MySQL · 引擎特性 · POLARDB 并行查询加速全程详解
Author: jijunxiang
概述
日前,POLARDB for MySQL 8.0版本重磅推出并行查询框架,当您打开并行查询开关后并且查询数据量到达一定阈值,就会自动启动并行查询框架,从而使查询耗时指数级下降。
在存储层将数据分片到不同的线程上,多个线程并行计算,将结果流水线汇总到总线程,最后总线程做些简单归并返回给用户,提高查询效率。并行查询(Parallel Query)利用多核CPU的并行处理能力,以8核 32G 配置为例,示意图如下所示:
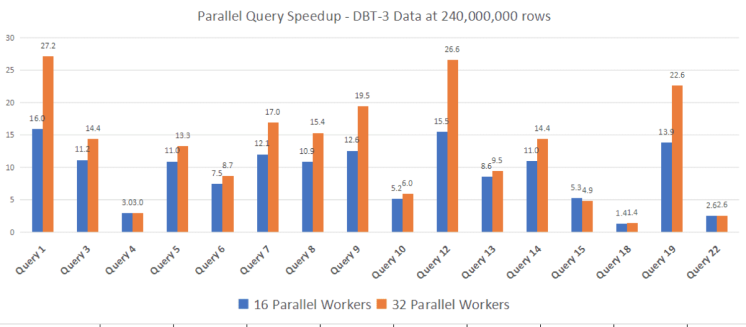
在基于POLARDB 32核256G的环境下,我们进行TPCH 40G的性能测试,设置并行度为32时,TPCH中超过70%的SQL可以得到加速,超过40%的SQL加速比超过10.
背景
无论是MySQL资深DBA还是MySQL小白用户,都面临一个无法解决的难题,随着MySQL数据量的不断增长,查询的响应时间都是指数级的增长。
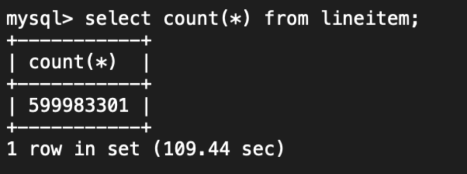
比如最简单的一个表统计行数语句,当表数据达到6亿后,即使在一个32核的空闲MySQL上,查询依旧耗时100多秒。
为什么最简单查询,当数据量大了过后,就会如此之慢。究其重要的原因之一,就是MySQL一直以来都是一个OLTP的数据库,追求的是更高的并发,更短的时延。MySQL的命令执行流程如下图所示:
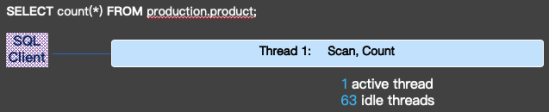
当来了一个请求后,就会分配一个线程服务这个请求。在一个单独的线程中,完成解析,优化,数据读取,执行等等一些操作,中间无多线程间的切换和同步,尤其是等待。
这种设计,在数据量小的时候,系统的效率是最高的。当高并发时, 系统的平均响应时间是最短的。但这种设计,当系统有一定资源空闲时并且数据量大的时候,只有一个线程处理大数据的请求,而其他线程却无法参与其中,无法进行加速。
为了减少查询耗时,无数DBA绞尽各种脑汁,通过各种分库分表,增加索引,大幅增加查询条件等等各种手段,通过这些手段可以减少数据的计算量,从而达到加速查询, 但都回避了一个问题,如何提高数据库的计算能力?
在今天的商业数据库中, 最常用的一种方式,就是利用多线程,对一个大的复杂查询,同时启动多个线程进行查询, 从而达到加速的效果。
设计与实现
架构设计
设计思路:在解析完SQL生成执行plan之前,增加一个hook, 进行判断是否可以并行加速, 如果可以进行并行查询, 则生成并行执行plan, 否则生成串行执行plan。
在并行执行plan中,启动2种线程,一种是worker 线程,负责做各种计算,另外一种是leader 线程,负责将worker 线程的计算结果收集起来,然后做一些不能并行的计算,并最终返回给用户。如下图所示:
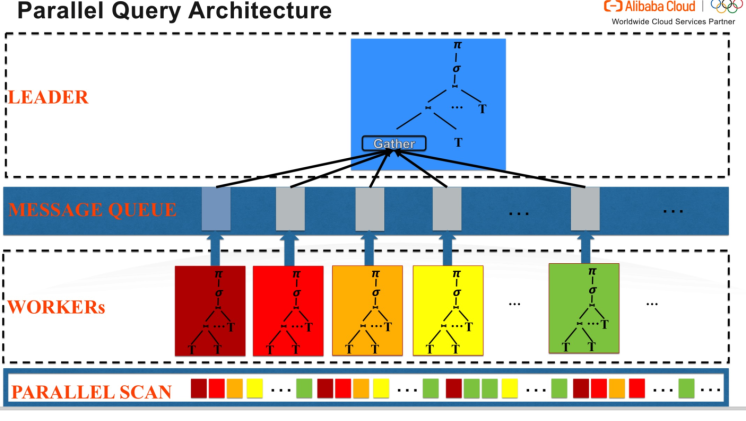
从架构图中可以看到,并行查询主要包含四部分:
- Leader线程就是传统POLARDB的连接线程,它负责生成并行查询计划,协调并行执行过程的其他组件。
- Message queue是leader线程和worker线程的通讯层,worker线程通过message queue向leader线程发送数据,而leader线程也会通过message queue向worker线程发送控制信息。
- Worker线程负责真正的执行任务。Leader线程解析查询语句生成并行计划,然后同时启动多个worker线程进行并行任务处理。worker线程在进行扫描,聚集,排序等操作后将中间结果集返回给leader,leader负责收集来自worker的所有数据集,然后进行适当的二次处理(比如merge sort,二次group by 等操作),最后将最终结果返回给客户端。
- Parallel Scan层是存储引擎要实现并行执行,需要将扫描数据划分成多个分区。如何能够让所有的workers尽可能的均匀的工作是数据分区划分的目标。
并行执行判断
优化器生成串行执行计划后, 需要做的第一件事情,就是判断是否需要进行并行执行, 如果可进行并行加速, 我们在串行计划的基础上生成并行计划:
- 是否打开了强制并行,或者关闭了并行查询开关。
- 表数据量是否大与20000行
- 是否有足够的资源, 线程池中还有足够的计算资源, 并且当前内存还有一定的盈余
- 语法判断, 当前SQL 语法是否可以支持并行, 比如subquery 目前还无法支持
并行读取
在并行查询计算之前, 必须先解决第一个先决条件, 并行扫描, 只有让数据并行读取出来,才能够并行计算。
因此POLARDB 首先制定一个原则, 将表数据进行分片, 分成很多分片, 一个worker线程一个时刻只处理一个分片, worker线程和worker线程之间相互独立, 不会处理相同的分片, 也不会漏掉分片, 另外分片和分片之间不会有重叠。
那如何进行合理并高效的分片呢,Innodb 表是基于B+ 树索引, 可以根据B+ 的节点所指定的范围,进行切分, 如下图所示:
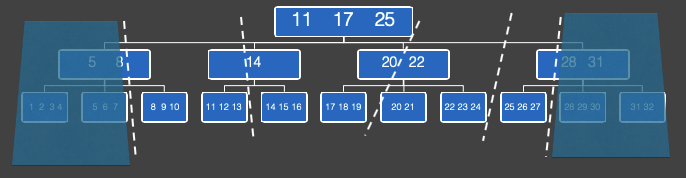
在上图中, 如果切片数设置为6(切片数大于等于并行度), B+ 树自顶向下逐层分析,在第一层中, 只有一个节点, 节点数小于切片数, 因此,不能在这一层进行切片, 向下走一层。
当走到第二层时, 第二层,有4个节点, 节点数小于切片数6, 因此再向下走一层。
当走到第三层时, 有11个节点, 大于切片数, 因此,可以对这一层,进行切分, 每个切片含1个或2个节点。
POLARDB做了一个优化, 为了让线程间工作更加均衡, 切片数会远大于并行度,因此每个切片的数据量会更小, 切片和切片之间不均衡性得到削弱, 另外,当一个线程处理完一个切片后, 会从池子中再取出一个切片进行计算, 从而让每个worker 都处于饱和状态工作。
并行执行
今天并行计算有一点点类似大数据中的MapReduce, 将尽可能多的工作下放到worker线程中进行执行,将汇总的工作留给leader线程。
LEADER
在optimizer生成串行计划之后,我们在串行计划的基础上生成并行计划,包含两部分:
- Leader上需要生成包含Gather(汇总)操作符的执行计划。
- 为Workers生成属于worker自身的执行计划,该计划是从串行的执行计划拷贝而来。
下面对并行执行执行进行简单的描述:
并行聚集
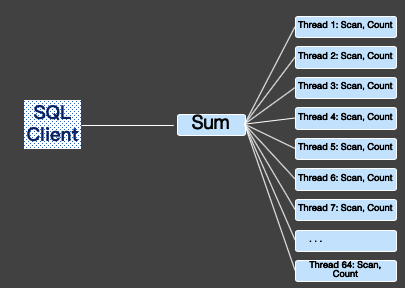
并行查询执行聚集函数下推到worker上并行执行。并行聚集是通过两次聚集来完成的, 比如, 我们最常见的“SELECT count(*) FROM production.product;”操作中: 第一次,参与并行查询部分的每个worker执行聚集步骤(count操作)。 第二次,Gather或Gather Merge节点将每个worker产生的结果汇总到leader(进行sum操作)。Leader会将所有worker的结果再次进行聚集,得到最终的结果。
多表并行连接
并行查询会将多表连接操作完整的下推到worker上去执行。POLARDB优化器只会选择一个自认为最优的表进行并行扫描,而除了该表外,其他表都是一般扫描。每个worker会将连接后的结果集返回给leader线程,leader线程通过Gather操作进行汇总,最后将结果返回给客户端。
比如,我们在最常见的join操作中, “SELECT * FROM t1 JOIN t3 ON t1.id = t3. id;”, 我们会对满足分片的表进行筛选, 选择其中较小的表进行切分, 每个worker 负责一个分片,在worker 线程中, 这个分片负责和其他表进行join。
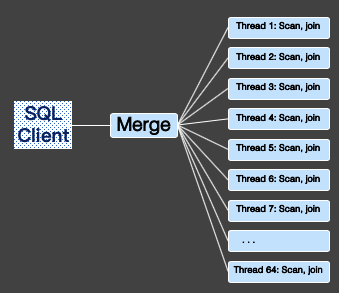
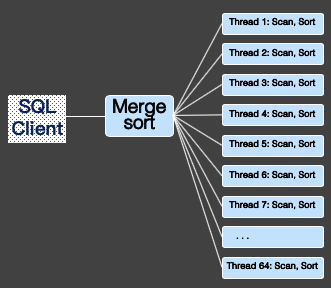
并行排序
POLARDB优化器会根据查询情况,将Order By下推到每个worker里执行,每个worker将排序后的结果返回给leader,leader通过Gather Merge Sort操作进行归并排序,最后将排序后的结果返回到客户端。
比如在最常见的 “SELECT col1, col2, col3 FROM t1 ORDER BY 1,2;”
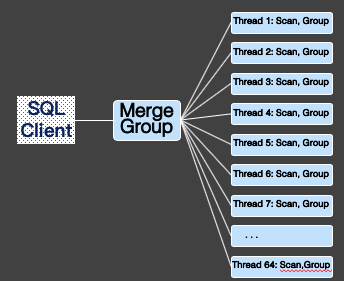
并行分组
POLARDB优化器会根据查询情况,将Group By下推到worker上去并行执行。每个worker负责部分数据的Group By。Worker会将Group By的中间结果返回给leader,leader通过Gather操作汇总所有数据。
这里POLARDB优化器会根据查询计划情况来自动识别是否需要再次在leader上进行Group By,例如,如果Group By使用了Loose index scan,leader上将不会进行再次Group By。否则Leader会再次进行Group By操作,然后把最终结果返回到客户端。
比如在我们常见的“SELECT col1, col2, SUM(col3) FROM t1 GROUP BY 1,2;”
MESSAGE QUEUE
Leader和Workers之间需要通信,Message queue就是为了两者的通信而设计的,它可以实现Leader和Workers之间的信息交换。Message queue的结构如下图所示:
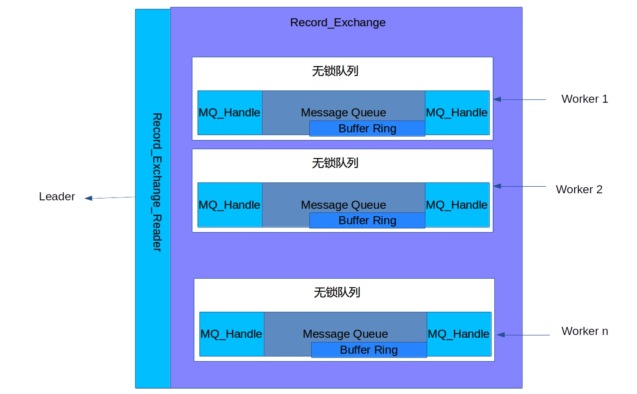
Leader通过调用GatherIterator::Read接口来与Message queue进行通信。Message queue分装了多个无锁队列,每个worker会对应一个队列;worker会将返回结果存放到自己对应Message queue中,当Message queue中的结果未能被Leader及时消费打满时,worker将等待。
WORKERS
Workers上需要实现调用执行器的流程,将需要的结果集返回给Message queue。为了高效的执行查询,Worker上的执行不需要进行再次优化,而是直接从Leader上来拷贝生成好的计划分片。这需要实现POLARDB执行计划树上所有节点的拷贝。 拷贝完成后,需要workers进行执行前的所有准备,比如打开表,初始化所有数据结构,比如让拷贝过来的执行计划树种的节点包含的列重新指到对应的新打开表的列等操作。 为了能让Worker执行拷贝过来的执行计划,也需要准备好官方POLARDB在优化阶段生成的数据结构,比如对GROUP BY操作创建的临时表等逻辑。
性能对比
以TPC-H为例,为您介绍并行查询使用示例。案例中所有示例,使用的数据量是TPC-H中SF=100GB ,使用POLARDB节点规格为88 核 710G的配置在主节点进行测试。
- GROUP BY & ORDER BY支持
- AGGREGATE函数支持(SUM/AVG/COUNT)
- JOIN支持
- BETWEEN函数 & IN函数支持
- LIMIT支持
- INTERVAL函数支持
- CASE WHEN支持
- LIKE支持
GROUP BY & ORDER BY支持
未开启并行查询,耗时1563.32秒,开启并行查询后,耗时只用49.65秒,提升31.48倍。 原始SQL语句,如下所示:
SELECT l_returnflag,
l_linestatus,
Sum(l_quantity) AS sum_qty,
Sum(l_extendedprice) AS sum_base_price,
Sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
Sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
Avg(l_quantity) AS avg_qty,
Avg(l_extendedprice) AS avg_price,
Avg(l_discount) AS avg_disc,
Count(*) AS count_order
FROM lineitem
WHERE l_shipdate <= date '1998-12-01' - INTERVAL '93' day
GROUP BY l_returnflag,
l_linestatus
ORDER BY l_returnflag,
l_linestatus ;
未开启并行查询,耗时1563.32秒。
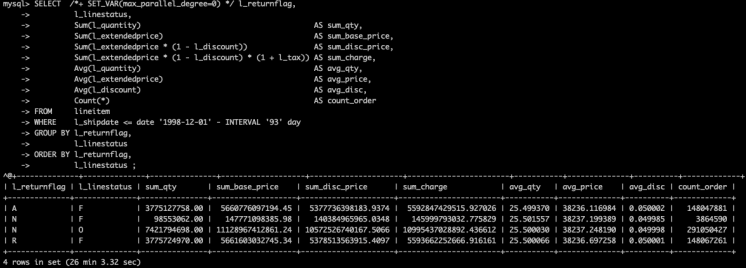
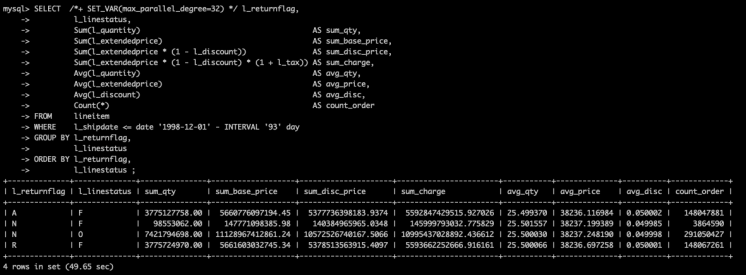
开启并行查询后,耗时只用49.65秒,提升31.48 倍。
AGGREGATE函数支持(SUM/AVG/COUNT)
未开启并行查询,耗时1563.32秒,开启并行查询后,耗时只用49.65秒,提升31.48倍。 原始SQL语句,如下所示:
SELECT l_returnflag,
l_linestatus,
Sum(l_quantity) AS sum_qty,
Sum(l_extendedprice) AS sum_base_price,
Sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
Sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
Avg(l_quantity) AS avg_qty,
Avg(l_extendedprice) AS avg_price,
Avg(l_discount) AS avg_disc,
Count(*) AS count_order
FROM lineitem
WHERE l_shipdate <= date '1998-12-01' - INTERVAL '93' day
GROUP BY l_returnflag,
l_linestatus
ORDER BY l_returnflag,
l_linestatus ;
未开启并行查询,耗时1563.32秒
开启并行查询后,耗时只用49.65秒,提升31.48 倍
JOIN支持
未开启并行查询,耗时21.73秒,开启并行查询后,耗时1.37秒,提升15.86倍。 原始SQL语句,如下所示:
select sum(l_extendedprice* (1 - l_discount)) as revenue
from lineitem, part
where ( p_partkey = l_partkey and p_brand = 'Brand#12'
and p_container in ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG')
and l_quantity >= 6 and l_quantity <= 6 + 10
and p_size between 1 and 5
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON' )
or ( p_partkey = l_partkey and p_brand = 'Brand#13'
and p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
and l_quantity >= 10 and l_quantity <= 10 + 10
and p_size between 1 and 10
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON' )
or ( p_partkey = l_partkey and p_brand = 'Brand#24'
and p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
and l_quantity >= 21 and l_quantity <= 21 + 10
and p_size between 1 and 15
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON' );
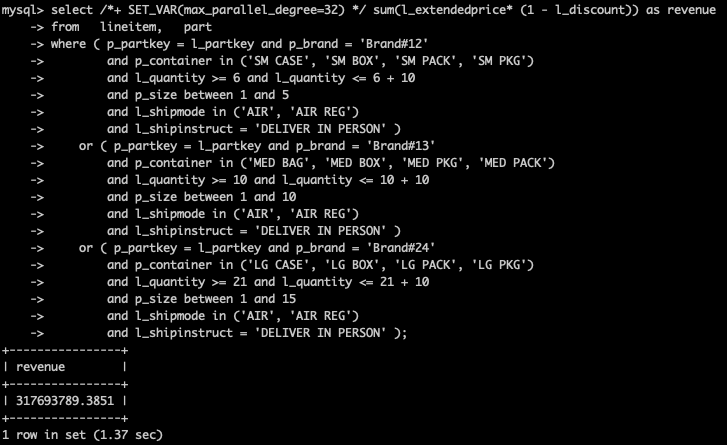
未开启并行查询,耗时21.73秒
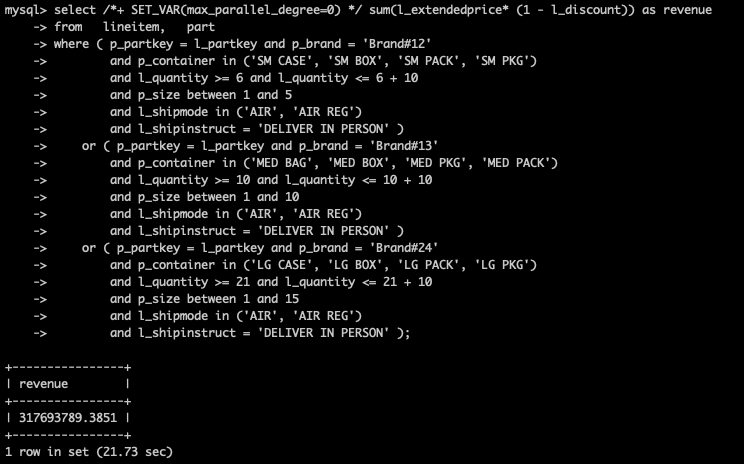
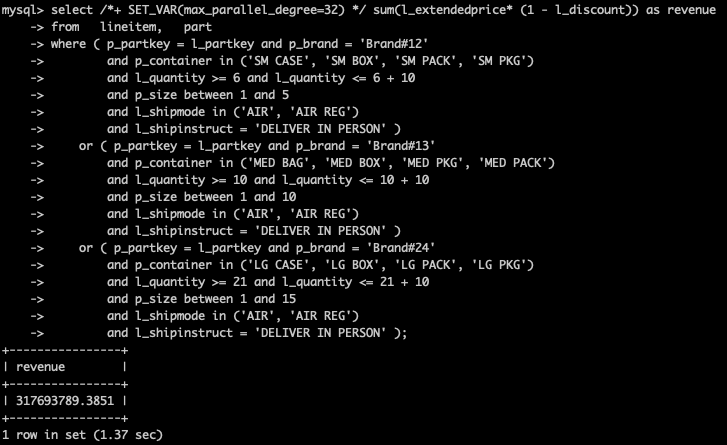
开启并行查询后,耗时1.37秒,提升15.86倍
BETWEEN函数 & IN函数支持
未开启并行查询,耗时21.73秒,开启并行查询后,耗时1.37秒,提升15.86倍。 原始SQL语句,如下所示:
select sum(l_extendedprice* (1 - l_discount)) as revenue
from lineitem, part
where ( p_partkey = l_partkey and p_brand = 'Brand#12'
and p_container in ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG')
and l_quantity >= 6 and l_quantity <= 6 + 10
and p_size between 1 and 5
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON' )
or ( p_partkey = l_partkey and p_brand = 'Brand#13'
and p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
and l_quantity >= 10 and l_quantity <= 10 + 10
and p_size between 1 and 10
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON' )
or ( p_partkey = l_partkey and p_brand = 'Brand#24'
and p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
and l_quantity >= 21 and l_quantity <= 21 + 10
and p_size between 1 and 15
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON' );
未开启并行查询,耗时21.73秒
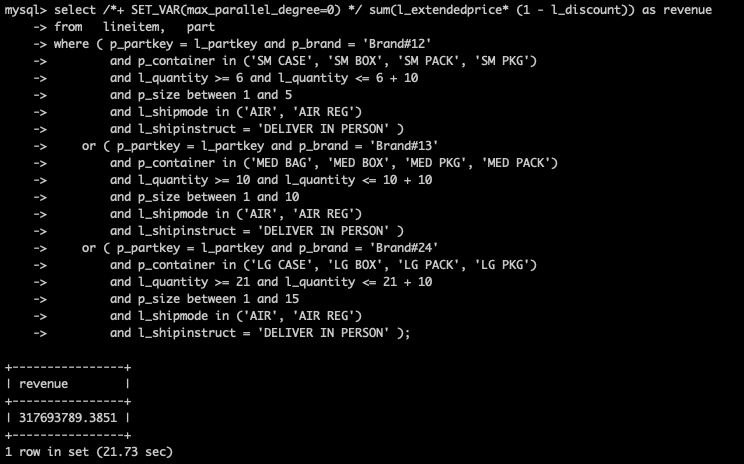
开启并行查询后,耗时1.37秒,提升15.86倍
LIMIT支持
未开启并行查询,耗时339.22 秒,开启并行查询后,耗时29.31秒,提升11.57倍。 原始SQL语句,如下所示:
select l_shipmode, sum(case when o_orderpriority = '1-URGENT' or o_orderpriority = '2-HIGH' then 1
else 0
end) as high_line_count, sum(case when o_orderpriority <> '1-URGENT' and o_orderpriority <> '2-HIGH' then 1
else 0
end) as low_line_count
from orders, lineitem
where o_orderkey = l_orderkey
and l_shipmode in ('MAIL', 'TRUCK')
and l_commitdate < l_receiptdate
and l_shipdate < l_commitdate
and l_receiptdate >= date '1996-01-01'
and l_receiptdate < date '1996-01-01' + interval '1' year
group by l_shipmode
order by l_shipmode limit 10;
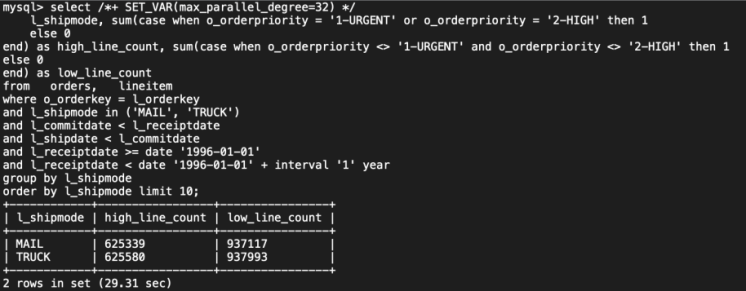
未开启并行查询,耗时339.22秒。
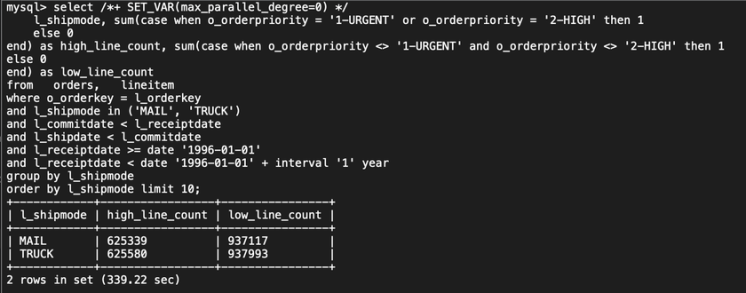
开启并行查询后,耗时29.31秒,提升11.57倍
INTERVAL函数支持
未开启并行查询,耗时220.87秒,开启并行查询后,耗时7.75秒,提升28.5倍。 原始SQL语句,如下所示:
select
100.00 * sum(case when p_type like 'PROMO%' then l_extendedprice * (1 - l_discount)
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
from lineitem, part
where l_partkey = p_partkey
and l_shipdate >= date '1996-01-01'
and l_shipdate < date '1996-01-01' + interval '1' month limit 10;
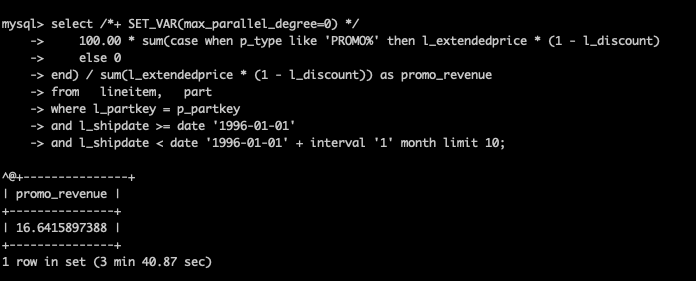
未开启并行查询,耗时220.87秒。
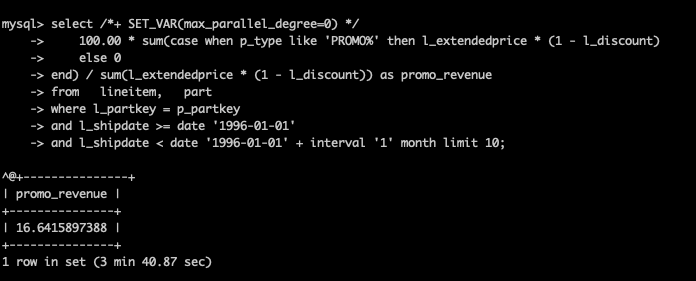
开启并行查询后,耗时7.75秒,提升28.5倍。
CASE WHEN支持
未开启并行查询,耗时220.87秒,开启并行查询后,耗时7.75秒,提升28.5倍。 原始SQL语句,如下所示:
select
100.00 * sum(case when p_type like 'PROMO%' then l_extendedprice * (1 - l_discount)
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
from lineitem, part
where l_partkey = p_partkey
and l_shipdate >= date '1996-01-01'
and l_shipdate < date '1996-01-01' + interval '1' month limit 10;
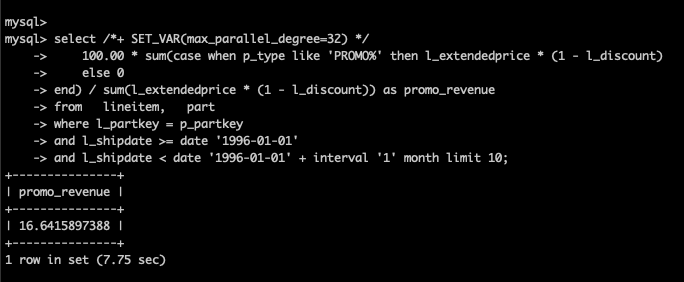
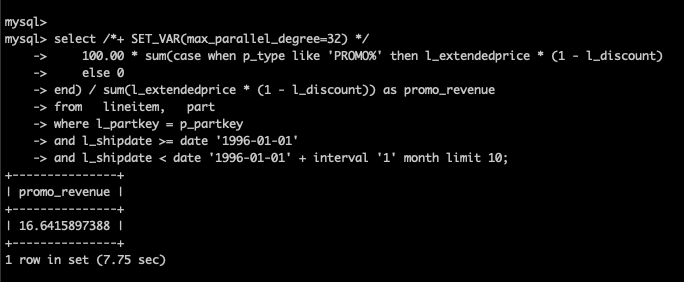
未开启并行查询,耗时220.87秒。
开启并行查询后,耗时7.75秒,提升28.5倍。
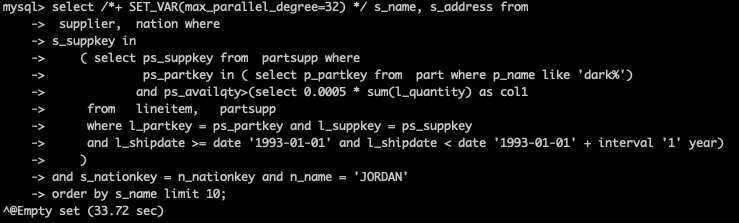
LIKE支持
未开启并行查询,耗时427.46秒,开启并行查询后,耗时33.72秒,提升12.68倍。 原始SQL语句,如下所示:
SELECT s_name, s_address
FROM supplier, nation
WHERE (s_suppkey IN (
SELECT ps_suppkey
FROM partsupp
WHERE ps_partkey IN (
SELECT p_partkey
FROM part
WHERE p_name LIKE 'dark%'
)
AND ps_availqty > (
SELECT 0.0005 * SUM(l_quantity) AS col1
FROM lineitem, partsupp
WHERE (l_partkey = ps_partkey
AND l_suppkey = ps_suppkey
AND l_shipdate >= DATE '1993-01-01'
AND l_shipdate < DATE '1993-01-01' + INTERVAL '1' YEAR)
)
)
AND s_nationkey = n_nationkey
AND n_name = 'JORDAN')
ORDER BY s_name
LIMIT 10;
未开启并行查询,耗时427.46秒
开启并行查询后,耗时33.72秒,提升12.68倍