What's new in PolarDB8.4(二)完备的集合操作
Author: 陈江(恬泰),淇泉
前言
PolarDB8.4已经在内测阶段了,前文介绍了What’s new in PolarDB8.4(一) prepare once ,本文继续介绍一下PolarDB8.4另一新特性-完备的集合操作,包含union, intersect, except, unary。相比较之下PolarDB8.0.2仅支持union,unary,并且8.4已经能支持集合的任意嵌套操作,大大丰富了实际使用场景。本篇文章将介绍PolarDB8.4集合运算新特性,以及具体是如何实现的。 PolarDB8.4对标的是社区mysql8.4,展示的代码是8.4.2版本代码。先让我们看看8.4里面新增的集合算子
集合操作语法介绍
mysql> select * from t1;
+------+
| a |
+------+
| 1 |
| 2 |
| 2 |
+------+
mysql> select * from t3;
+------+
| a |
+------+
| 2 |
| 3 |
| 3 |
| 2 |
intersect all(集合交集语义)
mysql> select * from t1 intersect all select * from t3;
+------+
| a |
+------+
| 2 |
| 2 |
+------+
intersect distinct
mysql> select * from t1 intersect distinct select * from t3;
+------+
| a |
+------+
| 2 |
+------+
except all(集合差集语义)
mysql> select * from t3 except all select * from t1
-> ;
+------+
| a |
+------+
| 3 |
| 3 |
+------+
except distinct
mysql> select * from t3 except distinct select * from t1;
+------+
| a |
+------+
| 3 |
+------+
unary
只能追加orderby, limit算子
mysql> (select distinct * from t3 )order by a desc;
+------+
| a |
+------+
| 3 |
| 2 |
+------+
集合并集语义:union all/union distinct
早先版本就有,没有mysql使用经验的读者可以了解下
mysql> select * from t1 union all select * from t3;
+------+
| a |
+------+
| 1 |
| 2 |
| 2 |
| 2 |
| 3 |
| 3 |
| 2 |
+------+
新引入数据结构
为了支持任意嵌套的集合操作,查询树在之前的Query_expression, Query_block上引入Query_term的数据结构。
class Query_expression {
/**
The query block wherein this query expression is contained,
NULL if the query block is the outer-most one.
*/
Query_block *master;//父QB
/// The first query block in this query expression.
Query_block *slave;//孩子QB
// The query set operation structure, see doc for Query_term.
Query_term *m_query_term{nullptr}//用于描述集合运算,如果是Query_block类型代表最简单的QE,非set_op
}
无论Query_expression是简单还是集合运算,都有一个有效的m_query_term成员,如果是集合操作,则是Query_term_set_op的派生类。如果Query_expression是简单的(非集合运算),m_query_term指向唯一child query_block。
Query_term继承树
Query_term
|__Query_block
|__Query_term_set_op
|__Query_term_unary
|__Query_term_union
|__Query_term_intersect
|__Query_term_except
Query_term及成员
class Query_term {
/**
The query result for this term. Shared between n-ary set operands, the first
one holds it, cf. owning_operand. Except at top level, this is always a
Query_result_union.
*/
Query_result *m_setop_query_result{nullptr};
/**
The operand of a n-ary set operation (that owns the common query result) has
this set to true. It is always the first one.
*/
bool m_owning_operand{false};
/**
Result temporary table for the set operation, if applicable
*/
Table_ref *m_result_table{nullptr};
/**
Used only when streaming, i.e. not materialized result set
*/
mem_root_deque<Item *> *m_fields{nullptr};
}
m_setop_query_result及m_result_table都是多个QueryBlock共用操作的结果集,但临时表只需一个QB负责创建+销毁,所以搞了m_owning_operand flag,由第一个QB负责。
Query_term_set_op及成员
class Query_term_set_op : public Query_term {
Query_block *m_block{nullptr};//类似早先版本fake_select_lex,这个block上只有set结果表+orderby+limit
mem_root_deque<Query_term *> m_children;//union,itersect等的child QB或嵌套的set_op
bool m_is_materialized{true};//一般是true,除了顶层union all+no order,streaming输出,算一个特殊优化
}
简单Query_expression数据结构
/// Example:select * from t1 order by a limit 10;
/// Tree:
/// Query_expression---- slave----+ //slave,m_query_term指向同一个也是唯一child Queryblock
/// | m_query_term |
/// V |
/// Query_block <---------------+ holds inner SELECT and its ORDER BY/LIMIT
/// Example: (SELECT * FROM .. ORDER BY .. LIMIT n) ORDER BY .. LIMIT m
一元unary数据结构
/// Tree:
/// Query_expression
/// | m_query_term
/// Query_term_unary
/// +--------------------+
/// | m_block ------+----> Query_block which holds outer
/// | : | ORDER BY and LIMIT
/// | m_children[0] |
/// +--------|-----------+
/// V
/// Query_block holds inner SELECT and its ORDER BY/LIMIT
再来看一个任意嵌套的集合操作对应的数据结构
(
(/* select#1 */
SELECT `test`.`t1`.`a` AS `a`
FROM `test`.`t1`
UNION /* select#2 */
SELECT `test`.`t2`.`a` AS `a`
FROM `test`.`t2`
UNION ALL /* select#3 */
SELECT `test`.`t3`.`a` AS `a`
FROM `test`.`t3`
ORDER BY `a`
LIMIT 5
)
INTERSECT
(
(/* select#4 */
SELECT `test`.`t3`.`a` AS `a`
FROM `test`.`t3`
ORDER BY `test`.`t3`.`a`
LIMIT 4
)
EXCEPT /* select#5 */
SELECT `test`.`t4`.`a` AS `a`
FROM `test`.`t4`
)
ORDER BY `a`
LIMIT 4
)
ORDER BY -(`a`)
LIMIT 3;
->
m_query_term +------------------+ slave(s)
+--------------|-Query_expression |------------------+
| +------------------+ |
V post_ |
+-------------------+processing_ +----------------------+ |
| Query_term_unary |block() |Query_block | |
| |----------->|order by -(`a) limit 3| |
+-------------------+ +----------------------+ |
|m_children |
| +-----------------------+ +----------------------+ |
| |Query_term_intersect | |Query_block | |
+>|last distinct index: 1 |-->|order by `a` limit 4 | |
+-----------------------+ +----------------------+ |
|m_children |
| +-----------------------+ +----------------------+ |
| |Query_term_union | |Query_block | |
+->|last distinct index: 1 |-->|order by `a` limit 5 | |
| +-----------------------+ +----------------------+ |
| |m_children |
| | +------------+ SELECT * FROM t1 /
| +-->|Query_block | <---------------------------------+
| | +------------+ ----------------------------------+ next
| | \
| | +------------+ SELECT * FROM t2 /
| +-->|Query_block | <---------------------------------+
| | +------------+ ----------------------------------+ next
| | \
| | +------------+ SELECT * FROM t3 /
| +-->|Query_block | <---------------------------------+
| +------------+ ----------------------------------+ next
| \
| +-----------------------+ +------------+ |
| |Query_term_except |->|Query_block | |
+->|last distinct index: 1 | +------------+ |
+-----------------------+ |
|m_children |
| +----------------------+ |
| |Query_block | SELECT * FROM t3 /
+-->|order by `a` limit 4 | <------------------------+
| +----------------------+ -------------------------+ next
| \
| +------------+ SELECT * FROM t4 |
+-->|Query_block | <------------------------------------+
+------------+
highlevel实现思想
接下来我们思考一下集合操作该如何优化执行,按如下示例来进行说明
/* QB1 */ select * from t1 intersect distinct
/* QB2 */ select * from t2
我们先把QB1查询结果集写到一个临时表里面, 然后查询t2,每获取一行,去临时表里面查找一下,找到的话标记一下,标记全部完成后,最后把临时表里面有标记的行全部扫描出来。这是不是跟物化表(derived table)执行很像? 但我们的LEX只有QB1,QB2,不足以完成物化+scan临时表的操作,这就要借助于Query_term_set_op里面的m_block了,m_block类型是Query_block,完全是为了我们用来辅助集合运算的。它会创建出一张临时表,底层QB1,QB2把结果集往这里面写,m_block负责scan这张表,当然只取有标记的行。
所以对于这个二元集合运算,事实上有3个QB,都要分别进行prepare, optimize,execution。 m_block与QB1,QB2通过物化进行桥接,执行时
- QB1, QB2扫各自的表t1,t2, 投影列写入物化表
- 适度的集合运算逻辑
- m_block可以认为是上层的Queryblock了,扫描物化表即可。 事实上mysql宏观实现也确实大致如此,难点在于构建出m_block,并进行prepare。让我们进一步diving into
语法解析
会进行子节点合并和order by limit下推,将二元操作符变成多元操作符
(select * /*+q1*/ from t1 UNION select * /*+q2*/ from t1) UNION ALL ( select * /*+q3*/ from t1 UNION ALL select * /*+q4*/ from t1);
不合并是个二叉树,set_op是个二元操作符
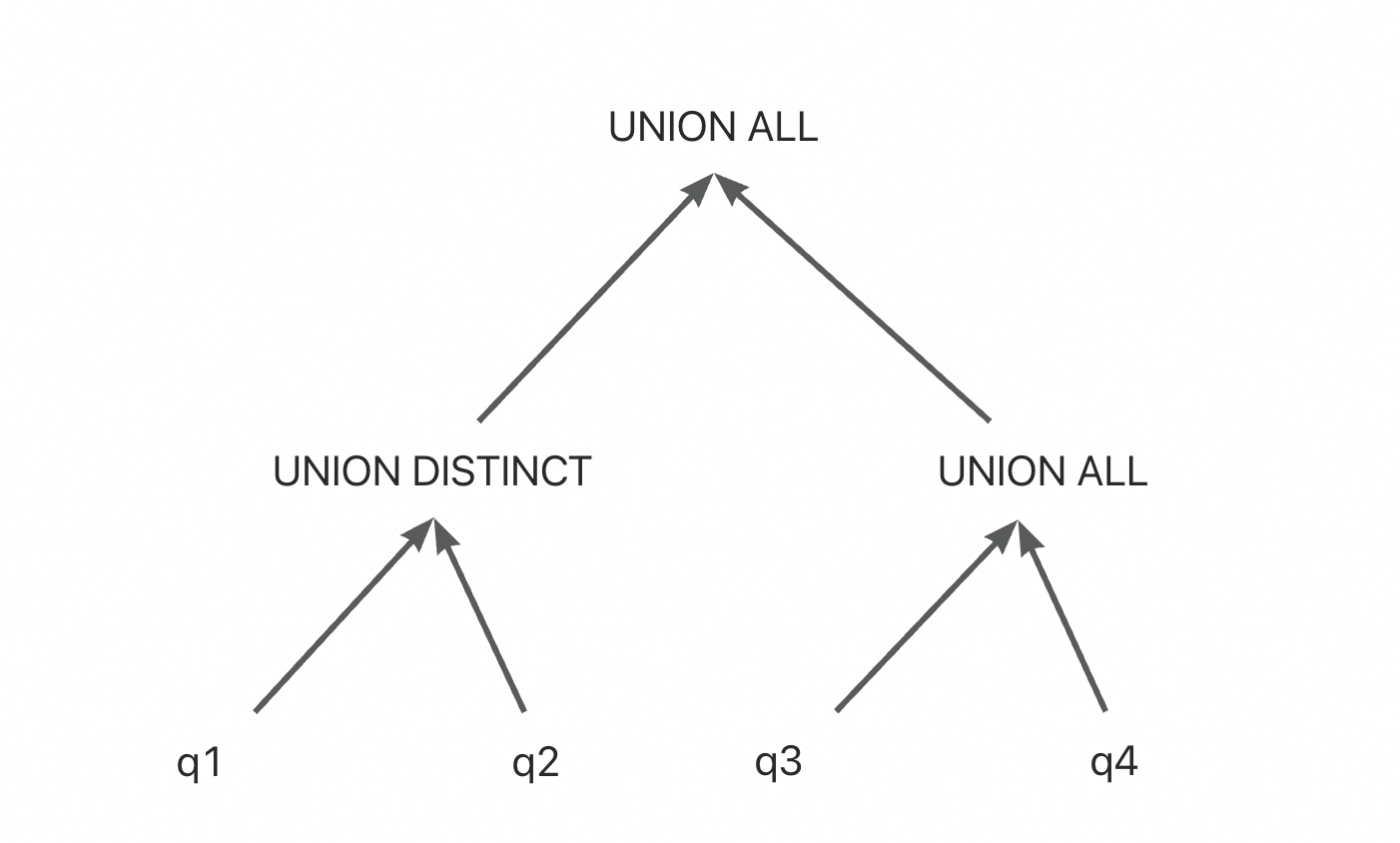
合并后顶层变成三元操作符
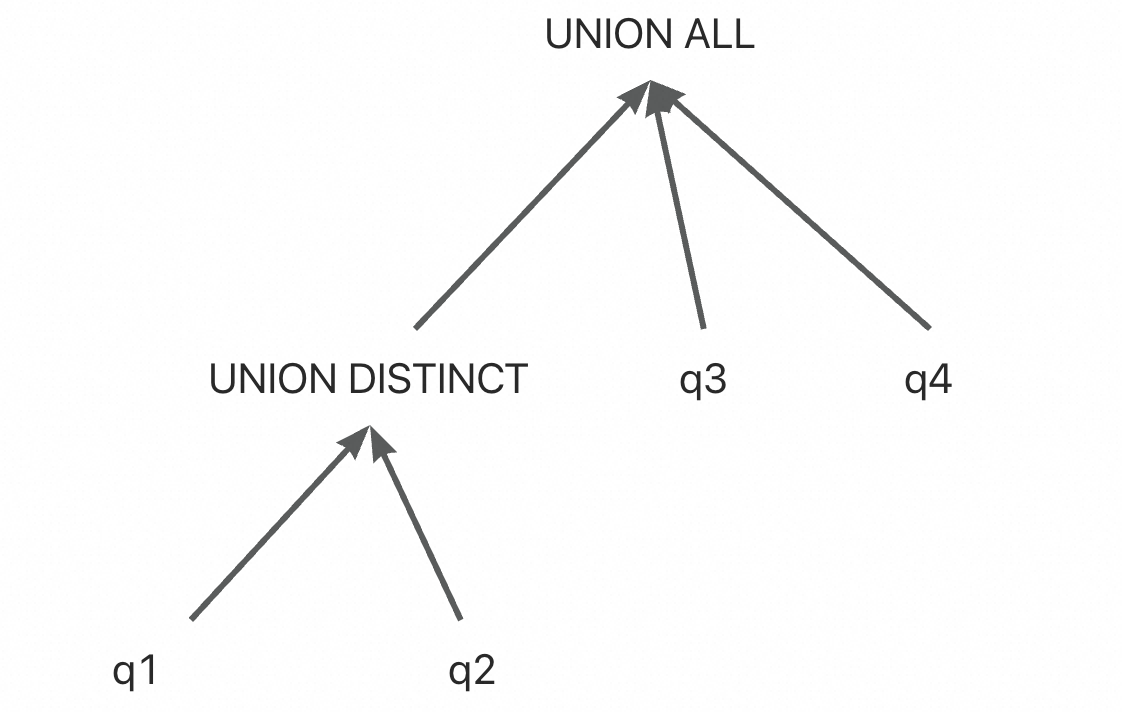
这块代码在PT_set_operation::merge_descendants, 合并的好处可以减少临时表/物化表使用,但基本不会修改这块代码,可以快速跳过。
prepare阶段
prepare整体流程都是自底向上执行过程,先做child query_block的prepare,然后调用prepare_query_term函数 prepare m_query_term->m_block,这决定了prepare_query_term 也会是自底向上执行。
- 先判断集合操作是否需要物化,设置m_is_materialized,这个参数决定集合操作最后选择物化执行还是streaming执行。
- 顶层union all,不含order by,不物化,使用stream方式,但也仍需要创建tmptable, 内层QB投影列拷贝到tmptable
- 其他都需要物化
- 第一个儿子为集合算子创建tmptable,当前层其他兄弟共享此tmptable, query_result。
- 将这个临时表加入到set_op的m_block的from 表上,做一遍prepare,会setup leaftables, setup_orderby, setup_limit等。
- 设置这个m_block的fields为tmptable的fields,最后这个Query_expression的输出就是这个m_block的fields 代码请参考Query_expression::prepare_query_term
优化阶段
optimize跟正常的query block没啥区别,但别忘了Query_term_set_op的m_block也需要optimize,然后生成TableScan accesspath。 然后Query_expression::create_access_paths会将这个set_op树变成accesspath树. make_set_op_access_path 是自底向上调用的。
children的accesspath构成materialize path的subquery path, Query_term_set_op::m_block优化结果TableScan path就是materialize path的 table path.
为每个set_op都会创建一个materialize path。代码请参考 make_set_op_access_path
执行阶段
为了支持集合操作的执行,社区在materialize_iterator::QueryBlock、TABLE以及Temp_table_param中增加了几个成员,变化如下:
materialize_iterator::QueryBlock:
struct QueryBlock {
/// The number of operands (i.e. blocks) involved in the set operation:
/// used for INTERSECT to determine if a value is present in all operands
ulonglong m_total_operands{0};
/// The current operand (i.e. block) number, starting at zero. We use this
/// for INTERSECT and EXCEPT materialization operand.
ulonglong m_operand_idx{0};
/// Used for EXCEPT computation: the index of the first operand involved in
/// a N-ary except operation which has DISTINCT. This is significant for
/// calculating whether to set the counter to zero or just decrement it
/// when we see a right side operand.
uint m_first_distinct{0};
}
TABLE:
struct TABLE {
// ----------------------------------------------------------------------
// The next few members are used if this (temporary) file is used solely for
// the materialization/computation of an INTERSECT or EXCEPT set operation
// (in addition to hash_field above used to detect duplicate rows). For
// INTERSECT and EXCEPT, we always use the hash field and compute the shape
// of the result set using m_set_counter. The latter is a hidden field
// located between the hash field and the row proper, only present for
// INTERSECT or EXCEPT materialized in a temporary result table. The
// materialized table has no duplicate rows, relying instead of the embedded
// counter to produce the correct number of duplicates with ALL semantics. If
// we have distinct semantics, we squash duplicates. This all happens in the
// reading step of the tmp table (TableScanIterator::Read),
// cf. m_last_operation_is_distinct. For explanation if the logic of the set
// counter, see MaterializeIterator<Profiler>::MaterializeQueryBlock.
//
/// A priori unlimited. We pass this on to TableScanIterator at construction
/// time, q.v., to limit the number of rows out of an EXCEPT or INTERSECT.
/// For these set operations, we do not know enough to enforce the limit at
/// materialize time (as for UNION): only when reading the rows with
/// TableScanIterator do we check the counters.
/// @todo: Ideally, this limit should be communicated to TableScanIterator in
/// some other way.
ha_rows m_limit_rows{HA_POS_ERROR};
private:
/// The set counter. It points to the field in the materialized table
/// holding the counter used to compute INTERSECT and EXCEPT, in record[0].
/// For EXCEPT [DISTINCT | ALL] and INTERSECT DISTINCT this is a simple 64
/// bits counter. For INTERSECT ALL, it is subdivided into two sub counters
/// cf. class HalfCounter, cf. MaterializeQueryBlock. See set_counter().
Field_longlong *m_set_counter{nullptr};
/// True if we have EXCEPT, else we have INTERSECT. See is_except() and
/// is_intersect().
bool m_except{false};
/// If m_set_counter is set: true if last block has DISTINCT semantics,
/// either because it is marked as such, or because we have computed this
/// to give an equivalent answer. If false, we have ALL semantics.
/// It will be true if any DISTINCT is given in the merged N-ary set
/// operation. See is_distinct().
bool m_last_operation_is_distinct{false};
}
Temp_table_param:
class Temp_table_param {
/// For INTERSECT and EXCEPT computation
enum {
TTP_UNION_OR_TABLE,
TTP_EXCEPT,
TTP_INTERSECT
} m_operation{TTP_UNION_OR_TABLE};
/// The tempoary table rows need a counter to keep track of its
/// duplicates: needed for EXCEPT and INTERSECT computation.
bool needs_set_counter() { return m_operation != TTP_UNION_OR_TABLE; }
/// For INTERSECT and EXCEPT computation.
/// Cf. TABLE::m_last_operation_is_distinct.
bool m_last_operation_is_distinct{false};
}
UNION
UNION有两类,UNION DISTINCT和UNION ALL;对UNION ALL的实现比较简单,只需要将各个查询块的数据依次写入临时表或者对外输出.
对UNION DISTINCT的实现类似,但是在写入临时表之前会多一个去重的操作。而对于UNION DISTINCT混合UNION ALL的情况,目前的实现方案是在query_block.disable_deduplication_by_hash_field上记录当前查询块是否需要去重.
比如q1 UNION DISTINCT q2 UNION ALL q3,在处理q1以及q2时是需要去重的,因此在物化这两个查询块的数据时每一行数据都会调用check_unique_constraint函数来检查重复,而在处理q3查询块时不需要该操作。
EXCEPT
对于每一个EXCEPT操作,其结果都会输出到一个临时表中,并且临时表增加了一个Field_longlong类型的隐藏列
物化
第一个查询块
如果当前行是第一次出现,那么就在
读取
如果
可以看到EXCEPT实际上就是利用了
INTERSECT
和EXCEPT类似,其结果都会输出到一个临时表中,并且临时表增加了一个Field_longlong类型的隐藏列
INTERSECT DISTINCT
物化
第一个查询块
如果当前行是第一次出现,那么就在
读取
如果
可以看到INTERSECT DISTINCT是利用位置信息在
INTERSECT ALL
对于INTERSECT ALL,
物化
第一个查询块 如果当前行是第一次出现,那么就在c0记录1 否则每多出现一次,那么c0加1 后续查询块(因为INTERSECT ALL目前只支持二元操作,所以只有一个查询块) 如果当前行在临时表中没有出现过,那么跳过 如果c1小于等于c0-1,那么c1加1
读取
输出min(c0,c1)次
可以看到INTERSECT ALL是利用了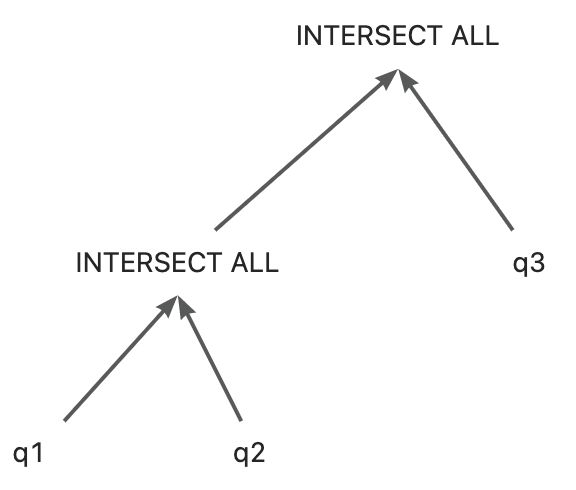
这样会增加一个临时表,代价会更大。
读取物化表
只读取想要的行
int TableScanIterator::Read() {
int tmp;
if (table()->is_union_or_table()) {
...//基表或union op_set
} else {
while (true) {
if (m_remaining_dups == 0) { // always initially
while ((tmp = table()->file->ha_rnd_next(m_record))) {
}
// Filter out rows not qualifying for INTERSECT, EXCEPT by reading
// the counter.
const ulonglong cnt =
static_cast<ulonglong>(table()->set_counter()->val_int());
if (table()->is_except()) {
if (table()->is_distinct()) {
// EXCEPT DISTINCT: any counter value larger than one yields
// exactly one row
if (cnt >= 1) break;
} else {
// EXCEPT ALL: we use m_remaining_dups to yield as many rows
// as found in the counter.
m_remaining_dups = cnt;
}
} else {
// INTERSECT
if (table()->is_distinct()) {
if (cnt == 0) break;
} else {
HalfCounter c(cnt);
// Use min(left side counter, right side counter)
m_remaining_dups = std::min(c[0], c[1]);
}
}
} else {
--m_remaining_dups; // return the same row once more.
break;
}
// Skipping this row
}
本文重点介绍实现核心思想,并不侧重于代码展现,但重点标注了对应的代码,感兴趣的话可以自行学习,理解作者思路后,学习事半功倍。