再演进,更全面、更极致的 PolarIndex 2.0
Author: 蛰语
索引模块是数据库管理系统的核心组件,其设计直接决定了数据库数据操作的性能与效率。如何构建高效高并发的索引结构,始终是数据库领域的研究重点。作为一款先进的云原生数据库,阿里云PolarDB也不断的在索引高并发优化技术上深耕。基于Latching coupling的设计理念,PolarDB实现了PolarIndex 1.0版本:将 SMO 操作分成两个阶段并引入Latching-coupling,消除InnoDB btree 索引结构变更(SMO)过程中的全局索引锁(Index Latch),并保证每次结构修改都只需在btree 的一层加锁, 从而减少了latch 粒度并,使得索引结构变更可以高度并发。PolarIndex 1.0的相关介绍可以参考PolarDB这一篇月报文章。这一技术极大的提升InnoDB Btree的写入能力,以TPCC单表测试场景为例,开启PolarIndex后峰值性能能有近3倍的提升。
虽然PolarIndex 1.0版本消除了InnoDB btree SMO的全局Index latch使得SMO操作可以并发,但是仍有许多优化尚未触及的地方:1)PolarDB 在btree cursor下降过程使用 latch coupling 最多同时持有两层次 page latch,仍存在(parent)page锁的瓶颈;2)InnoDB BLOB、TEXT等可变长度列格式,在数据长度过长时会将过长的变长字段单独存放在溢出页(off-page)中,其操作时走的是低效率悲观逻辑;3)索引页本身的操作效率、存储效率仍值得提升等。随着持续的深度优化,现在PolarIndex演化到了功能更全面、性能更极致的2.0版本,进一步提升PolarDB用户在不同业务场景下的数据操作效率,本文也将向大家深入介绍PolarIndex 2.0的主要新特性。
背景
B-tree 并发访问控制:B-tree 并发访问控制主要在于 page 和 btree 结构的并发读写控制这两方面,但是由于 btree 结构变化时往往还涉及到实际文件空间的分配,因此还有一层潜在的tablespace并发读写控制。InnoDB 允许多个线程访问共享的buffer pool page,因此在 page 粒度上需要进行并发访问控制,即一个线程读写某个page时,其它线程不能修改这个page的内容,否则会导致page内部结构变化;其次,btree SMO操作涉及多个page之间关联的改动,单独使用page级别的读写锁,不能避免树结构变换导致的访问问题,线程可能看到不一致的树结构。
对于page的并发控制,InnoDB利用rw latch来实现page的并发访问控制:每个 page 关联一个读写锁,读 page 需要获取 S latch,修改 page 获取 X latch;整个btree关联一个读写锁,锁住整个 btree 之后保证没有 page 的并发访问,就不需要再获取 page rw latch。
对于btree SMO的并发读写控制,最简单的做法是 btree 级别的大锁,所有读取操作加 index S latch,所有修改操作加 index X latch。这个方法的问题是粒度太大了,即便在不同线程访问的数据完全没有冲突的情况下,整个 btree 读写操作和写写操作也只能低效率地串行访问。在InnoDB原生逻辑中,存在潜在空间分配逻辑的操作(如blob写入、悲观更新等)时,都会走所谓悲观逻辑。
对于tablespace的并发修改,同样也是需要通过文件锁来保护文件的并发操作,InnoDB会在真实分配文件空间时获取tablespace锁和相应文件元数据页锁,避免并发分配冲突。
No latch coupling
InnoDB 中的 Btree 的并发控制机制经过了多次演进: 5.6 版本使用先乐观再悲观的方法,在写不密集的场景下(不频繁发生分裂/合并)缓解了修改操作 latch entire btree 的问题。
5.7 及后续版本使用 latch coupling 的方法来解决 btree 结构的并发访问问题,下降线程先获取到 child page 的锁,再放开 parent page 的锁,从而避免了子指针失效。为了解决 SMO 自下而上修改节点与下降线程出现的死锁问题,SMO 线程下降过程中提前持有可能影响到的 subtree 的根节点,以及之后到 leaf page 路径上的节点。
InnoDB 目前使用的 latch coupling 和 SMO latch subtree 机制下,无法精准判断影响的子树范围,通常会锁住一个比需要更大的子树,甚至锁住整个 btree。并且出于工程实现的考虑,使用 index latch 阻止 SMO 线程并发。这就导致了在相对耗时的 SMO 过程中,其它线程非常容易被阻塞,index 在频繁并发写入的场景成为明显的性能瓶颈。更坏的情况是,大表的数据页无法被 buffer pool 容纳,SMO 过程中需要多个 read IO 获取相关节点,这进一步增加了 SMO 的耗时,在 IO 延迟大的云存储环境下,这个问题更是雪上加霜。一个长久以来的说法是 InnoDB 大表性能不好,表越大越慢,需要进行分区等操作。由于 index latch 的存在,单表上无法获得线性扩展能力。
PolarIndex 1.0 通过阶段化 btree SMO 结构变更并在所有操作都实现了 latch coupling,去除 index latch,允许 SMO 并发访问 B-tree,并减小了锁范围,线程间冲突只在 page 级别,从而大大降低线程间冲突。
No latch coupling 实现 在现在的PolarIndex 2.0 中,我们基于 L&Y’s blink tree 描述的算法做进一步改造适配,实现了高并发访问的no latch coupling btree。简单来说,L&Y’s blink tree 是通过右向数据指针和稳定化的右侧数据范围,实现在无锁状态下自顶向下的访问策略和SMO自底向上的加锁策略。相比于 L&Y 算法,我们在实现中主要做了如下几点改动:
Page读写锁: L&Y 的算法不需要读锁,它假设内存中的 page 是不共享的,这意味着每个进程或线程都有自己独立的 page 副本,因此在读取数据时不需要担心其他进程会修改这些 page。而 polardb 允许不同线程共享内存中的 buffer pool,这种共享机制可以提高资源利用率,但也带来了并发访问的问题,为了确保读取的 page 不会被其他线程修改同样采用InnoDB原有的page级别的读锁,这降低了并发性但保证了正确的访问行为。
下降遍历: 与传统的 btree 相比,L&Y 算法给每个 page 上增加了一个指向其右兄弟页面的连接,以及一个 high key 表示该页面允许存储的 key 的上界。这两个改进使得算法能够检测到并发的页面分裂,从而允许在 search 下降过程中不需要 latch coupling,而是通过右移找到正确的目标 page。
为了避免添加 high key 影响原有的 page 数据格式,我们采用一种先乐观后悲观的 search 方法(假设 search_mode = LE):
- 乐观:search key >= 当前节点 last record,说明可能需要右移到 next page,此时先采取乐观方式,先释放当前节点,再获取 right page,判断其 first record 和 search key 的大小关系,如果 search key >= first record 说明右移是正确的,否则右移失败进入悲观流程;
- 悲观:search key >= 当前节点 last record,持有当前节点,同时获取 right page,判断 search key 和 first record 大小,根据比较结果确定是否右移,并释放一个节点; 我们认为乐观操作成功的概率为(k-1/k),k 是节点分裂前的 record 数量,一般来说成功概率较高。采用这种乐观方式和 high key 对比性能影响在 3% 以内。
范围遍历: InnoDB btree 每层 page 通过前后指针形成了一个双向链表,可以高效地支持正向和反向的 range scan,而 L&Y 描述的 blink tree 只有一个向右指针。这就需要在 L&Y 分裂算法中增加额外的一个步骤:持有当前分裂节点的 X lock,需要再获取 right page X lock 来修改其左指针,这个从左向右的加锁是安全的,我们规定不允许从右向左加锁。
- forward scan:向右扫描时,不需要使用 latch coupling 的方式获得 right page,因为即使当前 page 发生了分裂,数据记录的移动不会越过原本 page 的上界,而这些数据已经被扫描过了,这样不会漏掉没读过的数据,也不会重复扫描数据。 2)backward scan:向左反向扫描会比较复杂,获得当前 page 的 left-link 后,释放当前 page,再获取 left page,这期间 left page 可能已经发生过分裂,因此还需要进行右移来处理这种情况。
SMO: 在 SMO 执行的自下而上的方向,L&Y 算法需要使用 latch coupling ,先修改父节点再释放子节点,避免了子节点出现多个 link page。并且 L&Y 在 parent 层定位 child page downlink 的过程,需要用 latch coupling 右移。可以看到 L&Y 在做 SMO 时最多同时持有三个节点的 latch。在我们的右移实现中,parent 层查找 downlink 过程不再需要 latch coupling。另外,我们去掉了 SMO 自下而上的 latch coupling,通过给 child page 增加 SMO 标记的方式,使其它线程可以感知到 child page 处于 SMO 中间状态,等待 SMO 结束再 try again,避免继续分裂当前的 child page。
收益:
上述几种 btree 访问操作,最多只持有一个 page latch,最小化加锁粒度,降低并发操作的锁冲突,从而获得非常显著的并发吞吐性能提升。在sysbench oltp_insert@auto_inc=ON的测试场景,峰值性能达到 InnoDB 的 3 倍多(相对PolarIndex 1.0 版本再进一步提升 80%),并且随着并发线程数增加,具有很好的线性扩展能力。
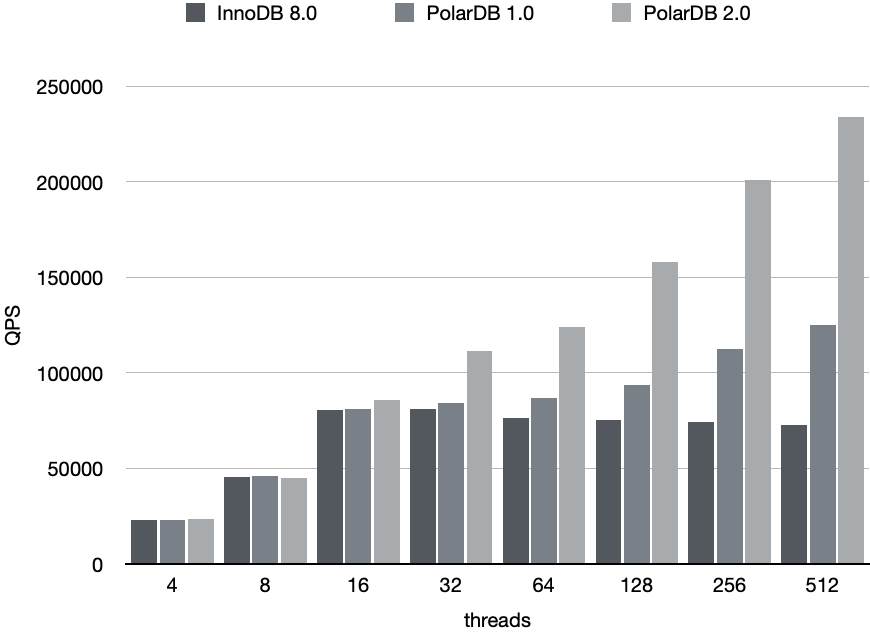
Lob Latch Optimization
在 Innodb 中,当字段长度较小时,blob 数据可以像正常字段一样直接存入主键索引的记录内。在处理如VARCHAR、VARBINARY、BLOB、TEXT等可变长度列时,若数据的长度过长,InnoDB不会直接将字段完整容纳在记录所在的B-Tree页上,而是会将过长的变长字段单独存放在溢出页(off-page)中。目前的机制保证超过约8K的记录才会移至溢出页,由于每次分配LOB页空间会分配一个空白页,因此LOB字段可以存在空间浪费(写放大)的情况。其次,前面提到过,由于溢出页会存在新页面的分配逻辑,因此当更新或写入的目标(可能)存在off-page操作时,Innodb就会默认走悲观更新逻辑,会持有 index/root 的sx-latch,目标节点、相邻节点的x-latch,单表并发情况下就会产生性能瓶颈。其次,由于LOB字段本身较大,redo的产生量较大,在加锁过程中就行redo copy,redo刷写性能不高的情况下持续写入大字段可导致redo buffer打满而进一步影响写入性能。
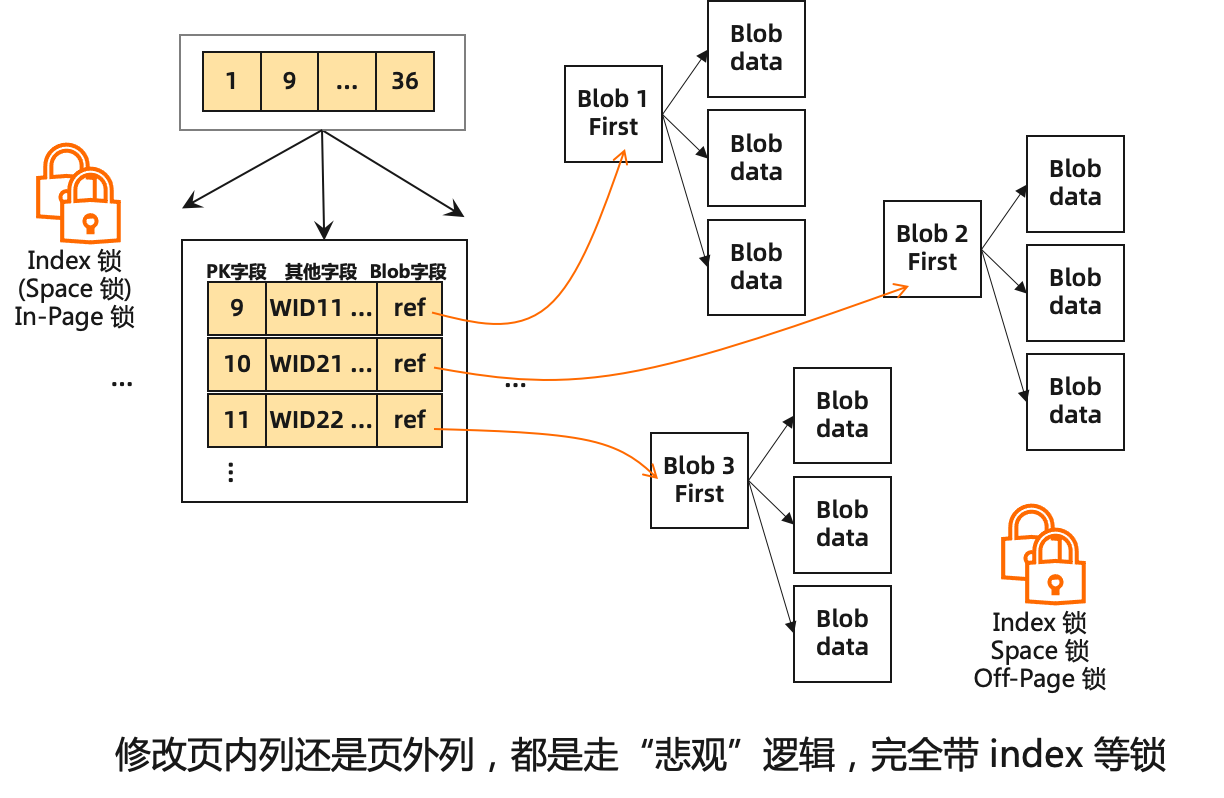
In-index part optimization
如果开启in-index part的lob优化,在更新含lob记录的in-index part时,不再会直接退出走悲观更新,会保留乐观状态(不拿锁)。在乐观状态下直接进行判断update后的记录是否需要引入off-page部分,如果需要引入off-page部分则生成big_rec_t的更新向量(这一步类似原有悲观更新判断并生成off-page列的逻辑),同时缩短、构建index部分的record内容,尝试对record的index部分进行乐观更新。由于生成off-page部分的情况下,索引部分被缩短为20或788Bytes,如果原有record的off-page存在性与更新的record一致(都需要或都不需要off-page部分)则这种情况下大概率是不需要进行index部分的SMO的,因此可以直接在乐观逻辑中进行索引更新;如果不一致,则通过8KB的限制具体决定是否更新,如果index部分仍需要做SMO,那会释放生成的big_rec_t的更新向量,重新走一遍悲观更新,和原有逻辑完全一致。简单来说,PolarIndex 2.0对存在off-page的记录保留了乐观逻辑,通过回退溢出列向量来兼容乐观失败情况下的悲观逻辑,使得含lob记录的in-index part可以并发写入。
Off-page part optimization
索引部分更新完成后会进入off-page部分的更新,即对生成的big_rec_t的溢出列更新向量进行实际更新。对于off-page part的lob优化逻辑,PolarIndex 2.0将生成逻辑和写入逻辑拆分,在生成逻辑阶段持有所需要的space和index锁,批量生成lob数据页;当生成成功后只保留所需的page锁,进行具体内容的写入;最后再将完整的off-page part的lob页串挂到index page上,具体逻辑如下。 第一阶段:属于分配的操作alloc_lob_page,这一阶段持有 root 和 space 锁,这里不需要每次分配一个page,可以一次性分配足够空间,分配多个 page且所有 page 不需要初始化来最小化全局锁临界区开销。其余页面上的操作都属于非分配阶段,无需 space 锁和 root 锁。 第二阶段:写入 lob 内容生成 lob 串/索引,我们会持有目标lob页的page X锁(实际上这些页还并为被其他线程可访问,不会造成冲突),然后依次写入lob页内容并且生成redo。这一阶段锁粒度很小,完全避免了批量copy操作的影响范围。 第三阶段:走optimistic restore 逻辑定位并加锁(root/index S锁,page X),optimistic restore 逻辑所需锁(root index S锁,page X)。
收益:
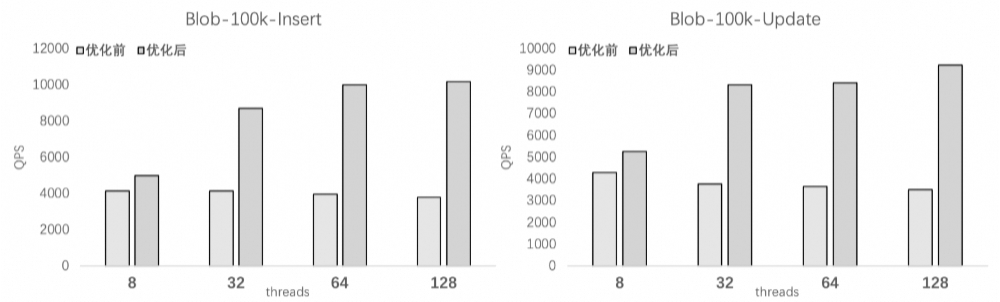
以线上16C实例、单表100KB行长Blob记录的插入和更新测试为例,结合PolarDB原有的partition redo、Non-zero filling等优化(避免其他环节瓶颈),PolarIndex 2.0在高并发情况下相对原有能有接近 3 倍的索引写入性能提升。
Prefix Encoding
InnoDB 通过 Btree 索引组织表数据并且支持构建 Btree 二级索引。InnoDB原生的索引结构中,对于主键record,首先是所有主键key的字段列、再是非key数据的字段列;而二级索引record,则先是对应二级索引key的字段列、再是主键key的字段列,并且没有做相同sk的聚合(Duplicate Key Removal)。这样的设计在相当程度上加剧了InnoDB 索引数据膨胀的问题,对于线上不少多索引的用户,其二级索引部分数据量甚至可以占到索引数据总量的30%至50%。基于这个现实情况,我们在PolarIndex 2.0中实现了二级索引的prefix encoding能力。
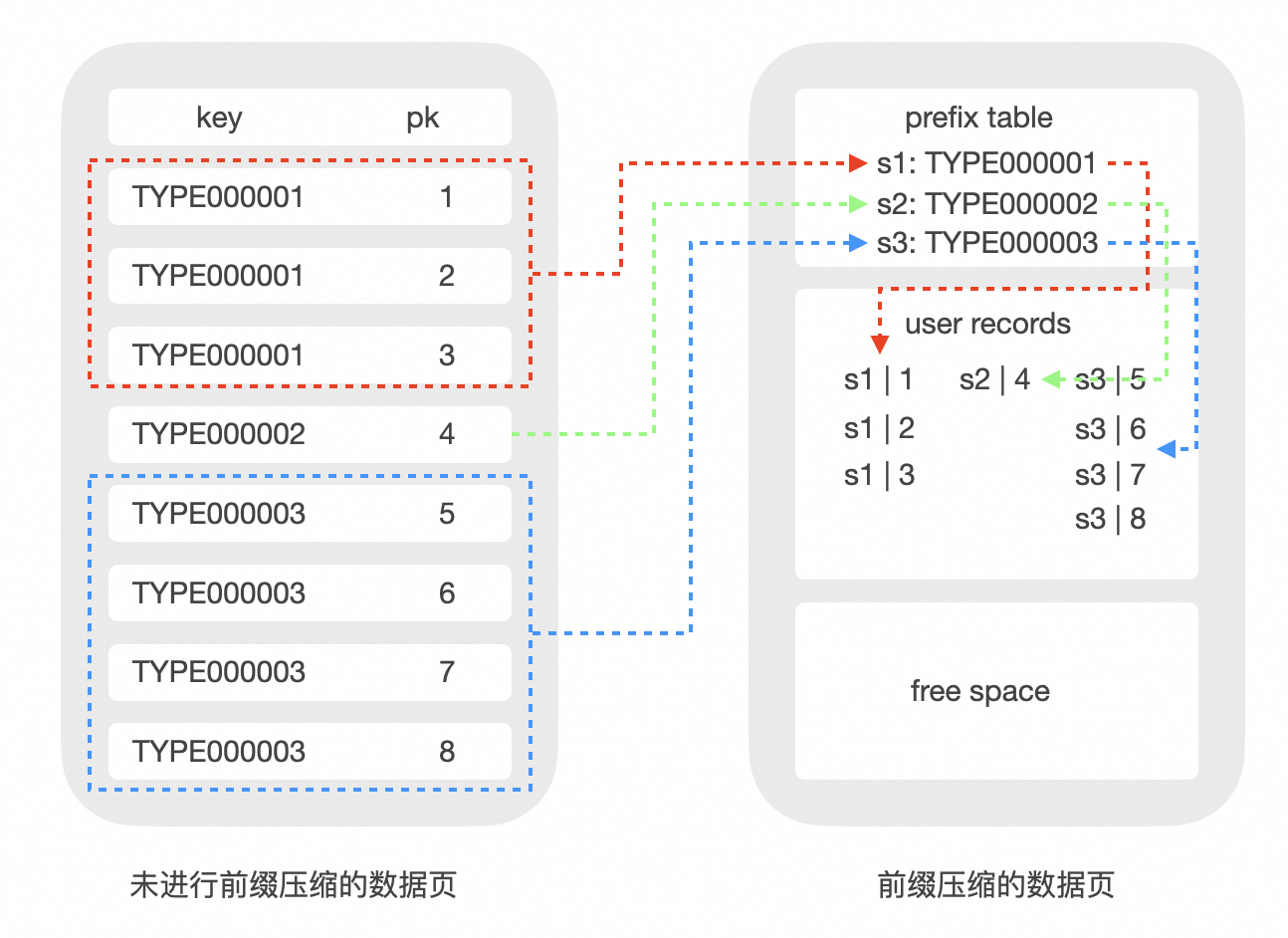
页内格式、Encode&Decode
我们在page内部开辟了symbol table存放压缩所需要的元信息,用来实现page record的快速压缩和解压。单个page自解析,避免读取时额外的 IO,并且重建 symbol table 是纯内存操作。symbol table的物理位置在system record之后user record 之前,也就是page heap的起始位置。一旦某个版本的symbol table确定之后,除非发生完整的symbol table更新,其内容是不会进行修改的,因此我们称之为半静态的元数据。
对于前缀压缩,新插入的record在page上首先保持非压缩状态,等到触发 encode 阈值再对page整体进行压缩以避免每次操作都有压缩开销。而触发encode阈值是在乐观路径的page满且reorganize也无法腾出空间时。原本会放锁进入 SMO 流程,我们这里先尝试在乐观路径中做 page 级别整体的encod,此时会尝试对所有记录进行最优化选取前缀压缩元信息,并判断对应生成的新symbol table是否会有足够收益。这里会通过贪心选择从第一个键开始,逐步扩展最长公共前缀,直到无法覆盖后续键。 再将页内键划分为多个前缀段,每段对应一个 Prefix Table 条目。 如果确定(重)压缩收益则(重新)压缩数据并更新写入,不再进入SMO流程。这个设计优先考虑在混合读写工作负载下的性能稳定性,大部分业务场景在开启压缩后,至少会看到一定程度的性能提升。保证压缩开销在DML操作路径上尽可能延后或者消除,而不会每次操作都有压缩开销。
我们在record的Info Flags上拓展了一位来表征此记录是否是压缩记录,老版本记录对应标志不会设置以完全兼容原有操作路径。在一个page页内可以同时存在压缩和非压缩两种类型的记录,根据对应标志位判断处理模式。InnoDB内部存在dtuple_t(内存记录格式)和rec_t(页上物理记录格式)两种record格式类型的转换与比较。当数据前缀压缩后可能失去列属性,因此rec_get_offsets等函数无法对压缩后的rec_t直接解析,需要对应的改造相应函数获取rec_t中的物理数据偏移。另外,InnoDB记录的比较是基于列的,offsets本质是辅助解析rec_t至各列的结构,只要保证相应信息能将压缩部分数据解析出来,就可以用压缩rec_t、压缩元信息以及对应的offsets,去和dtuple_t转换或比较。总的来说,对于压缩的record,要么先完全解压构建原来的rec_t数据走原来比较逻辑,要么用改造过的offsets或dtuple_t以及对应的列比较执行函数来做比较(可解释压缩计算)。PolarDB目前在不同路径上会根据环境条件从两种方式中选择之一。
性能影响
从实际数据来看,Prefix Encoding在二级索引上基本可以获得超30%的空间收益。除了空间收益,btree压缩还可以在一定程度上获得btree性能收益。我们来看 InnoDB 的两类性能问题:
IOPS 瓶颈 我们知道每一个 btree 节点对应磁盘上的一个物理 page,通常情况下 buffer pool 无法容纳所有 btree leaf page。那么对于 btree 的一次随机读写,都可能发生一次磁盘 IO,另外 range scan 需要遍历多个 leaf page 造成多次 IO。一般来说系统的 IOPS 存在上限,很容易成为系统瓶颈。另一方面,哪怕在做顺序写入时,二级索引上page的访问也不是顺序的,有更有多的随机访问产生加剧这一问题。
Index lock 瓶颈 InnoDB btree 在 SMO 过程中,持有了 index 大锁,如果需要额外的 IO 操作将 page 加载到 buffer pool,等待 page IO 时,其它线程无法访问 SMO subtree,也不允许整个 btree 上发生其它 SMO,导致逻辑上没有冲突的操作阻塞。这种情况下,IO 带宽很低,所有线程又都在等待,造成实例吞吐很低。所以会有 mysql 大表更慢的共识。云存储上的 IO 延迟是更大的,又放大了这个问题。
对 btree page 内部的记录压缩后,可以缓解上面两个性能问题:record 以轻量压缩后的格式存储在 btree page,内存 bp page 和物理文件 page 中的 record 完全一样。 由于内存和磁盘 page 中存储的都是压缩后的数据,单个 page 能存的数据量相对不压缩来说就更多了,在整体数据量一定的情况下,btree page 数量更少了,buffer pool 中可以保留更多 btree 节点,bp 命中率就可以提高。range scan 由于单个叶子结点能存更多的数据了,在需要扫描的数据总条数不变的情况下,扫描叶子结点数变少了。要读的结点数少了,磁盘 IOPS 就降低了,更不容易达到系统 IOPS 瓶颈,整体吞吐量得到提升。
收益:
从实际使用情况来看,Prefix Encoding在二级索引上平均可以获得超30%的空间收益,另外在性能方面: IO Bound 场景下压缩减少了btree叶子节点的数量,在 IO bound 场景增加了 buffer pool 对叶子节点的覆盖率,覆盖更多的 page 使随机读场景更少的 page 换入换出,对 bp 的 hash table 和 lru list 访问频率更小,hash 锁和 lru list 锁竞争更少。此外,对文件系统的 IO 次数更少,用户线程直接命中 BP 即可返回。 CPU Bound 场景下page 中 record 密度更大,减少了 page 分裂频率,缓解了分裂对 index SX 锁的争抢,而且减少了正在分裂节点的父节点拿的 X 锁数量,缓解了对其叶子节点的插入。此外,为了减少开启压缩后 SMO 时拿 index 锁时间,压缩路径不覆盖 SMO 过程。在 bp 足够大时进行随机读取,那么压缩并不会带来性能提升,访问压缩 record 会带来一定解压开销,但前缀解压的开销较小。需要根据具体业务需求判断,通常压缩对 IO 资源的节省远大于解压的开销。
总结与展望
优势场景总结,PolarIndex 2.0索引热点写入能力相对PolarIndex 1.0 版本再进一步提升 80%(提升至原始基础值的 300+%),支持 Blob 索引并发优化(单表Blob写入提升至PolarIndex 1.0的 300+%),二级索引空间试用率下降平均约 30-60%。上述的 PolarIndex 2.0 功能目前都已在 PolarDB 8.0 最新版本中上线,期待大家前来使用~
未来,PolarIndex 将继续演进,努力为用户业务提供更极致、更全面的能力支持。