PgSQL · 新特性探索 · 浅谈postgresql分区表实现并发创建索引
Author: 慎追
背景
在数据库中索引可谓是司空见惯,优化查询的利器,其常用程度和表已无差别且更有甚之。索引建立的最合适时间是在定义表之后在表中插入数据之前,当一个表中已经包含了大量的数据再去建立索引意味着需要对全表做一次扫描,这将是一个很耗时的过程。
在Postgres中,在一个表上创建索引时会在表上加一个ShareLock锁,这个锁会阻塞DML(INSERT, UPDATE, DELETE)语句,对于一个具有大数据量的表来说, 建立一个索引通常需要很长时间,如果在这段时间内不允许做DML,也就是说再执行CREATE INDEX语句时所有的insert/update/delete语句都会等待,这让用户是难以忍受的。所以在CREATE INDEX CONCURRENTLY(CIC) 功能解决了这个问题,在创建索引时将会加一个ShareUpdateExclusiveLock, 这样将会不阻塞DML(INSERT, UPDATE, DELETE)。然而这样一个重要的功能在具有巨大数据量上的分区表上却是不支持的。 pg文档中给出的解决方案是先在每一个分区上使用CIC,最后再在分区表上创建索引,这种方案在一个具有大量分区的分区表中显然不是友好的。
Postgres中CIC的实现
名词定义
CIC create index concurrently 并发创建索引
- hot 断链 (Broken HOT Chain) 一个HOT链,其中索引的键值已更改。 这通常不允许发生,但是如果创建了新索引,则可能发生。 在那种情况下,可以使用各种策略来确保没有任何可见较早的元组的事务可以使用索引。
- 冷更新 (Cold update) 正常的非HOT更新,其中为元组的新版本创建索引条目。
- HOT 安全 (HOT-safe ) 如果目的元组更新不更改元组的索引列,则被称为HOT安全的。
- HOT更新 (HOT update) 一个UPDATE,其中新的元组成为仅堆元组,并且不创建新的索引条目。
HOT介绍
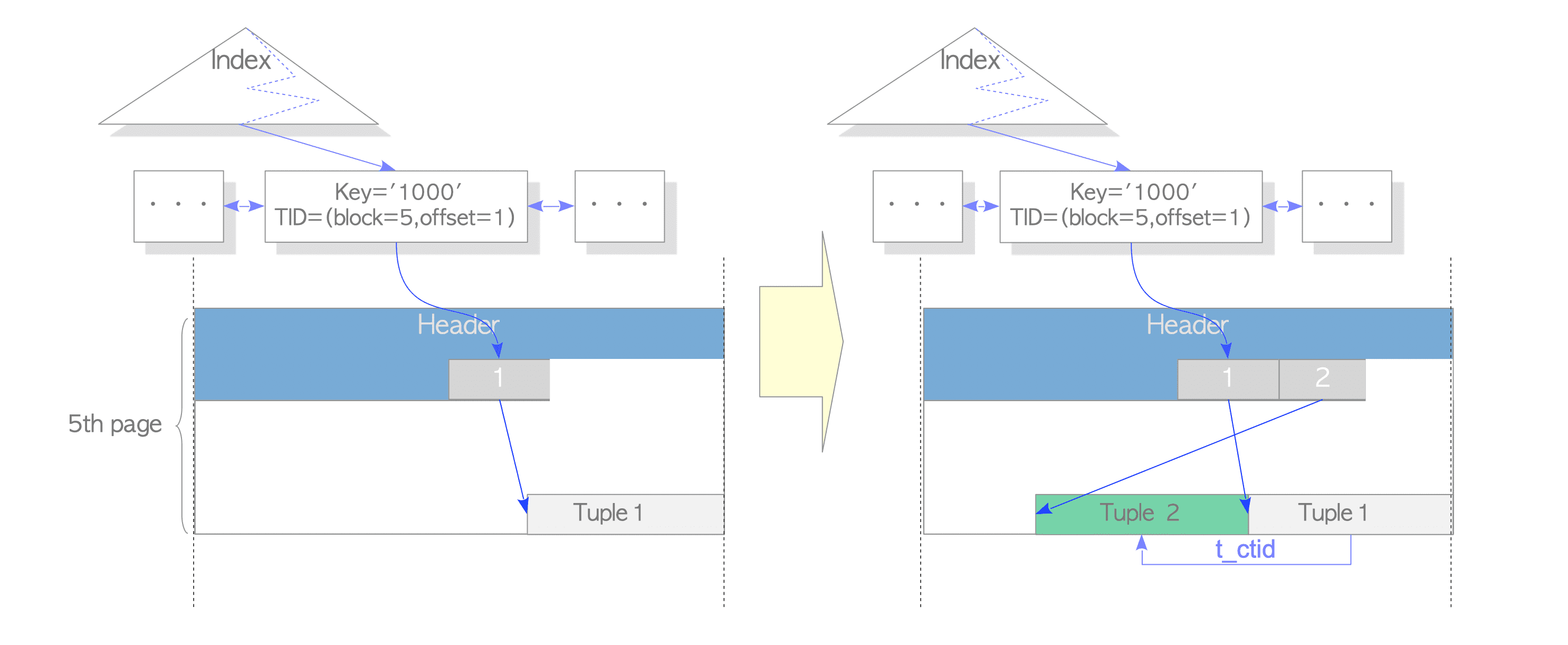
在PostgreSQL中为了消除了冗余索引条目,并允许在不执行table-wide vacuum的情况下重复使用DELETED或废弃的UPDATED元组占用的空间,提出了The Heap Only Tuple (HOT) 功能。众所周知的,postgresql为了实现读不阻塞写,写不阻塞读使用多版本的方案,即在update和delete元组时并不是直接的删除一行,而是通过xid和标记手段来设置这个元组对以后的事务不可见。当所有的事务都不可见以后,vacuum会对其标记和清理。 如果没有HOT,即使所有索引列都相同,更新链中行的每个版本都有其自己的索引条目。 使用HOT时,放置在同一页面上且所有索引列与其父行版本相同的新元组不会获得新的索引条目。 这意味着堆页面上的整个更新链只有一个索引条目。 无索引条目的元组标记有HEAP_ONLY_TUPLE标志。 先前的行版本标记为HEAP_HOT_UPDATED,并且(始终像在更新链中一样)其t_ctid字段链接到较新的版本。
- 没有HOT时的update
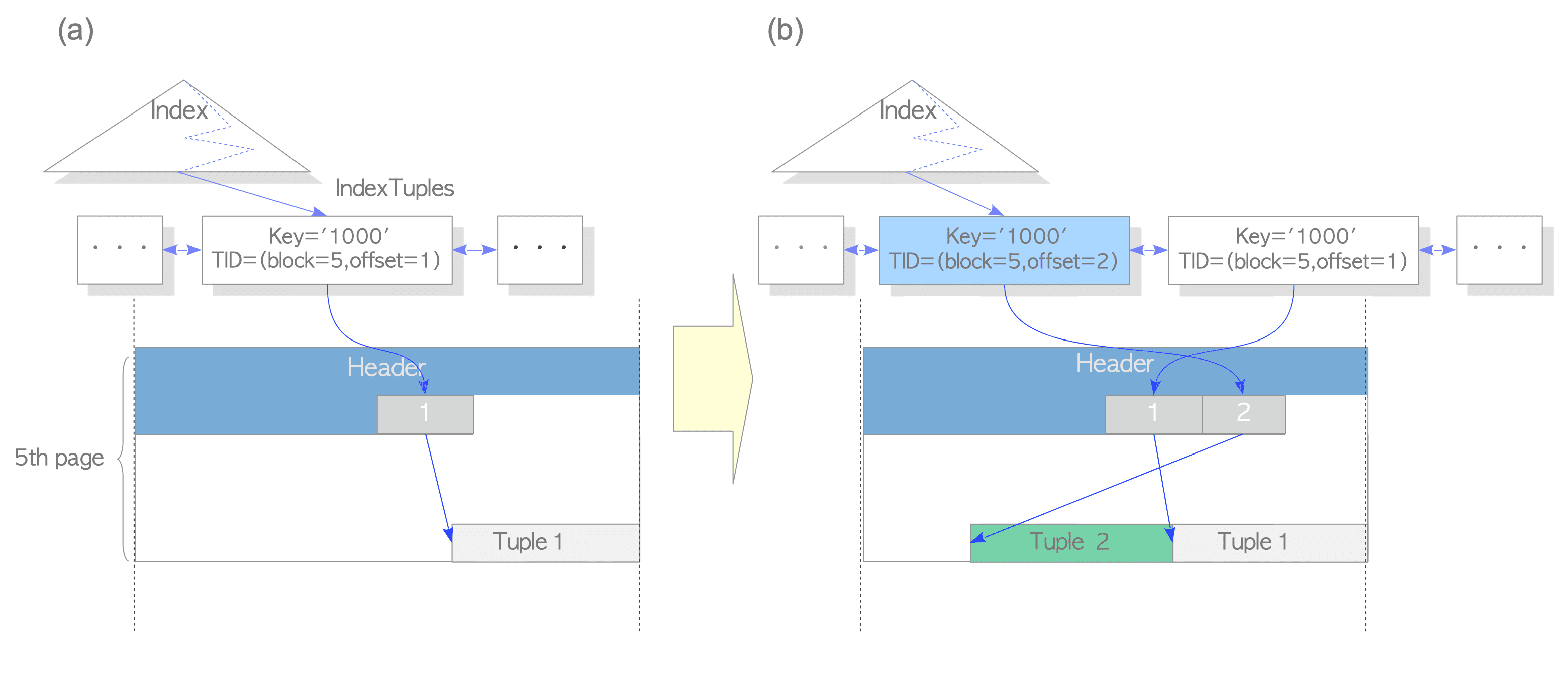
- 实现HOT时的update
并发创建索引
而HOT链会在如下两种下发生断链:
- 当更新的元组存储在另一页中,不存储旧元组同一页时。
- 当索引元组的键值更新时
举个例子:
 如上图所示, 当我们在table上的a 列创建索引时,并发的update 事务将第三行的a更新了,如果我们不做处理,这样建成的索引将会是错误的,索引中没有a=4的值。这种情况在普通的create index 不需要考虑,因为它会持有sharelock阻塞所有update/insert/delete事务。而在CIC中我们必须要考虑了。
CIC为了解决这种问题,使用了三个事务与pg_index中的如下三个flag,整个过程可以分为三个阶段来介绍。
如上图所示, 当我们在table上的a 列创建索引时,并发的update 事务将第三行的a更新了,如果我们不做处理,这样建成的索引将会是错误的,索引中没有a=4的值。这种情况在普通的create index 不需要考虑,因为它会持有sharelock阻塞所有update/insert/delete事务。而在CIC中我们必须要考虑了。
CIC为了解决这种问题,使用了三个事务与pg_index中的如下三个flag,整个过程可以分为三个阶段来介绍。
- indislive 设置为true 后,新的事务需要考虑hot-safe
- indisready 设置为true后,新的事务要维护索引主要指update/insert/delete事务
- indisvalid 设置为true后,新的事务可以使用此索引进行查询
Phase1 of CIC
- precheck 各种语法和功能行检查
- 构建catalog , 主要包括 relcache,pg_class, pg_index(indislive=true, indisready=false, indisvalid= false)
- 加一个会话锁(ShareUpdateExclusiveLock),提交事务
自此,索引的catalog已经建立成功,新的事务将会看到表中有一个invalid索引,因此在插入数据时将会考虑HOT-safe。
Phase2 of CIC
- 使用ShareLock等待表上所有的dml事务结束。(这里是为了等待,Phase1中事务结束前开始的事务,这些事务无法看到invalid索引)
- 开始事务,获取快照,扫描表中的所有可见元组构建索引,
- 更新pg_index indisready=true ,提交事务
此时,索引已经建立,但是无法用于查询,因为在phase2事务后开始的事务做插入的数据没有建立索引。新的update/insert/delete事务将会维护此索引。
Phase3 of CIC
- 使用ShareLock等待表上所有的dml事务结束。(这里是为了等待,Phase2中事务结束前开始的事务,这些事务无法看到isready索引)
- 获取快照,为Phase2事务开始到现在所缺少的事务补充索引。
- 记下当前快照的xmin, 提交事务
- 获取所有早于当前快照xmin的快照的vxid,等待它们结束。(这里是为了等待所有在Phase3 事务结束前开始的读写事务,它们无法看到Phase3 事务)
- 更新更新pg_index indisvalid=true
- 更新cache,释放会话锁
至此,索引已经对所有事务可用。
分区表中实现CIC
通过上述的介绍可以了解普通表中的CIC原理,与标准索引构建相比,此方法需要更多的总工作量,并且需要花费更长的时间才能完成。 但是,由于它允许在建立索引时继续进行正常操作,因此该方法对于在生产环境中添加新索引很有用。 当然,索引创建带来的额外CPU和I / O负载可能会减慢其他操作的速度。而且,如果在扫描表时出现问题,例如死锁或唯一索引中的唯一性冲突,则CREATE INDEX命令将失败,但会留下 “invalid” 索引。 出于查询目的,该索引将被忽略,因为它可能不完整。 但是它将仍然消耗更新开销。 这些问题将会在分区表中被放大,因为分区表相当于n个普通表的集合,我们的设计方案将以此为出发点。
例如: 一个分区表table1 ,有3个分区 part1, part2, part3,
其中part2 有两个分区 part21,part22
table1
├── part1
├── part2
│ ├── part21
│ ├── part22
├── part3
对于第一阶段:我们使用一个事务进行提交,这样可以保证catalog的一致性。 对于分区树的每一个分区,我们分别递归的自底向上的执行第二阶段,和第三阶段。 让前面的分区首先创建完成并可用。当出现失败后,后面的索引虽然没有创建完成,但是其catalog已经创建完成。
start transaction
Phase1 of table1
Phase1 of part1
Phase1 of part2
...
commit transaction
start transaction
Phase2 of part1
commit transaction
Phase3 of part1
commit transaction
start transaction
Phase2 of part21
commit transaction
start transaction
Phase3 of part21
commit transaction
...
start transaction
Phase2 of table1
commit transaction
start transaction
Phase3 of table1
commit transaction