PolarDB · 新特性 · 路在脚下, 从BTree 到Polar Index
Author: baotiao
上一篇文章InnoDB BTree latch 优化历程 介绍了 InnoDB 的BTree latch 的优化历程, 我们知道在InnoDB 里面, 依然有一个全局的index latch, 由于全局的index latch 存在会导致同一时刻在Btree 中只有一个SMO 能够发生, index latch 依然会成为全局的瓶颈点, 导致在大批量插入场景, 比如TPCC 的场景中, 性能无法提高. 在MySQL 的官方性能测试人员Dimitrick 的MySQL Performance : TPCC “Mystery” [SOLVED] 中也可以看到, index lock contention 是最大的瓶颈点.
在这之前, 我们进行了大量的探索和验证, 在这个POLARDB · B+树并发控制机制的前世今生 和 POLARDB · 敢问路在何方 — 论B+树索引的演进方向 中, 我们对比了blink-tree, bw-tree, masstree 等等, 其实学术界更多的探索在简单的场景中进行lock free, 多线程, 针对硬件相关的优化, 但是在实际工程中, MySQL 的索引结构已经不是一个简单的Btree, 它是和MySQL 的事务锁模块强绑定, 同时他还需要支持不仅仅是前序遍历, 还需要支持 modify_prev/search_prev, 需要对non-leaf node 进行加锁操作. 因此在MySQL 中的Btree 的修改就不仅仅是涉及到btree 子模块, 还需要涉及undo log, 事务子模块等等.
因此PolarDB 提出来High Performance Polar Index 解决这个问题, 从而在我们某一个线上业务的实际场景中, 性能能够有3倍的提升, 在TPCC 场景下更是能够有有11倍的性能提升..
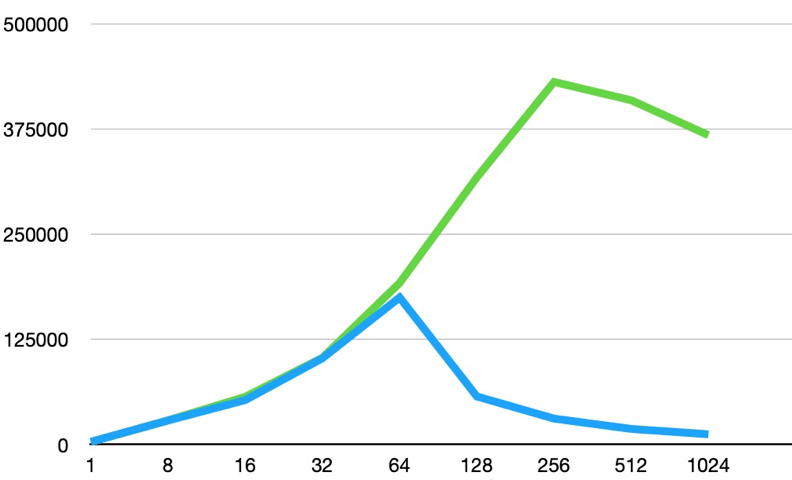
那Polar Index 的本质是什么, 如何实现的呢?
首先再来回顾一下InnoDB SMO的加锁流程(简化起见,假设本次SMO只需分裂leaf page):
- 对全局index->lock加SX锁
- 从root page开始,以不加锁的方式向下遍历non-leaf pages至level 2
- 对level 1的non-leaf page加X锁
- 对level 0的leaf page及其left、right page加X锁,完成leaf page的SMO
- 从root page开始,以不加锁的方式向下遍历至leaf page的parent
- 向parent page插入SMO中对应指向new page的nodeptr
- 释放所有锁,SMO结束
这里可以看到有下面2个瓶颈点:
- 对于单个SMO来说,参与SMO的leaf pages及其parent page的X锁会从一开始加着直到SMO结束,这样的加锁粒度有些大,其实SMO也是分层、从下到上依次操作的,如上面流程中:步骤4先在level 0对leaf page做分裂,然后再在步骤5向parent page插入指向new page的nodeptr,但其实在做步骤4的时候没必要先加着parent page X锁,同样再步骤5中也没必要还占着leaf pages X锁,这个问题在级联SMO场景(leaf page分裂引发其路径上多个non-leaf pages分裂)更为明显,这样在读写混合场景下,SMO路径上的读性能会受影响
- 虽然SMO对index->lock加了SX锁,可以允许其他非SMO操作并发进来,但SX之间还是互斥的,也就是说多个SMO并不能并发,即使它们之间完全没有page交集,这样在高并发大写入压力下(剧烈触发SMO)性能不理想
这些瓶颈点在Polar Index是如何解决的?
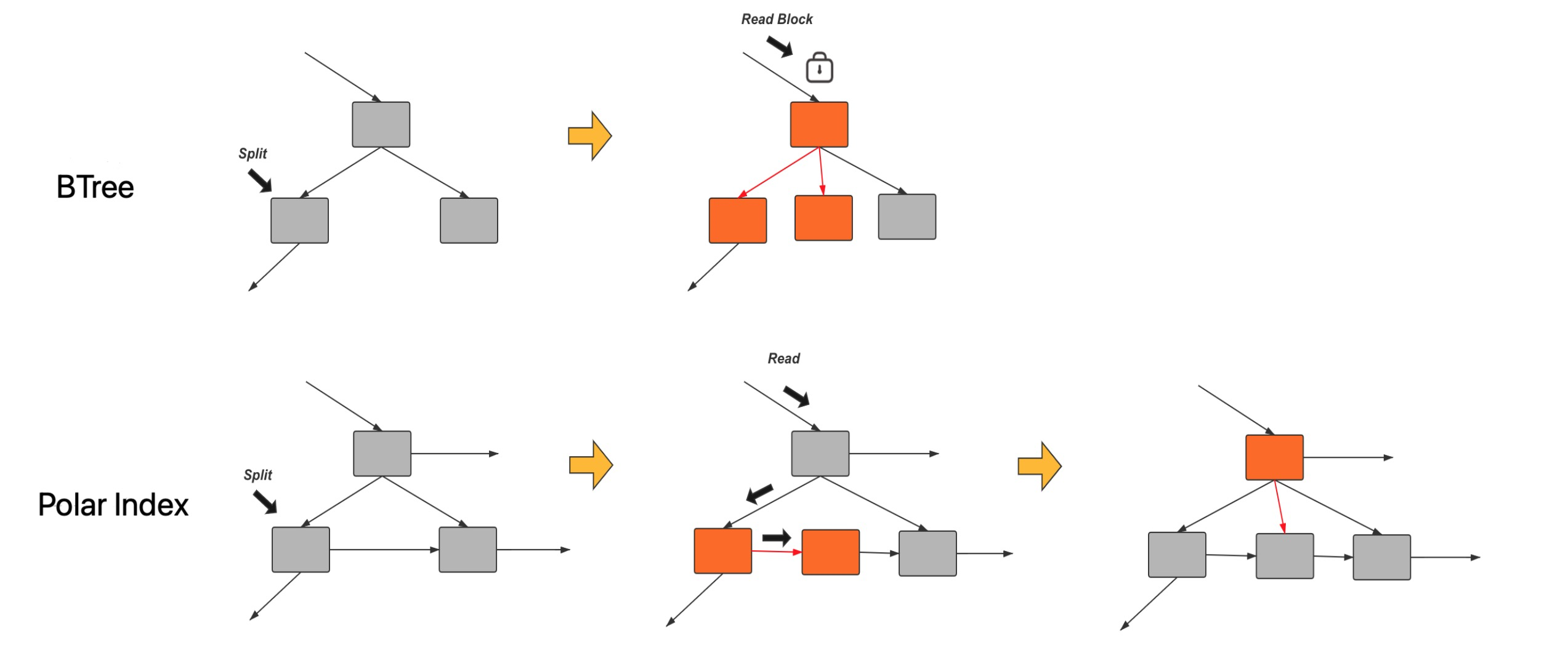
原先BTree 之所以需要持有Index latch 的原因是正常的搜索顺序是保证严格的自上而下, 自左向右, 但是SMO 操作由于需要保持对BTree 修改的原子性, 不能让其他线程访问到BTree 的中间状态, 因此需要持有叶子加点去加父节点的latch, 因此SMO 操作出现了自下而上的加锁操作, 在编程实现中, 一旦出现了多个线程无法遵守同一严格的加锁顺序, 那么死锁就无法避免, 为了避免这样的冲突InnoDB 通过将整个BTree index latch, 从而SMO 的时候, 不会有搜索操作进行.
Polar Index 的核心想法是把 SMO 操作分成了两个阶段.
在Polar Index 中每一个node 包含有一个link page 指针, 指向他的node. 以及fence key 记录的是link page 的最小值.
比如split 阶段
阶段1: 将一个page 进行split 操作, 然后建立一个link 连接在两个page 之间. 下图Polar Index 就是这样的状态
阶段2: 给父节点添加一个指针, 从父节点指向新创建的page.
当然还可以有一个阶段3 将两个page 之间的link 指针去掉.
在Polar Index 中, 阶段1 和阶段2 的中间状态我们也认为是合理状态, 如果这个阶段实例crash, 那么在crash recovery 阶段可以识别当前page 有Link page, 那么会将SMO 的下一个阶段继续完成, 从而保证BTree 的完整性.
这样带来的优点是在SMO 的过程中, 由于允许中间状态是合法状态, 那么就不需要为了防止出现中间状态的出现而需要持有叶子节点加父节点latch 的过程. 因此就避免的自下而上的加锁操作, 从而就不需要Index latch.
如下图对比BTree 和 Polar Index.
在去掉Index latch 之后, 通过latch coupling 从而保证每一次的修改都只需要在btree 的某一层加latch, 从而最大的减少了latch 的粒度.
如下是具体执行right split 的过程:
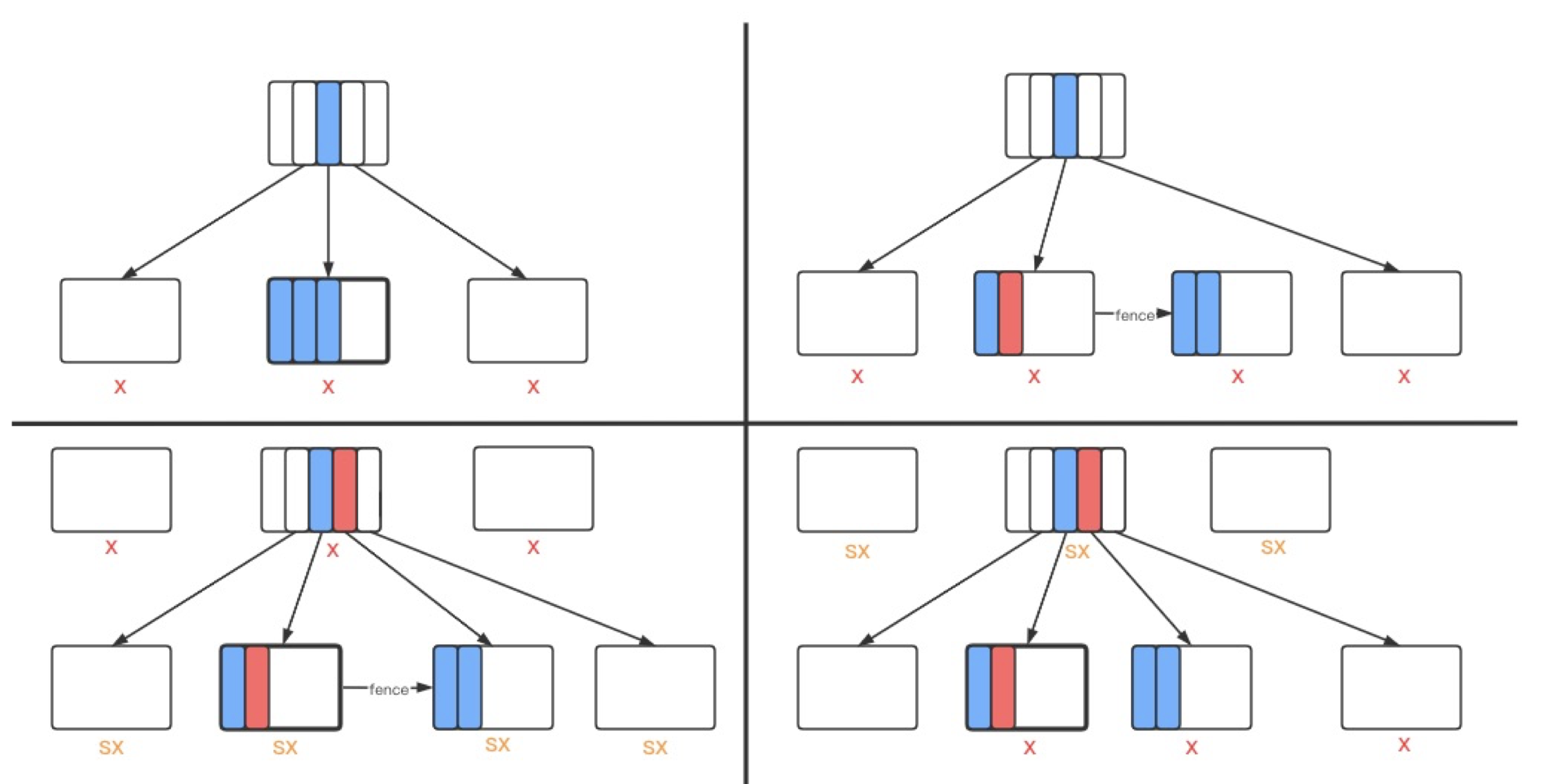
带来的收益是:
-
降低SMO的page加锁粒度,当前修改哪一层,就只对这一层相关的page加X锁,并且修改完之后立刻放锁再去修改其他层,这样读写并发就上来了。这样的做法要解决的问题就是:
对leaf page做完分裂之后,放锁放锁去修改parent,那么已经迁移到new page上的数据怎么被其他线程访问到呢?
这里Polar Index采用了类似Blink tree的做法,给分裂的leaf page设置一个high key,这个值为new page上最小的rec,这样如果leaf page放X锁之后,从parent下来的其他读操作检测到这个high key之后,就知道如果要查找的目标rec在当前leaf page没找到并且大于等于high key的话,就去next page(也就是new page)上查找。
-
去掉全局index->lock,正常的读写及SMO不对index->lock加任何锁,这样写并发就能上来了。不过在具体实现中,不是简单的删掉代码那么容易,要解决去掉它之后各种各样的问题:
遍历BTree的加锁方式
InnoDB在普通读、写操作时遍历BTree的方式:是从root page开始,将路径上所有non-leaf pages加S锁,然后占着S锁去加目标leaf page的X锁,加到之后释放non-leaf pages的S锁;在SMO是遍历BTree的方式是前面流程中的步骤2。当我们去掉index->lock,允许多个SMO并发起来,显然SMO的遍历方式是有问题的,因为在第一遍以无锁方式遍历BTree找到所有需要加X锁的page到第二遍遍历真正对这些page加锁之间,可能其他SMO已经修改了BTree结构。所以我们将遍历方式统一改成lock coupling,同时最多占2层page锁,这样做的好处是不管是普通读、写还是SMO操作,在遍历BTree时对non-leaf pages的加锁区间都很小,进一步提高并发
除此之外,在具体实现中,还要解决大量问题,比如:
- 多个SMO之间有重叠的pages,如何解决冲突,避免死锁
- 对于左分裂、左合并这种右->左的加锁,如何避免死锁
- 对于non-leaf page删除leftmost rec而触发其parent的级联删除如何处理
- … …
总结
在InnoDB 里面, 依然有一个全局的Index latch, 由于全局的Index latch 存在会导致同一时刻在Btree 中只有一个SMO 能够发生, 从而导致性能无法提升.
Polar Index 通过将SMO 操作分成两个阶段, 并保证中间状态的合理性, 从而避免了Index latch. 从而保证任意时刻在BTree 中只会持有一层latch, 从而实现性能极大提升.