PolarDB · 源码解析 · 深度解析PolarDB的并行查询引擎
Author: 程训焘
PolarDB与开源MySQL及其它类MySQL的产品相比,除了计算与存储分离的先进架构之外,另外一个最核心的技术突破就是开发了其它类MySQL产品没有的并行查询引擎,通过并行查询引擎,PolarDB除了保持自身对OLTP应用的优势之外,还对OLAP的支持能力有了一个质的飞越,遥遥领先于其它类MySQL产品。
用户越来越多的分析统计需求
众所周知,MySQL的优化器目前还不支持并行优化,也不支持并行执行。当然,MySQL自己也在逐渐探索并行执行的可能,比如对count()的并行执行,但整体上,还没有形成一套成熟的并行优化、并行执行的机制,只是针对一些特殊的场景进行局部优化。随着类MySQL产品在云上的蓬勃发展,越来越多的传统用户迁移到类MySQL产品上,对MySQL提出了一些新的挑战。很多传统用户在对OLTP要求的同时,还要求数据库有一些分析、统计、报表的能力,相对传统商业数据库来说,MySQL在这方面有明显的劣势。为了满足用户不断提升的OLTP能力,同时又能进行OLAP分析的需求,PolarDB的并行查询引擎应运而生。自诞生以来,通过强大的并行执行能力,原来需要几百秒的查询,现在只需要几秒,为用户节省了大量的时间和金钱,得到大量用户的极大好评。
PolarDB并行查询引擎应运而生
优化器是数据库的核心,优化器的好坏几乎可以决定一个数据库产品的成败。开发一个全新的优化器,对任何团队都是一个巨大的挑战,技术的复杂度暂且不提,就是想做到产品的足够稳定就是一个非常难以克服的困难。因此即使传统商业数据库,也是在现有优化器的基础上不断改进,逐渐增加对并行的支持,最终成为一个成熟的并行优化器。对PolarDB也是如此,在设计和开发并行查询引擎时,我们充分利用现有优化器的技术积累和实现基础,不断改进,不断打磨,最终形成了一个持续迭代的技术方案,以保证新的优化器的稳定运行和技术革新。
对于一个类OLAP的查询,显而易见的是它通常是对大批量数据的查询,数据量大意味着数据远大于数据库的内存容量,大部分数据可能无法缓存到数据库的buffer中,而必须在查询执行时才动态加载到buffer中,这样就会造成大量IO操作,而IO操作又是最耗时的,因此首先要考虑的就是如何能加速IO操作。由于硬件的限制,每次IO的耗时基本是固定的,虽然还有顺序IO和随机IO的区别,但在SSD已经盛行的今天,两者的差异也在逐渐接近。那么还有没有其它方式可以加速IO呢? 显然并行IO是一个简单易行的方法,如果多个线程可以同时发起IO,每个线程只读取部分数据,这样就可以快速的将数据读到数据库的buffer中。但是如果只是将数据读取到buffer中,而不是立即进行后续处理,那么这些数据就会因buffer爆满导致数据被换出,从而失去加速IO的意义。
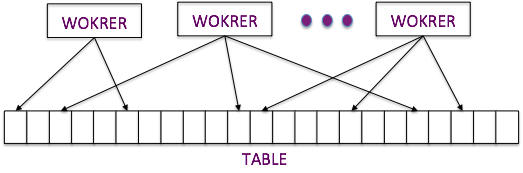
图1-并行IO示意图
因此,在并行读取数据的同时,必须同时并行的处理这些数据,这是并行查询加速的基础。因为原有的优化器只能生成串行的执行计划,为了实现并行读取数据,同时并行处理数据,首先必须对现有的优化器进行改造,让优化器可以生成我们需要的并行计划。比如哪些表可以并行读取,并且通过并行读取会带来足够的收益;或者哪些操作可以并行执行,并且可以带来足够的收益。并不是说并行化改造一定会有收益,比如对一个数据量很小的表,可能只是几行,如果也对它进行并行读取的话,并行执行所需要的多线程构建所需要的代价可能远大于所得到的收益,总体来说,并行读取会需要更多的资源和时间,这就得不偿失了,因此并行化的改造必须是基于代价的,否则可能会导致更严重的性能褪化问题。
Fact表的并行扫描
通过基于并行cost的计算和比较,选择可以并行读取的表作为候选,是并行执行计划的第一步。基于新的并行cost,也许会有更优的JOIN的顺序选择,但这需要更多的迭代空间,为防止优化过程消耗太多的时间,保持原有计划的JOIN顺序是一个不错的选择。另外,对于参与JOIN的每张表,因为表的访问方法不同,比如全表扫描、ref索引扫描,range索引扫描等,这些都会影响到最终并行扫描的cost。 通常我们选择最大的那张表作为并行表,这样并行扫描的收益最大,当然也可以选择多个表同时做并行扫描,后面会继续讨论更复杂的情况。 下面以查询年度消费TOP 10的用户为例:
SELECT c.c_name, sum(o.o_totalprice) as s FROM customer c, orders o WHERE c.c_custkey = o.o_custkey AND o_orderdate >= '1996-01-01' AND o_orderdate <= '1996-12-31' GROUP BY c.c_name ORDER BY s DESC LIMIT 10;
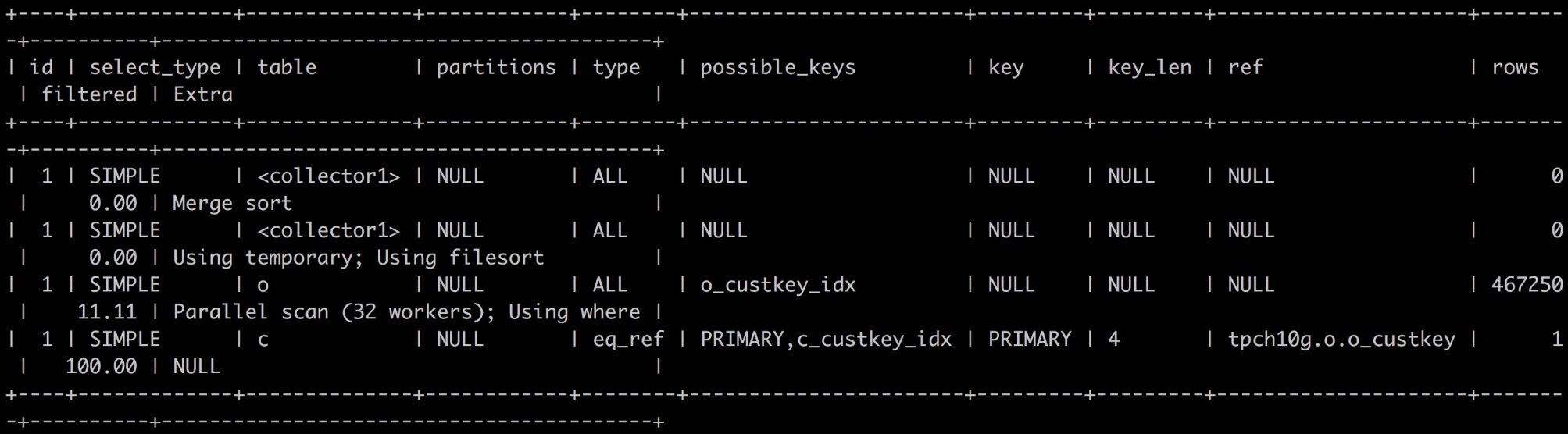
其中orders表为订单表,数据很多,这类表称之为Fact事实表,customer表为客户表,数据相对较少,这类表称之为dimension维度表。那么此SQL的并行执行计划如下图所示:
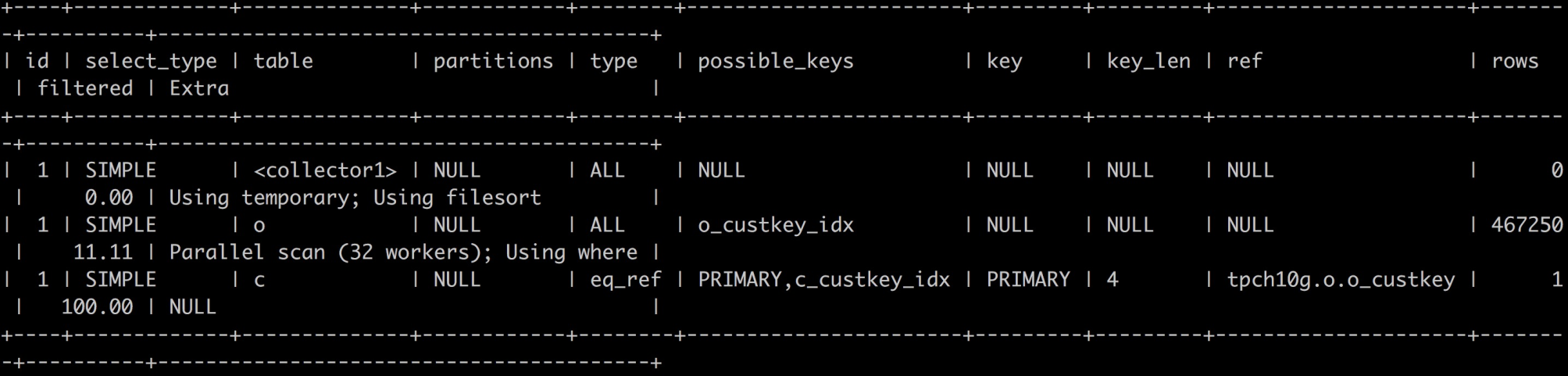 从计划中可以看出orders表会做并行扫描,由32个workers线程来执行,每个worker只扫描orders表的某些分片,然后与customer表按o_custkey做eq_ref进行JOIN,JOIN的结果发送到用户session中一个collector组件,然后由collector组件继续做后续的GROUP BY、ORDER BY及LIMIT操作。
从计划中可以看出orders表会做并行扫描,由32个workers线程来执行,每个worker只扫描orders表的某些分片,然后与customer表按o_custkey做eq_ref进行JOIN,JOIN的结果发送到用户session中一个collector组件,然后由collector组件继续做后续的GROUP BY、ORDER BY及LIMIT操作。
多表并行JOIN
将一张表做并行扫描之后,就会想为什么只能选择一张表?如果SQL中有2张或更多的FACT表,能不能可以将FACT表都做并行扫描呢?答案是当然可以。以下面SQL为例:
SELECT o.o_custkey, sum(l.l_extendedprice) as s FROM orders o, lineitem l WHERE o.o_custkey = l.l_orderkey GROUP BY o.o_custkey ORDER BY s LIMIT 10;
其中orders表和lineitem表都是数据量很大的FACT表,此SQL的并行执行计划如下图所示:
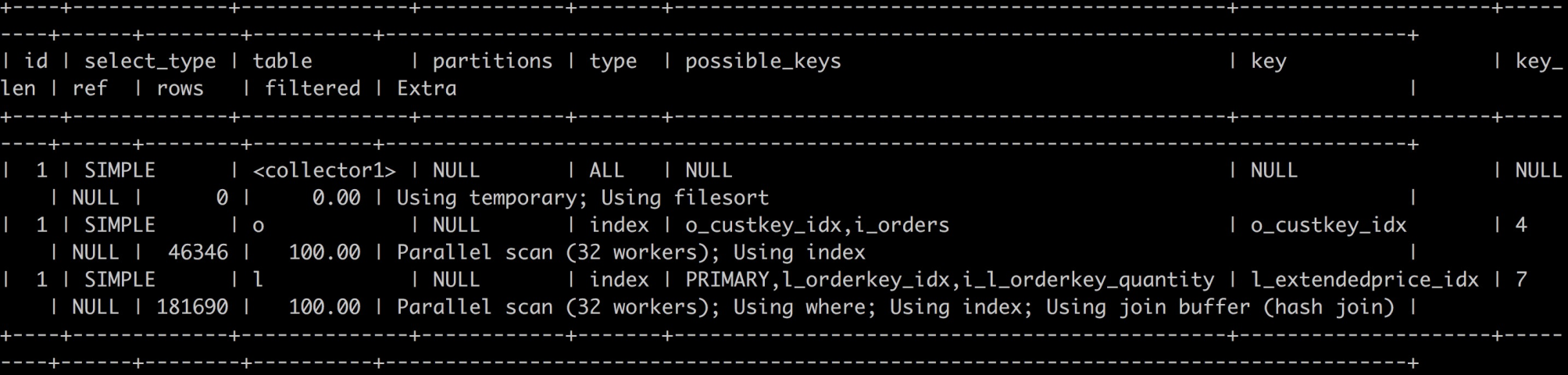 从计划中可以看到orders表和lineitem表都会做并行扫描,都由32个workers线程来执行。那么多个表的并行是如何实现的呢?我们以2个表为例,当2个表执行JOIN时,通常的JOIN方式有Nested Loop JOIN、HASH JOIN等,对于不同的JOIN方式,为保证结果的正确性,必须选择合理的表扫描方式。以HASH JOIN为例,对于串行执行的HASH JOIN来说,首先选择一个表创建HASH表称之谓Build表,然后读取另一个Probe表,计算HASH,并在Build表中进行HASH匹配,若匹配成功,输出结果,否则继续读取。如果改为并行HASH JOIN,并行优化器会对串行执行的HASH JOIN进行并行化改造,使之成为并行HASH JOIN,并行化改造的方案可以有以下两种解决方案。方案一是将2个表都按HASH key进行分区,相同HASH值的数据处于同一个分区内,由同一个线程执行HASH JOIN。方案二是创建一个共享的Build表,由所有执行HASH JOIN的线程共享,然后每个线程并行读取属于自己线程的另外一个表的分片,再执行HASH JOIN。
从计划中可以看到orders表和lineitem表都会做并行扫描,都由32个workers线程来执行。那么多个表的并行是如何实现的呢?我们以2个表为例,当2个表执行JOIN时,通常的JOIN方式有Nested Loop JOIN、HASH JOIN等,对于不同的JOIN方式,为保证结果的正确性,必须选择合理的表扫描方式。以HASH JOIN为例,对于串行执行的HASH JOIN来说,首先选择一个表创建HASH表称之谓Build表,然后读取另一个Probe表,计算HASH,并在Build表中进行HASH匹配,若匹配成功,输出结果,否则继续读取。如果改为并行HASH JOIN,并行优化器会对串行执行的HASH JOIN进行并行化改造,使之成为并行HASH JOIN,并行化改造的方案可以有以下两种解决方案。方案一是将2个表都按HASH key进行分区,相同HASH值的数据处于同一个分区内,由同一个线程执行HASH JOIN。方案二是创建一个共享的Build表,由所有执行HASH JOIN的线程共享,然后每个线程并行读取属于自己线程的另外一个表的分片,再执行HASH JOIN。
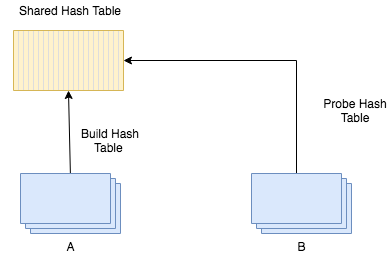
图2-并行HASH JOIN示意图
对于方案一,需要读取表中的所有数据,根据选中的HASH key,对数据进行分区,并将数据发送到不同的处理线程中,这需要额外增加一个Repartition算子,负责根据分区规则将数据发送到不同的处理线程。为了提高效率,这里通常会采用message queue队列来实现。 对于方案二,需要并行创建共享的HASH build表,当build表创建成功后,每个线程读取Probe表的一个分片,分别执行HASH JOIN,这里的分片并不需要按照HASH key进行分片,每个线程分别读取互不相交的分片即可。
分析统计算子的并行
对于一个分析统计的需求,GROUP BY操作是绕不开的操作,尤其对大量的JOIN结果再做GROUP BY操作,是整个SQL中最费时的一个过程,因此GROUP BY的并行也是并行查询引擎必须优先解决的问题。
以年度消费TOP10客户的SQL为例,对GROUP BY并行化后的并行执行计划如下图所示:
 与之前的执行计划相比,新的执行计划中多了一个collector组件,总共有2个collector组件。首先我们看第二行的collector组件,它的extra信息中有2条”Using temporary; Using filesort”,这表示它是对从workers接收到的数据执行GROUP BY,然后再按ORDER排序,因为只有第一个collector组件在用户的session中,所以这个collector也是在worker中并行执行,也就是说并行的做Group by和Order by以及Limit;然后看第一行的collector组件,它的extra信息中只有一条”Merge sort”,表示session线程对从workers接收到的数据执行一次merge sort,然后将结果返回给用户。这里可能就有人会提出疑问,为什么session线程只做merge sort就可以完成GROUP BY操作呢?另外LIMIT在哪里呢?
首先回答第2个问题,因为explain计划显示的问题,在常规模式下不显示LIMIT操作,但在Tree模式下会显示LIMIT操作。如下所示:
与之前的执行计划相比,新的执行计划中多了一个collector组件,总共有2个collector组件。首先我们看第二行的collector组件,它的extra信息中有2条”Using temporary; Using filesort”,这表示它是对从workers接收到的数据执行GROUP BY,然后再按ORDER排序,因为只有第一个collector组件在用户的session中,所以这个collector也是在worker中并行执行,也就是说并行的做Group by和Order by以及Limit;然后看第一行的collector组件,它的extra信息中只有一条”Merge sort”,表示session线程对从workers接收到的数据执行一次merge sort,然后将结果返回给用户。这里可能就有人会提出疑问,为什么session线程只做merge sort就可以完成GROUP BY操作呢?另外LIMIT在哪里呢?
首先回答第2个问题,因为explain计划显示的问题,在常规模式下不显示LIMIT操作,但在Tree模式下会显示LIMIT操作。如下所示:
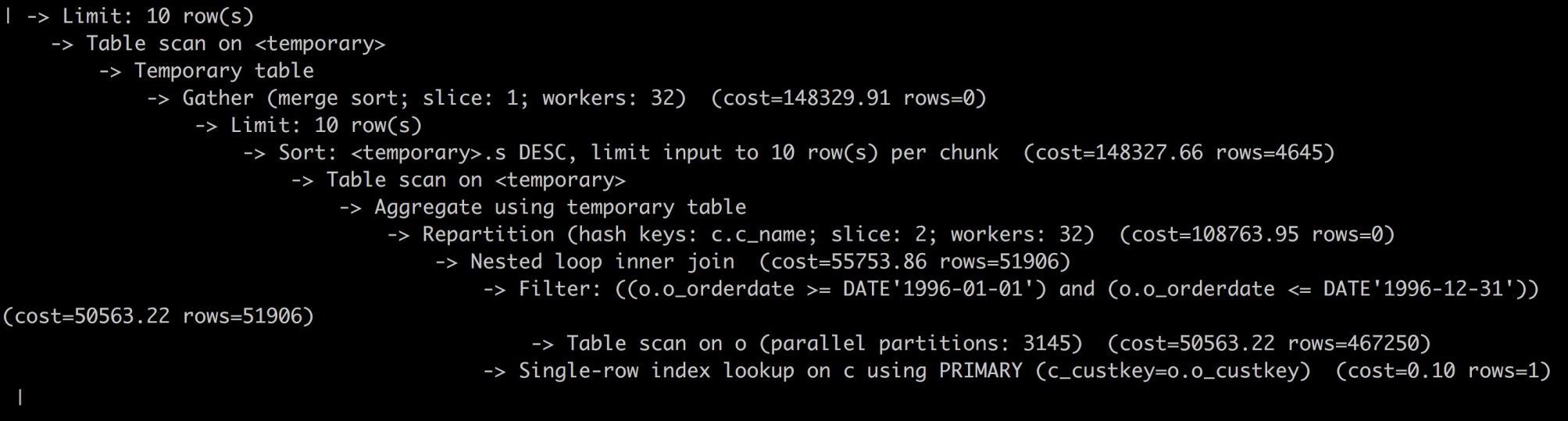 从Tree型计划树上可以清楚的看到LIMIT操作有2处,一处在计划的顶端,也就是在session上,做完limit后将数据返回给用户;另外一处在计划树的中间位置,它其实是在worker线程的执行计划上,在每个worker线程中在排序完成后也会做一次limit,这样就可以极大减少worker返回给session线程的数据量,从而提升整体性能。
下面来回答第一个问题,为什么GROUP BY只需要在worker线程上执行一次就可以保证结果的正确性。通常来说,每个worker只有所有数据的一个分片,只在一个数据分片上做GROUP BY是有极大的风险得到错误的GROUP BY结果的,因为同一GROUP分组的数据可能不只是在本WORKER的数据分片上,也可能在其它WORKER的数据分片中,被其它WORKER所持有。但是如果我们可以保证同一GROUP分组的数据一定位于同一个数据分片,并且这个数据分片只被一个WORKER线程所持有,那么就可以保证GROUP BY结果的正确性。通过Tree型执行计划可以看到,在并行JOIN之后,将JOIN的结果按GROUP分组的KEY值: c.c_name进行Repartition操作,将相同分组的数据分发到相同的WORKER,从而保证每个WORKER拥有的数据分片互不交叉,保证GROUP BY结果的正确性。
因为每个WORKER的GROUP BY操作已经是最终结果,所以还可以将ORDER BY和LIMIT也下推到WORKER来执行,进一步提升了并行执行的效率。
从Tree型计划树上可以清楚的看到LIMIT操作有2处,一处在计划的顶端,也就是在session上,做完limit后将数据返回给用户;另外一处在计划树的中间位置,它其实是在worker线程的执行计划上,在每个worker线程中在排序完成后也会做一次limit,这样就可以极大减少worker返回给session线程的数据量,从而提升整体性能。
下面来回答第一个问题,为什么GROUP BY只需要在worker线程上执行一次就可以保证结果的正确性。通常来说,每个worker只有所有数据的一个分片,只在一个数据分片上做GROUP BY是有极大的风险得到错误的GROUP BY结果的,因为同一GROUP分组的数据可能不只是在本WORKER的数据分片上,也可能在其它WORKER的数据分片中,被其它WORKER所持有。但是如果我们可以保证同一GROUP分组的数据一定位于同一个数据分片,并且这个数据分片只被一个WORKER线程所持有,那么就可以保证GROUP BY结果的正确性。通过Tree型执行计划可以看到,在并行JOIN之后,将JOIN的结果按GROUP分组的KEY值: c.c_name进行Repartition操作,将相同分组的数据分发到相同的WORKER,从而保证每个WORKER拥有的数据分片互不交叉,保证GROUP BY结果的正确性。
因为每个WORKER的GROUP BY操作已经是最终结果,所以还可以将ORDER BY和LIMIT也下推到WORKER来执行,进一步提升了并行执行的效率。
不断迭代创新的并行查询引擎
总之,通过对并行查询引擎的支持,PolarDB不仅在保持查询引擎稳定的同时,还极大的提升了复杂SQL,尤其是分析统计类型查询的性能。通过有计划的不断迭代,PolarDB在并行查询引擎的道路上越走越远,也越来越强大,为了满足客户日益不断增长的性能需求,为了更多企业用户的数字化升级,PolarDB为您提供革命性的数据引擎,助您加速拥抱万物互联的未来。
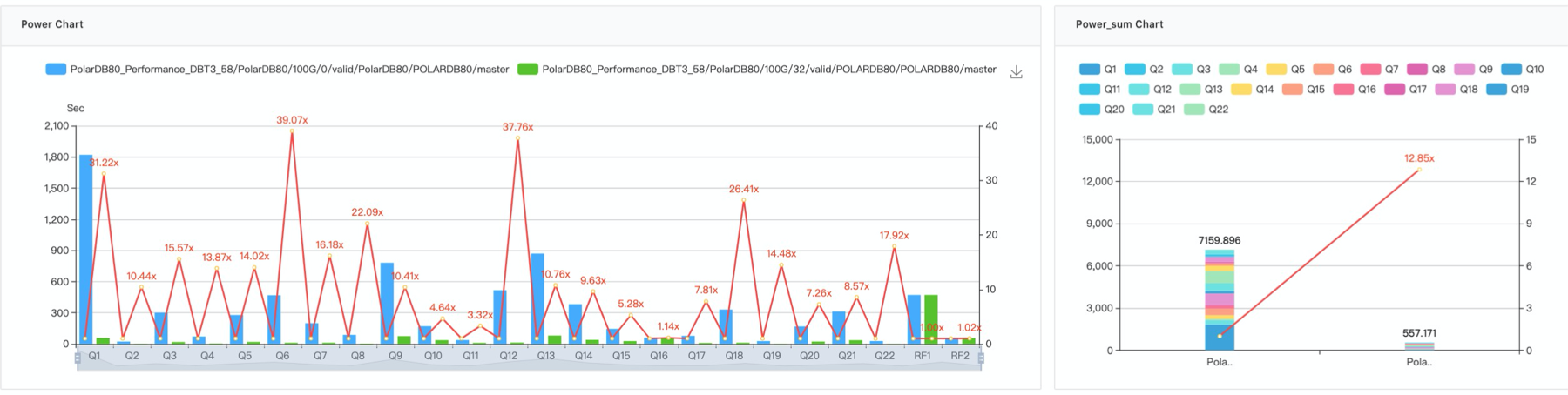
并行查询引擎对TPCH的线性加速
附图是一个并行查询引擎对TPCH的加速效果,TPC-H中100%的SQL可以被加速,70%的SQL加速比超过8倍,总和加速近13倍,Q6和Q12加速甚至超过32倍。