浅析 DuckDB 的内存管理
Author: huaxiong
浅析 DuckDB 的内存管理
1 Introduction
DuckDB 是一个开源、列存、面向分析型查询的嵌入式数据库。与传统数据库不同,DuckDB 可以以库的形式直接嵌入应用程序中,极大降低了部署复杂度,能够很好地适用于轻量级分析场景。
在 DuckDB 的 In-File 模式下,所有数据通常默认存储于单个数据库文件中。用户也可以通过 ATTACH 命令显式加载额外的 database。尽管 database 在文件系统层面相互隔离,拥有独立的存储管理单元,但所有 database 的内存都由全局的内存管理模块进行统一管理。
DuckDB storage 的内存管理模块主要包括 BufferPool 和 StandardBufferManager,本篇内容也将主要围绕这两者展开。
2 BufferPool
BufferPool(后文简称 BP)是 DuckDB 中的全局内存池,负责了内存的淘汰、释放等操作,并维护内存使用情况的统计信息。和 MySQL 中 InnoDB 引擎的 BP 不同,DuckDB 的 BP 并不会在启动阶段完成大片内存的申请,内存块会在使用的过程中按需使用和管理。DuckDB 的 BP 是一个逻辑上的整体,其中包含了诸多的内存块。
2.1 EvictionQueue
DuckDB 中文件读写和内存管理的基本单元都是 BLOCK,BP 中根据 BLOCK 的类型,设计了 3 种共 8 条无锁淘汰队列(EvictionQueue),形成层次化的缓存淘汰优先级体系。

-
队列 1 用于缓存普通的 BLOCK(BLOCK_AND_EXTERNAL_FILE_QUEUE,后文简称 BEFQ),这类 BLOCK 在没有被访问的情况下对应的内存块可以直接被释放。
-
队列 2 ~ 7 用于管理运行过程中产生的脏 BLOCK(MANAGED_BUFFER_QUEUE, 后文简称 MBQ),这类 BLOCK 对应的内存在释放前必须要进行持久化。
-
队列 8 用于单独管理小于 256KB 的小内存块(TINY_BUFFER_QUEUE,后文简称 TBQ)。
BLOCK 添加到 BP 之前,会根据 BLOCK 的内存类型来决定其应该被添加到哪种队列中。BLOCK 中记录了引用计数 readers, Pin/Unpin 操作会让引用计数发生变化。BLOCK 中定义了销毁策略,在引用计数清零时,会根据策略决定后续内存的管理方式,各个策略对应的操作如下表所示:
| 销毁策略 | 不再使用时是否加入 BP | 内存销毁前是否写入临时文件 |
|---|---|---|
| DestroyBufferUpon::BLOCK | 是 | 是 |
| DestroyBufferUpon::EVICTION | 是 | 否 |
| DestroyBufferUpon::UNPIN | 否 | 否 |
由于当前 BP 淘汰 BLOCK 时是从前往后遍历每一个队列,因此 BP 中队列顺序直接决定了缓存淘汰的优先级。上述的各个队列中,BEFQ 中保存的 BLOCK 可以随时被释放,具备最高的淘汰优先级;TBQ 中由于缓存的 BLOCK 大小不一且规格较小,当需要固定或者较大 size 的内存块时淘汰代价较高,因此具备最低的淘汰优先级;脏 BLOCK内部维护的 eviction_queue_idx 决定了其应该被加入到哪一条 MBQ 当中,在当前的设计中,eviction_queue_idx 越小,则 BLOCK 会被放置到越靠后的 MBQ 中,就越难被淘汰。
2.2 EvictBlock
在介绍 BP 的淘汰之前,笔者先介绍一下 DuckDB 中 BP 的内存限制和内存统计机制。
- Memory limit
DuckDB 提供了一个 memory_limit 的全局参数用于控制 BP 缓存内存的大小,当设置的 memory_limit 值小于当前已经使用的内存值时会触发内存的淘汰,在设置新值的过程中引入了二阶段淘汰的机制。其中第一次淘汰是在修改 memory_limit 之前,尝试释放足够的内存,使得当前使用量小于等于新的限制值。这是一个“预检”操作,如果连当前限制下都无法满足新限制,那就没必要做真正的修改了。此时 memory_limit 还未更改,所以淘汰策略基于旧限制。第二次淘汰是在 memory_limit 已经设置之后,目的是确认在新的内存限制下,系统仍然满足内存约束,如果第二次淘汰动作没有执行成功,那么 memory_limit 会回滚为旧值。
- Memory usage
BP 中包含了内存的统计信息,根据使用用途将内存统计项分为了 14 个 tag、64 个子计数器,更新内存统计信息时根据线程 ID 的哈希值将新值写入到对应的子计数器内。除此之外,BP 中的各个统计项还包含了一个全局计数器,只有子计数器中的内存变更的累计值超过阈值(32KB) 时,才会触发全局计数器的更新。当然,BP 也提供了获取精确内存值的方式(FLUSH 模式),获取过程会直接将子计数器的统计信息汇总到总计数器中并返回。如下图所示,每一列表示一个计数器,每一行的信息汇总则是特定 tag 的内存使用情况。
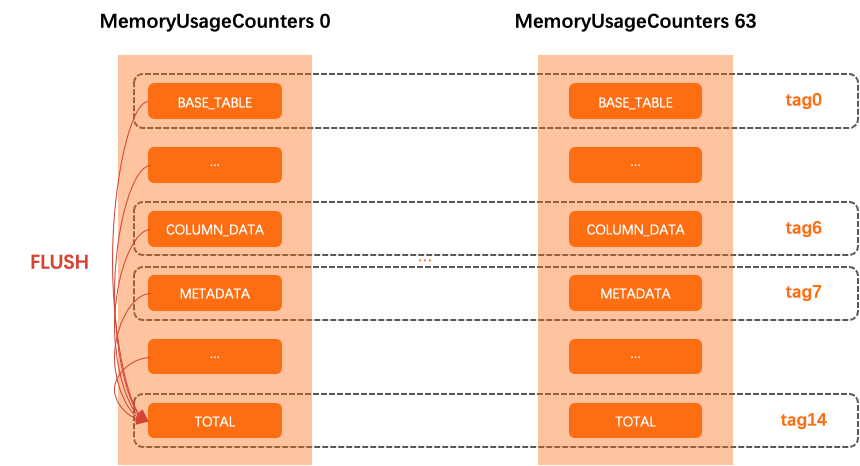
这样的设计避免了多线程模式下频繁更新全局原子变量下来的冲突和性能下降,但是由于 BP 中的内存统计信息并不是实时更新的,理论上存在的最大偏差值为:32KB * 14(tag) * 64(子计数器)= 28MB。此外,由于 BP 的淘汰依赖于内存的统计信息,因此 BP 对于内存块的淘汰行为和缓存的内存大小也是一个相对不固定的值。
- Evict
申请方在发现内存不足时,会调用 EvictBlocks 触发 BP 的淘汰,而 BP 的淘汰本质上对应的是 8 条队列的淘汰,越靠前的队列优先发生淘汰动作,一旦淘汰腾出足够的空间,后续的队列将不再做淘汰动作。DuckDB 的内存管理中引入了 Reservation 的概念, Reservation 的存在将内存的申请和实际内存的持有分成了两个阶段。一旦申请内存成功时,BP 会将保存有内存类别(tag) 和大小(extra_memory) 的内存“支票” Reservation 传递给申请方,申请方在后续根据“支票”中保存的 tag 和 extra_memory 去持有实际内存。
单个队列中淘汰内存的主要步骤如下:
-
DuckDB 首先会构造一个 Reservation,用于暂存本次申请的内存类型(tag)和大小(extra_memory)。随后,这些信息会被更新到对应的子计数器和全局计数器中。
-
内存统计信息更新后, BP 会采用 NO_FLUSH 的形式获取当前“粗略”的总内存值,当发现总内存值小于 memory_limt 时,会直接认为内存申请成功。由此也可以看出,尽管设置了内存上限值,但是在实际申请和使用过程中,还是有可能超出这一限制的。
-
逐个取出队列中的所有元素,一旦满足条件,就结束遍历动作。这里满足的条件有几种:
-
提供了 FileBuffer 指针用于接收淘汰的内存块,且在遍历队列的过程中找到了相同 size 的 BLOCK。满足这种条件时,BLOCK 的内存块会被传递到入参 FileBuffer 中直接使用。与此同时,被淘汰的 BLOCK 的内存统计信息会从内存计数器中被扣除。
-
持续遍历,每次直接释放 BLOCK 的内存、扣除相应统计信息,每次释放完毕后都使用 NO_FLUSH 的方式重新查看当前系统的总内存值,直至总内存值小于 memory_limit。
-
-
2 或 3 步骤中内存申请成功后,将 Reservation 返回给申请方。同时,如果本次申请的内存量大于 512MB 时,会触发一次内存的 flush,释放实际的物理内存。当然,内存申请也有可能失败,在失败时要将此前Reservation 中暂存的内存信息从内存计数器中清除,避免统计信息泄露。
从上述的步骤中不难看出,被淘汰的内存块有两种处理方式,一是返回给调用方复用,二是释放其内存空间。实际上在直接释放之前,部分的 BLOCK 可能会做持久化处理,写入到磁盘中。
BLOCK 中由 block_id 来唯一区分一个 BLOCK,它在磁盘上的物理位置也可以由 block_id 计算得到。除了唯一标识 BLOCK 之外,block_id 还能用来区分当前 BLOCK 是否为临时 BLOCK:当 block_id > 2^62^ 时表示该 BLOCK 为临时 BLOCK。当临时 BLOCK 的销毁策略被设置为 DestroyBufferUpon::BLOCK 时,其内存必须在销毁前写入临时文件完成持久化,以防止数据丢失。BLOCK 归属的 BufferManager 结合 tag、block_id,将内存数据写入到特定的文件中,完成持久化。关于写临时文件的更多内容笔者会在后文介绍 StandardBufferManager 时再做进一步介绍。
DuckDB 在当前设计中实际上并没有使用到基于 timestamp 的 LRU 淘汰机制,所有 BLOCK 被添加到淘汰队列中的 timestamp 都是 0。只有显式配置了 track_eviction_timestamps 参数后,BLOCK 在添加到队列时才会被设置上时间戳;此外,BP 的清理需要从 EvictBlocks 调用改为 PurgeAgedBlocks 调用才能让某一时间范围内的 BLOCK 被淘汰。同时由于队列本身并没有根据 timestamp 进行排序,因此执行 PurgeAgedBlocks 操作时,依旧是遍历队列来淘汰满足条件的 BLOCK。简言之,EvictBlocks 是以内存大小的维度去做淘汰,需要多少就淘汰多少;而PurgeAgedBlocks 是以时间的维度做淘汰,淘汰的是指定时间范围内的所有队列的所有 BLOCK。
2.3 Purge

队列中还维护了失效 BLOCK 的数量 total_dead_nodes,所谓的失效是指 BLOCK 已经被销毁或已过期。BLOCK 内部维护了淘汰序列号 eviction_seq_num,在加入淘汰队列前会自增该值。eviction_seq_num 可以判断出 BLOCK 是否是首次加入淘汰队列,当 BLOCK 被重复加入时,队列中会有多个相同的 BLOCK,此时旧的 BLOCK 就是过期的 BLOCK。当缓存淘汰时,出队列的 BLOCK 如果处于失效状态,则将 total_dead_nodes 减一,同时由于失效状态的 BLOCK 的淘汰不会释放内存块,因此淘汰动作还将继续。
BP 中每个队列中维护了插入的 BLOCK 总数量 evict_queue_insertions。每插入 4096 个 BLOCK ,BP 外层调用方如 StandardBufferManager 就可能会触发一次队列的清理操作,对队列中的缓存元素进行清理。因此队列的清理除了前文提到的内部不足淘汰时会发生之外,主动调用 Purge 也会触发队列的清理。
主动 Purge 产生的队列清理采用了自适应的清理策略,主要执行过程如下:
-
计算本次需要 purge 的数量:purge_size = 4096 * 2 = 8192。
-
对比当前队列大小 q_size 和 purge_size,如果 q_size < purge_size * 4,则认为当前队列太小,无需清理。
-
将清理过程分为 n 个批次进行,每次清理 purge_size 数量的节点。每次清理完毕后都要重新判断当前队列的大小是否满足 q_size < purge_size * 4 的条件,一旦满足也会提前结束清理过程。 另外,每个批次中还会计算当前队列中有效 BLOCK 和失效 BLOCK 的比例,只要满足 3 * alive_nodes > dead_nodes 条件,清理过程也会提前结束。

在每次清理的过程中,如果遇到有效的 BLOCK,会将这些已经出队列的节点重新添加到队列中,并重新更新total_dead_nodes 的值。
3 StandardBufferManager
StandardBufferManager(后文简称为 SBM)是 DuckDB 中直接和文件管理器交互的内存管理对象,负责内存的 alloc、release、evict、swap 等。相对 BP ,SBM 更像是一个内存的使用方,DuckDB 的 storage 的所有内存操作都是通过 SBM 完成的。本节内容主要围绕 BLOCK 的内存申请、swap 操作和 BLOCK 的 BatchRead 展开,SBM 的缓存的添加、淘汰完全基于 BP 实现,此处不再赘述。
3.1 Register memory
在介绍 SBM 的内存申请的相关操作之前,笔者先简单介绍 BLOCK 中 Pin 和 Unpin 的概念。
Pin 可以理解为对某个数据块(BLOCK)的内存申请与固定操作。当执行 Pin 操作时:若目标 BLOCK 已在缓存中且有效(即已分配内存),则将其读引用计数 n_reader 加 1,并直接返回该 BLOCK,避免重复加载;若 BLOCK 当前无效(未加载或已被淘汰),则需为其分配内存。在分配前,系统会再次检查是否有其他线程已并发加载同一 BLOCK(防止重复加载)。若发现已存在,则仍执行引用计数递增并返回;否则,触发缓存加载流程,包括内存分配与 BLOCK 的重建。同时,系统会在执行 Pin/Unpin 操作时,同步更新内存计数器中的统计信息。Unpin 是 Pin 的反向操作,首先减少引用计数,当引用计数清零时则触发淘汰/内存释放动作。如前文提及到的,当 BLOCK 定义的销毁策略不是DestroyBufferUpon::UNPIN 时,BLOCK 会被添加到 BP 中,进一步地,添加操作还可能会触发 BP 中队列的 Purge(每 4096 次添加会触发一个 Purge)。

SBM 中定义了较多的内存注册方式。申请小内存时构造 TINY_BUFFER 的 BLOCK,这类 BLOCK 在淘汰时会进入到 TBQ 中,具备最低的淘汰优先级,在内存销毁前必须写入到磁盘中。申请普通内存时构造 EXTERNAL_FILE 或 MANAGED_BUFFER 类型的 BLOCK,这类 BLOCK 在淘汰时会分别进入到 BEFQ 或 MBQ 中,其销毁策略由调用方决定,内存销毁前可能被直接淘汰,也可能被写入到临时文件中。不论是小内存还是普通内存,注册产生的 BLOCK 的 block_id 都是临时的(>2^62^),只有持久化时才会被分配实际的 block_id。
3.2 Swap
当内存不足且启用了临时目录时,DuckDB 根据内存的销毁策略(DestroyBufferUpon::BLOCK)可能会执行 SWAP 操作,将缓冲区写入磁盘。写入到临时文件时,DuckDB 会按照特定的格式写入,读取时也会按照相应的格式进行解析。
对于 256K 的固定大小块,DuckDB 采用类似伙伴算法的管理方式,把内存信息经过压缩后写入到一组共享的.tmp 文件中。其中每一个.tmp 文件负责保存特定大小的 BLOCK 数据,如压缩后为 32K 和 64K 大小的 BLOCK 分别会被写入到duckdb_temp_storage_32768-1.tmp 和duckdb_temp_storage_65536-2.tmp 中。文件信息以及写入的位置会和 block id 关联,记录在内存的 map 中。由于每个 tmp 文件中的 BLOCK size 都是固定的,因此在落盘时并不需要保存具体的 size 信息,临时文件的格式如下:

对于变长块,则会单独生成 .block 文件,将内存的大小、加密等头信息以及数据本身写入到单独的与 block_id 关联的.block 文件中,例如 block id = 99 的 block 会被写入到duckdb_temp_block-99.block 的临时文件中。临时文件的格式如下:

3.3 Prefetch
SBM 中设计了 prefetch 用于 IO 慢的场景,例如 DuckDB 使用远程的 S3 作为底层的数据存储介质时,IO 延迟很高,prefetch 的设计能够减少 IO 的次数,提升整体性能。
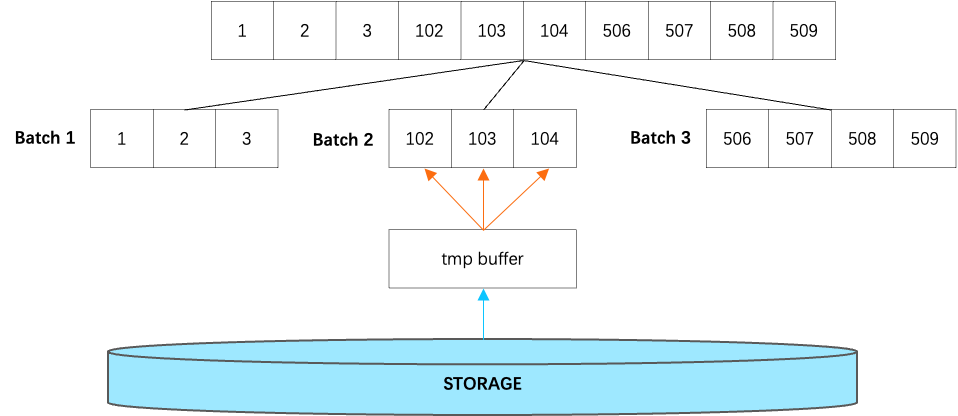
Prefetch 操作会尽可能放大单次读取的 BLOCK 数量、减少 IO 的次数。当一批待请求的 BLOCK 被传入时,BLOCK 会根据相邻关系被分组,所有紧邻的 BLOCK 会被一次性执行 BatchRead。相同的分组分批处理逻辑在文件 free block 的 TRIM 过程中也被使用到,目的都是减少操作的次数。BatchRead 的主要流程如下:
-
首先申请一片大的临时内存用于本次读取,内存大小为 BLOCK 数量 * BLOCK 大小。
-
由于 BLOCK 已经完成分组,单批次的 BLOCK 的物理索引(block_id)一定是连续的,因此直接根据起始位置和总大小完成一次 IO 读取。
-
将临时内存中的数据按照 BLOCK 的粒度逐个填充到各个 BLOCK 中。填充过程中如果发现 BLOCK 已经被其他线程加载过,就无需再次填充。
在笔者看来,临时内存是理论上可以省去的,在读取的过程中直接完成填充。但是这样的设计会让代码的耦合度变高,当前的实现上各个模块相对独立,可维护性更高。BatchRead 只是为后续操作预取数据,并不会保持 BLOCK 处于 pinned 状态。只要 BLOCK 在此期间未被释放,其中的数据就会一直可用。由于实际读取操作通常很快就会发生,因此数据通常都是可用的(不需要重新从磁盘读取)。
4 Conclusion
BufferPool 是全局共享的逻辑内存池,使用 8 条缓存淘汰队列实现优先级控制。BLOCK 的淘汰策略决定了其是否需要加入 BP、是否需要落盘。内存限制的变更采用了预检、提交验证的两阶段修改方式。内存统计采用计数器分片 + 延迟刷新的机制,避免多线程竞争,但存在最大约 28MB 的统计偏差。
StandardBufferManager 是 BP 的“客户端”,负责实际的 alloc、pin/unpin、swap、prefetch 等操作。启用临时目录时,SBM 执行 swap 将内存写入临时文件,对于固定大小和非固定大小的文件有不同的写入和读取方式。
作为一款嵌入式分析型数据库,DuckDB 并未采用传统数据库中常见的静态内存预分配模式,而是通过按需分配、细粒度管理和动态回收的方式,构建了一套高效且灵活的运行时内存体系。内存管理中引入了诸多分片、分批的设计,如多队列管理、分片内存统计器,类似的设计有效降低了高并发下的冲突,提升了整体的性能。DuckDB 在轻量架构下,各个组件的职责划分是很清晰的,在工程设计和实现上都具备参考价值。