MySQL · 引擎特性 · InnoDB redo log 之 write ahead
Author: jacketwoo.wxf
1. 背景
现代文件系统对文件的buffer IO,一般是按照page为单位进行处理的。假设page的大小4096字节,当要将数据写入到文件偏移范围为[6144, 8192)的区域,会先在内存里,将对应page cache的[2048, 4096)这个区域的数据修改为新值,然后将对应的page cache,整个的从内存刷到磁盘上。但是如果要写入的文件区域,因为还没有被缓存或者被置换出去了等原因,在内存里不存在对应的page cache,则需要先将对应page的内容从磁盘上读到内存里,修改要写入的数据,然后在将整个page写回到磁盘;在这种情况下,会有一次额外的读IO开销,IO的性能会有一定的损失。
InnoDB内redo log采用的是buffer write,也会遇到这种问题,而且mysql的整体性能对redo log写IO的性能比较敏感,为此InnoDB对该问题做了优化,结合redo log写入是append write的特性,引入了write ahead方法,尝试解决这个问题。主要原理是当某次写文件系统IO满足这两个条件:
a. 该IO的目的地址是文件内的某个page的起始偏移地址;
b. 改IO的数据大小为page大小的整数倍
则该IO的执行,不需要先从磁盘中读出对应page的数据,再做修改和和写入,而是直接将该IO所带的数据作为修改后的数据,缓存在内存里(即page cache),等后续刷盘操作将该page cache写入到磁盘上。这样就避免了额外的读IO开销。
write ahead的原理比较简单,但是InnoDB内的实现比较精炼,不易理解,容易淡忘。所以,本文以MySQL 8.0.12版本代码为参考,注释分析redo log的write ahead的工作机制,以备后续查记;并简单验证该write ahead机制是否有效。
2. redo log write ahead的工作流程
在MySQL 8.0,innodb将redo log的相关操作,按照功能划分成不同的阶段,由不同的线程负责不同阶段的逻辑。在mini transaction的commit阶段,将该mini transaction产生的redo log拷贝到log_sys->buf内,这部分逻逻辑比较分散,可以发生在用户线程内; log_writer线程,负责将全局的log_sys->buf内的redo log写入文件系统,暂时保存在page cache中;log_flusher线程,负责刷盘,将还处在文件系统的redo log写到磁盘上;log_write_notifier和log_flush_notifier线程,负责触发事件,分别提醒log_writer线程和log_flusher线程从等待中开始工作。
redo log的write ahead逻辑发生在log_writer线程内。该线程逻辑的代码入口在log0write.cc:log_writer函数处;它的工作流程比较简单:
- 循环等待条件:log_sys->m_recent_written->m_tail 大于 log_sys->m_written_lsn,条件满足时,说明有新的redo log产生,需要被写入;
- 有新的redo log时,则写redo log到文件系统中。
主路径的调用路径如下:
log_writer
->log_writer_write_buffer
->log_files_write_buffer // redo log的write ahead逻辑发生在这个函数内
下面结合代码分析log_files_write_buffer函数的实现:
//@log_files_write_buffer函数
static void log_files_write_buffer(log_t &log, byte *buffer, size_t buffer_size,
lsn_t start_lsn) {
......
// 该变量为true,表示将redo log直接从log_sys->buf内写入到文件系统;
// 否则,表示需要先将要写入的redo log拷贝到log_sys->write_ahead_buf,
// 然后从log_sys->write_ahead_buf,将redo log写入到文件系统中, 对于后者
// 有两种情况:a. 执行write ahead逻辑;b. 需要对最后一个完整的log block填0。
bool write_from_log_buffer;
// 计算本次redo log IO的大小和判断write_from_log_buffer的值。
// 后面分析其实现。
auto write_size = compute_how_much_to_write(log, real_offset, buffer_size,
write_from_log_buffer);
if (write_size == 0) {
// 如果本次IO大小的计算值为0,表示当前刚好处在正在写入的redo log文件的结尾,
// 需要先切换到下一个redo log文件
start_next_file(log, start_lsn);
return;
}
// 以512个字节为单位,计算并填入每个完整的log block的元信息,
// 如:该log block的有效数据长度、该log block当前对应的checkpoint no,
// 该log block的checksum等。
// note: 这里计算的是完整log block的元信息,不完整的log block后面再做处理。
prepare_full_blocks(log, buffer, write_size, start_lsn, checkpoint_no);
......
if (write_from_log_buffer) {
// 从log_sys->buf,将redo log直接写入到文件系统
// 只需将写入的源端指向log_sys->buf内的正确位置,即
// buffer所指向的地址。
......
write_buf = buffer;
.......
} else {
// 从log_sys->write_ahead_buf将redo log写入到文件系统,
// 同样要讲写入的源端指向log_sys->write_ahead_buf
write_buf = log.write_ahead_buf;
// 先将要写入的redo log从全局log_sys->buf内拷贝到log_sys->write_ahead_buf
// 中, 拷完后,将最后一个不完整的block的结尾区域填0,并填上checkpoint no,
// checksum等元信息。
copy_to_write_ahead_buffer(log, buffer, write_size, start_lsn,
checkpoint_no);
//执行到这里的逻辑,有两种情况:
//a. 当前要写入文件偏移量刚好log_sys->write_ahead_buf当前可以覆盖区域的结尾处
//. (这个地址一般都是page对齐的), 需要做write ahead操作;
//b. 本次IO要写入的redo log量太少,小于一个log block的大小,需要一块额外的buffer
//. 空间,将这块不完整log block的后端区域填0,并计算和填入checksum值等信息。如果直
// 接在log_sys->buf内原地填0,可能会把mtr刚刚拷贝到该区域的log覆盖掉。
// 下面的这个分支判断筛选出情况a.
if (!current_write_ahead_enough(log, real_offset, 1)) {
// 在执行write ahead的情况下,将log_sys->write_ahead_buf内未被有效redo log
// 填充的区域都填0;同时更新write_size的值, 即write ahead buffer的大小
written_ahead = prepare_for_write_ahead(log, real_offset, write_size);
}
}
......
// 当刚才完成的写IO的目标范围的结束偏移(不是有效redo log的结束偏移),不在
// log_sys->write_ahead_buf的当前覆盖范围内,则往后滑动
// log_sys->write_ahead_buf的覆盖范围,以便计算后续的redo log写IO,
// 是否需要执行write ahead,和截断要写入的log数据等操作.
update_current_write_ahead(log, real_offset, write_size);
}
//@log_files_write_buffer->compute_how_much_to_write
// 该函数主要是为了判断当前的redo log写IO,是否需要write ahead,
// 和计算本次IO应该写入的数据大小。
static inline size_t compute_how_much_to_write(const log_t &log,
uint64_t real_offset,
size_t buffer_size,
bool &write_from_log_buffer) {
size_t write_size;
.......
// 如果需要跨文件,则当前IO只写入当前正在写入的redo log文件可以装下的数据;
// 这很容易理解,一般的同步IO都是这么操作的。
if (!current_file_has_space(log, real_offset, buffer_size)) {
......
// 如果已经处在当前正在写入的redo log文件的结尾处,则需要先切换redo log文件;
// 设置当前IO大小为0,来通知上层调用切换到新的redo log文件
if (!current_file_has_space(log, real_offset, 1)) {
.......
write_from_log_buffer = false;
return (0);
} else {
// 设定本次写入IO的数据量为当前redo log文件可以容纳的最大数据
write_size =
static_cast<size_t>(log.current_file_end_offset - real_offset);
......
}
} else {
// 如果不需要跨文件(当前redo log文件可以容纳要写入的log), 则暂时设定
// 写入IO的大小为要写入的log的大小,这个值在后面可能还要受到
// log_sys->write_ahead_buf能够容纳的数据量的限制,而被截断。
write_size = buffer_size;
}
......
// InnoDB的redo log是按照log block进行管理的,一个log block的大小为
// OS_FILE_LOG_BLOCK_SIZE字节,每个log block都有独立的元信息,如log
// block no, checksum等。当某次写redo log的IO要写入的log数据不足一个
// OS_FILE_LOG_BLOCK_SIZE时,该IO准备逻辑需要将该写入数据的对应的log
// block的后端区域填0,然后计算和填入该block填0后的checksum值;但是这
// 不能在全局的log_sys->buf原地做,需要一块额外buffer,否则可能会覆盖后
// 续填入其中的log数据;这里我们将log_sys->write_ahead_buf选为我们
// 的"额外buffer",所以这里当write_size小于OS_FILE_LOG_BLOCK_SIZE时,
// 令'write_from_log_buffer'为false,表示本次写IO数据最后要从
// log_sys->write_ahead_buf写入到文件系统中。
write_from_log_buffer = write_size >= OS_FILE_LOG_BLOCK_SIZE;
......
// 判断当前的write ahead区域,是否可以装得下我们这log IO要写入的数据,如
// 果装不下,则需要截断本次IO要写入的数据;如果当前要写入的文件偏移,刚好处
// 在log_sys->write_ahead_buf当前覆盖覆盖区域的结束位置(一般也是某个
// page的起始或者结束地址处),这个时候,需要采用一次write ahead操作,具体
// 逻辑为:将本次写IO要写入的数据从log_sys->buffer拷贝到
// log_sys->write_ahead_buf内,将log_sys->write_ahead_buf后
// 端未被有效数据填充的区域填0,然后将整个log_sys->write_ahead_buf的
// 内容写入到文件系统中,避免可能出现的一次读IO开销
//
// note. 这里有一个隐藏的假设:
// a. 当某次写IO的目的偏移地址是与log_sys->write_ahead_buf当前覆盖范围
// 的结束地址对齐时,则假定该次写IO目标区域在内存没有对应的page cache,需
//. 要执行一次write ahead操作
// b. 当执行一次write ahead逻辑后,在接下来的一段时间内,该区域对应的page cache
//. 会保存在内存中,后续对当前write ahead buffer可以覆盖的文件区域的
//. 写IO,都可以命中这些page cache, 从而避免额外的读IO开销。
// 上面的假设a和b,真实情况下并不是百分百成立的。
if (!current_write_ahead_enough(log, real_offset, write_size)) {
if (!current_write_ahead_enough(log, real_offset, 1)) {
// 本次写IO的目的地址不在write ahead buffer当前可以覆盖区域内
// 计算write ahead buffer下一个覆盖区域的结尾偏移地址
const auto next_wa = compute_next_write_ahead_end(real_offset);
if (!write_ahead_enough(next_wa, real_offset, write_size)) {
// log_sys->write_ahead buffer的下一个完整的覆盖区域都容纳不了本次
// 写IO的log数据,则将本次IO要写入的数据截断到write ahead buffer的
// 大小;并且不需要再从log_sys->write_ahead_buf写,可以直接从
// log_sys->buf写入到文件系统,减少了一次内存拷贝的开销。
......
write_size = next_wa - real_offset;
......
} else {
// 本次写IO执行write ahead逻辑
write_from_log_buffer = false;
}
} else {
// log_sys->write_ahead_buf的当前覆盖范围容纳不了本次IO要写入的log
// 数据,将本次IO要写入的log数据按照可以容纳的量阶段。
write_size =
static_cast<size_t>(log.write_ahead_end_offset - real_offset);
......
}
} else {
if (write_from_log_buffer) {
// 走到这里,根据上面write_from_log_buffer的赋值逻辑,说明本次IO要写入的log数
// 据是大于一个OS_FILE_LOG_BLOCK_SIZE的,在这种情况下,将写入的log数据按照向下
// 对齐OS_FILE_LOG_BLOCK_SIZE进行截断,这样可以一定概率的避免对最后一个不完整
// block的后面区域填0操作(填0操作,有拷贝到另外一块额外buffer内的开销),因为等下
// 一次IO的时候,这个不完整的block可能又有新的log数据填入,变得完整了。
write_size = ut_uint64_align_down(write_size, OS_FILE_LOG_BLOCK_SIZE);
}
}
return (write_size);
}
总的来说,某次写redo log的IO可能会有以下这四种情况:
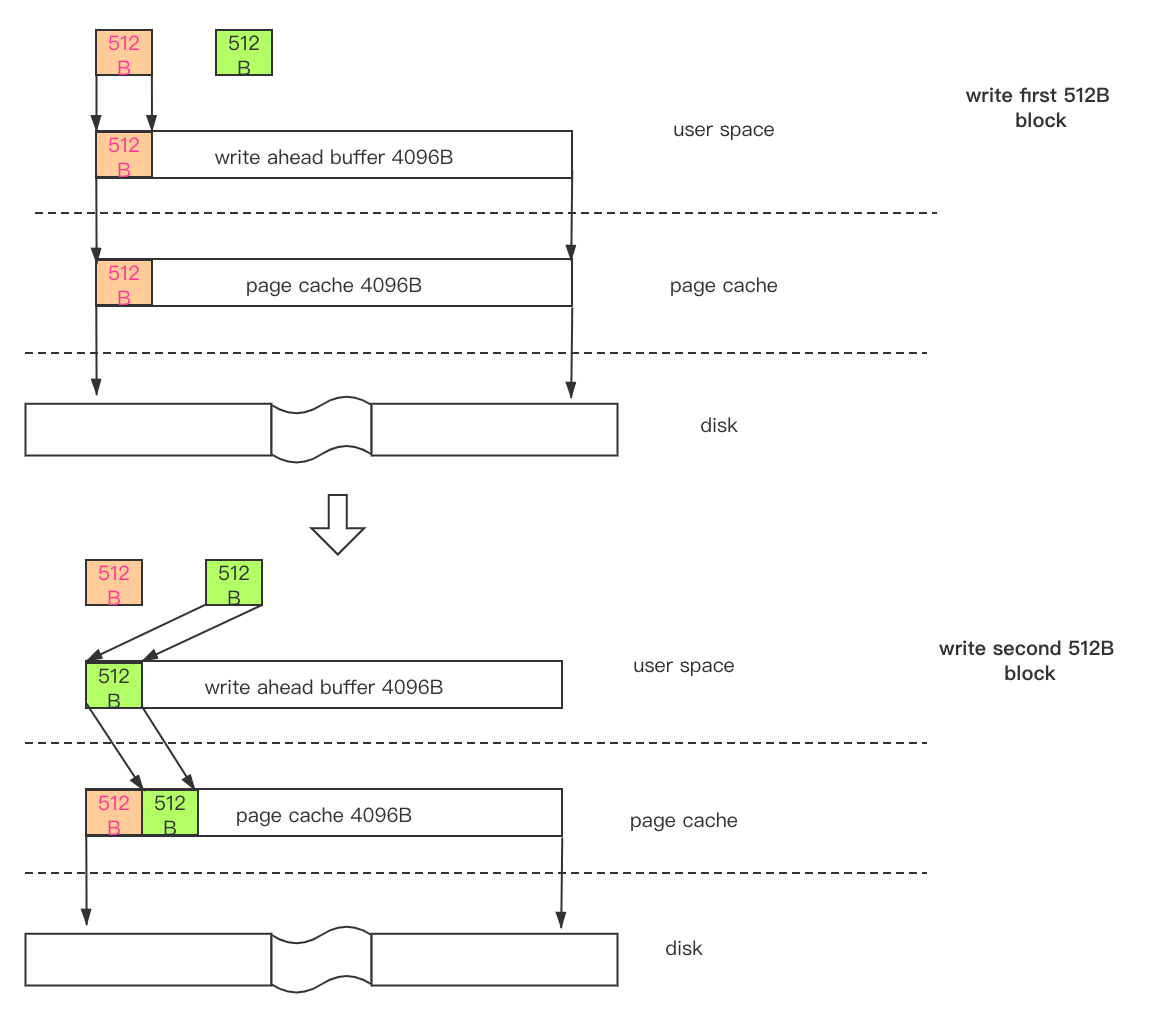
a. 该IO的目标偏移量刚好是log_sys->write_ahead_buf当前可以覆盖区域的结尾处,并且该IO要写入的log数据量小于srv_log_write_ahead_size, 则利用log_sys->write_ahead_buf,执行write ahead逻辑:将要写入的log数据拷贝到log_sys->write_ahead_buf内,对log_sys->write_ahead_buf后端未被有效数据填充的区域填0,然后将整个log_sys->write_ahead_buf写入到文件系统中;
b. 该IO的目标偏移量刚好是log_sys->write_ahead_buf当前可以覆盖区域的结尾处,并且该IO要写入的log数据大于srv_log_write_ahead_size, 则不需要执行write ahead操作。将本次写入IO的数据量截断为srv_log_write_ahead_size大小,直接从log_sys->buf将这srv_log_write_ahead_size大小的数据写入到文件系统中,这样既起到了write ahead操作的作用,也避免了write ahead操作所产生的额外内存拷贝的开销。
c. 该IO的目标偏移量不在log_sys->write_ahead_buf当前可以覆盖区域的结尾处,并且该IO要写入的数据小于一个log block的大小,则不需要执行write ahead 操作,但是需要利用log_sys->write_ahead_buf对这个不完整的log block的后端未填入有效log数据的区域填0,并计算checksum等信息,然后将整个log block从log_sys->write_ahead_buf处写入到文件系统中,这个过程会有一次额外的内存拷贝,从log_sys->buf将要写入的log数据拷贝到log_sys->write_ahead_buf内。
d. 该IO的目标偏移量不在log_sys->write_ahead_buf当前可以覆盖区域的结尾处,并且该IO要写入的数据大于一个log block的大小,则也不需要执行write ahead操作。将本次写入IO的数据大小按下截断到OS_FILE_LOG_BLOCK_SIZE的整数倍,然后从log_sys->buf直接写入到文件系统,这样可以较大概率的避免对最后一个不完整log block的填0操作所引入的开销。
下图可以简要的是示意上面介绍的InnoDB内redo log写IO的情况:
3. 主要的数据结构和参数
a. log_sys->write_ahead_buf
该buffer主要有两个作用:a. 用于redo log的write ahead,先将要写入的redo log从log_sys->buf拷贝到log_sys->write_ahead_buf, 再对log_sys->write_ahead_buf后端未被有效数据填充的区域填0;b. 用于对不完整block的后端区域填0。因为原地填0等操作,可能会覆盖后续填入的有效log数据。
b. 参数innodb_log_write_ahead_size
用于控制log_sys->write_ahead_buf的大小,默认为8092;一般需要设置为内存页大小的整数倍,linux下内存页的大小可通过‘getconf PAGE_SIZE’命令获取,内存页的大小一般为4096字节。
4. 验证write ahead是否有效
附录里有测试的代码,大致的思路是在清空page cache的情况下,按照append write的方式,单线程同步的对一个文件写入1G数据,按两种方式进行对比:a. 普通写入方式,每次写入的数据为512B,直至写完1GB;b. 采用write ahead的方式进行写入,当写入的地址为一个page的起始地址时,则写入一个后端填0的完整page,否则写入512B数据,也是直至写完1GB数据。
对比测试是在同一个物理机的同一块磁盘上进行的(这里就不给出软硬件型号参数了),磁盘采用的是nvme盘;测试前清空缓存。
分别执行如下命令,进行对比
// 命令说明:
// a. 先给tmp.txt写入1G的数据,在进行测试,是为了避免文件第一次写入时,元信息修改产生的影响;
//. b. echo 3 >/proc/sys/vm/drop_caches 用于清空缓存。
// write ahead写入方式,
> dd if=/dev/zero of=./tmp.txt bs=1048576 count=1024 && g++ -O3 -DWRITE_AHEAD append_write.cc -o append_write && echo 3 >/proc/sys/vm/drop_caches && time ./append_write ./tmp.txt
// 普通写入方式
> dd if=/dev/zero of=./tmp.txt bs=1048576 count=1024 && g++ -O3 -DNORMAL_WRITE append_write.cc -o append_write && echo 3 >/proc/sys/vm/drop_caches && time ./append_write ./tmp.txt
跑3次取平均值,结果为:
| 不同的写入方式 | write ahead写入方式 | 普通写入方式 |
|---|---|---|
| 耗时/second | 2.878 | 11.515 |
可以看到在这种方式,write ahead的收益还是很明显的,有差不多4倍的收益。
结论: 在page cache不命中的情况下,采用write ahead的方式进行写入的优化效果还是很明显的。
##附:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <errno.h>
#include <stdint.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
char filepath[128];
uint32_t len_per = 512;
char buf[4096];
char buf2[4096];
const uint64_t file_size = 1024*1024*1024*1ul;
const uint64_t block_size = 4096;
void usage() {
fprintf(stderr, "usage:\n\t./append_write filepath [len_per]\n");
}
int main(int argc, char* argv[]) {
if (argc > 3) {
usage();
return -1;
}
strcpy(filepath, argv[1]);
if (argc == 3) {
len_per = atoi(argv[2]);
}
int32_t fd = open(filepath, O_RDWR);
if (fd == -1) {
fprintf(stderr, "create new file failed, errno: %d\n", errno);
return -1;
}
fprintf(stderr, "start writing...\n");
for (uint64_t sum = 0; sum < file_size; sum += len_per) {
#ifdef WRITE_AHEAD
if (sum % block_size == 0) {
memcpy(buf2, buf, len_per);
memset(buf2+len_per, 0, block_size - len_per);
if (pwrite(fd, buf2, block_size, sum) != block_size) {
fprintf(stderr, "write failed, errno: %d\n", errno);
close(fd);
return -1;
}
} else if (pwrite(fd, buf, len_per, sum) != len_per) {
fprintf(stderr, "write failed, errno: %d\n", errno);
close(fd);
return -1;
}
#elif defined(NORMAL_WRITE)
if (pwrite(fd, buf, len_per, sum) != len_per) {
fprintf(stderr, "write failed, errno: %d\n", errno);
close(fd);
return -1;
}
#endif
}
fprintf(stderr, "finish writing...\n");
close(fd);
return 0;
}