MySQL · 源码阅读 · Innodb内存管理解析
Author: 尚灿芳
本文主要介绍innodb的内存管理,涉及基础的内存分配结构、算法以及buffer pool的实现细节,提及change buffer、自适应hash index和log buffer的基本概念和内存基本配比,侧重点在内存的分配和管理方式。本文所述内容基于mysql8.0版本。
基础内存分配
在5.6以前的版本中,innodb内部实现了除buffer pool外的额外内存池,那个时期lib库中的分配器在性能和扩展性上表现比较差,缺乏针对多核系统优化的内存分配器,像linux下最通用的ptmalloc的前身是Doug Lea Malloc,也是因为不支持多线程而被弃用了。所以innodb自己实现了内存分配器,使用额外的内存池来响应那些原本要发给系统的内存请求,用户可以通过设置参数innodb_use_sys_malloc 来选择使用innodb的分配器还是系统分配器,使用innodb_additional_mem_pool_size参数设定额外内存池的大小。随着多核系统的发展,一些分配器对内部实现进行了优化和扩展,已经可以很好的支持多线程,相较于innodb特定的内存分配器可以提供更好的性能和扩展性,所以这个实现在5.6版本已经弃用,5.7版本删除。本文所讨论的内容和涉及到的代码基于mysql8.0版本。
innodb内部封装了基础分配释放方式malloc,free,calloc,new,delete等,在开启pfs模式下,封装内部加入了内存追踪信息,使用者可传入对应的key值来记录某个event或者模块的内存分配信息,这部分信息通过pfs内部表来对外展示,以便分析内存泄漏、内存异常等问题。
innodb内部也提供了对系统基础分配释放函数封装的allocator,用于std::*容器内部的内存分配,可以让这些容器内部的隐式分配走innodb内部封装的接口,以便于内存信息的追踪。基础的malloc/calloc等封装后也会走allocator的接口。 基础封装:
非UNIV_PFS_MEMORY编译模式
#define UT_NEW(expr, key) ::new (std::nothrow) expr
#define UT_NEW_NOKEY(expr) ::new (std::nothrow) expr
#define UT_DELETE(ptr) ::delete ptr
#define UT_DELETE_ARRAY(ptr) ::delete[] ptr
#define ut_malloc(n_bytes, key) ::malloc(n_bytes)
#define ut_zalloc(n_bytes, key) ::calloc(1, n_bytes)
#define ut_malloc_nokey(n_bytes) ::malloc(n_bytes)
...
打开UNIV_PFS_MEMORY
#define UT_NEW(expr, key) \
::new (ut_allocator<byte>(key).allocate(sizeof expr, NULL, key, false, \
false)) expr
#define ut_malloc(n_bytes, key) \
static_cast<void *>(ut_allocator<byte>(key).allocate( \
n_bytes, NULL, UT_NEW_THIS_FILE_PSI_KEY, false, false))
#define ut_zalloc(n_bytes, key) \
static_cast<void *>(ut_allocator<byte>(key).allocate( \
n_bytes, NULL, UT_NEW_THIS_FILE_PSI_KEY, true, false))
#define ut_malloc_nokey(n_bytes) \
static_cast<void *>( \
ut_allocator<byte>(PSI_NOT_INSTRUMENTED) \
.allocate(n_bytes, NULL, UT_NEW_THIS_FILE_PSI_KEY, false, false))
...
可以看到在非UNIV_PFS_MEMORY编译模式下,直接调用系统的分配函数,忽略传入的key,而UNIV_PFS_MEMORY编译模式下使用ut_allocator分配,下面有ut_allocator的介绍,比较简单的封装。
memory heap
主要管理结构为mem_heap_t,8.0中的实现比较简单,内部维护block块的链表,包含指向链表开始和尾部的指针可以快速找到链表头部和尾部的节点,每个节点都是mem_heap_t的结构。mem_heap在创建的时候会初始一块内存作为第一个block,大小可由使用者指定。mem_heap_alloc响应基本的内存分配请求,先尝试从block中切分出满足请求大小的内存,如果不能满足则创建一个新的block,新的block size至少为上一个block的两倍(last block),直到达到规定的上限值,新创建的block总是链到链表的尾部。mem_heap_t中记录了block的size和链表中block的总size以及分配模式(type)等信息,基本结构如下图:
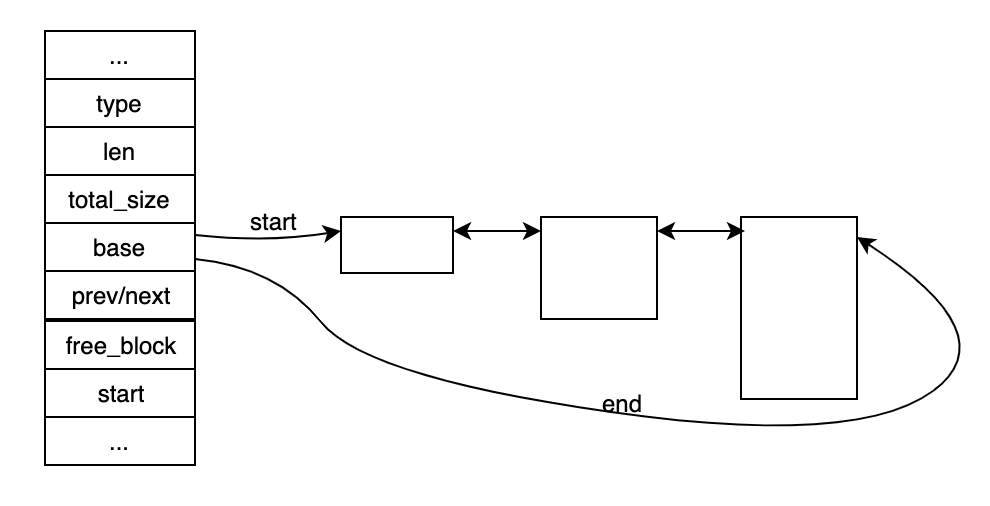 innodb在内部定义了三种分配block模式供选择:
innodb在内部定义了三种分配block模式供选择:
- MEM_HEAP_DYNAMIC 使用malloc动态分配,比较通用的分配模式
- MEM_HEAP_BUFFER size满足一定条件,使用buffer pool中的内存块
- MEM_HEAP_BTR_SEARCH 保留额外的内存,地址保存在free_block中
一般的使用模式为MEM_HEAP_DYNAMIC,也可以使用b|c的模式,在某些情况下使用free_block中的内存。mem heap链表中的block在最后统一free,按照分配模式走不同的free路径。
我理解基本思想也是使用一次性分配大内存块,再从大内存块中切分来响应小内存分配请求,以避免多次调用malloc/free,减少overhead。实现上比较简单,内部只是将多个大小可能不一的内存块使用链表链起来,大多场景只有一个block。没有内存归还、复用和合并等机制,使用过程中不会将内存free,会有一定程度的内存浪费,但有效减少了内存碎片,比较适用于短周期多次分配小内存的场景。
基础allocator
ut_allocator
innodb内部提供ut_allocator用来为std::* 容器分配内存,内部封装了基础的内存分配释放函数,以便于内存追踪和统一管理。 ut_allocator提供基本的allocate/deallocate的分配释放函数,用于分配n个对象所需内存,内部使用malloc/free。另外也提供了大内存块的分配,开启LINUX_LARGE_PAGES时使用HugePage,在服务器内存比较大的情况可以减少页表条目提高检索效率,未开启时使用mmap/munmap内存映射的方式。 更多细节见如下代码:
/** Allocator class for allocating memory from inside std::* containers. */
template <class T>
class ut_allocator {
// 分配n个elements所需内存大小,内部使用malloc/calloc分配
// 不开启PFS_MEMORY分配n_elements * sizeof(T)大小的内存
// 开启PFS_MEMORY多分配sizeof(ut_new_pfx_t)大小的内存用于信息统计
pointer allocate(size_type n_elements, const_pointer hint = NULL,
PSI_memory_key key = PSI_NOT_INSTRUMENTED,
bool set_to_zero = false, bool throw_on_error = true);
// 释放allocated()分配的内存,内部使用free释放
void deallocate(pointer ptr, size_type n_elements = 0)
// 分配一块大内存,如果开启了LINUX_LARGE_PAGES使用HugePage
// 否则linux下使用mmap
pointer allocate_large(size_type n_elements, ut_new_pfx_t *pfx)
// 对应allocate_large,linux下使用munmap
void deallocate_large(pointer ptr, const ut_new_pfx_t *pfx)
// 提供显示构造/析构func
void construct(pointer p, const T &val) { new (p) T(val); }
void destroy(pointer p) { p->~T(); }
开启PFS_MEMORY场景下提供更多可用func:
pointer reallocate(void *ptr, size_type n_elements, PSI_memory_key key);
// allocate+construct的封装, 分配n个单元的内存并构造相应对象实例
pointer new_array(size_type n_elements, PSI_memory_key key);
// 同上,deallocate+destroy的封装
void delete_array(T *ptr);
}
mem_heap_allocator
mem_heap_t的封装,可以作为stl allocator来使用,内部使用mem_heap_t的内存管理方式。
/** A C++ wrapper class to the mem_heap_t routines, so that it can be used
as an STL allocator */
template <typename T>
class mem_heap_allocator {
mem_heap_allocator(mem_heap_t *heap) : m_heap(heap) {}
pointer allocate(size_type n, const_pointer hint = 0) {
return (reinterpret_cast<pointer>(mem_heap_alloc(m_heap, n * sizeof(T))));
}
void deallocate(pointer p, size_type n) {}
// 提供显示构造/析构func
void construct(pointer p, const T &val) { new (p) T(val); }
void destroy(pointer p) { p->~T(); }
private:
mem_heap_t *m_heap;
}
buddy
innodb支持创建压缩页以减少数据占用的磁盘空间,支持1K, 2K, 4K 、8K和16k大小的page。buddy allocator用于管理压缩page的内存空间,提高内存使用率和性能。
buffer pool中:
UT_LIST_BASE_NODE_T(buf_buddy_free_t) zip_free[BUF_BUDDY_SIZES_MAX];
/** Struct that is embedded in the free zip blocks */
struct buf_buddy_free_t {
union {
ulint size; /*!< size of the block */
byte bytes[FIL_PAGE_DATA];
} stamp;
buf_page_t bpage; /*!< Embedded bpage descriptor */
UT_LIST_NODE_T(buf_buddy_free_t) list;
};
伙伴系统也是比较经典的内存分配算法,也是linux内核用于解决外部碎片的一种手段。innodb的实现在算法上与buddy的基本实现并无什么区别,所支持最小的内存块为1k(2^10),最大为16k,每种内存块维护一个链表,多种内存块链表组成了zip_free链表。 分配入口在buf_buddy_alloc_low,先尝试从zip_free[i]中获取所需大小的内存块,如果当前链表中没有,则尝试从更大的内存块链表中获取,获取成功则进行切分,一部分返回另一块放入对应free链表中,实际上是buf_buddy_alloc_zip的一个递归调用,只是传入的i不断增加。如果一直递归到16k的块都没法满足,则从buffer pool中新申请一块大内存块,并将其按照伙伴关系进行(比如现分配了16,需要2k,先切分8k,8k,再将其中一个8k切分为4k,4k,再将其中4k切分为2k,2k)切分直到满足分配请求。 释放入口在buf_buddy_free_low,为了避免碎片在释放的时候多做了一些事情。在释放一个内存块的时候没有直接放回对应链表中,而是先查看其伙伴是不是free的,如果是则进行合并,再尝试对合并后的内存块进行合并。如果其伙伴是在USED的状态,这里做了一次relocate操作,将其内容拷贝到其它free的block块上,再进行对它合并。这种做法有效减少了碎片的存在,但拷贝这种操作也降低了性能。
buffer pool
buffer pool是innodb主内存中一块区域,用于缓存主表和索引中的数据,读线程可以直接从buffer pool中读取相应数据从而避免io提升读取性能,当一个页面需要修改时,先在buffer pool中进行修改,另有后台线程来负责刷脏页。一般在专用服务器中,会将80%的内存分配给buffer pool使用。数据库启动时就会将内存分配给buffer pool,不过内存有延迟分配的优化,这部分内存在未真正使用前是没有进行物理映射的,所以只会影响虚存大小。buffer pool的内存在运行期间不会收缩还给系统,在数据库关闭时将这部分内存统一释放。可以设置多个buffer pool实例。
buffer pool中使用chunk内存块来管理内存,每个buffer pool实例包含一个或多个chunk,chunks在buffer pool初始化时使用mmap分配,并初始化为多个block。每个block地址相差UNIV_PAGE_SIZE,UNIV_PAGE_SIZE一般是16kb,这块内存包含了page相关控制信息和真正的数据page两部分,之后将这些page加入free list中供使用。这里直接使用了mmap而非malloc,是因为在glibc的ptmalloc内存分配器中,大于MMAP_THRESHOLD阀值的内存请求也是使用mmap,MMAP_THRESHOLD默认值是128k,buffer pool的配置大小一般会远大于128k。
数据结构
buffer pool进行内存管理的主要数据结构。
buf_pool_t
控制buffer pool的主结构,内部包含多种逻辑链表以及相关锁信息、统计信息、hash table、lru和flush算法相关等信息。
struct buf_pool_t {
//锁相关
BufListMutex chunks_mutex; /*!< protects (de)allocation of chunks*/
BufListMutex LRU_list_mutex; /*!< LRU list mutex */
BufListMutex free_list_mutex; /*!< free and withdraw list mutex */
BufListMutex zip_free_mutex; /*!< buddy allocator mutex */
BufListMutex zip_hash_mutex; /*!< zip_hash mutex */
ib_mutex_t flush_state_mutex; /*!< Flush state protection mutex */
BufPoolZipMutex zip_mutex; /*!< Zip mutex of this buffer */
// index、各种size、数量统计
ulint instance_no; /*!< Array index of this buffer pool instance */
ulint curr_pool_size; /*!< Current pool size in bytes */
ulint LRU_old_ratio; /*!< Reserve this much of the buffer pool for "old" blocks */
#ifdef UNIV_DEBUG
ulint buddy_n_frames;
#endif
ut_allocator<unsigned char> allocator; // 用于分配chunks
volatile ulint n_chunks; /*!< number of buffer pool chunks */
volatile ulint n_chunks_new; /*!< new number of buffer pool chunks */
buf_chunk_t *chunks; /*!< buffer pool chunks */
buf_chunk_t *chunks_old;
ulint curr_size; /*!< current pool size in pages */
ulint old_size; /*!< previous pool size in pages */
// hash table, 用于索引相关数据页
page_no_t read_ahead_area;
hash_table_t *page_hash;
hash_table_t *page_hash_old;
hash_table_t *zip_hash;
// 统计信息相关
ulint n_pend_reads;
ulint n_pend_unzip;
time_t last_printout_time;
buf_buddy_stat_t buddy_stat[BUF_BUDDY_SIZES_MAX + 1];
buf_pool_stat_t stat; /*!< current statistics */
buf_pool_stat_t old_stat; /*!< old statistics */
// flush相关
BufListMutex flush_list_mutex;
FlushHp flush_hp;
UT_LIST_BASE_NODE_T(buf_page_t) flush_list;
ibool init_flush[BUF_FLUSH_N_TYPES];
ulint n_flush[BUF_FLUSH_N_TYPES];
os_event_t no_flush[BUF_FLUSH_N_TYPES];
ib_rbt_t *flush_rbt;
ulint freed_page_clock;
ibool try_LRU_scan;
lsn_t track_page_lsn; /* Pagge Tracking start LSN. */
lsn_t max_lsn_io;
UT_LIST_BASE_NODE_T(buf_page_t) free;
UT_LIST_BASE_NODE_T(buf_page_t) withdraw;
ulint withdraw_target;
// lru 相关
LRUHp lru_hp;
LRUItr lru_scan_itr;
LRUItr single_scan_itr;
UT_LIST_BASE_NODE_T(buf_page_t) LRU;
buf_page_t *LRU_old;
ulint LRU_old_len;
UT_LIST_BASE_NODE_T(buf_block_t) unzip_LRU;
#if defined UNIV_DEBUG || defined UNIV_BUF_DEBUG
UT_LIST_BASE_NODE_T(buf_page_t) zip_clean;
#endif /* UNIV_DEBUG || UNIV_BUF_DEBUG */
UT_LIST_BASE_NODE_T(buf_buddy_free_t) zip_free[BUF_BUDDY_SIZES_MAX];
buf_page_t *watch;
};
buf_page_t
数据页的控制信息,包含数据页的大部分信息,page_id、size、引用计数(io,buf),access_time(用于lru调整),page_state以及压缩页的一些信息。
class buf_page_t {
public:
page_id_t id;
page_size_t size;
uint32_t buf_fix_count;
buf_io_fix io_fix;
buf_page_state state;
the flush_type. @see buf_flush_t */
unsigned flush_type : 2;
unsigned buf_pool_index : 6;
page_zip_des_t zip;
#ifndef UNIV_HOTBACKUP
buf_page_t *hash;
#endif /* !UNIV_HOTBACKUP */
#ifdef UNIV_DEBUG
ibool in_page_hash; /*!< TRUE if in buf_pool->page_hash */
ibool in_zip_hash; /*!< TRUE if in buf_pool->zip_hash */
#endif /* UNIV_DEBUG */
UT_LIST_NODE_T(buf_page_t) list;
#ifdef UNIV_DEBUG
ibool in_flush_list;
ibool in_free_list;
#endif /* UNIV_DEBUG */
FlushObserver *flush_observer; /*!< flush observer */
lsn_t newest_modification;
lsn_t oldest_modification;
UT_LIST_NODE_T(buf_page_t) LRU;
#ifdef UNIV_DEBUG
ibool in_LRU_list;
#endif /* UNIV_DEBUG */
#ifndef UNIV_HOTBACKUP
unsigned old : 1;
unsigned freed_page_clock : 31;
unsigned access_time;
#ifdef UNIV_DEBUG
ibool file_page_was_freed;
#endif /* UNIV_DEBUG */
#endif /* !UNIV_HOTBACKUP */
};
逻辑链表
free list
包含空闲的pages,当需要从buffer pool中分配空闲块时从free list中摘取,当free list为空时需要从LRU、unzip_LRU或者flush list中进行淘汰或刷脏以填充free list。buffer pool初始化时创建多个chunks,划分的pages都加入free list中待使用。
LRU list
最重要的链表,也是缓存占比最高的链表。buffer pool使用lru算法来管理缓存的数据页,所有从磁盘读入的数据页都会先加入到lru list中,也包含压缩的page。新的page默认加入到链表的3/8处(old list),等待下次读取并满足一定条件后再从old list加入到young list中,以防止全表扫描污染lru list。需要淘汰时从链表的尾部进行evict。
unzip_LRU list
是LRU list的一个子集,每个节点包含一个压缩的page和指向对应解压后的page的指针。
flush list
已修改过还未写到磁盘的page list,按修改时间排序,带有最老的修改的page在链表的最尾部。当需要刷脏时,从flush list的尾部开始遍历。
zip_clean list
包含从磁盘读入还未解压的page,page一旦被解压就从zip_clean list中删除并加入到unzip_LRU list中。
zip_free
用于buddy allocator的空闲block list,buddy allcator是专门用于压缩的page(buf_page_t)和压缩的数据页的分配器。
主要操作
初始化buffer pool
buffer pool在db启动时调用buffer_pool_create进行初始化,使用mmap创建配置大小的虚拟内存,并划分为多个chunks,其它字段基本使用calloc分配(memset)。
buf_page_get_gen
从buffer pool中读取page,比较重要的操作。通过page_id获取对应的page,如果buffer pool中有这个page则封装一些信息后返回,如果没有则需要从磁盘中读入。读取模式分为以下7种:
NORMAL
在page hash table中查找(hash_lock s模式),如果找到增加bufferfix cnt并释放hash_lock,如果该page不在buffer pool中则以sync模式从磁盘中读取,并加入对应的逻辑链表中,判读是否需要线性预读。如果第一次访问buffer pool中的该page,设置访问时间并判断是否需要线性预读。判断是否需要加入到young list中。
SCAN
如果page不在buffer pool中使用异步读取磁盘的模式,不做随机预读和线性预读,不设置访问时间不加入young list,其它与normal一样。
IF_IN_POOL
只在buffer pool中查找page,如果没有找到则返回NOT_FOUND。
PEEK_IF_IN_POOL
这种模式仅仅用来drop 自适应hash index,跟IF_IN_POOL类似,只是不加入young list,不做线性预读。
NO_LATCH
读取并设置buffefix,但是不加锁。
IF_IN_POOL_OR_WATCH
与IF_IN_POOL类似,只在buffer pool中查找此page,如果没有则设置watch。
POSSIBLY_FREED
与normal类似,只是允许执行过程中page被释放。
buf_LRU_get_free_block
从buffer pool的free list中摘取一个空闲页,如果free list为空,移除lru链表尾部的block到free list中。这个函数主要是用于用户线程需要一个空闲block来读取数据页。具体操作如下:
- 如果free list不为空,从中摘取并返回。否则转下面的操作。
- 如果buffer pool设置了try_LRU_scan,遍历lru链表尝试从尾部释放一个空闲块加入free list中。如果unzip_LRU链表不为空,则先尝试从unzip_LRU链表中释放。如果没有找到再从lru链表中淘汰。
- 如果没有找到则尝试从lru中flush dirty page并加入到free list中。
- 没有找到,设置scan_all重复上述过程,与第一遍不同的地方在于需要scan整个lru链表。
- 如果遍历了整个lru链表依然没有找到可以淘汰的block,则sleep 10s等待page cleaner线程做一批淘汰或者刷脏。
- 重复上述过程直到找到一个空闲block。超过20遍设置warn信息。
page cleaner
系统线程,负责定期清理空闲页放入free list中和flush dirty page到磁盘上,dirty page指那些已经被修改但是还未写到磁盘上的数据页。使用innodb_page_cleaners 参数设定page cleaner的线程数,默认是4。通过特定参数控制dirty page所占buffer pool的空间比维持在一定水位下,默认是10%。
flush list
上面章节提到过flush_list是包含dirty page并按修改时间有序的链表,在刷脏时选择从链表的尾部进行遍历淘汰,代码主体在buf_do_flush_list_batch中。这里不得不提的一个巧妙的操作,叫作Hazard Pointer,buf_pool_t中的flush_hp,将整体遍历复杂度由最差O(nn)降到了O(n)。之所以复杂度最差会变为O(nn)是由于flush list允许多个线程并发刷脏,每次从链表尾部进行遍历,使用异步io的方式刷盘,在io完成后将page从链表中摘除,每次提交异步io后从链表尾部再次扫描,在刷盘速度比较慢的情况下,可能每次都需要跳过之前已经flush过的page,最差会退化为O(n*n)。 flush_hp: 用于刷脏遍历flush list过程,flush_list_mutex保护下修改,在处理当前page之前,将hazard pointer设置为下一个要遍历的buf_page_t的指针,为线程指定下一个需要处理的page。当前page刷盘时会释放flush_list_mutex,刷盘完成后重新获得锁,处理flush_hp指向的page,无论这中间发生过什么,链表如何变动,flush_hp总是被设置成为下一个有效的buf_page_t指针。所以复杂度总能保证为O(n)。 刷脏的过程中也做了一些优化,代码在buf_flush_page_and_try_neighbors中,可以将当前page相邻的dirty page页也一起刷盘,目的是将多个随机io转为顺序io减少overhead,这在传统HHD的设备上比较有用,在SSD上seek time已经不是显著的影响因素。可以使用参数innodb_flush_neighbors进行设置和关闭:
- 为0则关闭flush neighbors的优化
- 默认值为1,flush与当前page相同extent(1M)上的连续dirty page
- 为2则flush与当前page相同extent上的dirty page
flush LRU list
buf_flush_LRU_list主要完成两件事:
- 将lru list尾部的可以移除的pages放入到free list中
- 将lru list尾部的dirty page刷到磁盘。
同一时刻只会有一个page cleaner线程对同一个LRU list操作。lru list遍历的深度由动态参数innodb_lru_scan_depth决定,用于优化io敏感的场景,默认值1024,设置比默认值小的值可以适应大多数work load,设置过大会影响性能,尤其是在buffer pool足够大的情况。操作过程在LRU_list_mutex的保护下,代码主体在buf_do_LRU_batch中。其中涉及到unzip_LRU list和LRU list中的淘汰,unzip_LRU list不一定每次都会做淘汰操作,衡量内存大小和负载情况,只有在size超出buffer pool的1/10以及当前负载为io bound的情况才会做。代码主体在buf_free_from_unzip_LRU_list_batch中, 将uncompressed page移除到free list中,并不会将任何数据刷盘,只是将解压缩的frames与压缩page分离。 如果在上述操作后仍无法达到需要释放的page数量(遍历深度),则继续从lru list尾部进行遍历,操作在buf_flush_LRU_list_batch中,lru list的遍历同样使用了Hazard Pointer,buf_pool_t中的lru_hp。当前page如果是clear并且没有被io fixed和buffer fixed,则从lru list中移除并加入free list中,否则如果page是已经修改过的并且满足flush的条件则对其进行刷脏。
小结
innodb设定了buffer pool的总大小,空闲page不够用时会将lru链表中可替换的页面移到free list中,根据统计信息估计负载情况来决定淘汰的策略。所有的block在几种状态之间进行转换,unzip_LRU、flush list设置一定的上限,设置多个影响淘汰和刷脏策略的参数,以达到不同负载不同buffer pool size下的性能和内存之间的平衡。
change buffer
change buffer是用于缓存不在buffer pool中的二级索引页改动的数据结构,insert、update或者delete这些DML操作会引起buffer的改变,page被读入时与change buffer中的修改合并加入buffer pool中。引入buffer pool的目的主要减少随机io,对于二级索引的更新经常是比较随机的,当页面不在buffer pool中时将其对应的修改缓存在change buffer中可有效地减少磁盘的随机访问。可以通过参数 innodb_change_buffering 设置对应缓存的操作:all, none, inserts, deletes, changes(inserts+deletes), purges。change buffer的内存也是buffer pool中的一部分,可以通过参数innodb_change_buffer_max_size来设置内存占比,默认25%,最多50%。

Adaptive Hash Index
innodb的索引组织结构为btree,当查询的时候会根据条件一直索引到叶子节点,为了减少寻路的开销,AHI使用索引键的前缀建立了一个哈希索引表,在实现上就是多个个hash_tables(分片)。哈希索引是为那些频繁被访问的索引页而建立的,可以理解为btree上的索引。看代码初始创建的数组大小为buf_pool_get_curr_size() / sizeof(void *) / 64,其实是比较小的一块内存,使用malloc分配。
log buffer
log buffer是日志未写到磁盘的缓存,大小由参数innodb_log_buffer_size指定,一般来说这块内存都比较小,默认是16M。在有大事务的场景下,在事务未commited之前可以将redo日志数据一直缓存,避免多次写磁盘,可以将log buffer调大。
参考资料:
https://dev.mysql.com/doc/refman/5.6/en/innodb-performance-use_sys_malloc.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-in-memory-structures.html