MySQL · 内核特性 · 直方图
Author: huaying
背景
直方图(histogram)是数据库中的一种重要的统计信息,可以描述列中的数据分布情况。MariaDB 在 10.0 版本就实现了这一功能,MySQL 也在 8.0 版本增加了对直方图的支持。
直方图最典型的应用场景是通过估算查询谓词的选择率来帮助优化器选择最优的执行计划。举个简单的例子,考虑以下SQL语句:
select *
from
customer join orders on customer.cust_id = orders.customer_id
where
customer.balance < 1000 and
orders.total > 10000
在优化过程中,为了决定 customer 与 orders 两表的 join order,我们需要哪个表经过 where 条件(customers.balance < 1000 和 orders.total > 10000)筛选后能生成更少的行数。这时,优化器不光需要知道两表的总行数,也需要知道每个表中符合条件的行数,即查询谓词的选取率。在相应列既没有直方图也没有索引的情况下,MySQL 对选择率的估算为max((1/max_distinct_values), max_distinct_values),其中max_distinct_values的值为 0.1(where 条件为 = 时)或 0.333(where 条件为 < 或 > 时)。这种估算方式十分粗糙地忽略了列中数据的分布。
本文将大致讲解几种主流直方图进行统计数据存储、数据采样及选取率估算的原理;并用简单的例子介绍 MySQL 中直方图的使用方式和其对 SQL 优化的作用。
直方图的实现原理
直方图的基本原理是将数据排序后分成若干个桶(bucket),并记录每个桶中数据的最大值、最小值、出现频次占比等信息。按照数据分桶的方式和桶中储存的数据可以分为 Equi-width Histogram、Equi-height Histogram、Compressed Histogram 等。
下面我们将介绍几种主流的直方图类型及其实现原理。示例中会以下表中列 score 上、N个桶的直方图为例:
create table exam (student_id int, score int);
假设score的概率分布曲线如下:
Equi-width Histogram
Equi-width Histogram(等宽直方图)是将数据最大、小值之间的区间等分为N份,每个桶中最大、小值之差都为整体数据最大、小值之差/N,既所谓“等宽”。我们以 N=20 为例,在按照该曲线随机生成的数据上可以得到如下结果:
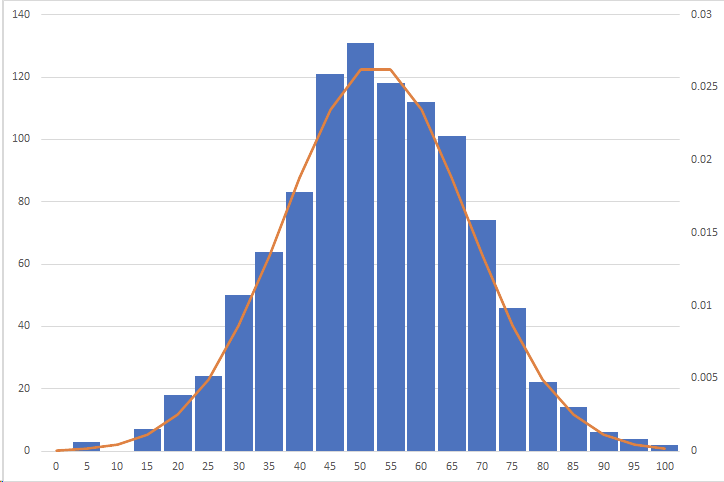
Equi-width Histogram 最大的缺陷是在数据频次较高的桶中统计信息不够清晰,比如在桶 [55, 60] 中,我们只知道它的总频次是40,却不知道是55、56、57、58、59各出现了8次,还是55出现了36次而其他值都只有一次。因此,当桶数量远小于列中 distinct value 数量、单个桶中 distinct value 过多且分布不均时,Equi-width Histogram 很有可能做出错误的估算并影响优化结果。
Singleton Histogram
Singleton Histogram 可以视为等宽直方图在桶数量与 distinct value 数目相等时的特殊情况,每个桶都只记录一个值的出现频次。Singleton Histogram 能够提供最为精确的数据分布信息,但当列中的 distinct value 较多时,Singleton Histogram 占用的内存也会到达一个难以接受的数值,
Equi-height Histogram
Equi-height Histogram(等高直方图)又叫 Equi-depth Histogram,它的桶宽度并不相等,取而代之的是,等高直方图会保证每个桶中数值的频次之和为总行数的 1/N。然而,严格遵守“等高”的原则进行分桶会使某些值出落桶的边界上,而导致同一个值出现在两个不同的桶中。显然,这样会对选择率的估算造成干扰,所以 MySQL 在实现中对其进行了一定的修改:如果将一个值加入桶中会导致桶中数据频次超过总行数的 1/N,则根据哪种情况更接近 1/N 将该值放入其中该桶或下一个桶中。这种 Equi-height Histogram 的变形在 MySQL 中仍被称为 Equi-height Histogram。
在和之前概率曲线相同的数据集上,能够生成如下图所示的等高直方图:
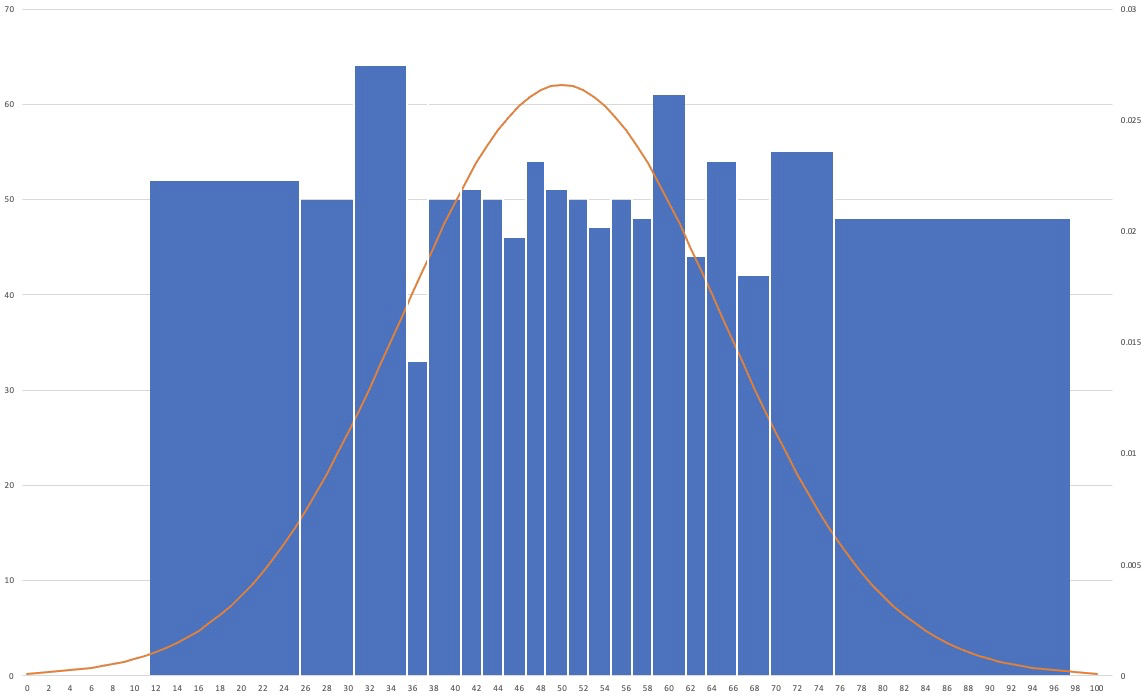 由图中可以看到桶中的数据频次已经和分布曲线没有关系,而且每个桶中的行数都十分接近。值得注意的是,数据集中的区间内每个桶中的数值跨度更小,这样有利于增加选择率估算的准确性;而数据分散的区间内每个桶中的数值跨度更大,有利于减小储存直方图所消耗的内存。
由图中可以看到桶中的数据频次已经和分布曲线没有关系,而且每个桶中的行数都十分接近。值得注意的是,数据集中的区间内每个桶中的数值跨度更小,这样有利于增加选择率估算的准确性;而数据分散的区间内每个桶中的数值跨度更大,有利于减小储存直方图所消耗的内存。
当然,MySQL 中的这种等高直方图也有它的局限性:由于单个 distinct value 不能同时出现在多个桶中,所以当存在某个频次占比远高于 总行数/N 的数值时,等桶中的数据分布将出现较大倾斜。比如,将一半的数据改为 100,则直方图的分桶结果会变为:
| 桶下限 | 4 | 29 | 37 | 42 | 46 | 50 | 54 | 59 | 64 | 70 | 79 | 80 | 81 | 83 | 84 | 87 | 88 | 90 | 97 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 桶上限 | 28 | 36 | 41 | 45 | 49 | 53 | 58 | 63 | 69 | 78 | 79 | 80 | 81 | 83 | 84 | 87 | 88 | 90 | 100 |
| 数据量 | 51 | 49 | 54 | 44 | 52 | 47 | 55 | 46 | 51 | 36 | 1 | 4 | 1 | 2 | 1 | 1 | 2 | 1 | 502 |
可以看到,最后一个桶中集中了一半的数据,而部分桶中数据占比极低。所以在列中的数据大量集中在少数几个数值是,等高直方图并不是一个合适的选择。
目前版本的 MySQL 代码中,共实现了两种直方图,一种就是 Equi-height Histogram,另一种是刚才聊到的 Singleton Histogram。创建直方图时无需指定,MySQL 会根据桶数量 N 和列指定中 distinct value 数量的关系自动选择要使用的直方图类型:当 N > distinct value 数量时选用 Equi-height Histogram,否则使用 Singleton Histogram。
Compressed Histogram
刚才我们列举了一种对 Equi-height Hisgotram 和 Singleton Histogram 都比较尴尬的分布方式:少数数值出现频率极高,而大多数数值则占比不大且分布较为均匀。对于这样的数据,使用 Equi-height Hisgotram 会遇到高占比数值引起的统计数据倾斜,而使用 Singleton Histogram 则需要对占比不大的数据也单独建桶,颇有大材小用之嫌。
对于这样的数据,就适合建立 Compressed Histogram。它是Equi-height Hisgotram 和 Singleton Histogram 的结合,既会分配单独的桶给出现频次较高、对选择率影响较大的数值,也会建立类似于等高直方图的桶来聚合频次较低、没有必要单独建桶的数值,同时集合了 Singleton Histogram 的高精度和 Equi-height Hisgotram 的高聚合度。
Compressed Histogram 在社区版本的 MySQL 中暂时没有实现。但是在 PostgreSQL、PolarDB 中有已经加入了相应的功能。
限于篇幅,本文只介绍以上几种直方图的类型,除此之外还有 Top Frequency、Hybrid 等多种思路各异的直方图类型,感兴趣的朋友可以自己在网上学习相关资料。
直方图的建立
MySQL中用户可以通过如下语句建立或更新直方图:
ANALYZE TABLE t1 UPDATE HISTOGRAM ON col1 [, col2, ...] [ WITH n BUCKETS ];
# 其中 n 默认为 100
建立直方图前,要先对相应的列建立 value_map。value_map 是一个 map 结构,其 key 为列中出现的 distinct 值,value 为该值的出现频次。和 analyze table 相似,建立 value_map时也可以不扫描表中所有数据,而是通过部分采样的方式来提高效率。
其采样率由系统变量 histogram_generation_max_mem_size决定。它的主要作用是通过调整采样率限制创建或更新直方图时占用的最大内存大小,具体计算方式如下:
size_t row_size_bytes= 0;
for (int i = 0; i < FIELDS_COUNT; i++)
{
// Row count variable.
row_size_bytes+= sizeof(ha_rows);
/*
Data type size. For instance, sizeof(double). For Strings, we are
pessimistic and do:
sizeof(String) + (charset.mbmaxlen *
min(field_length, HISTOGRAM_MAX_COMPARE_LENGTH));
其中,HISTOGRAM_MAX_COMPARE_LENGTH 为 42
*/
row_size_bytes+= sizeof(field[i].DATA_TYPE);
/*
Overhead for each node in the Value_map. This depends on the underlying
container. For instance, std::map on GCC has a overhead of 32 bytes per
node, while std::vector has little/no overhead.
*/
row_size_bytes+= VALUE_MAP_NODE_OVERHEAD;
}
这里我们可以看到,段 String 的长度直接被忽略,单个 String 的长度被视为至少 42,且计算每一行时都加入了 map key 占用的内存,而实际上一个 distinct 值只需要占用一次。所以,此处对内存占用的估计其实是相当粗糙的,实际占用的内存大小很可能小于 histogram_generation_max_mem_size ,实际使用时可以通过 SELECT schema_name, table_name, column_name, HISTOGRAM->>'$."sampling-rate"' FROM INFORMATION_SCHEMA.COLUMN_STATISTICS;来查看采样率,逐渐调整到合适的数值。具体的操作可以参考这里提供的方法。
虽然更高的采样率能带来更准确的统计信息,但也会增加建立直方图所需的时间,90G 的表建立采样率 100% 的直方图所需时间大约为三十分钟。为了减小对线上业务的影响,建议根据实际情况合理调整采样率,并在业务低峰期进行直方图更新。为了从根本上解决这一问题,我们还为 PolarDB 设计了直方图更新的 offload 功能,即将直方图的建立放在备节点上进行,获取统计信息后再回传到主节点进行写入,由此来将直方图更新对业务的影响降低到最小。
生成 value_map 后,MySQL 会以“桶数 N 是否不小于列中 distinct 值数量”为标准选择 Singleton Histogram 或 Equi-height Histogram 并生成相应直方图,并将结果以 JSON 的形式储存在 INFORMATION_SCHEMA.COLUMN_STATISTICS中。
当表数据变化导致直方图中的统计信息过时需要更新时,可以通过ANALYZE TABLE t1 UPDATE HISTOGRAM ON col1 [, col2, ...] [ WITH n BUCKETS ];在该列上重新建立。目前 MySQL 还不支持对直方图的自动更新,而 PolarDB 已经支持根据更新行数批量更新直方图。
直方图的优化效果
直方图对对执行计划的优化主要在两个方面:where 条件的选择和 join order 的选择。where 条件的选择原理比较简单:通过直方图计算各谓词的选择率,优先进行选择率较高的筛选,在背景部分已经有简单的举例。
join order 的选择则基于对 join 结果行数的估算。如果 join 条件中的列都已经建立了直方图,则可以根据以下流程对 join 结果行数进行较为准确的估算:
- 调整其中一表的直方图使得两直方图的桶边界相同。
- 将两表中数据相对应的每对桶中的行数相乘。
- 将上一步结果求和,得到预估行数。
在 join 条件列上数据分布不均匀的情况下,使用直方图能够大大提升 join 结果行数预估的准确性。同时,如果发现某个桶在其中一列上的行数为0,也可以进行标记并在后续执行 join 的过程中直接跳过该桶以提升效率。
直方图与索引的区别
与索引相比,直方图并不能直接加速数据扫描,只是通过辅助选择更优的 where 条件或 join order 来优化执行计划。但由于直方图中储存的数据更为精简,对它进行创建、储存与更新的代价也比索引要小得多。同时,直方图不要求与表中数据保持实时同步,只需要在表中数据已经累计的较多修改是手动更新即可。所以直方图也完全不会对insert及delete的效率造成影响。
在优化效率方面,在只需要读取统计信息计算选择率时,使用 index dive 需要对磁盘中的索引数据进行读取,而只用直方图则是内存操作,在效率上也超过了索引。
综上所述,当我们已经有合适的索引帮助查询,只需要对where条件的筛选顺序进行优化时,对所需列创建直方图是一个比增加索引更为高效的选择。
小结
到这里我们已经大致介绍了 MySQL 中直方图的原理和使用。与 MariaDB、Oracle 等更早实现了直方图的产品相比,MySQL 直方图的实现还是相对原始,在大表采样、自动更新等方面有很大的提升空间。目前我们也在逐步展开相关工作,填补社区 MySQL 在这些方面的空白。
参考
- 官方 WL#8707: Classes/structures for Histograms
- 官方 WL#8706: Persistent storage of Histogram data
- 官方 WL#8943: Extend ANALYZE TABLE with histogram support
- 官方 WL#9127: Define new handler API for sampling
- 官方 WL#9223: Using histogram statistics in the optimizer
- 一文读懂MySQL 8.0直方图
- Improved Histograms for Selectivity Estimation of Range Predicates