
Buffers: shared hit=176994 read=40704 dirtied=6492, temp read=8104 written=8105
I/O Timings: read=7331.714
-> Hash Left Join (cost=1892.09..44348.74 rows=57313 width=263) (actual time=15149.706..21451.028 rows=57661 loops=1)
Hash Cond: ((g.orggid = i.orggid) AND ((g.gid)::text = (i.gdgid)::text))
Buffers: shared hit=176994 read=40703 dirtied=6492, temp read=8104 written=8105
I/O Timings: read=7331.550
-> Hash Join (cost=1874.03..43746.09 rows=57313 width=199) (actual time=159.533..6403.588 rows=57661 loops=1)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '6'::numeric) = (sortname_3.scode)::text)
Buffers: shared hit=1210 read=37485 dirtied=206
I/O Timings: read=5876.774
-> Hash Join (cost=1734.27..43445.83 rows=58257 width=184) (actual time=154.793..6343.266 rows=57974 loops=1)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '4'::numeric) = (sortname_2.scode)::text)
Buffers: shared hit=1136 read=37479 dirtied=206
I/O Timings: read=5873.563
-> Hash Join (cost=1594.51..43142.91 rows=59216 width=163) (actual time=153.656..6287.467 rows=58269 loops=1)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '3'::numeric) = (sortname_1.scode)::text)
Buffers: shared hit=1056 read=37479 dirtied=206
I/O Timings: read=5873.563
-> Hash Join (cost=1454.75..42837.32 rows=60191 width=142) (actual time=152.529..6231.446 rows=58651 loops=1)
Hash Cond: (substr((g.sort)::text, '1'::numeric, '2'::numeric) = (sortname.scode)::text)
Buffers: shared hit=976 read=37479 dirtied=206
I/O Timings: read=5873.563
-> Bitmap Heap Scan on orggoods g (cost=1314.98..42529.00 rows=61182 width=121) (actual time=151.424..6165.760 rows=58701 loops=1)
Recheck Cond: (orggid = 1000001)
Heap Blocks: exact=37575
Buffers: shared hit=896 read=37479 dirtied=206
I/O Timings: read=5873.563
-> Bitmap Index Scan on orggoods_orggid_idx1 (cost=0.00..1299.69 rows=61182 width=0) (actual time=144.145..144.145 rows=59901
loops=1)
Index Cond: (orggid = 1000001)
Buffers: shared hit=52 read=748
I/O Timings: read=130.214
-> Hash (cost=110.15..110.15 rows=2369 width=21) (actual time=1.063..1.063 rows=2381 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 158kB
Buffers: shared hit=80
-> Seq Scan on sortname (cost=0.00..110.15 rows=2369 width=21) (actual time=0.003..0.522 rows=2381 loops=1)
Filter: ((acode)::text = '0000'::text)
Rows Removed by Filter: 48
Buffers: shared hit=80
-> Hash (cost=110.15..110.15 rows=2369 width=21) (actual time=1.098..1.100 rows=2381 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 158kB
Buffers: shared hit=80
-> Seq Scan on sortname sortname_1 (cost=0.00..110.15 rows=2369 width=21) (actual time=0.006..0.549 rows=2381 loops=1)
Filter: ((acode)::text = '0000'::text)
Rows Removed by Filter: 48
Buffers: shared hit=80
-> Hash (cost=110.15..110.15 rows=2369 width=21) (actual time=1.126..1.127 rows=2381 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 158kB
Buffers: shared hit=80
-> Seq Scan on sortname sortname_2 (cost=0.00..110.15 rows=2369 width=21) (actual time=0.022..0.590 rows=2381 loops=1)
Filter: ((acode)::text = '0000'::text)
Rows Removed by Filter: 48
Buffers: shared hit=80
-> Hash (cost=110.15..110.15 rows=2369 width=21) (actual time=4.725..4.726 rows=2381 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 158kB
Buffers: shared hit=74 read=6
I/O Timings: read=3.211
-> Seq Scan on sortname sortname_3 (cost=0.00..110.15 rows=2369 width=21) (actual time=0.216..4.237 rows=2381 loops=1)
Filter: ((acode)::text = '0000'::text)
Rows Removed by Filter: 48
Buffers: shared hit=74 read=6
I/O Timings: read=3.211
-> Hash (cost=18.00..18.00 rows=4 width=100) (actual time=14990.139..14990.140 rows=25909 loops=1)
Buckets: 32768 (originally 1024) Batches: 1 (originally 1) Memory Usage: 1620kB
Buffers: shared hit=175784 read=3218 dirtied=6286, temp read=8104 written=8105
I/O Timings: read=1454.775
-> CTE Scan on temp_yc_v_online_storeinv i (cost=0.00..18.00 rows=4 width=100) (actual time=13729.928..14982.796 rows=25909 loops=1)
Filter: (orggid = 1000001)
Buffers: shared hit=175784 read=3218 dirtied=6286, temp read=8104 written=8105
I/O Timings: read=1454.775
-> Hash (cost=1.29..1.29 rows=29 width=20) (actual time=0.258..0.259 rows=29 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
Buffers: shared read=1
I/O Timings: read=0.164
-> Seq Scan on goodsbusgate gb (cost=0.00..1.29 rows=29 width=20) (actual time=0.247..0.251 rows=29 loops=1)
Buffers: shared read=1
I/O Timings: read=0.164
-> Hash (cost=655.15..655.15 rows=5715 width=51) (actual time=26.060..26.061 rows=4259 loops=1)
Buckets: 8192 Batches: 1 Memory Usage: 422kB
Buffers: shared hit=559 read=39
I/O Timings: read=20.801
-> Seq Scan on vendorh v (cost=0.00..655.15 rows=5715 width=51) (actual time=0.256..24.921 rows=4259 loops=1)
Buffers: shared hit=559 read=39
I/O Timings: read=20.801
-> Hash (cost=17595.41..17595.41 rows=4666 width=25) (actual time=563.176..563.289 rows=117336 loops=1)
Buckets: 131072 (originally 8192) Batches: 1 (originally 1) Memory Usage: 7898kB
Buffers: shared hit=11354 read=1012 dirtied=22
I/O Timings: read=474.128
-> Gather (cost=1000.00..17595.41 rows=4666 width=25) (actual time=2.011..534.020 rows=117336 loops=1)
Workers Planned: 3
Workers Launched: 3
Buffers: shared hit=11354 read=1012 dirtied=22
I/O Timings: read=474.128
-> Parallel Seq Scan on rpggd r (cost=0.00..16128.81 rows=1505 width=25) (actual time=0.243..528.498 rows=29334 loops=4)
Filter: (DECODE( gcode , '9901'::character varying , 1000001 , '9902'::character varying , 1000002 , '9908'::character varying , 1000311 , NULL::integer ) =
1000001)
Rows Removed by Filter: 205338
Buffers: shared hit=11354 read=1012 dirtied=22
I/O Timings: read=474.128
-> Hash (cost=23573.24..23573.24 rows=49315 width=36) (actual time=599.266..599.271 rows=37822 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 4285kB
Buffers: shared hit=3839 read=258
I/O Timings: read=139.879
-> Subquery Scan on gds (cost=21255.86..23573.24 rows=49315 width=36) (actual time=367.168..589.813 rows=37822 loops=1)
Buffers: shared hit=3839 read=258
I/O Timings: read=139.879
-> GroupAggregate (cost=21255.86..23080.09 rows=49315 width=36) (actual time=367.166..583.407 rows=37822 loops=1)
Group Key: gds_1.gdgid
Buffers: shared hit=3839 read=258
I/O Timings: read=139.879
-> Sort (cost=21255.86..21617.36 rows=144600 width=27) (actual time=367.120..391.182 rows=198884 loops=1)
Sort Key: gds_1.gdgid
Sort Method: quicksort Memory: 22180kB
Buffers: shared hit=3839 read=258
I/O Timings: read=139.879
-> Hash Join (cost=1.39..8862.41 rows=144600 width=27) (actual time=0.539..290.520 rows=198884 loops=1)
Hash Cond: ((gds_1.code)::text = (gd1.code)::text)
Buffers: shared hit=3839 read=258
I/O Timings: read=139.879
-> Seq Scan on gdsaleschemedtl gds_1 (cost=0.00..7711.00 rows=361500 width=7) (actual time=0.251..215.365 rows=364404 loops=1)
Buffers: shared hit=3839 read=257
I/O Timings: read=139.699
-> Hash (cost=1.28..1.28 rows=8 width=23) (actual time=0.264..0.265 rows=7 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
Buffers: shared read=1
I/O Timings: read=0.180
-> Seq Scan on gdsalescheme gd1 (cost=0.00..1.28 rows=8 width=23) (actual time=0.253..0.258 rows=7 loops=1)
Filter: (((code)::text <> '9901'::text) AND (orggid = 1000001))
Rows Removed by Filter: 12
Buffers: shared read=1
I/O Timings: read=0.180
Planning Time: 18.960 ms
Execution Time: 23474.323 ms
(367 rows)
观察到估计误差较大的情况依然存在

而GroupAggregate执行时间约为 583.407 ms,如果采用 nestloop,预计耗时为 57661 * 583.407 ms = 33639831.027 ms。

- 对其他组合SQL以及原始SQL进行 explain 执行计划查看,情况都类似。关闭 nestloop 后,原SQL 111906.768 ms 出结果。相对原来执行时间显著缩短(优化之后主要耗时点集中在 sort 与 I / O 操作上)。
实际上,这个 case 中估计误差大产生的原因是统计信息采样值较低,采用与 case 6 相同的方法可以解决问题。这里只是想分享下分析思路。
对于长时间执行不出结果的慢 SQL,我们可以先观察它的 EXPLAIN 计划,然后结合之前的优化经验,缩小 SQL 中执行慢的范围,然后再确定慢的原因以及解决方法,需要分析的同学有一定的排查经验。
case 17
实际生产业务的 SQL 在绝大多数情况下是通过驱动发送到数据库,而为了增加业务逻辑的复用性以及数据库的执行效率,往往会使用参数化的 SQL。对于参数化 SQL,PG 在生成计划时需要确定每个参数的类型,不同参数的类型可能会生成不一样的执行计划。参数类型可以在驱动中指定,也可以不指定由数据库自行推导。如果遇到参数化慢 SQL,我们需要将参数的具体数值填入才能得到执行计划,但有时可能没有和慢 SQL 的参数类型保持一致,得到不同的执行计划。比如这一个 case:
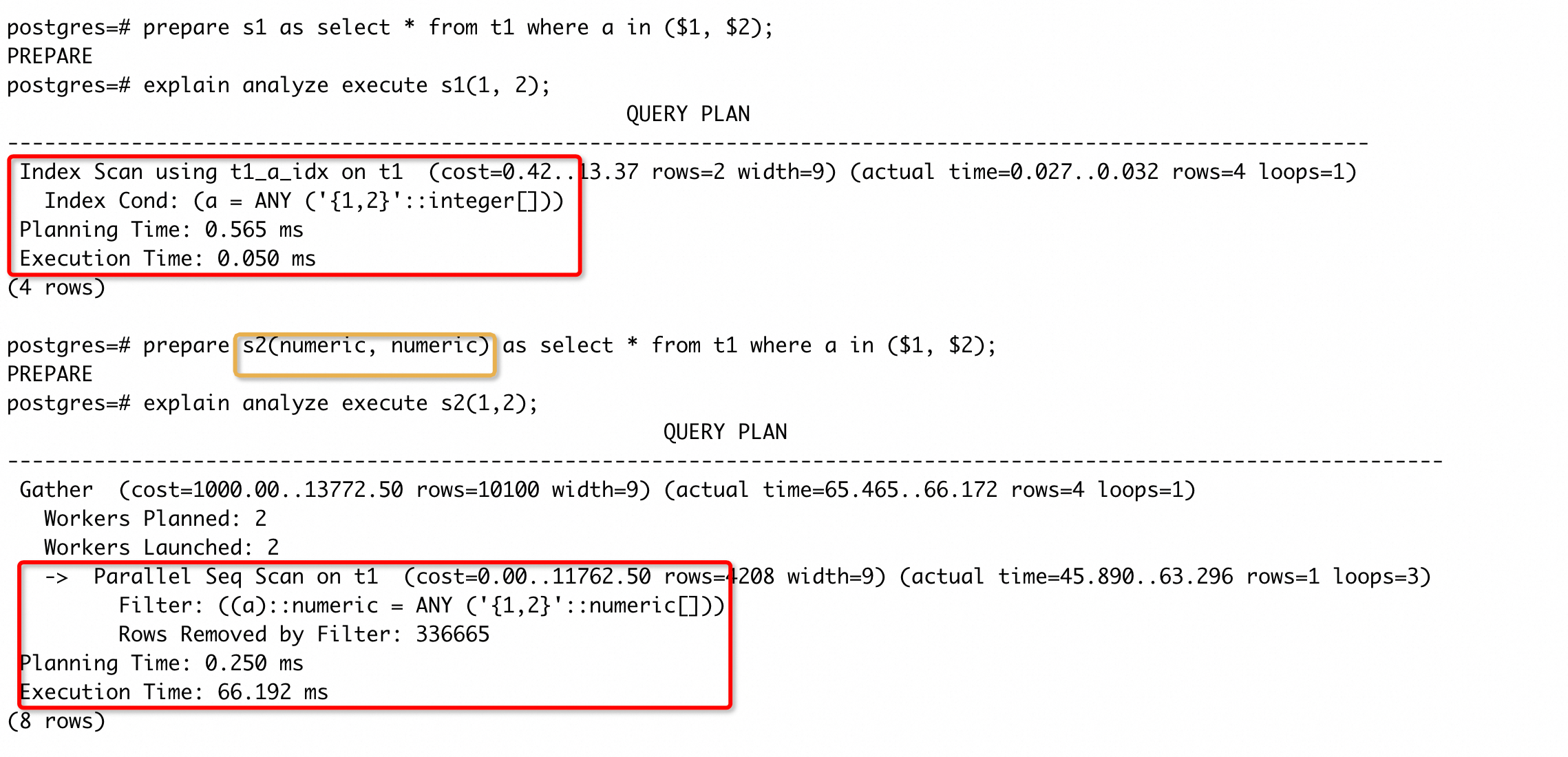
我们使用 prepare 语法来定义参数化 SQL。s1 定义时没有指定参数类型,因此优化器自行推导的参数类型为 integer,执行计划中能够使用 index scan,执行时间较快。s2 定义时指定了参数类型都为 numeric,执行计划中会在 a 列上添加了到 numeric 的转换,导致执行计划中没有使用 index scan,从而产生慢 SQL。
在排查问题时,我们如果不清楚驱动定义的参数类型,往往不会指定参数类型,让优化器自行推导。如果此时我们恰好得到了 s1 的执行计划,而业务上是 s2 的执行计划,就会发现执行时间和业务上感知的不一样,没有什么优化空间,不能解决问题。遇到这种情况,如果我们能够得到业务 SQL 的执行计划,就能够确定问题了。PG 提供了 auot_explain 的模块,可以用来自动记录慢查询的执行计划,并且不需要使用 EXPLAIN 命令。auto_explain 是一个动态库,使用前需要先确保已经被载入。一般做法是把 auto_explain 加入session_preload_libraries或者shared_preload_libraries中,让新建会话默认加载。通过调整 auto_explain 参数,我们可以在日志中记录期望慢 SQL 的执行计划,这样就能够确定业务 SQL 执行慢的原因。注意,auto_explain 会带来额外的开销,影响整体效率,所以不要默认开启,并且使用后要及时关闭。
复现 SQL 和实际业务 SQL 执行时间相差较大的情况,很有可能是两者的执行计划不一致。这种情况下,学会使用 auto_explain 能够有效帮助你捕获业务 SQL 的执行计划,从而确定和解决问题。
case 18
客户选择数据库时会对比不同数据库之间的性能,而每款数据库的优化能力都有些差异。在某种场景下,可能 A 数据库能够优化,SQL 执行很快,但是 B 数据库缺少这种优化能力,SQL 执行很慢。这里以 PG 和 Oracle 做对比,列出 PG 缺少 OR 转 UNION ALL 的 case(这里并不是要说明两款数据库哪一款更优,因为本文是说 PG 慢 SQL 优化,所以列举了一个 PG 没有优化的场景):
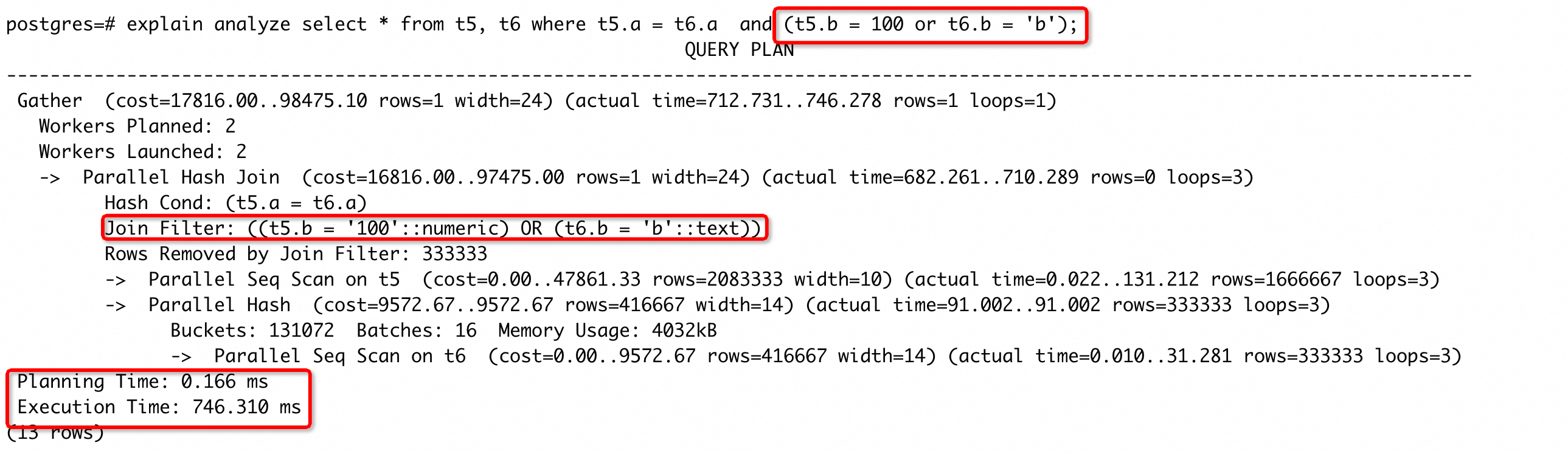
从原始 SQL 的执行计划中可以看到t5.b = 100 or t6.b = 'b'这个条件并没有下推到 t5 和 t6 上,因此两张表都需要进行 seq scan,导致执行时间长。我们将 SQL 改写下面的形式,再次执行:
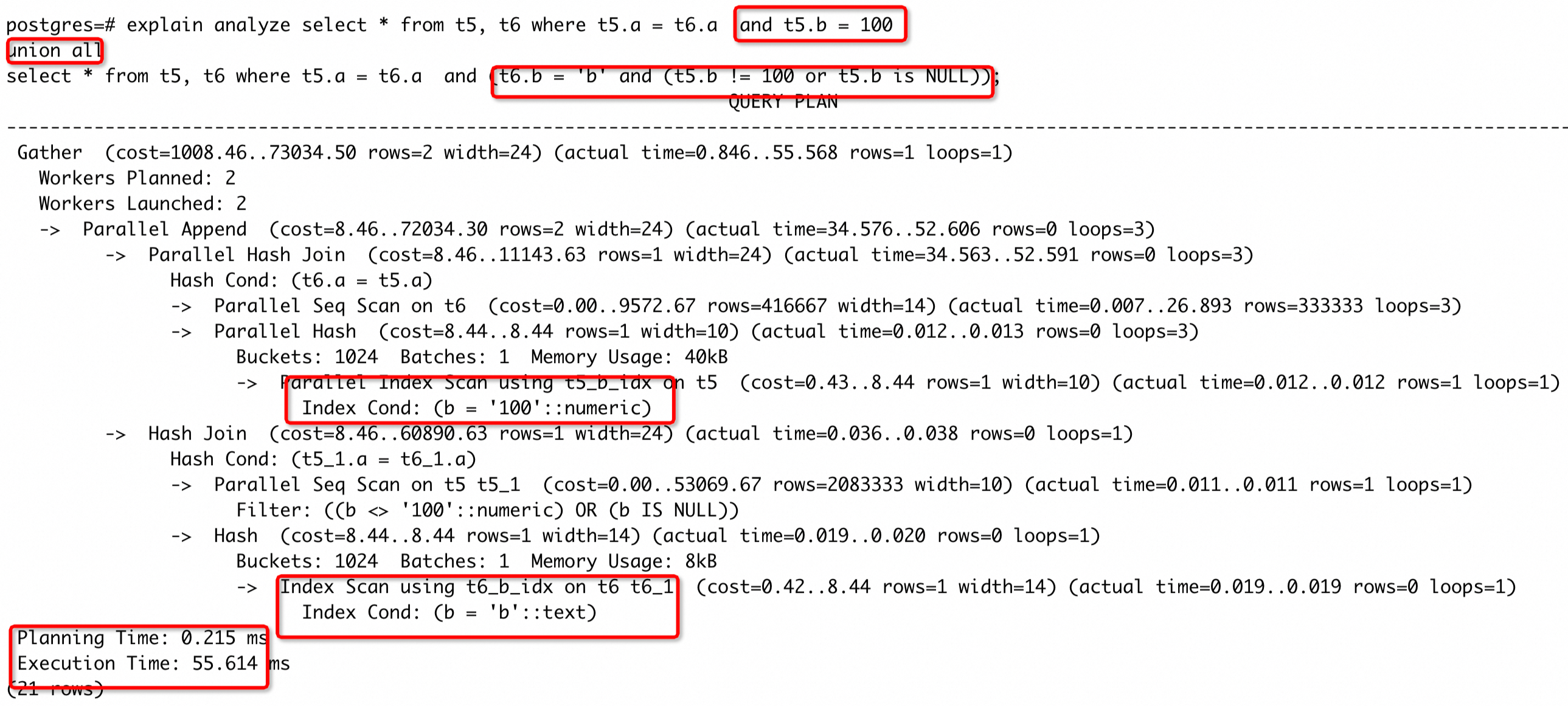
可以看到两张表都走了 index scan,执行时间明显降低。这种 UNION ALL 的改写形式和原始 OR 的写法是等价的,Oracle 优化器能够自动进行这个转换(可以参考文章),但是 PG 不能自动做这个优化。如果在 PG 遇到这种情况,我们能做的就是增大并行,或者手动改写 SQL。如果你是内核的开发者,也可以考虑补全这个能力,抑或是跟社区进行讨论补全这个能力。
对于缺失某种优化能力的情况,我们短期内能够做的就是确定问题原因,然后看下是否有等价改写的方式来加速 SQL,长期可以考虑补齐这种优化能力。
总结
本文主要分享了 PostgreSQL SQL 自身执行较慢优化的一些经验和原理。开头先表达了分析和解决慢 SQL 的必要性,再介绍了几种监控慢 SQL 的方法,然后介绍了慢 SQL 产生的原因以及对应的优化思路。 在优化慢 SQL 章节中,本文先介绍了慢 SQL 产生的常见原因,再介绍了排查慢 SQL 的重要指令 EXPLAIN 和查看执行计划的小工具,然后通过 18 个具体的 case 来说明了六类常见慢 SQL 产生的原理以及对应的优化方法。
参考文献
[1] Proceedings of ACM SIGMOD International Conference on Management of Data, 1998, Pages 436-447