PolarDB PostgreSQL 基于代价的查询变换框架 (CBQT)
Author: 费长红
前言
查询变换是指基于等价规则,将一个查询语句改写成语义上等价的另一种形式。例如社区 PostgreSQL 中常用的“子查询上拉”、“外连接消除”、“表达式预处理”、“消除无用连接”、“谓词下推”等都是基于规则的查询变换,并且经过这些查询变换后的计划一定是更优的,因此 PostgreSQL 一定会尝试应用这些变换。
但一些查询变换,如“子连接下推”、“OR 转 UNION ALL”等,应用后不一定使计划更优。为此,PolarDB PostgreSQL 版实现了基于代价的查询变换框架,能够基于执行代价选择是否做某种变换。
对于复杂查询,CBQT 会收集该查询都可以在哪些 query block 做哪些基于代价的查询变换,这些变换会汇总成一个状态空间。CBQT 会按照指定的策略搜索状态空间,从中选择代价最低的状态。
如下图所示,对于输入的 SQL 语句,CBQT 在 query block1 和 query block2 中收集到基于代价的查询变换 A 和 B,这两个变换组成的状态空间有:None(均不作变换)、[1,A](query block1 做变换 A)、[1,B](query block1 做变换 B)、[2,A](query block2 做变换 A)。CBQT 会依次尝试应用状态空间的各种变换,在 linear 搜索策略中,状态[1,B]能使计划更优,因此在生成 Plan4 时,也会保持[1,B]的应用。
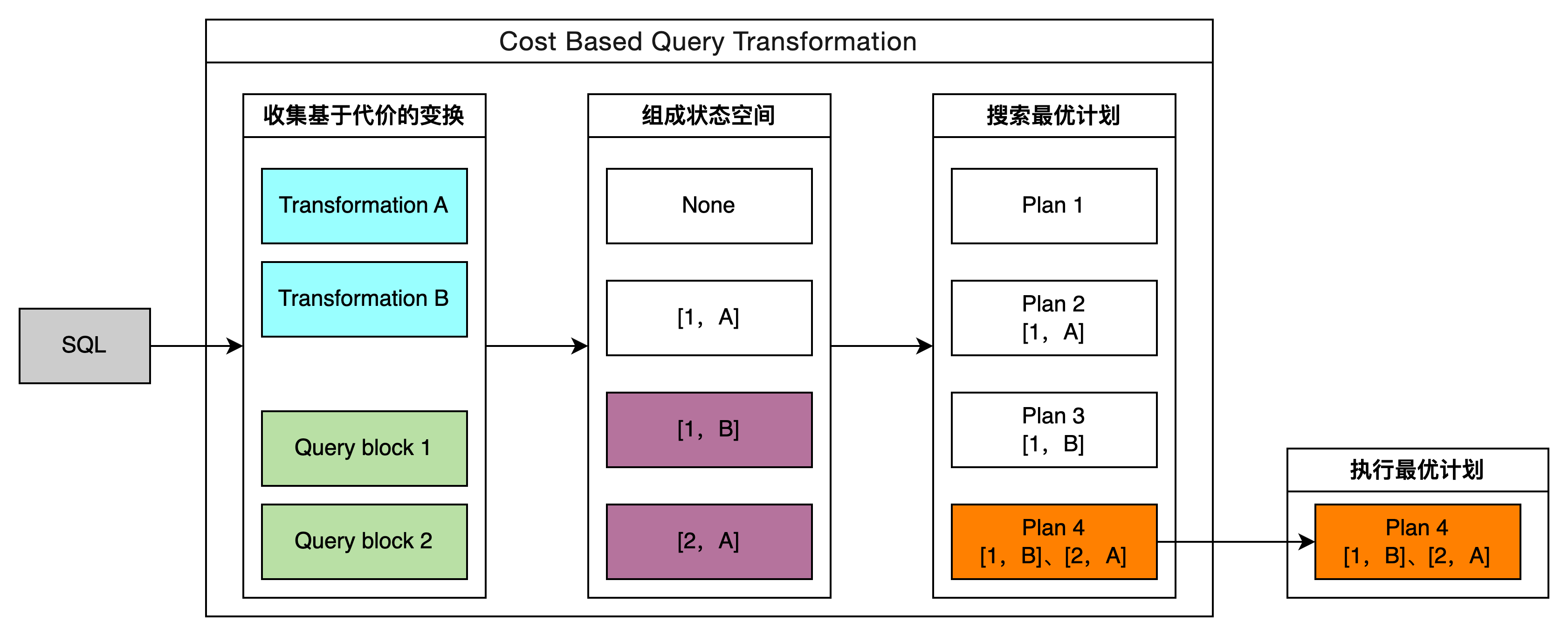
要实现 CBQT 功能有以下几个关键点:
- 状态空间的维护
- CBQT 最好能精准控制每个 query block 中的每个谓词是否应用某个基于代价的查询变换,因此,状态空间需要有“query block”、“规格”、“谓词”3个维度。以“or转union all”功能为例,
select * from t where (a = 1 or b = 1) and (c = 1 or d = 1);中含有2个or子句,每个or子句只能单独尝试转为union all。因此在当前query block,“or转union all”需要2个CBQT状态。 - 需要考虑如何标识一个query block。
- 需要考虑planner会对查询树进行修改,对应的状态空间如何维护。
- CBQT re-plan的维度选择
按照re-plan范围的不同,可以分为以“query block为粒度”和以“SQL为粒度”两种维度,需要根据 plan的开销、选出更优计划的概率、内存管理等方面综合考虑。
- 互斥和依赖的处理
规则间的相互影响分为Interleaving和Juxtaposition:
- Interleaving(依赖):例如S1+S2+S3才能最优的计划,如果S2没有被应用,也就没有S3,但S1+S2比单独应用S1的代价更大,在linear模式下,S2则不会被应用,可能会错过最优的计划。 *Juxtaposition(互斥):例如S1和S2不能同时应用,S1应用后,S2状态就会消失,反之亦然。
- 对性能的影响
CBQT 需要多次re-plan,re-plan的次数越多,更容易找到更优计划,但plan的开销也会越大,这对简单SQL的性能影响是不可忽视的。因此,CBQT需要避免对非优化场景带来性能回退。经过sysbench和pgbench测试,在各种负载下,PolarDB PostgreSQL实现的CBQT对性能的影响都在1%以内。
使用方法
PolarDB PostgreSQL 版提供了以下参数用于控制 CBQT 的行为:
| 参数名 | 参数范围 | 默认值 | 描述 |
|---|---|---|---|
| polar_enable_cbqt | on/off | off | 控制是否开启 CBQT 功能。 |
| polar_cbqt_cost_threshold | 0~DBL_MAX | 50000 | 控制开启 CBQT 代价的阈值,只有原始计划的代价超过阈值才会启用 CBQT。 |
| polar_cbqt_strategy | twophase/linear | linear | 控制 CBQT 状态空间的搜索策略: - twophase:两遍搜索。在该策略下,只会对比所有状态都应用或者都不应用的代价,选择更优的计划。 - linear:线性搜索。在该策略下,会依次对比每个状态应用前后的代价,选择更优的计划。 |
| polar_cbqt_iteration_limit | 1-INT_MAX | 10 | 控制 CBQT 迭代次数。迭代次数越多选择出最优计划的可能性越大,但优化时间会更长。反之选出最优计划的可能性越小,优化时间更短。 |
目前已经支持基于代价的查询改写功能如下:
| 功能开关 | 描述 |
|---|---|
| polar_cbqt_pushdown_sublink | “子连接下推”:尝试将子连接下推到子查询中,利用子查询中的索引生成参数化路径,提升查询的效率。 |
| polar_cbqt_convert_or_to_union_all_mode | “OR 子句转 UNION ALL”:尝试将合适的 OR 子句转换成 UNION ALL 的形式,提升查询的效率。 |
使用示例
接下来以“子连接下推”功能为例,介绍 CBQT 功能以及各个参数的使用。
- 创建测试表并准备测试数据
create table t_small(a int);
create table t_big(a int, b int, c int);
create index on t_big(a);
insert into t_big select i, i, i from generate_series(1, 1000000)i;
insert into t_small values(1), (1000000);
analyze t_small, t_big;
- 关闭 CBQT 功能
在关闭 CBQT 开关,开启“子连接下推”开关时,“子连接下推”功能并不会开启,t_big表仍然需要全表扫描,执行效率很低。
-- 关闭CBQT功能
set polar_enable_cbqt to off;
-- 开启“子连接下推”功能
set polar_cbqt_pushdown_sublink to on;
test=# explain analyze select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_small);
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------
Merge Semi Join (cost=1.46..59511.17 rows=10000 width=12) (actual time=0.052..1274.435 rows=2 loops=1)
Merge Cond: (t_big.a = t_small.a)
-> GroupAggregate (cost=0.42..46910.13 rows=1000000 width=12) (actual time=0.033..1151.005 rows=1000000 loops=1)
Group Key: t_big.a
-> Index Scan using t_big_a_idx on t_big (cost=0.42..31910.13 rows=1000000 width=8) (actual time=0.022..433.821 rows=1000000 loops=1)
-> Sort (cost=1.03..1.03 rows=2 width=4) (actual time=0.015..0.016 rows=2 loops=1)
Sort Key: t_small.a
Sort Method: quicksort Memory: 25kB
-> Seq Scan on t_small (cost=0.00..1.02 rows=2 width=4) (actual time=0.005..0.006 rows=2 loops=1)
Planning Time: 0.904 ms
Execution Time: 1274.539 ms
(11 rows)
- 开启 CBQT 功能
在打开 CBQT 开关,打开“子连接下推”开关时,“子连接下推”功能正确开启。a in (select a from t_small)子句被下推到了子查询中,可以利用连接条件为t_big表生成参数化路径,扫描的数据大大减少,执行时间明显缩短。
-- 开启CBQT功能
set polar_enable_cbqt to on;
-- 开启“子连接下推”功能
set polar_cbqt_pushdown_sublink to on;
test=# explain analyze select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_small);
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
GroupAggregate (cost=17.96..17.99 rows=2 width=12) (actual time=0.060..0.063 rows=2 loops=1)
Group Key: t_big.a
-> Sort (cost=17.96..17.96 rows=2 width=8) (actual time=0.052..0.053 rows=2 loops=1)
Sort Key: t_big.a
Sort Method: quicksort Memory: 25kB
-> Nested Loop (cost=1.46..17.95 rows=2 width=8) (actual time=0.032..0.046 rows=2 loops=1)
-> Unique (cost=1.03..1.04 rows=2 width=4) (actual time=0.014..0.018 rows=2 loops=1)
-> Sort (cost=1.03..1.03 rows=2 width=4) (actual time=0.013..0.014 rows=2 loops=1)
Sort Key: t_small.a
Sort Method: quicksort Memory: 25kB
-> Seq Scan on t_small (cost=0.00..1.02 rows=2 width=4) (actual time=0.006..0.007 rows=2 loops=1)
-> Index Scan using t_big_a_idx on t_big (cost=0.42..8.44 rows=1 width=8) (actual time=0.009..0.010 rows=1 loops=2)
Index Cond: (a = t_small.a)
Planning Time: 0.644 ms
Execution Time: 0.150 ms
(15 rows)
- 不满足 CBQT 的代价阈值
原始计划的代价(59511.17)小于polar_cbqt_cost_threshold参数设置的阈值(500000),不会启用 CBQT 功能,仍然会选择原始的计划。
-- 开启CBQT功能
set polar_enable_cbqt to on;
-- 设置CBQT的代价阈值为 500000
set polar_cbqt_cost_threshold to 500000;
-- 开启“子连接下推”功能
set polar_cbqt_pushdown_sublink to on;
test=# explain analyze select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_small);
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------
Merge Semi Join (cost=1.46..59511.17 rows=10000 width=12) (actual time=0.059..1253.452 rows=2 loops=1)
Merge Cond: (t_big.a = t_small.a)
-> GroupAggregate (cost=0.42..46910.13 rows=1000000 width=12) (actual time=0.041..1127.255 rows=1000000 loops=1)
Group Key: t_big.a
-> Index Scan using t_big_a_idx on t_big (cost=0.42..31910.13 rows=1000000 width=8) (actual time=0.029..414.488 rows=1000000 loops=1)
-> Sort (cost=1.03..1.03 rows=2 width=4) (actual time=0.014..0.015 rows=2 loops=1)
Sort Key: t_small.a
Sort Method: quicksort Memory: 25kB
-> Seq Scan on t_small (cost=0.00..1.02 rows=2 width=4) (actual time=0.005..0.006 rows=2 loops=1)
Planning Time: 0.280 ms
Execution Time: 1253.558 ms
(11 rows)
- 不同 CBQT 状态空间的搜索策略
以下示例中有两个能够下推的“子连接”,但只有第二个“子连接”下推才是更优的,在 linear 搜索策略下,CBQT 选择了最优的计划。
-- 开启CBQT功能
set polar_enable_cbqt to on;
-- 设置搜索策略为linear(默认值)
set polar_cbqt_strategy to linear;
-- 开启“子连接下推”功能
set polar_cbqt_pushdown_sublink to on;
test=# explain select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_big) union all select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_small);
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Append (cost=0.85..105692.60 rows=500002 width=12)
-> Merge Semi Join (cost=0.85..98174.56 rows=500000 width=12)
Merge Cond: (t_big_1.a = t_big.a)
-> GroupAggregate (cost=0.42..46910.13 rows=1000000 width=12)
Group Key: t_big_1.a
-> Index Scan using t_big_a_idx on t_big t_big_1 (cost=0.42..31910.13 rows=1000000 width=8)
-> Index Only Scan using t_big_a_idx on t_big (cost=0.42..26264.42 rows=1000000 width=4)
-> GroupAggregate (cost=17.96..17.99 rows=2 width=12)
Group Key: t_big_2.a
-> Sort (cost=17.96..17.96 rows=2 width=8)
Sort Key: t_big_2.a
-> Nested Loop (cost=1.46..17.95 rows=2 width=8)
-> Unique (cost=1.03..1.04 rows=2 width=4)
-> Sort (cost=1.03..1.03 rows=2 width=4)
Sort Key: t_small.a
-> Seq Scan on t_small (cost=0.00..1.02 rows=2 width=4)
-> Index Scan using t_big_a_idx on t_big t_big_2 (cost=0.42..8.44 rows=1 width=8)
Index Cond: (a = t_small.a)
(18 rows)
以下示例中有两个能够下推的“子连接”,但只有第二个“子连接”下推才是更优的,在 twophase 搜索策略下,两个“子连接”都选择了下推。
-- 开启CBQT功能
set polar_enable_cbqt to on;
-- 设置搜索策略为twophase
set polar_cbqt_strategy to twophase;
-- 开启“子连接下推”功能
set polar_cbqt_pushdown_sublink to on;
test=# explain select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_big) union all select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_small);
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Append (cost=0.85..113192.60 rows=1000002 width=12)
-> GroupAggregate (cost=0.85..88174.56 rows=1000000 width=12)
Group Key: t_big.a
-> Merge Semi Join (cost=0.85..73174.56 rows=1000000 width=8)
Merge Cond: (t_big.a = t_big_1.a)
-> Index Scan using t_big_a_idx on t_big (cost=0.42..31910.13 rows=1000000 width=8)
-> Index Only Scan using t_big_a_idx on t_big t_big_1 (cost=0.42..26264.42 rows=1000000 width=4)
-> GroupAggregate (cost=17.96..17.99 rows=2 width=12)
Group Key: t_big_2.a
-> Sort (cost=17.96..17.96 rows=2 width=8)
Sort Key: t_big_2.a
-> Nested Loop (cost=1.46..17.95 rows=2 width=8)
-> Unique (cost=1.03..1.04 rows=2 width=4)
-> Sort (cost=1.03..1.03 rows=2 width=4)
Sort Key: t_small.a
-> Seq Scan on t_small (cost=0.00..1.02 rows=2 width=4)
-> Index Scan using t_big_a_idx on t_big t_big_2 (cost=0.42..8.44 rows=1 width=8)
Index Cond: (a = t_small.a)
(18 rows)
- 限制 CBQT 迭代次数
通过polar_cbqt_iteration_limit参数将 CBQT 的迭代次数限制为 1。在以下示例中,即使第二个“子连接”下推会使计划更优,但由于迭代次数的限制,并不会进行尝试。
-- 开启CBQT功能
set polar_enable_cbqt to on;
-- 设置搜索策略为linear
set polar_cbqt_strategy to linear;
-- 设置迭代次数为1次
set polar_cbqt_iteration_limit to 1;
-- 开启“子连接下推”功能
set polar_cbqt_pushdown_sublink to on;
test=# explain select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_big) union all select * from (select a, sum(b) b from t_big group by a)v where a in (select a from t_small);
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Append (cost=0.85..113192.60 rows=1000002 width=12)
-> GroupAggregate (cost=0.85..88174.56 rows=1000000 width=12)
Group Key: t_big.a
-> Merge Semi Join (cost=0.85..73174.56 rows=1000000 width=8)
Merge Cond: (t_big.a = t_big_1.a)
-> Index Scan using t_big_a_idx on t_big (cost=0.42..31910.13 rows=1000000 width=8)
-> Index Only Scan using t_big_a_idx on t_big t_big_1 (cost=0.42..26264.42 rows=1000000 width=4)
-> GroupAggregate (cost=17.96..17.99 rows=2 width=12)
Group Key: t_big_2.a
-> Sort (cost=17.96..17.96 rows=2 width=8)
Sort Key: t_big_2.a
-> Nested Loop (cost=1.46..17.95 rows=2 width=8)
-> Unique (cost=1.03..1.04 rows=2 width=4)
-> Sort (cost=1.03..1.03 rows=2 width=4)
Sort Key: t_small.a
-> Seq Scan on t_small (cost=0.00..1.02 rows=2 width=4)
-> Index Scan using t_big_a_idx on t_big t_big_2 (cost=0.42..8.44 rows=1 width=8)
Index Cond: (a = t_small.a)
(18 rows)
相关资料
- PolarDB PostgreSQL 基于代价的查询变换:https://help.aliyun.com/zh/polardb/polardb-for-postgresql/cbqt
- Cost-based query transformation in Oracle:https://dl.acm.org/doi/10.5555/1182635.1164215