一站式智能检索:PolarDB AutoETL 实现自动数据流转
Author: 归墨
背景
PolarSearch 是阿里云基于自研高性能存储底座 PolarStore 打造的一站式分布式数据检索与分析引擎,全面兼容 Elasticsearch 与 OpenSearch 生态,无缝融入现有技术栈。面向海量数据场景,PolarSearch 提供企业级的高可用性、极致查询性能与开箱即用的智能检索能力,助力业务快速构建实时搜索与分析服务。
其核心优势包括:
高可用与弹性伸缩
采用分布式架构,支持自动负载均衡与故障自愈——单节点故障对业务无感,服务持续可用。同时提供在线动态扩缩容能力,存储与计算资源按需弹性伸缩,轻松支撑从百万到亿级数据规模的平滑演进。
毫秒级实时检索性能
数据写入后百毫秒内即可被检索,并支持复杂查询场景,包括多字段组合过滤、分桶聚合(Aggregation)、Top-K 相关性排序等,满足高并发、低延迟的业务需求。
一站式智能检索体验
内置 AutoETL 数据流转能力,无需额外开发同步链路,通过创建 PolarDB 搜索视图,即可将 PolarDB 中的业务数据自动、实时、一致地同步至 PolarSearch。并在此基础上,支持全文检索、向量相似性搜索、结构化查询与智能分析,真正实现端到端的一站式智能检索方案。
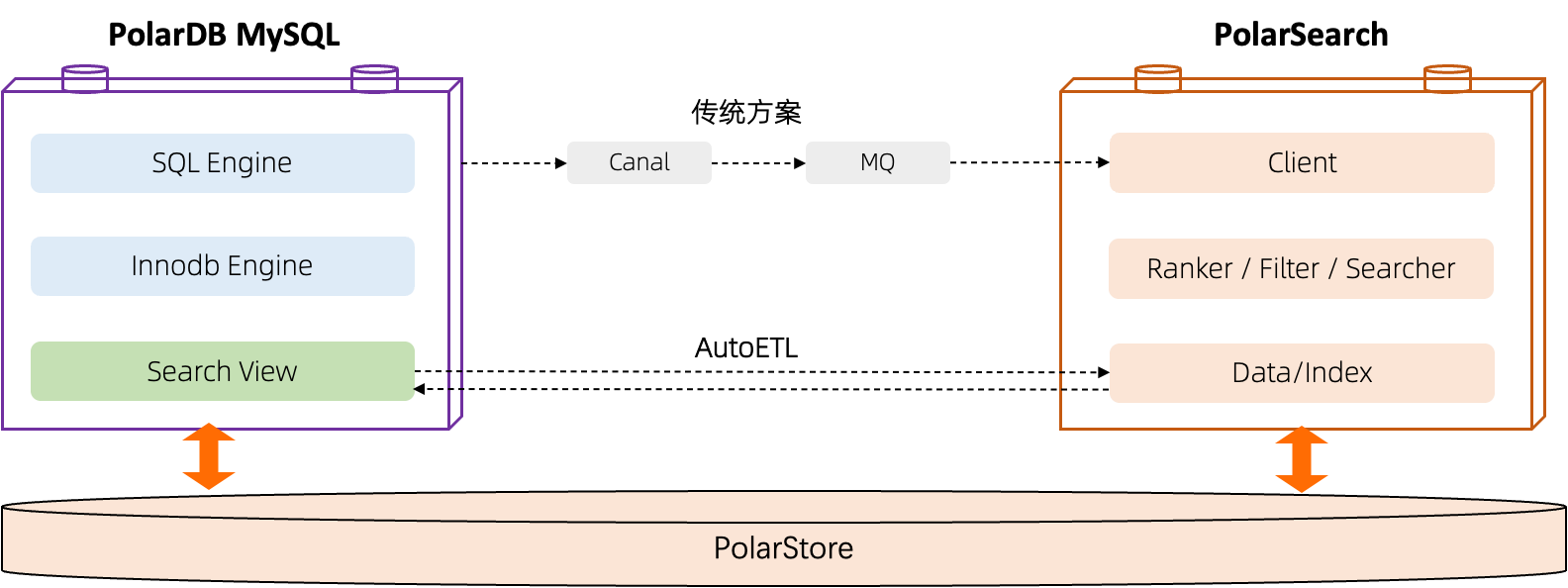
随着业务场景日趋复杂,在线事务系统如 MySQL/PostgreSQL,往往承载着高并发、强一致的核心交易数据,而业务搜索需求却日益多样化:从模糊匹配、多字段组合查询,到实时排序与聚合分析。MySQL 全文检索性能弱、功能有限,难以支撑高维、低延迟的检索场景。为了弥补这一短板,业务团队不得不自行搭建并维护一套从 MySQL 到其他数据检索平台的同步链路。这不仅带来额外的开发、运维成本,还引入了数据一致性、链路稳定性的新挑战。
因此,PolarDB AutoETL 应运而生——无需编写同步逻辑,无需管理中间链路,只需简单配置,即可自动将 PolarDB MySQL 数据实时同步至 PolarSearch 引擎,让业务团队聚焦于产品体验与创新。AutoETL 具有以下优势:
接口简单,零学习成本
SQL 即配置,采用熟悉的 MySQL 视图语法定义数据同步逻辑,即可完成字段映射、过滤、打宽等操作。
极低运维成本
业务无需另外搭建 CDC、消息队列、消费程序,就能快速搭建一站式检索服务。
毫秒级延迟,承载高并发写入场景
端到端数据变更毫秒级延迟;单链路最高支撑数十万 QPS 写入。
覆盖多样场景,灵活应对复杂业务
支持从简单的单表同步,再到多表聚合打宽,覆盖大多数业务使用场景。
多实例汇聚
支持从多个 PolarDB MySQL 引擎汇聚到一个 PolarSearch 引擎中,支持 GDN 同步。
高可用能力
链路具备自动重试、断点续传等故障恢复能力。
技术实现
AutoETL 实现
PolarDB AutoETL 使用独立的计算引擎服务,并和上下游引擎通过高速网络相连,解决传统方案链路时延过长的问题。并深入结合 MySQL 语法,将 MySQL 搜索视图转化为 ETL SQL 逻辑,AutoETL 引擎在解析到 ETL 请求后,读取数据,进行计算,最后批量写入到 Search 引擎。在同步过程中,Monitor 组件会定期监测链路状态,并提供 failover 机制进行自动重试和断点续传能力。
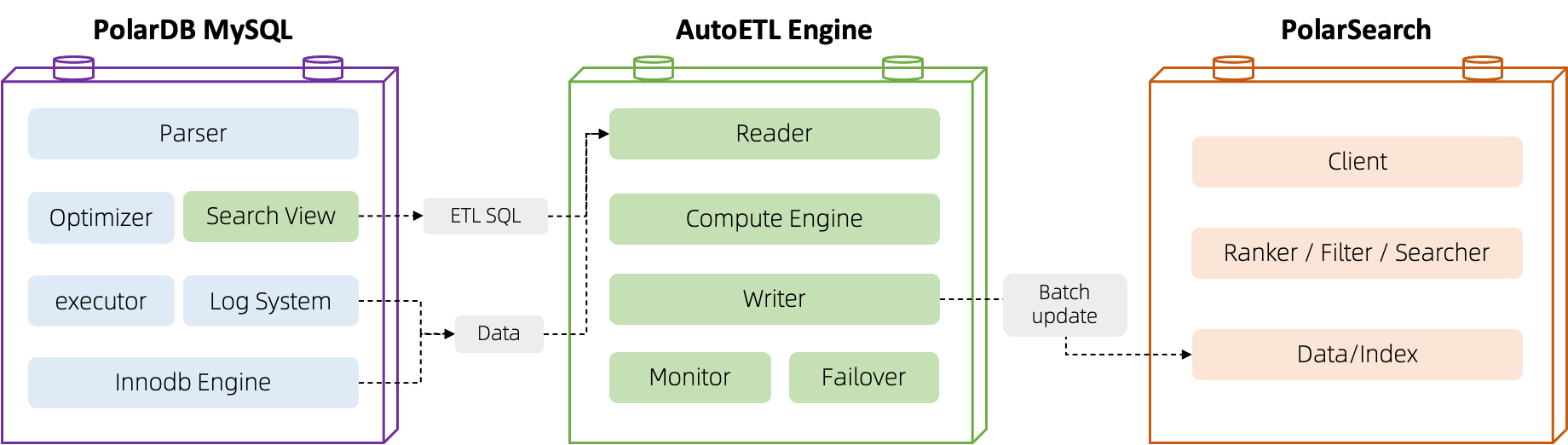
搜索视图(Search View)
PolarDB MySQL 在最新版本正式支持了搜索视图语法,可以通过下面的 SQL 语法,即可在 MySQL 创建搜索视图与 AutoETL 引擎交互,将 MySQL 数据计算并同步到 PolarSearch 节点上。
CREATE
SEARCH VIEW view_name [(column_list, primary key (pk_column_list))]
AS select_statement;
在搜索视图创建后,首先会进入全量读取阶段,AutoETL 引擎会自动读取搜索视图涉及的所有 MySQL 基表数据,写入到 PolarSearch 中。在 PolarSearch 端的索引构建完成后,AutoETL 引擎会持续监听 MySQL 的变更日志,将 MySQL 的变更数据实时写入到 PolarSearch 节点中。
同时,AutoETL 引擎会定期返回视图的延迟数据和错误信息,通过下面的 SQL 语句,我们能看到当前所有搜索视图的状态和复制延迟。
MySQL > show search view status;
+-----------+--------+----------+---------------+---------------------+---------------------+
| View Name | Type | Status | Message | Created_at | Updated_at |
+-----------+--------+----------+---------------+---------------------+---------------------+
| view_1 | search | active | latency:50ms | 2026-03-03 15:13:14 | 2026-03-03 15:13:14 |
+-----------+--------+----------+---------------+---------------------+---------------------+
1 row in set (0.00 sec)
目前搜索视图主要支持数据同步语义,在后续版本中,我们将逐步支持搜索视图的在线读取能力,进一步优化提升用户的检索效率。
高级配置

为了支持更复杂的业务场景,AutoETL 还支持用户进行搜索视图配置,如:
- 在搜索视图中调用用户自定义的数据处理函数(ETL_UDF),使用如 Java SDK 编写更为复杂的计算逻辑;
- 设置写入到 PolarSearch 的分片字段(routing 字段)。
- 对 Json 对象进行自动转化,转换为 object 对象,或者展开到 PolarSearch 的索引字段中。
性能优化
为了提升 ETL 的同步效率,我们针对常见的业务场景进行了优化。
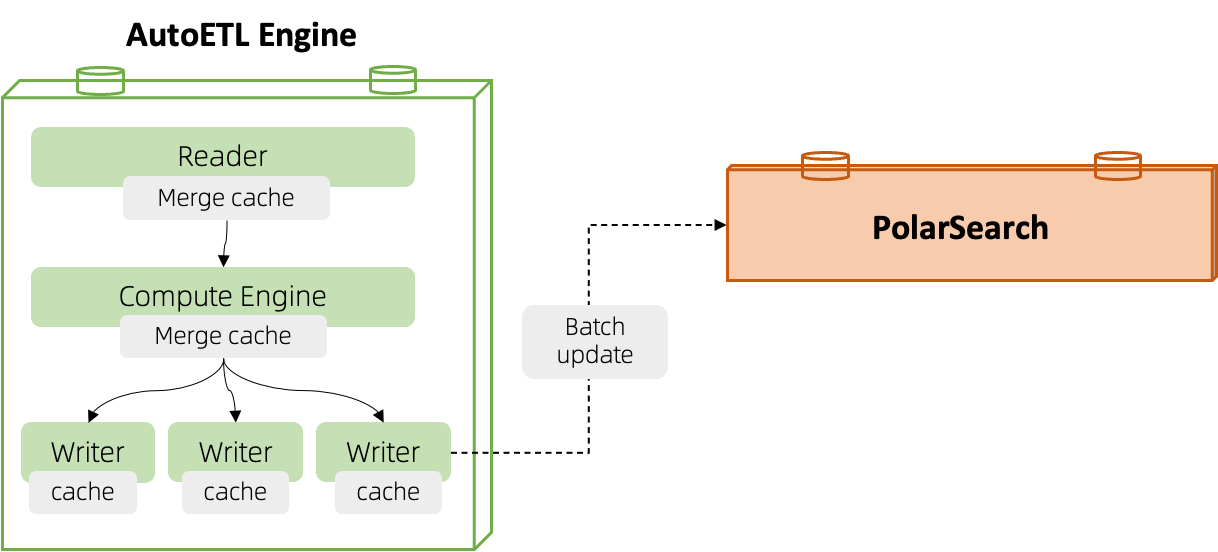
- 修改合并
大多数交易类型的业务场景,数据写入集中在小部分数据集,导致热点数据的修改频率很高。AutoETL 引擎进行了修改合并优化,在一定的时间间隔内,将收集到的更新操作按照搜索视图的主键进行合并,向 PolarSearch 引擎写入合并后的结果,减少写入的频率。
- 批量并发写入
在 PolarSearch 的架构实现上,批量的 bulk 写入更有利于提升写入效率。频繁的小写入请求的执行效率较低,我们使用了批量并发写入的模式,按照时间间隔,写入次数进行积攒,达到阈值后,对写入 cache 的数据采用多个并发请求线程进行批量写入到 Search 引擎中。
测试效果
为了验证 AutoETL 的性能表现,我们使用 sysbench 模拟常见的 OLTP 负载压力,将 5 张表汇聚打宽到 PolarSearch 中。
- 测试环境:
规格选择 8 核 64GB PolarDB 集群。
- sysbench 的源表结构
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1000000 DEFAULT CHARSET=utf8;
- 创建搜索视图,汇聚 5 张表的数据到 PolarSearch 的 ‘merge_sysbench_data’ 索引中。
use sysbench;
create search view merge_sysbench_data(id, k1, k2, k3, k4, k5, c1, c2, c3, c4, c5, primary key(id))
as select t1.id, t1.k, t2.k, t3.k, t4.k, t5.k, t1.c, t2.c, t3.c, t4.c, t5.c
from sbtest1 as t1
left join sbtest2 as t2 on t2.id = t1.id
left join sbtest3 as t3 on t3.id = t1.id
left join sbtest4 as t4 on t4.id = t1.id
left join sbtest5 as t5 on t5.id = t1.id;
- sysbench 压力
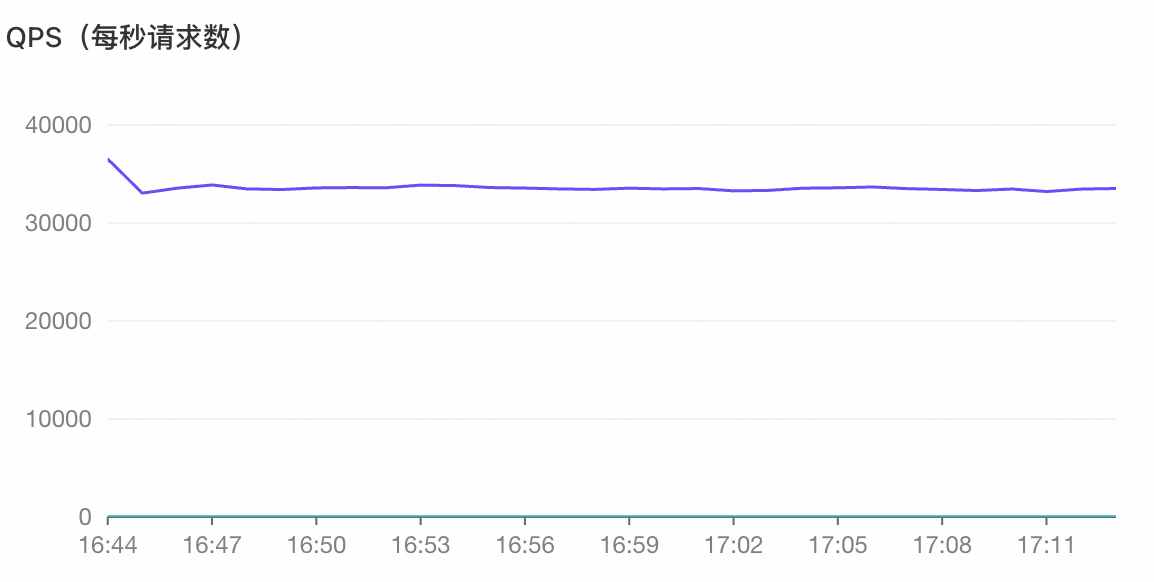
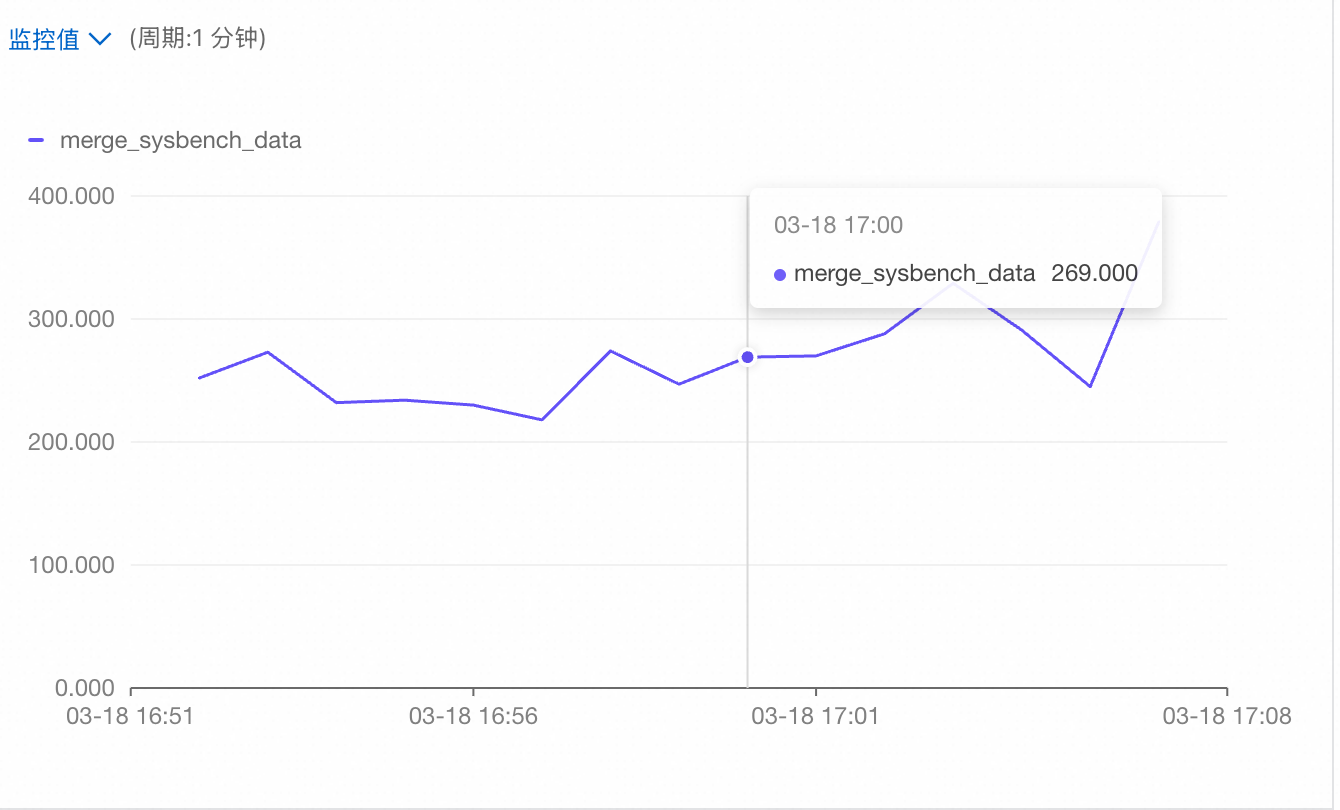
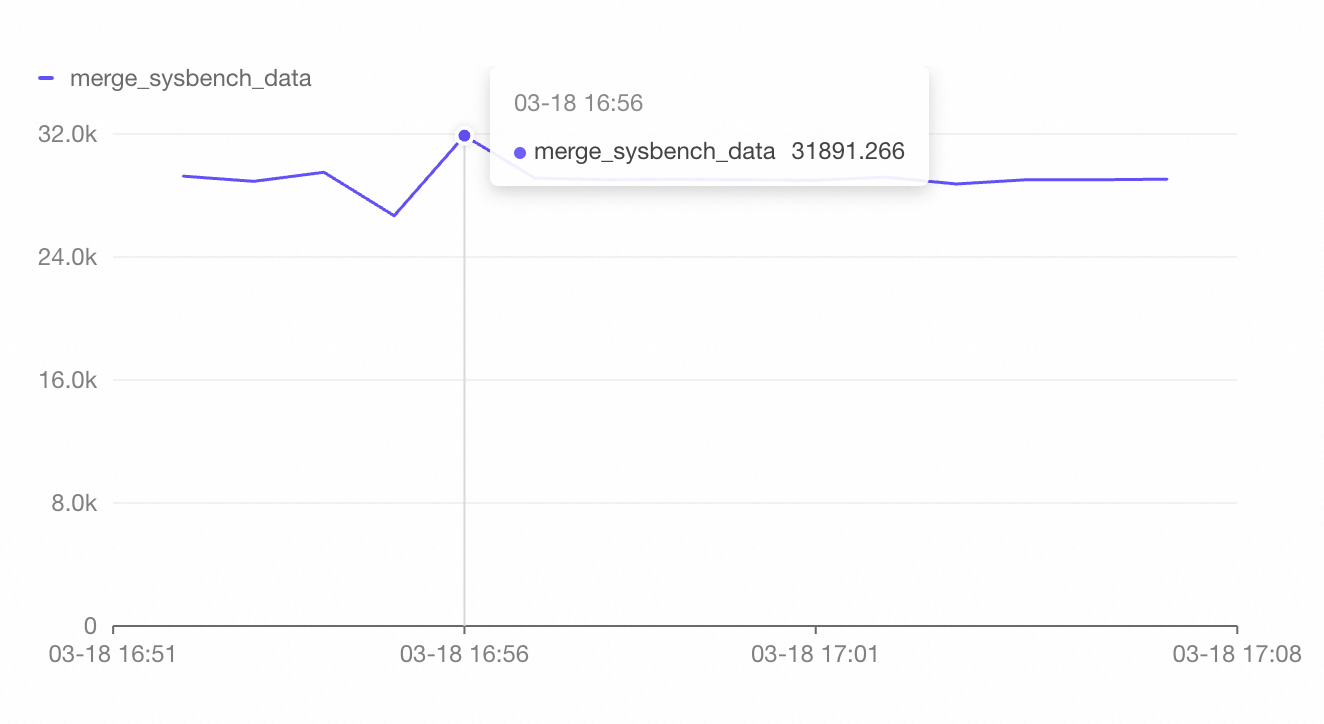
持续随机更新 PolarMySQL 5 张表的一百万行数据。测试 MySQL 并发写入 QPS 在 35000 时,汇聚的 ETL 延迟稳定维持在 250ms。
sysbench oltp_write_only --mysql-host=xxx --mysql-port=3306 --mysql-user=xxx --mysql-password=xxxxx --mysql-db=sysbench --db-driver=mysql --threads=64 --rand-type=uniform --tables=5 --table_size=1000000 --report_interval=1 --time=2000 run
总结
本文介绍了 PolarDB 的一站式智能检索能力,针对交易和检索混合查询需求,在不侵入业务代码、业务无需新增中间组件的前提下,真正实现 “写入即搜、搜即所得” 的端到端闭环。依托 PolarDB AutoETL 能力,以及 PolarSearch 的高性能分布式索引架构。既延续了事务数据库如 MySQL 的易用性与生态兼容性,又具备实时检索、聚合与向量分析能力。在后续版本中,我们将持续增强一站式智能搜索能力,支持端到端的在线读取能力,进一步提升 ETL 性能,支持异构数据源,以及内核级可观测性。欢迎持续关注后续版本更新。