Database · 理论基础 · 高性能B-tree索引
Author: lefeng
1. 前言
在关系型数据库系统(RDBMS)中,索引是一个重要组成部分,其主要作用是提升查询性能,侧重OLTP的关系型数据库常用的索引大致可以分为两大类:
- 基于树(tree-based)的B-tree索引。B-tree索引(这里B-tree代表B+-tree)适合以块或者页为单位的存储,支持高效的点查询(point query)和范围查询(range query),在数据库中已经广泛使用。
- 基于哈希(hash-based)的哈希索引。哈希索引更适合建在内存中,仅支持点查询,更多使用于内存数据库中,如MS SQL Server Hekaton, SAP ASE In Memory Row Store等。
目前主流数据库产品大都支持B-tree索引, B-tree索引的设计和实现至关重要,直接影响整个数据库系统的性能,本文主要关注高性能B-tree索引在数据库中的设计和实现。
B-tree是一个经典的数据结构,网上关于它的介绍很多,这里不再赘述,下面仅列出一些关键特性以及一个示意图,以帮助更好理解本文接下里的内容,
-
包含根结点,非叶节点和叶子节点
-
每一个节点存放在某个固定大小的连续存储空间上,称为索引页
-
非叶子节点仅存放查询导向信息
-
叶子节点存放<key, record_id>信息,且按照顺序存放(便于二分查找)
-
所有叶子节点双向连接(便于前向或后向范围查询)
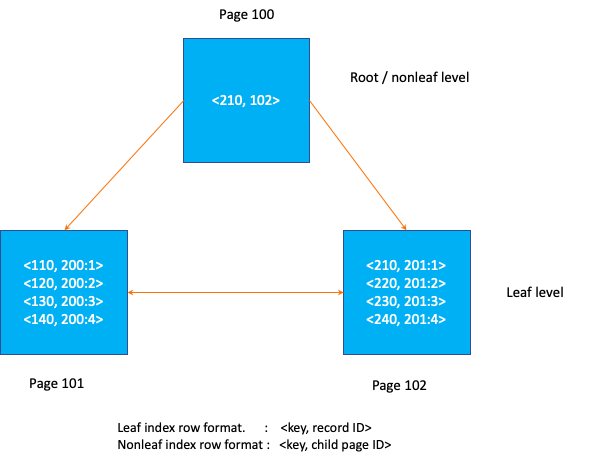
B-tree本身并不复杂,实现起来也不是特别困难,这方面的资料有很多,这里不对其细节过多讨论。
本文要重点介绍的是,如何从高性能数据库的角度去设计一个 1)保证原子性 2)能够高效恢复 3)且支持高并发的B-tree索引,因为这里需要考虑的情况更多且更复杂,比如,
- 如何加锁才能支持高并发?
- 如何对索引页进行更改才能使对并发任务的影响最小化?
- 如何记录日志才能保证系统发生故障时能够高效地恢复?
- 如何保证没有提交的SMO操作在系统发生故障的时候能够恢复到一致性状态?
- 如何保证已经提交的SMO操作不会因事务的失败而回滚?
- 如何保证索引遍历遇到了正在进行SMO操作的索引页也依然能正常工作(而非阻塞)?
- 如何保证事务T1插入到页P1而后又被SMO操作移动到页P2上的数据能够回滚?
这都是一些非常典型的问题,当然,设计一个支持高并发的高性能B-tree索引要考虑和解决的问题远不止这些,针对这些问题,不同的数据库厂商(产品)可能会给出不同的答案。本文基于数据库的基础理论知识(ARIES / IM),并参考SAP ASE数据库的相关资料,对上述问题进行简单解答。
2. 锁同步
锁是并发任务同步的常用方式,锁的粒度越大,持续时间越长,系统越容易实现,但是会影响并发。
为了在数据库系统中支持高并发,数据部分可以选择使用行锁(row lock)来实现事务的隔离,而B-tree索引部分则使用latch,latch类似于mutex,是一种更加轻量级的锁,分为shared和exclusive两种模式,有如下特点,
- 持有时间短。Reader或writer操作一个索引页前先加latch,操作完后立即释放(Transactional lock则要等到transaction commit/rollback之后才会释放);
- 只保证物理一致性(physical consistency)。Reader加latch(shared latch)后从索引页读到的数据是可信赖的,writer加latch(exclusive latch)后能保证此刻只有自己能够修改索引页;
- 不保证逻辑一致性(logical consistency)。Writer对索引页的修改结束后立即释放latch,最新修改在latch释放后对其他事务立即可见;
- 无死锁检测。使用者需要自己定义加锁顺序以防止死锁,同时,单个任务同时持有的latch数量是有限的。
从实现角度来讲,由于latch是针对单个索引页的,可以把存放latch状态信息的控制块(control block)放在索引页对应的在缓存页中,这样一来,不但能够快速访问给定缓存页的latch状态信息,而且申请和释放latch的操作更高效(不需要为latch控制块分配或释放内存)。
3. Ladder locking
B-tree索引的遍历是个自上而下的操作,一般是从根节点开始,逐层向下遍历,直到找到一个符合条件的叶子节点。
其他一些索引操作,如索引页分裂和索引页删除(统称为SMO – Structure Modification Operation),则是自下而上的,这样一来,就非常容易发生死锁。
避免死锁的一种常用方法是,规定加锁的次序,B-tree索引也使用了这种方法,加锁方向为,自上而下(遍历),从左到右(范围查找)。
对与自上而下的遍历,加锁采用ladder locking (又叫lock coupling)的方式,顾名思义,类似于我们下梯子的过程,即,刚开始两只脚都在第一层,一只脚先下到第二层,等站稳后,另外一只脚离开第一层,以此类推,直至到达目标层。
基于这种方式的B-tree索引遍历过程如下,
- 先对根节点加latch,从根结点读取数据并找到下一层的叶子节点(即孩子节点);
- 对下一层的孩子节点加latch,成功后,释放父节点上的latch;如果无法立即获得孩子节点上的latch,等待,直到加latch成功,才能释放父节点上的latch。
- 重复此操作,直到到达叶子层节点。
这个方法容易理解且易于实现,遍历过程中最多同时对2个索引页加锁,加锁范围小,减少了对其他任务的影响,有利于支持高并发。
4. 逻辑删除(logical delete) vs 物理删除(physical delete)
删除一条数据之前,需要先删除其对应的索引项(index entry),大致过程是,首先遍历索引,找叶子层的目标索引页(加exclusive latch),然后从该索引页上删除对应的索引项。
这里需要考虑的一个问题是,为了有效利用空间,是否可以直接把该索引项物理删除,以便立即释放其占用的空间?
在支持行锁和高并发的数据库系统中,一般不做物理删除,更常用的方法是逻辑删除,便于高效地支持事务,即,删除操作仅在索引项上设置一个deleted或invalid标签,待事务提交后,空间清理由其它异步的任务来做(比如在有些系统中,House Keeper任务会做page compact)。之后,如果其他事务扫描到该索引项,将根据自己的事务隔离级别(transaction isolation level)和索引项的状态(执行删除操作的事务是否已提交)执行相应的操作(忽略该索引项或者锁等待)。
总体来讲,逻辑删除有如下一些好处,
- 简单高效。仅设置状态位,无其他不必要的数据移动;
- 简化并发控制。不需要调整其他索引项的存储位置,减少了对并发任务的影响;
- 保证事务正常回滚。被删除的数据行依然处于加锁(transactional lock)状态,直到事务提交才释放,其对应的索引项(处于逻辑删除状态)所占用的空间得以保持,如果事务回滚,不需要重新分配空间,能够快速完成回滚。
5. SMO和Nested Top Action
SMO(Structure Modification Operation)包括索引页的分裂(split)和删除(shrink),这类操作涉及多个步骤,我们希望其具有“原子性”,并且一旦完成,不应随着整个事务的失败而回滚。下面以索引页分裂操作为例,介绍下背后的原因。
插入一个新索引项(index entry)时,会首先遍历索引找到目标索引页,如果该索引页上的剩余连续空间已经不足以容纳下要插入的索引项,该索引页就需要分裂,腾出空间,大致过程如下,
- 分配一个新的索引页
- 移动目标索引页上的部分索引项(分裂点后面的所有索引项)到新索引页
- 连接新分配的索引页到目标索引页后面(修改相邻索引页的prev/next指针)
- 在上一级索引页(父节点)中添加指向新索引页的索引项,如果上一级索引页没有足够空间,继续分裂,直到受影响的非叶子节点完成更新。
可以看到,
- 分裂操作的代价是相对比较大的,如果数据插入过程触发较多索引页分裂,将会影响性能;
- 并且,如果分裂后的索引页由于触发分裂的事务的失败而回滚,接下来的数据插入可能会再次触发索引页分裂,带来不必要的开销;
- 更为严重的是,还可能发生数据丢失,考虑如下的情况,

事务T1在插入数据的过程中,导致索引页P1发生分裂,新索引页P2被分配出来,分裂完成后,事务T2插入的数据4保存在了P2上,此时事务T1回滚,如果索引页分裂过程回滚,索引页P2的分配将会回滚,导致P2上的所有数据丢失。
可见,索引页分裂的最终结果不应该依赖外层事务的状态,如果分裂失败,需要遵循正常的逻辑回滚整个事务(包括触发索引页分裂的事务),一旦分裂过程完成,即使后面整个事务失败回滚,已经完成的索引页分裂也不应该回滚。
Nested Top Action
为了解决这个问题, ARIES提出了Nested Top Action,其论文中对Nested Top Action的描述如下,
A nested top action, for our purposes, is taken to mean any subsequence of actions of a transaction which should not be undone once the sequence is complete and some later action which is dependent on the nested top action is logged to stable storage, irrespective of the outcome of the enclosing transaction.
A transaction execution performing a sequence of actions which define a nested top actions consists of the following steps:
(1) ascertaining the position of the current transaction’s last log record;
(2) logging the redo and undo information associated with the actions of the nested top action;
(3) and on completion of the nested top action, writing a dummy CLR whose UndoNxtLSN points to the log record whose position was remembered in step (1).
ARIES提到,在nested top action结束的时候,写一条dummy CLR日志,它的UndoNxtLSN指向nested top action开始前的最后一条日志,这样一来,在外层事务回滚的时候,会读到该dummy CLR日志,取出UndoNxtLSN,然后跳转到nested top action开始前的日志,继续回滚。
同样使用了nested top action的概念,SAP ASE的处理则稍有不同,大致包括,
- SMO的所有日志会被包含在一对begin_top_action和end_top_action之间
- end_top_action表示SMO操作已结束,事务已提交
- 对于已提交的SMO操作,回滚过程将忽略begin_top_action和end_top_action之间属于该SMO的日志。
SAP ASE基于nested top action的索引页分裂过程大致如下,
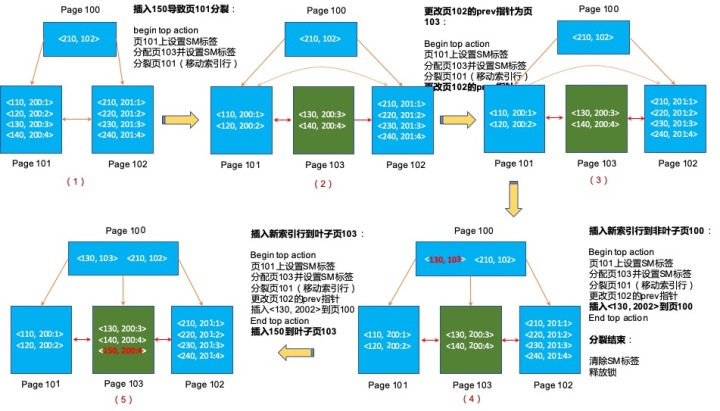
6. SMO和并发
SMO包含一系列操作,在触发SMO的事务提交之前,其它事务可能会访问受SMO影响的索引页,为了支持高并发,SMO采用自底向上的方式(从叶子节点到非叶子结点)。为了避免死锁,需要先释放叶子层节点上的latch,然后从根节点遍历,按照ladder locking的方式找到父节点并进行相应修改(增加或删除index entry)。这里有一个窗口,在释放了叶子层节点上的latch之后,但是找到需要修改的父节点之前,如果一个任务正在遍历索引且正好访问到其父节点,继续往下遍历的时候将可能找不到对应的记录(比如,被移动到了新分裂出来的索引页上),这就是索引的不一致状态(参考图3中的步骤(3))。
ARIES / IM 提出使用exclusive tree latch解决这个问题,即,SMO开始前对当前索引加exclusive tree latch,并在所有受SMO影响的索引页上设置SM标记 (SPLIT或SHRINK),以便其它访问这些索引页的任务能够知道SMO操作正在进行。一旦SMO结束,清除之前设置的SM标记,并释放exclusive tree latch。
ARIES / IM 提到,对于并发的遍历,插入和删除操作,当遍历索引的时候,如果遇到了受设置SM标签的索引页,需要尝试加shared tree latch,如果无法获得,说明SMO操作尚未结束,需要等待,直到SMO操作结束,这样做的原因是,
- 对于插入和删除操作,如果允许它们对未完成的SMO影响的索引页进行修改,然后,执行插入和删除操作的事务提交,如果SMO失败回滚,之前已提交的修改将会丢失;
- 对于遍历操作,如果一个非叶子节点的孩子节点正在进行SMO操作,从非叶子节点中得到的导向信息将是不可信的(参考上面提到的不一致状态,对于分裂操作,可能目标索引项在新分配的索引页上,而非叶子节点却指向正在分裂的索引页)。
虽然tree latch能够解决这个问题,但是其粒度较大,对高并发不友好。
SAP ASE则使用了一些更加巧妙的思路,包括,仅在受SMO影响的索引页上加address lock(基于缓存页地址加锁),且支持在这些索引页上做查询(即使SMO未完成),
- 对于索引页分裂操作,仅对当前分裂的索引页和新分配的索引页加锁;
- 对于索引页删除操作,仅对要删除的索引页和其前向页加锁);
- 对于正在分裂的索引页,如果在当前页未找到符合条件的索引行,会查询其右邻居节点,继续遍历(到孩子节点层),直到找到目标索引行(类似于B-link tree)。
这样一来,大大减小了加锁粒度,能够在一个索引上同时支持多个SMO和查询操作,提升了对高并发的支持。
7. 日志和恢复(logging and recovery)
这里所讨论的日志和恢复基于商业数据库中广泛使用的ARIES (WAL based)。
日志(logging),可以分为两大类,逻辑日志和物理日志。
物理日志,侧重数据修改在存储层的表示,比如,受影响的数据在数据页上的偏移量(offset),以及数据的拷贝。对于有些操作,比如更新操作(UPDATE),甚至还需要包含修改前后的两份数据。所有操作(包括page compact)都需要记录日志,产生的日志量较大。
逻辑日志,侧重修改数据的逻辑操作,受影响的数据所在的位置是无关紧要的。比如,对于一条数据行的插入,只需要记录插入的数据,而不需要记录具体插入到了哪个数据页的什么位置。Page compact是没有意义的,所以不需要写日志,虽然日志数量减少了,但是基于这种方法的恢复更加复杂,商业数据库很少使用这种方案。
上述两种方案的优缺点都比较明显,主流数据库更多采用的是Physiological logging,这种方案是物理日志和逻辑日志两种方案的综合,大致思想是,“physical to a page, logical within a page”,日志里面记录数据所在的页面号和行号,不需要记录页内偏移量。这样一来,即使数据在页内发生移动,也不会影响recovery,触发page compact的时间点也更加灵活。
下面是一个简单的例子,给出了一个事务中执行的SQL语句,以及生成的日志(基于未创建索引的数据表)。

恢复,包括runtime rollback和restart recovery,ARIES在其论文中对recovery的过程做了详细的阐述(restart recovery复杂些,包括analysis,redo和undo阶段),由于内容较多且简单易懂,这里不再赘述,接下来我们看一个有意思的索引操作的回滚场景。
一般情况下,恢复的过程比较直接,给定一条日志,获得里面记录的页面号和行号,读取该数据页,在对应的数据行上做redo或者undo。但是对于索引页,这种方法在有些情况下是行不通的,请看下面的场景(为了便于说明,这里略去了数据部分的日志,仅包含索引部分的日志),

插入4的时候导致索引页100分裂,索引页101被分配出来,4插入到了索引页101上,分裂过程结束。接下来,外层事务回滚,倒序扫描日志并逐个回滚,
- INSRT <page 101, row 2, value 4>
回滚:读取页101,把第二行设置为删除状态(logical delete)
- End_top_action
回滚: 已提交的SMO操作,忽略所有该事务的日志,直到begin_top_action.
- INSERT <page 100, row 3, value 3>
回滚:读取页100,但是发现最大行号是2,无法找到row 3。
在这种情况下,原始的数据插入位置由于索引页分裂会发生变化,导致数据插入时产生的日志中记录的位置信息失效,所以对于索引来讲,这些记录的位置信息是不可靠的。
为了解决这个问题,ARIES / IM 采用了逻辑回滚(logical undo)的方法。例如,在回滚日志 INSERT <page 100, row 3, value 3> 的时候,使用日志中记录的值3作为搜索条件,查找B-tree索引,在 <page 101, row 1> 中找到目标行,然后进行删除。
同样道理,在restart recovery的redo阶段也使用同样的方法重做B-tree上的改动。
8. 结束语
本文简单介绍了设计和实现支持高并发的高性能B-tree索引所要考虑的一些问题,以及业界部分数据库厂商使用的解决方案,随着新技术和新硬件的出现(如NUMA架构,多核CPU和闪存),一些数据库厂商提出了提升B-tree索引性能的新思路,如latch free B-tree, cache-line friendly B-tree等,比较有代表性的有MS SQL Server的Bw-tree,其使用latch free的方式对index page进行delta update,消除了因加latch引起的开销(index page contention,cache line invalidation等)。
参考文献
- C. Mohan, Don Handerle. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging.
- C. Mohan, Frank Levine. ARIES/lM: An Efficient and High Concurrency index Management Method Using Write-Ahead Logging.
- Goetz Graefe. A Survey of B-Tree Logging and Recovery Techniques.
- Goetz Graefe. A Survey of B-Tree Locking Techniques.
- Database system with methods providing high-concurrency access in B-Tree structures. https://patents.google.com/patent/US6792432B1/en.