PolarDB Mysql · 新功能特性 · groupby/orderby消除
Author: 陈江(恬泰)
前提条件
集群版本需为PolarDB MySQL引擎8.0版本,Revision version为8.0.2.2.33及以上
您可以通过查询版本号确认集群版本。
背景信息
在 SQL 查询执行过程中,groupby 算子通常通过排序或哈希去重实现,带来显著的 CPU 和内存开销。然而,在某些情况下,即使未显式去重,查询结果也天然具有唯一性(如主键关联、函数依赖等)。 本优化功能利用 函数依赖(Functional Dependency),在查询优化阶段识别出 groupby列的值已经唯一,自动消除冗余的 groupby算子,从而提升执行效率,降低资源消耗。
原理
-
fd:函数依赖,如果y=f(x),我们称之为x->y(x决定y)或者y函数依赖于x
- 如果order list里面有GroupBy/OrderBy x,y 可以简化成GroupBy/OrderBy x.
-
如果groupby列在join结果集中已经具有唯一性,则可直接消除groupby算子
使用方法
- 通过系统参数groupby_elimination_mode开启groupby消除功能。
- 通过系统参数orderby_elimination_mode开启orderby消除功能。
| 参数名称 | 级别 | 描述 |
|---|---|---|
groupby_elimination_mode |
Global、Session | 取值范围:- ON:开启该功能- REPLICA_ON(默认值):只在RO节点开启该功能- OFF: 关闭该功能 |
orderby_elimination_mode |
Global、Session | 取值范围:- ON:开启该功能- REPLICA_ON(默认值):只在RO节点开启该功能- OFF: 关闭该功能 |
适用范围
- 如果groupby列具有唯一性,那么可以消除groupby
- 如果groupby列都是常量,那么可以消除groupby,并添加LIMIT 1
- 如果存在x->y,则groupby/orderby x,y可化简为 groupby/orderby x
- 如果orderby列都是常量,那么可以消除orderby
优化场景示例
- a是const,添加limit 1 可去掉distinct算子
SELECT a, b, 1, a + b FROM t1 WHERE a = 1 AND b = 1 group by a, b, 1, a + b;
=>
SELECT a, b, 1, a + b FROM t1 WHERE a = 1 AND b = 1 limit 1;
- tpch Q10&Q18均有优化,以Q10为例, 存在如下函数依赖
##c_custkey是主键,决定其他列
c_custkey->{c_name, c_acctbal, c_phone,c_address, c_comment,c_nationkey}
## n_nationkey是主键,决定其他列
n_nationkey->n_name
因c_nationkey = n_nationkey,他们相互决定,所以有c_nationkey->n_nationkey
## fd具有传导性c_custkey->c_nationkey, c_nationkey->n_nationkey所以有
c_custkey->n_nationkey
##最终 c_custkey->{c_name, c_acctbal, c_phone,c_address, c_comment,n_nationkey},groupby中的这些列都可以消除
SELECT c_custkey, c_name
, sum(l_extendedprice * (1 - l_discount)) AS revenue
, c_acctbal, n_name, c_address, c_phone, c_comment
FROM customer, orders, lineitem, nation
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate >= '1994-09-01'
AND o_orderdate < date_add('1994-09-01', INTERVAL '3' MONTH)
AND l_returnflag = 'R'
AND c_nationkey = n_nationkey
GROUP BY c_custkey, c_name, c_acctbal, c_phone, n_name, c_address, c_comment
ORDER BY revenue DESC
LIMIT 20;
===》
SELECT c_custkey, c_name
, sum(l_extendedprice * (1 - l_discount)) AS revenue
, c_acctbal, n_name, c_address, c_phone, c_comment
FROM customer, orders, lineitem, nation
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate >= '1994-09-01'
AND o_orderdate < date_add('1994-09-01', INTERVAL '3' MONTH)
AND l_returnflag = 'R'
AND c_nationkey = n_nationkey
GROUP BY c_custkey
ORDER BY revenue DESC
LIMIT 20;
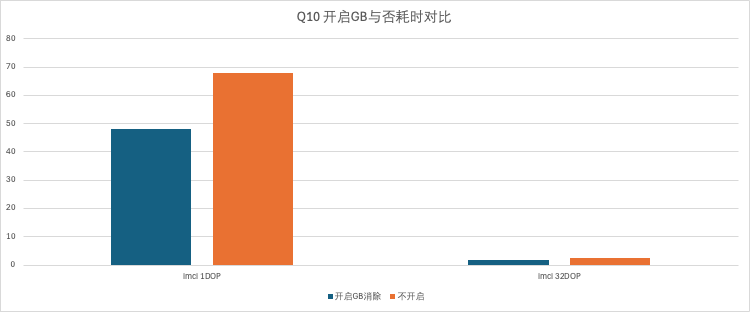
性能收益
以上例tpch 100G数据集为例, 开启groupby消除 Q10 性能提升29%。
| 开启GB消除(单位:秒) | 不开启(单位:秒) | 提升 | |
|---|---|---|---|
| imci 1DOP | 48 | 68 | 0.29 |
| imci 32DOP | 1.9 | 2.6 | 0.27 |
核心实现
- mysql 基于collation比较规则下的bug
CREATE TABLE `t1` (a varchar(1));
insert into t1 values('a'), ('A');
mysql> select a, hex(a) from t1;
+------+--------+
| a | hex(a) |
+------+--------+
| A | 41 |
| a | 61 |
+------+--------+
mysql> select a, hex(a) from t1 group by a;
+------+--------+
| a | hex(a) |
+------+--------+
| a | 61 |
+------+--------+
在strict sql_mode下,使用utf8mb4_0900_ai_ci比较’a’, ‘A’认为是相等的,所以’a’,’A’被认为是一组,但分别对应了两个HEX值,但这条带groupby的sql能通过ONLY_FULL_GROUP_BY检查,这是个bug。 polardb要完全兼容mysql,就算是bug,也要保证行为一模一样 所以如下sql虽然在关系代数中可以无脑消掉GB,但在mysql codebase中要保留,确保跟mysql兼容
select a, hex(a) from t1 group by a, hex(a)
可改写成==>select a, hex(a) from t1 group by a
//在mysql中不要做改写
构建fd graph
- 自底向上构建fd graph,依赖fd graph的查询变换依赖于fd graph的状态,在fd graph的一个状态下我们可能需要做多个查询变换,因此我们基于fd graph推导出的UNIQUE、CONST性质进行order item消除。
唯一性来源
- 函数决定唯一键, Uniq索引列上的组合keypart具有唯一性
- 函数决定GROUP BY列
- 内层DISTINCT/implicitly group by/group by scalar/limit 1/scalar table/dual,那么内层所有投影列具有唯一性,可传递给外层。
- 派生表t上的投影列具有唯一性,并且满足下列条件之一,JOIN后GB列仍具有唯一性。
- t semi join/anti join t’
- t left join t’ with false cond
- t left join/inner join scalar table
常量性来源
- Item或Item集合
- 是常量
- 被常量函数决定
- 等于常量
- implicitly group by/group by scalar/limit 1/scalar table/dual,那么所有投影列具有常量性
- 派生表t上的投影列具有常量性,并且没有被NULL implemented
使用fd graph进行唯一性测试
测试{init_fdset}->target是否成立,用函数bool fd_exists(init_fdset, target)表示 我们有输入fd集合init_fdset,通过图的连通性(fd就是图的边)不断扩充fd集合,当图不再发生变化,判断target节点是否在最终的fd集合中,如果在说明{init_fdset}->target成立。参考图染色算法,每轮染色后判断是否有新染色节点,没有的话可退出循环。
Corner case
- groupby (select it.a from it where it.b =ot.b)GB列是标量子查询,求值后是常量,按理说可以消掉。但这个子查询有个max1row的检查,只能在执行期才能判断出是否合法,所以在查询改写期如果删了就发现不了子查询多行的错误,所以这种GB列是标量子查询的,先不消除,在mysql的optimize阶段也会做常量求值的。
-
开篇mysql collation引入的bug,在collation下一些函数,fd不成立。比如hex, length, ascii。 在collation比较规则下,多个不同的字符被认为是相同的,但他们的binary是不同的。我们对这个问题进行抽象,就是逻辑上的相同值(‘A’, ‘a’),进行一些函数运算输出不同的值,是1对多的关系,我们引入一个fd_deterministic概念,上述函数对于同一string值求值后会输出多值,我们标记为none fd_deterministic. 这种函数不具有fd特性。
- none fd_deterministic有传播性, 比如y = g(hex(x)), 函数hex是none fd_deterministic, 函数g是fd_deterministic的,但x->y仍旧不成立。
- 遇到如下函数并且函数参数是string,我们认为是none fd_deterministic,我们不建立fd,推导关系不成立
- length
- hex
- ascii
- ord
- base64
- md5
- aes_encrypt
- aes_decrypt
- enhanced_aes_encrypt
- enhanced_aes_decrypt
- cast_as_char
- crc32
- uncompressed_length
- 如果lex上有udf, set_var, param也不进行消除,因为可能消除列的item有side-effect特性, 导致结果集不正确。
- 有分组+聚合函数的sql,不能将GB消掉,因为这样输出从多行就变为1行了,破坏了语义。