MySQL · 内核特性 · Link buf
Author: zhuyan
目的
8.0 中使用 link buf 管理并发写 redo 时如何获取到连续的 lsn,在 log_writer 线程中才能把这段对应的日志刷到文件系统 page cache 中。
代码文件:storage/innobase/include/ut0link_buf.h
参数
innodb_log_recent_written_size
分析
初始化
capacity 表示 link buf 能够管理的无序范围。比如有多个 mtr 并发的写入,其对应的 LSN 如下:
mtr1: [4096 ~ 5096]
mtr2: [5097 ~ 8022]
mtr3: [8022 ~ 8048]
mtr4: [8049 ~ 9033]
假如 capacity 是 4K,那么能够处理的 max(LSN) - min(LSN) = 4K. 因为每一个 LSN 都要 HASH 到 link_buf 的一个数组中。而 capacity 就是数组的大小。数组元素的类型由 Position 决定。
template <typename Position>
Link_buf<Position>::Link_buf(size_t capacity)
: m_capacity(capacity), m_tail(0) {
if (capacity == 0) {
m_links = nullptr;
return;
}
ut_a((capacity & (capacity - 1)) == 0);
m_links = UT_NEW_ARRAY_NOKEY(std::atomic<Distance>, capacity);
for (size_t i = 0; i < capacity; ++i) {
m_links[i].store(0);
}
}
初始化后:
m_link[capacity] 其中每一个值都是 0
添加元素
多个 mtr 写 redo log 的时候会去 reserve 一段连续的空间,如初始化部分介绍,mtr 的起始和结束的 LSN。添加到 link buf 中
template <typename Position>
inline void Link_buf<Position>::add_link(Position from, Position to) {
ut_ad(to > from);
ut_ad(to - from <= std::numeric_limits<Distance>::max());
const auto index = slot_index(from);
auto &slot = m_links[index];
ut_ad(slot.load() == 0);
slot.store(to - from);
}
根据 from ,也就是起始的位置寻找到 m_link 数组中的一个位置。算法比较简单,对 capacity 取模即可,因为要保证一个并发空间内的起始 LSN 取模唯一,所以 capacicy 会限制并发空间。
template <typename Position>
inline size_t Link_buf<Position>::slot_index(Position position) const {
return position & (m_capacity - 1);
}
假如 mtr1 和 mtr 3 先加入 link buf:
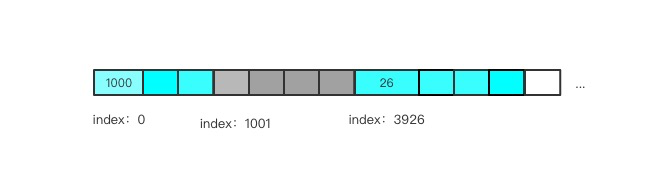
mtr1 落到 index 0 的位置,在这个数组元素中写入 mtr1 的 数据长度,也就是 LSN 区间大小,是 1000. 同样 mtr3 也落到 index 3926 的位置,写入区间大小,26。数组的其余位置都为 0。
寻找连续
上面添加完元素之后,其实 mtr1 和 mtr3 的 LSN 是接不上的,因为 mtr2 还没并发的写到 redo log buffer 中,因为不能最多只能刷盘的 mtr1 的 end LSN。Log writer 线程会在刷盘的时候通过 Link buf 找到连续位置:
template <typename Position>
template <typename Stop_condition>
bool Link_buf<Position>::advance_tail_until(Stop_condition stop_condition) {
auto position = m_tail.load();
while (true) {
Position next;
bool stop = next_position(position, next);
if (stop || stop_condition(position, next)) {
break;
}
/* Reclaim the slot. */
claim_position(position);
position = next;
}
if (position > m_tail.load()) {
m_tail.store(position);
return true;
} else {
return false;
}
}
template <typename Position>
inline bool Link_buf<Position>::advance_tail() {
auto stop_condition = [](Position from, Position to) { return (to == from); };
return advance_tail_until(stop_condition);
}
用变量 m_tail 表示最后一个找到的连续位置。函数 advance_tail 尝试推进这个值,其中 next_positon 会根据当前的 LSN 获得下一个连续位置的 LSN。
template <typename Position>
bool Link_buf<Position>::next_position(Position position, Position &next) {
const auto index = slot_index(position);
auto &slot = m_links[index];
const auto distance = slot.load();
ut_ad(position < std::numeric_limits<Position>::max() - distance);
next = position + distance;
return distance == 0;
}
代码比较简单,就是根据数组中的长度,加上当前的 LSN。对于上述列子,假如此时 m_tail 是 4096 也就是 mtr1 之前,此时 4096 找到 mtr1 的 index,然后加上 mtr1 的长度,得到 next_position 是 5096,也就是 mtr2 的起始 LSN。但是此时 mtr2 还未假如 link buf, index[1001] 是 0。表示此时无法继续推进。如果 mtr2 也加入了 linkbuf,则可以顺着大小找到 mtr3 的结尾。
是否能使用 link buf
link buf 长度有限,肯定存在两个 LSN 指向同一个 index slot,所以在添加元素之前要先检测一下是否能够放进去。
template <typename Position>
inline bool Link_buf<Position>::has_space(Position position) const {
return tail() + m_capacity > position;
}
看起来很简单,就是加入的 position 是不是落到 tail() + capacity 里面。
在 log_buffer_write_completed 函数中的注释有解释:
/* Let M = log.recent_written_size (number of slots). For any integer k, all lsn values equal to: start_lsn + k*M correspond to the same slot, and only the smallest of them may use the slot. At most one of them can fit the range [log.buf_ready_for_write_lsn..log.buf_ready_ready_write_lsn+M). Any smaller values have already used the slot. Hence, we just need to wait until start_lsn will fit the mentioned range. */
uint64_t wait_loops = 0;
while (!log.recent_written.has_space(start_lsn)) {
++wait_loops;
os_thread_sleep(20);
}
因为 LSN 是递增的,总是较小的 LSN 先进入 link buf,所以检测 slot 是否可用,就能阻止相同 slot 的进入。
重新理解 capacity
capacity 表示容量,其实上面的例子容易有误导,认为 mtr1 到 mtr2 中间隔着 1000 个 slot,这些 slot 就用不到,一直为 0 了。其实不然,举个例子:
假如来了一个 mtr 5 [9034 - 14062], 此时 tail 仍然是 4095。mtr5 落到了 index 842 的位置,其实 mtr5 的长度已经大于 capacity 了,如果又来一个 mtr7 [14063 - 14070],实际上会落到 index 751 的位置。
由此看 link buf 的 mtr 之间的 slot 并不一定是 0. 所以 capacity 可以这么理解,就是最大的 mtr 并发数,当然一般很难达到,必须要所有的 mtr 的 start lsn 都不冲突才行。
Note: mtr 的 LSN 应该是 SN,也就是有效的数据的 LSN,不包括 Log block 的 hearder 和 tail,而 block 又是 512 对齐的,所以 capacity 的大小配置如果是 512 对齐的,可能就有某些 slot 就一直用不上。default 值是 16 MB 通过参数 log_recent_written_size 配置。